GKE usage metering: Whose line item is it anyway?

Madhu Yennamani
Product Manager
As Kubernetes gains widespread adoption, a growing number of enterprises and [P/S]aaS providers are using multi-tenant Kubernetes clusters for their workloads. These clusters could be running workloads that belong to different departments, customers, environments, etc. Multi-tenancy has a whole slew of advantages: better resource utilization, lower control plane overhead and management burden, reduced resource fragmentation, and reuse of extensions/CRDs, to name a few. However, the advantages do come at a cost. When running Kubernetes in a multi-tenant configuration, it can be hard to:
- estimate which tenant is consuming what portion of the cluster resources
- determine which tenant introduced a bug that led to a sudden usage spike
- identify the prodigal tenant(s) who may not be aware that they are wasting resources
We are pleased to announce the launch of Google Kubernetes Engine (GKE) usage metering in beta. The feature allows you to see your Google Cloud Platform (GCP) project’s resource usage broken down by Kubernetes namespaces and labels, and attribute it to meaningful entities (for example, department, customer, application, or environment.) This enables a number of enterprise use cases, such as approximating cost breakdown for departments/teams that are sharing a cluster, understanding the usage patterns of individual applications (or even components of a single application), helping cluster admins triage spikes in usage, and providing better capacity planning and budgeting. SaaS providers can also use it to estimate the cost of serving each consumer.
How GKE usage metering works
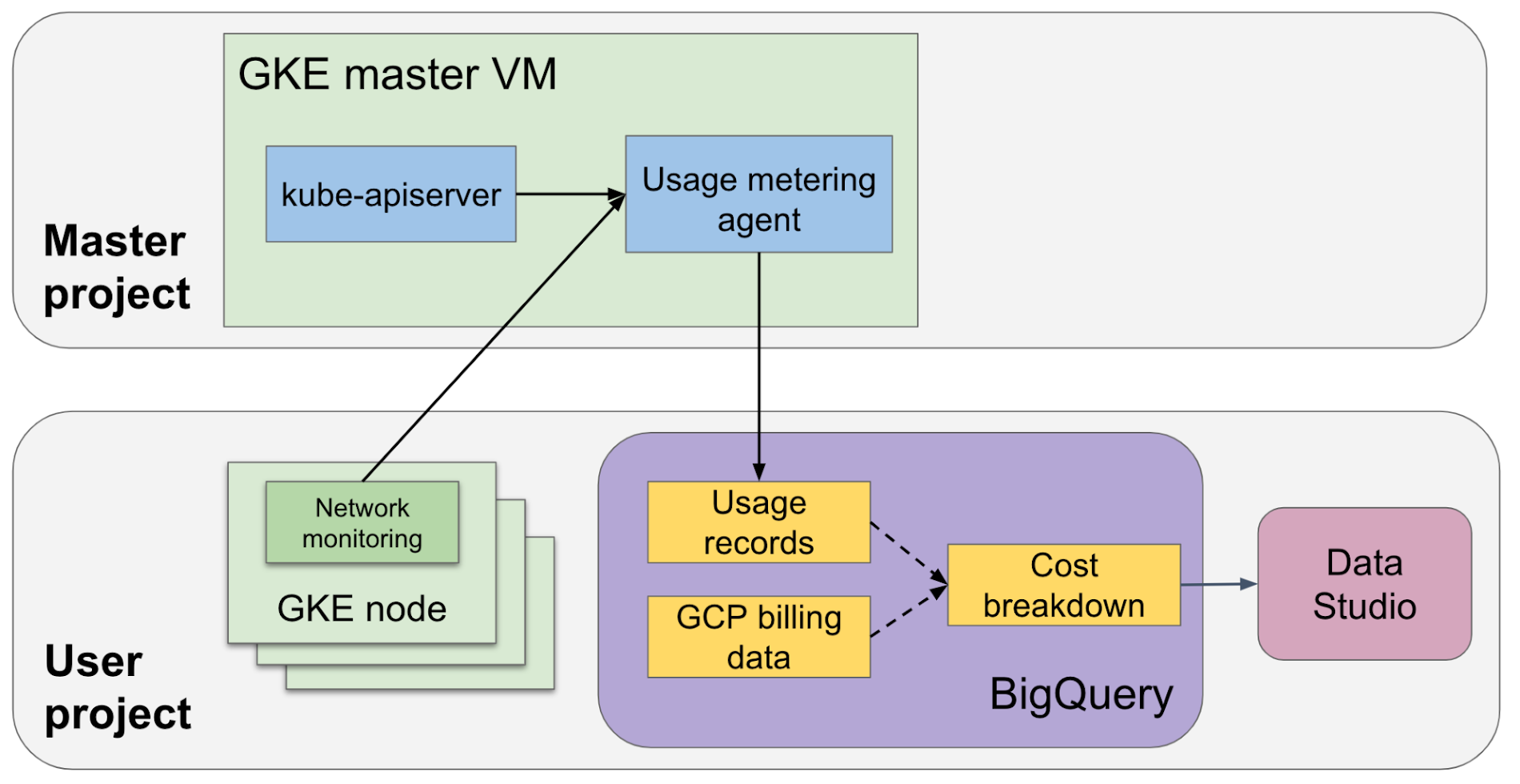
When you enable GKE usage metering, resource usage records are written to a BigQuery table that you specify. Usage records can be grouped by namespace, labels, time period, or other dimensions to produce powerful insights. You can then visualize the data in BigQuery using tools such as Google Data Studio.
Optionally, you can enable network egress metering. With it, a network metering agent (NMA) is deployed into the cluster as a DaemonSet (one NMA pod running on each cluster node). The NMA is designed to be pretty lightweight, however, it is important to note that an NMA runs as a privileged pod and consumes some resources on the node.
What customers are saying
Early adopters of GKE usage metering tell us that the feature improves the operational efficiency and flexibility of their organizations.
“We have found the usage metering feature very helpful as it lets us break down costs for each individual team using a multi-tenant cluster. Since the data is available directly in BigQuery, our finance team can easily access the data, without us as operators having to write any scripts or do calculations ourselves.” - Matthew Brown, Staff Software Engineer, Spotify
“Descartes Labs' multi-tenant platform is built on top of Kubernetes and GKE to allow many different types of use cases, such as wide-range geospatial ML modeling, but no two workloads have the exact same resource footprint. Being able to isolate each user's workload in its own Kubernetes namespace, then having tooling natively built into GKE to measure resources being consumed per namespace, provides us great visibility into how our platform is being leveraged and works similarly to the GCP billing export we are already know well.” - Tim Kelton, Co-founder, head of SRE, Security, and Cloud Operations, Descartes Labs
Getting started
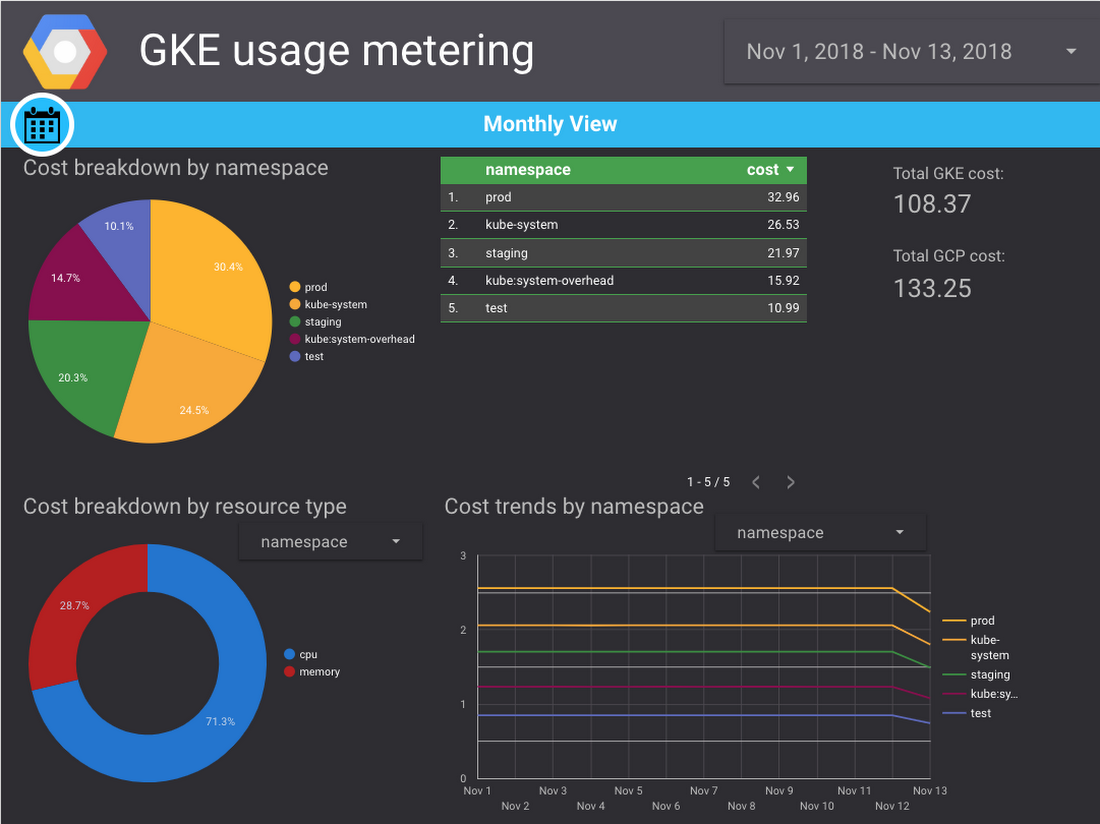
You can enable usage metering on a per-cluster basis (detailed instructions and relevant documentation can be found here). This enables one of GKE usage metering’s popular use cases: obtaining a cost breakdown of individual tenants. In the documentation, you’ll find some sample BigQuery queries and plug-and-play Google Data Studio templates to join GKE usage metering and GCP billing export data to estimate a cost breakdown by namespace and labels. They allow you to create dashboards like this:
GKE usage metering best practices
The combination of namespaces and labels gives a lot of flexibility—users can segregate resource usage using namespaces, Kubernetes labels, or a combination of both. Taking the time to consciously plan the namespace/labeling strategy and standardizing it across your organization will make it easier to generate powerful insights down the road. The exact recommendations for setting namespaces and labels vary depending on factors such as the size of the company, the complexity of workloads, organizational structure, etc. Here are some general guidelines to keep in mind:
- While using too many namespaces can introduce complexity, using too few will make it hard to take advantage of multi-tenancy features. For a large company with multiple teams sharing the cluster, aim to have at least one namespace per team. For more details and scenarios, see this short video.
- It is a good idea to define a required set of labels for the org and make sure the essential attributes are captured for every application/object. For example, you can require every Kubernetes application to define the application id, team name, and environment, and allow team members to customize additional labels as needed. However, keep in mind that taking this to the extreme and using too many labels may slow down some components.
Enabling effective multi-tenancy on Kubernetes
Enterprises and resellers using GKE clusters in a multi-tenant environment need to understand resource consumption on a per-tenant basis. GKE usage metering provides a flexible mechanism to dissect and group GKE cluster usage based on namespaces and labels. You can find detailed documentation on our website. And please take a few minutes to give us your feedback and ideas, to help us shape upcoming releases.
