Performance-driven dynamic resource management in E2 VMs
Ari Liberman
Group Product Manager
Tyler Sanderson
Software Engineer
Editor's note: As of March 19, 2020, E2 VMs are generally available. We’ve also added E2 VMs to all 22 global regions. This is the second post in a two-post series. Click here for part 1: E2 introduction.
As one of the most avid users of compute in the world, Google has invested heavily in making compute infrastructure that is cost effective, reliable and performant. The new E2 VMs are the result of innovations Google developed to run its latency-sensitive, user-facing services efficiently. In this post, we dive into the technologies that enable E2 VMs to meet rigorous performance, security, and reliability requirements while also reducing costs.
In particular, the consistent performance delivered by E2 VMs is enabled by:
An evolution toward large, efficient physical servers
Intelligent VM placement
Performance-aware live migration
A new hypervisor CPU scheduler
Together we call these technologies dynamic resource management. Just as Google’s Search, Ads, YouTube, and Maps services benefited from earlier versions of this technology, we believe Google Cloud customers will find the value, performance, and flexibility offered by E2 VMs improves the vast majority of their workloads.
Introducing dynamic resource management
Behind the scenes, Google’s hypervisor dynamically maps E2 virtual CPU and memory to physical CPU and memory on demand. This dynamic management drives cost efficiency in E2 VMs by making better use of the physical resources.
Concretely, virtual CPUs (vCPUs) are implemented as threads that are scheduled to run on demand like any other thread on the host—when the vCPU has work to do, it is assigned an available physical CPU on which to run until it goes to sleep again. Similarly, virtual RAM is mapped to physical host pages via page tables that are populated when a guest-physical page is first accessed. This mapping remains fixed until the VM indicates that a guest-physical page is no longer needed.
The image below shows vCPU work coming and going over the span of a single millisecond. Empty space indicates a given CPU is free to run any vCPU that needs it.
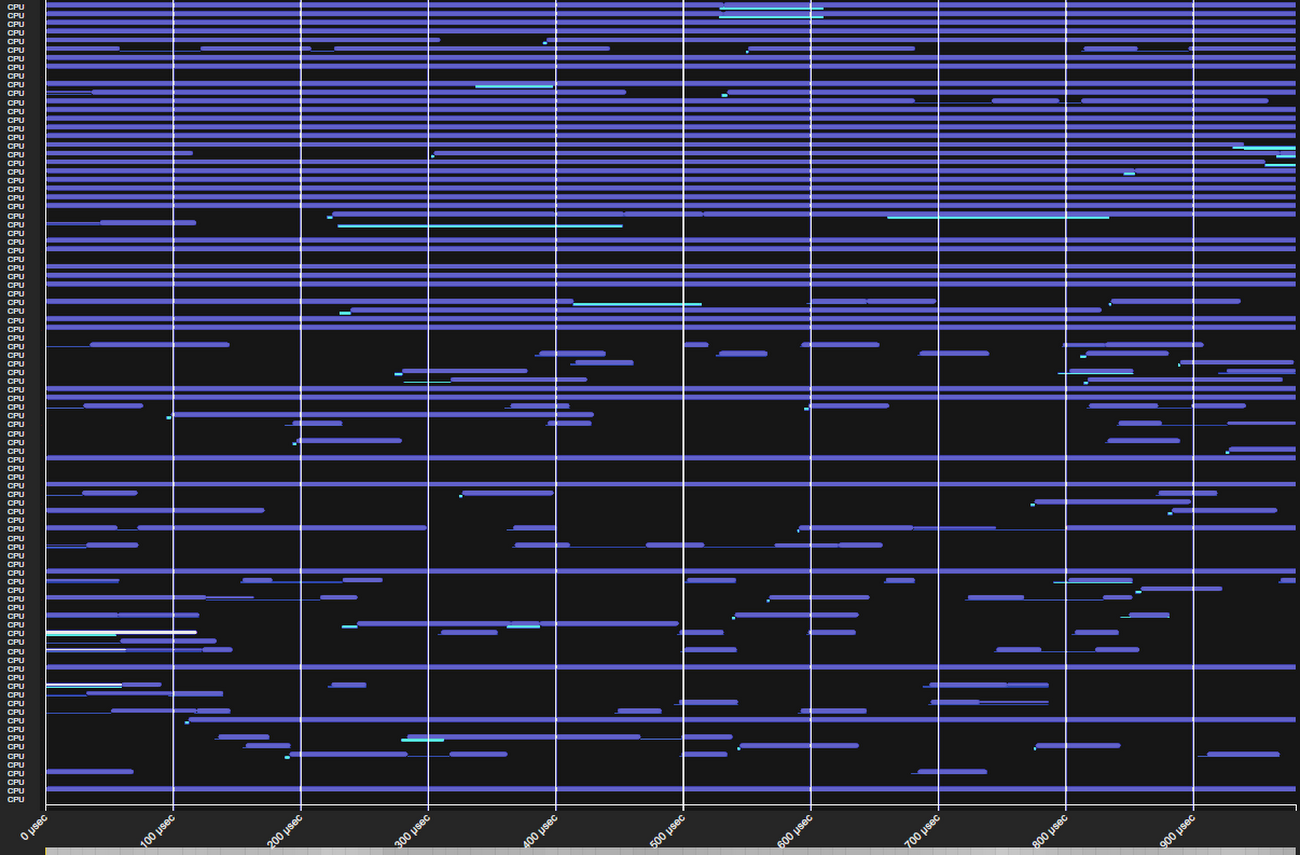
Notice two things: there is a lot of empty space, but few physical CPUs are continuously empty. Our goal is to better utilize this empty space by scheduling VMs to machines and scheduling vCPU threads to physical CPUs such that wait time is minimized. In most cases, we are able to do this extremely well. As a result, we can run more VMs on fewer servers, allowing us to offer E2 VMs for significantly less than other VM types.
For most workloads, the majority of which are only moderately performance sensitive, E2 performance is almost indistinguishable from that of traditional VMs. Where dynamic resource management can differ in performance is in the long tail—the worst 1% or 0.1% of events. For example, a web serving application might see marginally increased response times once per 1,000 requests. For the vast majority of applications, including Google’s own latency-sensitive services, this difference is lost in the noise of other performance variations such as Java garbage collection events, I/O latencies and thread synchronization.
The reason behind the difference in tail performance is statistical. Under dynamic resource management, virtual resources only consume physical resources when they are in use, enabling the host to accommodate more virtual resources than it could otherwise. However, occasionally, resource assignment needs to wait several microseconds for a physical resource to become free. This wait time can be monitored in Stackdriver and in guest programs like vmstat and top. We closely track this metric and optimize it in four ways that we detail below.
1. An evolution toward large, efficient physical servers
Over the past decade, core count and RAM density has steadily increased such that now our servers have far more resources than any individual E2 VM. For example, Google Cloud servers can have over 200 hardware threads available to serve vCPUs yet an E2 VM has at most 16 vCPUs. This ensures that a single VM cannot cause an unmanageable increase in load.
We continually benchmark new hardware and look for platforms that are cost-effective and perform well for the widest variety of cloud workloads and services. The best ones become the “machines of the day” and we deploy them broadly. E2 VMs automatically take advantage of these continual improvements by flexibly scheduling across the zone’s available CPU platforms. As hardware upgrades land, we live-migrate E2 VMs to newer and faster hardware, allowing you to automatically take advantage of these new resources.
2. Intelligent VM placement
Google’s cluster management system, Borg, has a decade of experience scheduling billions of diverse compute tasks across diverse hardware, from TensorFlow training jobs to Search front- and back-ends. Scheduling a VM begins by understanding the resource requirements of the VM based on static creation-time characteristics.
By observing the CPU, RAM, memory bandwidth, and other resource demands of VMs running on a physical server, Borg is able to predict how a newly added VM will perform on that server. It then searches across thousands of servers to find the best location to add a VM.
These observations ensure that when a new VM is placed, it is compatible with its neighbors and unlikely to experience interference from those instances.
3. Performance-aware live migration
After VMs are placed on a host, we continuously monitor VM performance and wait times so that if the resource demands of the VMs increase, we can use live migration to transparently shift E2 load to other hosts in the data center.
The policy is guided by a predictive approach that gives us time to shift load, often before any wait time is encountered.
VM live migration is a tried-and-true part of Compute Engine that we introduced six years ago. Over time, its performance has continually improved to the point where its impact on most workloads is negligible.
4. A new hypervisor CPU scheduler
In order to meet E2 VMs performance goals, we built a custom CPU scheduler with significantly better latency guarantees and co-scheduling behavior than Linux’s default scheduler. It was purpose-built not just to improve scheduling latency, but also to handle hyperthreading vulnerabilities such as L1TF that we disclosed last year, and to eliminate much of the overhead associated with other vulnerability mitigations. The graph below shows how TCP-RR benchmark performance improves under the new scheduler.
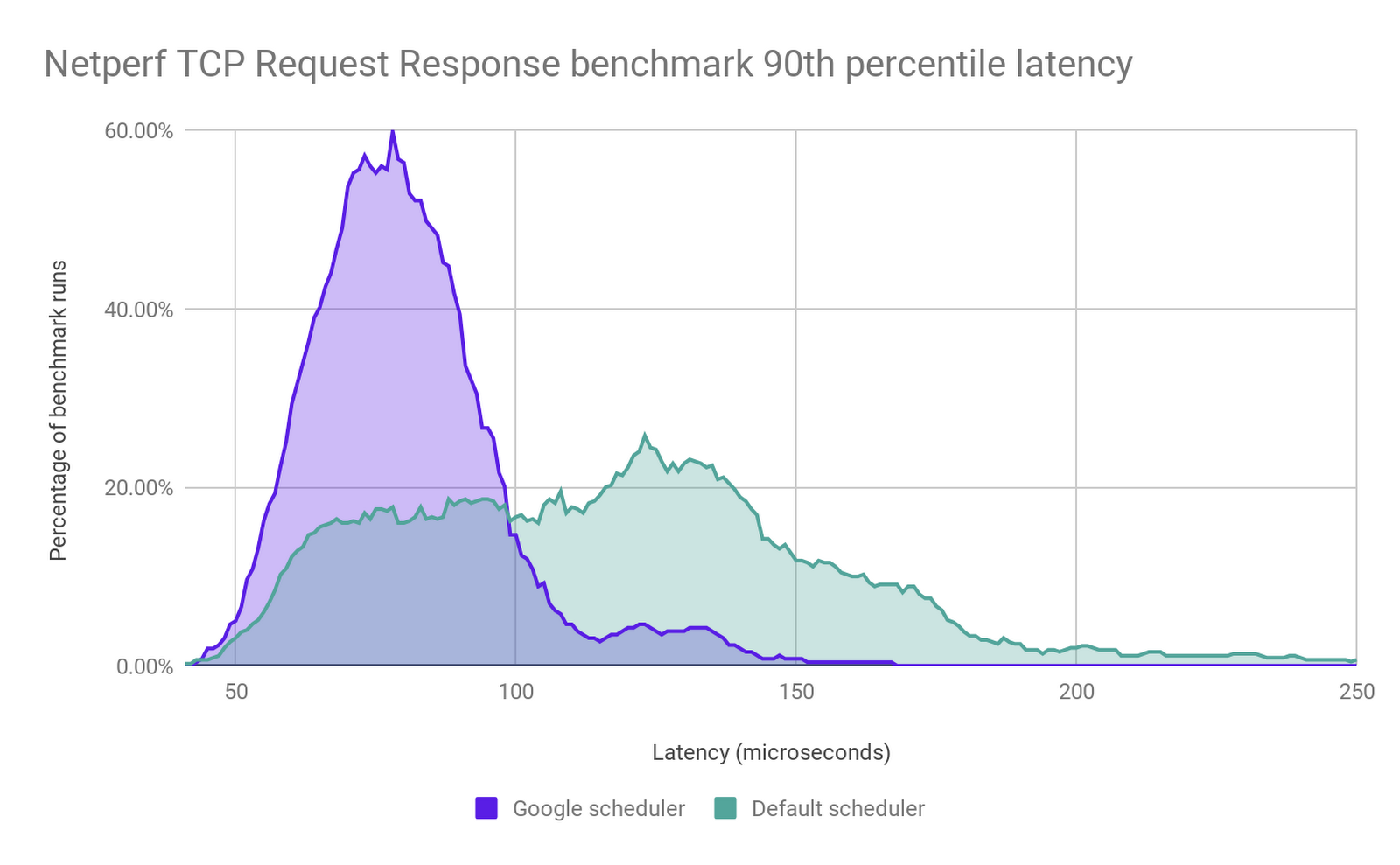
The new scheduler provides sub-microsecond average wake-up latencies and extremely fast context switching. This means that, with the exception of microsecond-sensitive workloads like high-frequency trading or gaming, the overhead of dynamic resource management is negligible for nearly all workloads.
Get started
E2 VMs were designed to provide sustained performance and the lowest TCO of any VM family in Google Cloud. Together, our unique approach to fleet management, live-migration at scale, and E2’s custom CPU scheduler work behind the scenes to help you maximize your infrastructure investments and lower costs.
E2 complements the other VM families we announced earlier this year—general-purpose (N2) and compute-optimized (C2) VMs. If your applications require high CPU performance for use-cases like gaming, HPC or single-threaded applications, these VM types offer great per-core performance and larger machine sizes.
Delivering performant and cost-efficient compute is our bread and butter. The E2 machine types are now generally available. If you’re ready to get started, check out the E2 docs page and try them out for yourself!



