Providing scalable, reliable video distribution with Google Kubernetes Engine at AbemaTV
Mr. Junpei Tsuji
Engineer, Development Division, AbemaTV Inc
Mr. Yoshikazu Umino
SRE, Development Division, AbemaTV Inc
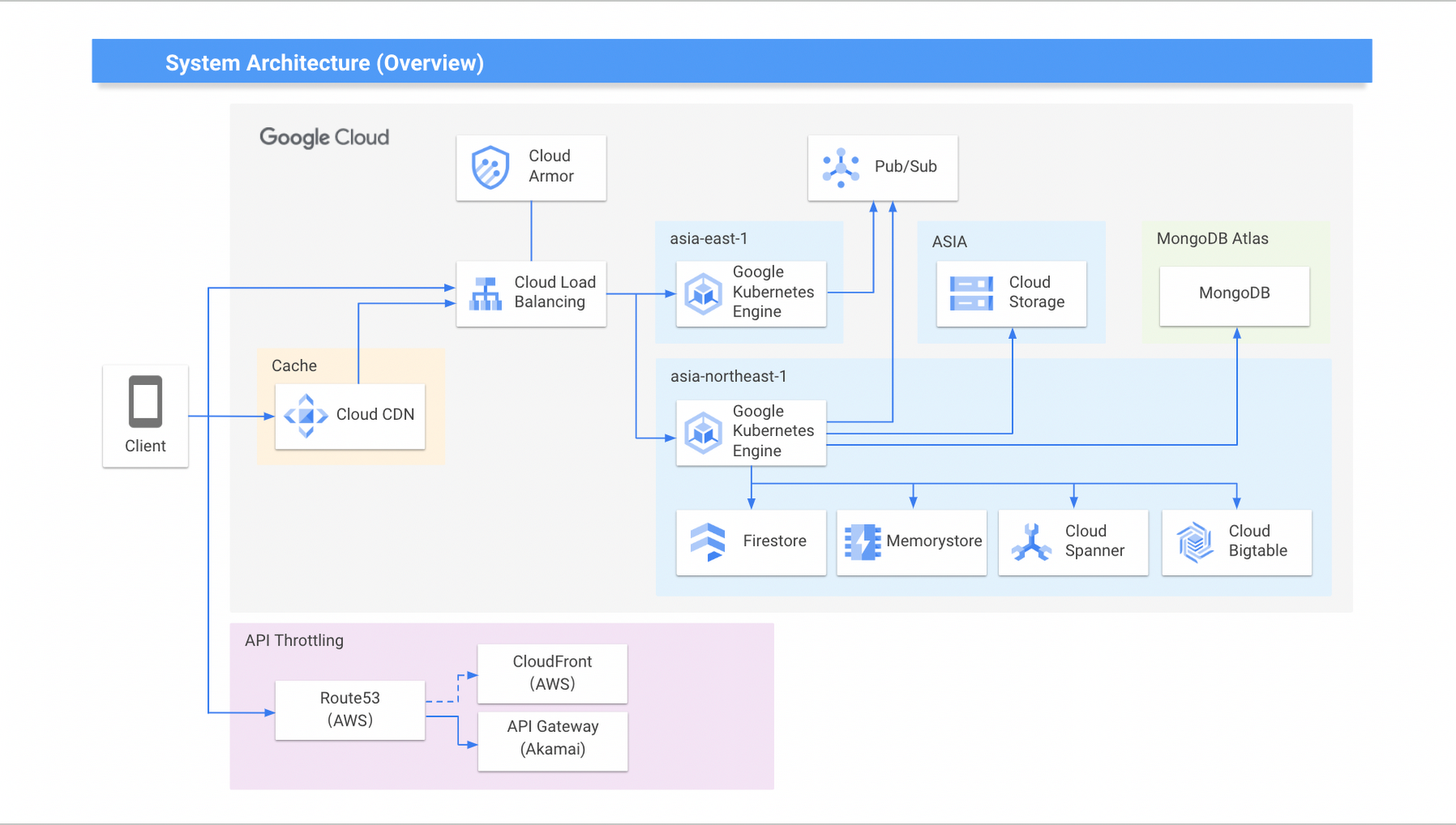
AbemaTV (ABEMA) is a free video streaming service with approximately 25 channels in a variety of genres broadcast 24 hours a day, 365 days a year. Since the start of our operations in 2015, ABEMA has been using Google Cloud as a platform for peripheral services such as video distribution APIs, data analysis, recommendation systems, and ad distribution. As ABEMA's services continue to grow, we needed a platform that could handle higher traffic. This is when we decided to adopt Google Kubernetes Engine (GKE), a managed service that could achieve a high-speed development cycle even on a large scale.
At the time, there weren’t many public use cases of container orchestration, but development using containers was much faster than a normal VM-based development. And as our service continued to expand and network complexities grow, we found that choosing GKE was a good decision. Anthos Service Mesh was also good in helping reduce network complexity.
ABEMA was about to broadcast one of the largest global sporting events, and although the basic existing architecture was fine, we wanted to be prepared for a sudden surge in traffic. We expected to see an unprecedented amount of traffic during the event and needed to make sure we resolved any technical debt and implemented load countermeasures beforehand to make full use of the features of Google Cloud.
For example, with Bigtable, we had been using a single-zone configuration to focus on data consistency, but changed to a multi-zone configuration to maintain consistency using app profiles.
Originally, we had a self-hosted Redis Cluster, but we moved to Memorystore where we reconfigured and divided it into instances per microservices as a countermeasure against latency under high load. MongoDB was similarly divided into instances per microservices. And until then, we had been operating in the Taiwan region, but we also took this opportunity to relocate to the Tokyo region in consideration of latency.
Implementing thorough advance measures
The traffic on the day of the global sporting event was the highest ever for ABEMA, but we were able to provide a stable broadcast of all matches without any major problems. In addition to the aforementioned system upgrades, Google Cloud's PSO team helped us take proactive measures that assured our success.
The first thing we did to manage the load for the day was to estimate the traffic and identify what we called the critical user journey — the 'no stoppages'. We analyzed the access logs from a previously broadcast large-scale martial arts event and used that as a reference to estimate the number of requests we would receive. This was only a rough estimate for reference when creating a test scenario. The full workflow included testing with a sufficiently large load based on the traffic obtained and taking measures to prevent the critical user journey from falling.
In creating the test scenario, we modeled the events that could occur during the game and the users’ behavior in response to them. This was to simulate what kind of phenomena would occur on the system side in response to accesses that fluctuated in real time, and to identify problems. With these test results, we built an infrastructure capacity that was 6 times the normal size.
In an actual broadcast, the traffic fluctuates from moment to moment as the match unfolds. For example, we created scenarios based on user behavior in various situations, such as immediately after the start of a match, at halftime, or when a goal is scored. Based on that, we thought about load measures for critical user journeys and measures against traffic spikes, etc.
The PSO team advised us on capacity planning, reviewed load tests, and proposed failure tests, greatly improving the reliability of our load measures. With only an in-house team, various biases tend to occur, such as missing processes and incorrect prioritization, so it was very helpful to receive candid advice from the PSO team. We asked them to check from the perspective of an expert who knows the content of the product — the internal components of Google Cloud — starting with whether we had made any mistakes in our approach to countermeasures.
For the load test, we used k6, a load-test tool that runs on Kubernetes, and simulated the sequence calls of various APIs leading to the critical user journey based on the test scenario. We repeated the cycle of gradually increasing the number of clients and implementing countermeasures when problems occurred, until we finally achieved the number of simultaneous viewers that was set as the business goal. Specifically, we took measures such as scaling out the database, adding circuit breakers, increasing the number of Kubernetes nodes, and adding the necessary resources. At the same time, two times the number of Weekly Active Users was used for the simulation.
In the failure test, we confirmed the scope of impact and how the behavior of the entire system would change if a component with a particularly high risk was stopped or if access to an external service was cut off.
In principle, it is impossible to intentionally break the cloud, so there was the problem of how to simulate a failure situation. The PSO team advised us on how to set up failure tests and how to intentionally create failure conditions, among other things.
One of the improvement items for load countermeasures they recommended was to introduce Cloud Trace, a distributed tracing system, which proved to be very useful for analyzing problems that occurred during load and failure tests.
With microservices, it can be difficult to identify where a problem is occurring. Cloud Trace helps save a lot of time in identifying the problem, as we were able to keep track of detailed telemetry. Furthermore, some of the issues we uncovered during testing were of a nature that we wouldn't have found without Cloud Trace. As failures tend to occur in a chain reaction, the distributed tracing mechanism was really useful.
Improving the platform for load tests and failure tests
As a result of these preliminary measures, we were able to deliver stable broadcasts from the tournament’s start to finish without any major problems. There were times when requests exceeded the expected maximum number of simultaneous connections. Despite this, thanks to proper planning and utilization of Google Cloud, we served full functionality for all matches.
For the number of concurrent connections, we initially set a goal to ensure full functionality for requests up to half of the target maximum connections, and beyond that, to deliver critical functionality up to the maximum number of target connections. As a result, the system was more stable than expected, and we were able to continue providing all functionality, even though at peak times, the number of simultaneous connections was close to the maximum. We believe that this is the result of eliminating various bottlenecks in advance with the cooperation of the PSO team.
Based on this success, we would like to improve the platform so that we can perform load tests and failure tests continuously at the same level. Complex testing of loosely coupled microservices is extremely time-consuming and imposes a high cognitive load. Building a platform where it could be done continuously would save a lot of time.



