Google’s open-source solution to DFDL Processing
Carolina Hernandez
Cloud Solution Architect, Google
Usama Ijaz
Strategic Cloud Engineer
The cloud has become the choice for extending and modernizing applications, but there are some situations where the transition is not straightforward, such as migrating applications that access data from a mainframe environment. Migrating the data and the applications at certain points can be outsync. Mechanisms need to be in place during the transition to support interoperability with legacy workloads and access data out of the mainframe. For the latter, the Data Format Description Language (DFDL) which is an open standard modeling language from the Open Grid Forum (OGF), has been used to access data from a mainframe, e.g. IBM Integration Bus.
DFDL uses a model or schema that allows text or binary data to be parsed from its native format and to be presented as an information set out of the mainframe (i.e., logical representation of the data contents, independent of the physical format).
DFDL Processing with IBM App Connect
If we talk about solutions for parsing and processing data described by DFDL, one of the options in the past has been IBM App Connect which allows development of custom solutions via IBM DFDL. The following diagram represents a high-level architecture of DFDL Solution implementation on IBM App Connect:
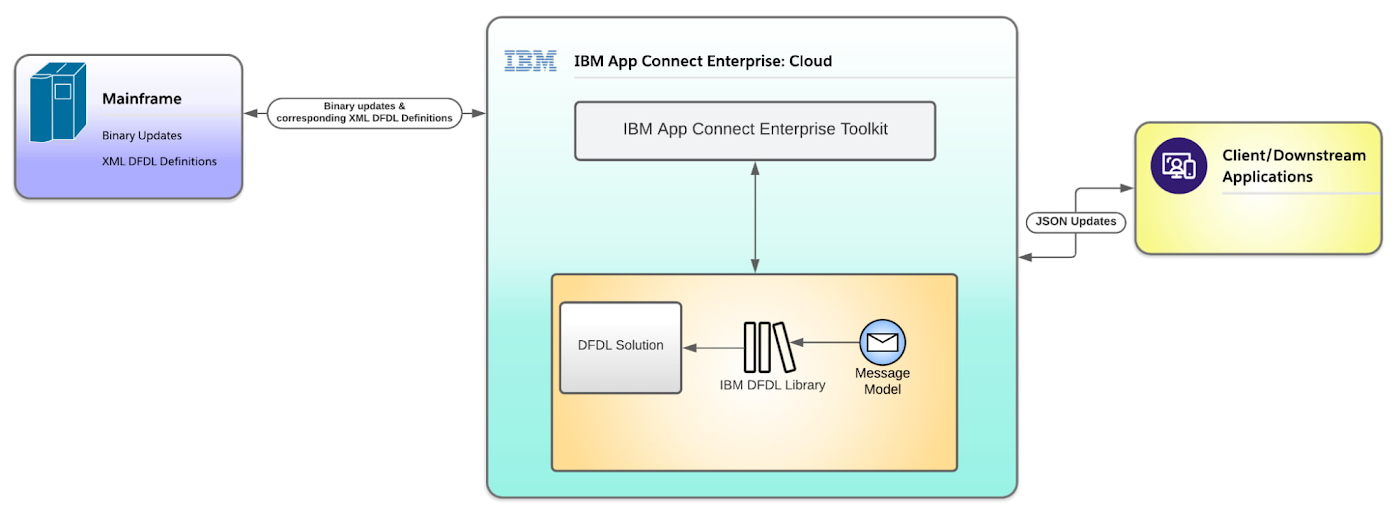
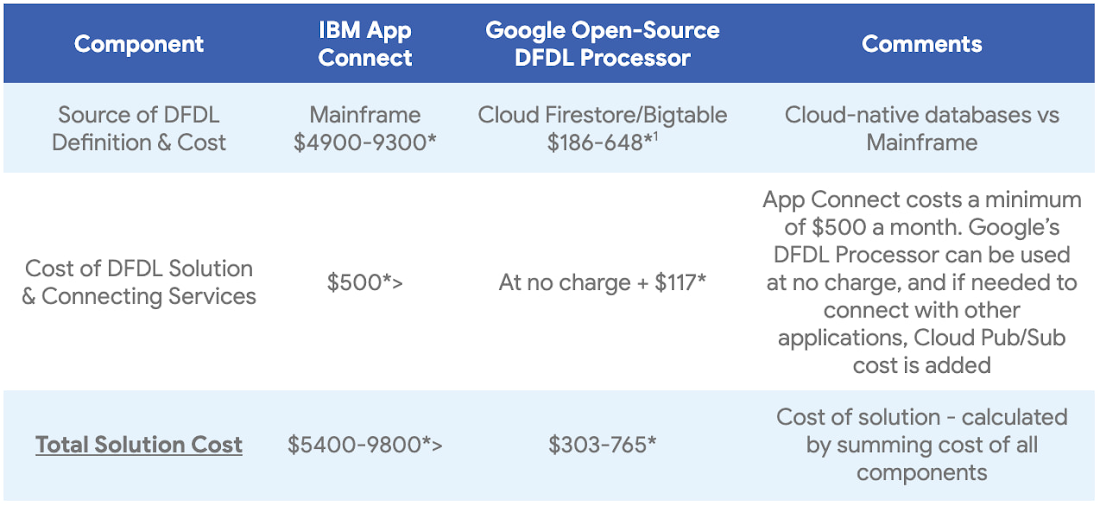
IBM App Connect brings stable integration to the table at an enterprise level cost. According to IBM’s sticker pricing as of May 2022, IBM App Connect charges $500 and above per month for using the App Connect with IBM Cloud services. These prices are excluding the cost of storing and maintaining DFDL Definitions in the Mainframe. With the introduction of Tailored Fit Pricing on IBMz15, cost of maintaining the mainframe can range from $4900 to $9300 per month over the span of 5 years, which may be costly for a small/medium business only wanting to process data defined by DFDL.
Introducing Google Open-Source DFDL Processor with Google Cloud
At Google our mission is to build for everyone, everywhere. With this commitment in mind, the Google Cloud team has developed and open-sourced the solution for DFDL Processor which can be easily accessible and customizable for organizations to use it.
We understand that mainframes can be expensive to maintain and use, which is why we have integrated Cloud Firestore and Bigtable as the databases to store the DFDL definitions. Firestore can provide 100K reads, 25K writes, 100K deletes, and 1TB of storage per month for approximately $186 per month. While on the other hand Bigtable provides a fast, scalable database solution for storing terabytes, or even petabytes of data at a relatively lower cost too. This move away from the mainframe and adopting cloud-native database solutions can save organizations thousands of dollars every month.
Next, we have substituted App Connect with a combination of our open-source DFDL processor, Cloud Pub/Sub service and open-source Apache Daffodil Library. Pub/Sub provides the connection between the mainframe and the processor, and from the processor to the downstream applications. The Daffodil Library helps in compiling schemas, and outputting infosets for the given DFDL definition and message. The total cost of employing the Pub/Sub service and the Daffodil Library comes out to be approximately $117 per month, which means an organization can save a minimum of $380 per month by using this solution.
The table below shows a summary of the cost difference breakdown between the solutions as discussed above:
How it works
The data described by the DFDL usually needs to be available in widely used formats such as JSON, in order to be consumed by downstream applications which might have already been migrated to a cloud native environment. To achieve the consumption of the data, cloud native applications/services can be implemented in conjunction with Google Cloud Services, which accepts the textual or binary data as input from the mainframe , fetches corresponding DFDL from a database, and finally compiles and outputs the equivalent JSON for the downstreaming applications to consume.
The following diagram describes a high level architecture to be presented
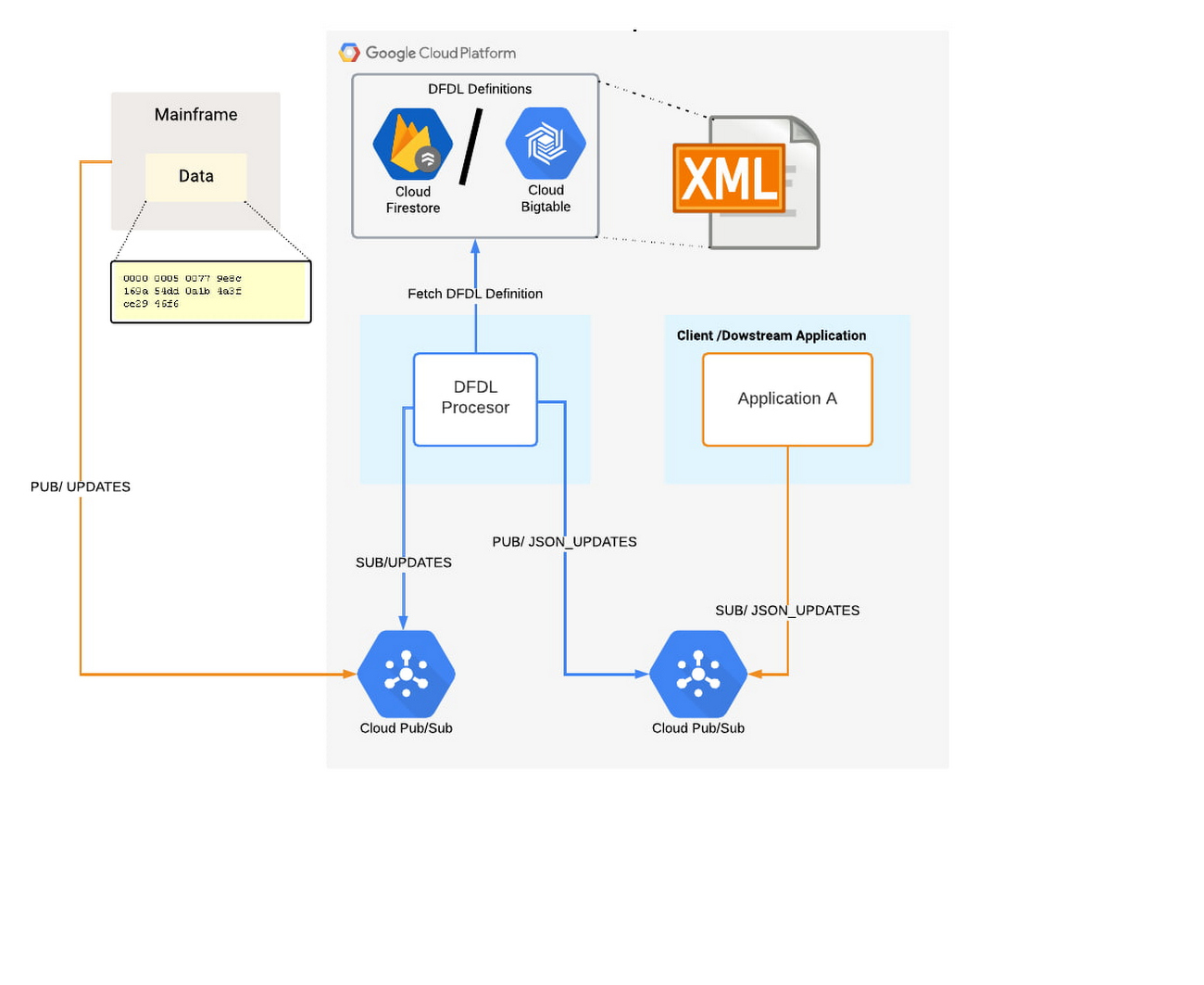
An application can be built to process the information being received from the mainframe, e.g a DFDL Processor Service, leveraging the Daffodil API to parse the data against a corresponding DFDL schema and output the JSON.
DFDL schema definitions can be potentially migrated and stored in Firestore or Bigtable. Since these definitions rarely change and they can be stored in a key-value pair format, the storage of preference is a non-relational managed database.
Google Cloud Pub/Sub, can leverage an eventing mechanism that receives the binary/textual message from a Data Source, i.e. the mainframe, in a Pub/Sub topic. This feature will allow the DFDL Processor to access the data, to retrieve the corresponding DFDL definition from Firestore or Bigtable and finally pass both on to the Daffodil API to compile and output the JSON result. The JSON result is finally published into a resulting Pub/Sub topic for any downstream application to consume. It is recommended to follow CloudEvent schema specification which allows to describe events in common formats, providing interoperability across services platforms and systems.
You can find examples of the implementation in Github:
Conclusion
In this post, we have discussed different pipelines used to process data defined by DFDL, and cost comparisons of these pipelines. Additionally, we have demonstrated how to use Cloud Pub/Sub, Firestore, and Bigtable to create a service which is capable of listening to binary event messages, extract the corresponding DFDL definition from a managed database, and process it to output a JSON which can then be consumed by downstream applications using well-established technologies and libraries.
1. Price comparison analysis as of May 2022 and subject to change based on usage




