Train and deploy state-of-the-art mobile image classification models via Cloud TPU

Hongkun Yu
Software Engineers, Google Brain
Mingxing Tan
Software Engineers, Google Brain
As organizations use machine learning (ML) more frequently in mobile and embedded devices, training and deploying small, fast, and accurate machine learning models becomes increasingly important. To help accelerate this process, we’ve published open-source Cloud TPU models to enable you and your data science team to train state-of-the-art mobile image classification models faster and at a lower cost.
For many IoT-focused businesses, it’s also essential to optimize both latency and accuracy, especially on low power, resource-constrained devices. By leveraging a novel, platform-aware neural architecture search framework (MnasNet), we identified a model architecture that can outperform the previous state-of-the-art MobileNetV1 and MobileNetV2 models that were carefully built by hand. You can find a comparison between MnasNet and MobileNetV2 below:
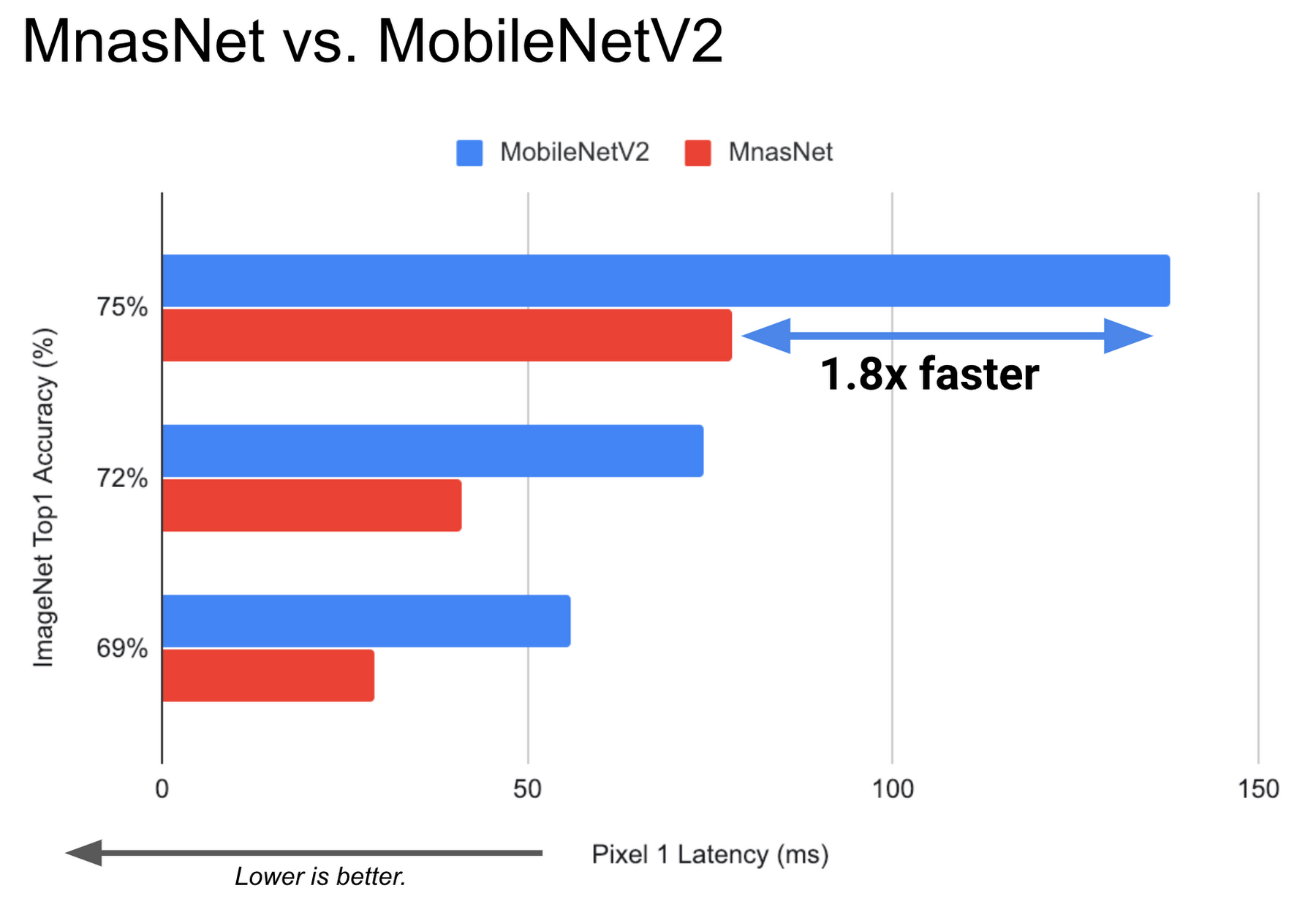
This new MnasNet model runs nearly 1.8x faster inference speed (or 55% less latency) than the corresponding MobileNetV2 model and still maintains the same ImageNet top-1 classification accuracy.
How to train MnasNet on Cloud TPU
We specifically designed and optimized MNasNet to train as fast as we could make it on Cloud TPUs. The MnasNet model training source code is now the latest available in the TensorFlow TPU GitHub repository. Using this code, you can benefit from both low training cost and fast inference speed when you train MnasNet on Cloud TPUs and export the trained model for deployment.
If you have not yet experimented with training models on Cloud TPUs, you might want to begin by following the QuickStart guide. Once you are up and running with Cloud TPUs, you can begin training an MnasNet model by executing a command of this form:
The model processes training data in TFRecord format, which can be created from input image collections via TensorFlow’s Apache Beam pipeline tool. You can find more details on how to use Cloud TPUs to train MnasNet in our tutorial.
To help you further tune your MnasNet model, we have published additional notes about our implementation along with a variety of suggested tuning parameters to accommodate different classification latency requirements.
How you can deploy via SavedModel or TensorFlow Lite
You can easily deploy the models trained on Cloud TPUs to a variety of different platforms and devices. We have published pre-trained SavedModel files (mnasnet-a1 and mnasnet-b1) from ImageNet training runs to help you get started: you can use this MnasNet Colab to experiment with these pre-trained models interactively.
*.tflite file with the following code:Next, you can optionally apply post-training quantization, a common technique that reduces the model size while also providing up to 3x lower latency. These improvements are a result of smaller word sizes that enable faster computation and more efficient memory usage. To quantize 32-bit floating point numbers into more efficient 8-bit integers, add the following code:
The open-source implementation provided in the Cloud TPU repository implements saved model export, TensorFlow Lite export, and TensorFlow Lite’s post-training quantization by default. The code also includes a default serving input function that decodes and classifies JPEG images: if your application requires custom input preprocessing, you should consider modifying this example to perform your own input preprocessing (for serving or for on-device deployment via TensorFlow Lite).
With this new open source MnasNet implementation for Cloud TPU, it is easier and faster to train a state-of-the-art image classification model with full control and deploy it on mobile and embedded devices. Check out our tutorial and Colab to get started.
Acknowledgements
Many thanks to the Googlers who contributed to this post, including Zak Stone, Xiaodan Song, David Shevitz, Barrett Williams, Russell Power, Adam Kerin, and Quoc Le.



