Bringing capacity assurance and faster startup times to Vertex AI Training
Jose Brache
AI/ML Customer Engineer
May Hu
Product Manager
Customers often look for capacity assurance for their critical machine learning (ML) workloads. This is to ensure the capacity is available when they need it, especially during peak seasonal events, like Black Friday/Cyber Monday (BFCM), Super Bowl, Tax Season and other occasions where running freshly trained models is essential. We announced persistent resources at Google Cloud Next '23 as a capacity assurance option for model training in response to customer requests.
In this blog, we explain how you can use persistent resources to ensure compute resource availability and achieve faster startup times to run your critical model training applications.
What are persistent resources?
Vertex AI provides a managed training service which enables you to operationalize large scale model training. You can run your training applications based on any machine learning (ML) framework and also handle more advanced ML workflows like distributed training jobs. These training jobs are ephemeral in nature and when they complete the provisioned virtual machines (VMs) are deleted.
A Vertex AI persistent resource is a long-running cluster you can use to submit multiple Vertex AI Training jobs, and you let the cluster delegate the resources.
When to use persistent resources?
An ideal use case would be to have a persistent resource, with accelerator worker resource pools, you can send similar training jobs and let the cluster delegate the resources. They are recommended in the following scenarios:
- You are already leveraging Vertex AI Training for your custom training jobs.
- You want to ensure capacity availability for scarce resources like GPUs (A100s or H100s).
- You are submitting similar jobs multiple times and can benefit from data and image caching by running the jobs on the same persistent resource.
- CPU or GPU based jobs types are short-lived where the actual training is shorter than the job startup time.
If you have a critical ML workload, during peak seasonal events you may need to ensure GPU accelerator availability, like having the highly demanded A100s, or newly released H100 GPUs. Unlike ephemeral training jobs submitted to Vertex AI Training, VMs in a persistent resource remain available so you can submit your training jobs to the cluster and utilize the available worker resource pools.
Why should I use persistent resources?
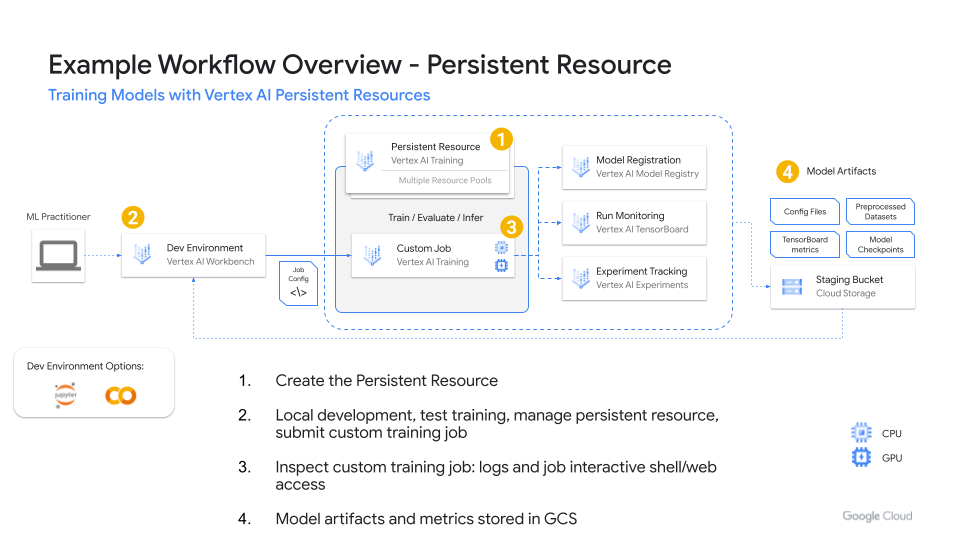
Figure 1. Example workflow
An example workflow for using a Vertex AI persistent resource interactively is shown on Figure 1. Once a persistent resource is created, multiple users can leverage the same persistent resource to submit their training jobs. If the persistent resource is set up for auto-scaling, it can auto-expand to pull in more resources.
When submitting a custom training job, startup times can be 5 - 10 minutes or more. You can save time with persistent resources to run similar custom training jobs if they have been cached from previous runs.
You can also ensure you have capacity available using a minimum replica amount so that between training jobs don’t run into situations where you’re unable to run your critical ML workloads due to a resource stockout.
Where can I try this out?
If you are interested in seeing an example leveraging persistent resources for Vertex AI Training, inspect this sample: Persistent Resource Getting Started which goes through the process end to end from creation to deletion. Stay tuned for Part 2 where we will cover using persistent resources for distributed training with Dask.



