Domain-specific AI apps: A three-step design pattern for specializing LLMs
Arsalan Mosenia
AI Lead at Google and Member of Faculty at NYU
The world of AI has undergone a transformation with the rise of large language models (LLMs). These advanced models, often regarded as the zenith of current natural language processing (NLP) innovations, excel at crafting human-like text for a wide array of domains. A trend gaining traction is the tailoring of LLMs for specific fields — imagine chatbots exclusively for lawyers, for instance, or solely for medical experts.
This article embarks on a journey through the key advantages of domain-specific LLMs. Along the way, we'll dissect three pivotal techniques for their specialization: prompt engineering, retrieval augmented generation (RAG), and fine-tuning. And to tie these technicalities into a relatable narrative, I introduce what I fondly term the “student analogy.” Let’s dive in!
Key benefits of LLMs customized to your domain
Domain-specific LLMs bring several distinct advantages:
- Precision and expertise: By fine-tuning on or grounding in datasets from specialized domains, such as law or medicine, LLMs yield results that are not just accurate but also deeply relevant, capturing the nuances of the domain far better than their generic counterparts.
- Enhanced reliability: With a narrowed focus, these models are less susceptible to external and irrelevant information, ensuring more consistent and reliable outputs.
- Safety and liability: Domains like healthcare and law come with heightened stakes. A misinformed output can be detrimental. Domain-specific LLMs, often embedded with additional safety mechanisms, can deliver more trustworthy insights.
- Improved user experience: Engaging with a model that speaks the domain's language — able to understand its specific jargon and context — leads to a more gratifying user interaction.
- Model efficiency: Instead of relying on a massive general-purpose model, it's often more efficient to fine-tune a smaller model on a domain-specific dataset. This smaller model can offer higher quality outputs at a significantly lower cost.
In summary, while general-purpose LLMs are versatile and can handle a wide range of tasks, LLMs customized to your domain cater to the unique demands and intricacies of particular fields, ensuring more accurate, reliable, and efficient outputs. They bridge the gap between broad general knowledge and deep specialized expertise.
Tailoring LLMs for domain specificity
We've established the significance of domain-specific LLMs. In this section, we delve into a three-step guide to craft specialized LLMs. The figure below provides an overview of these techniques, which we will discuss in more detail.

Prompt engineering, RAG, and fine-tuning can offer a three-step approach for building domain-specific LLMs.
Step 1: Prompt engineering
Prompt engineering is the quickest way to extract domain-specific knowledge from a generic LLM without modifying its architecture or undergoing retraining. This technique involves crafting questions or prompts that guide the model to generate outputs tailored to a specific domain. For instance, we may instruct a general model to "Always provide a short answer using medical terms.” This specificity guides the model to offer a short response and use medical jargon in its response.
You can refer to the “Introduction to prompt design” documentation guide to learn about how to create prompts that elicit the desired response from language models provided by Vertex AI on Google Cloud.
Step 2: RAG (retrieval augmented generation)
RAG merges the strengths of information retrieval and LLMs. By connecting to an external knowledge source, such as a database of documents, the LLM can fetch pertinent information to form its responses. This is especially valuable for producing explainable and accurate answers, as it allows the model to access real-time or specialized facts that might be beyond its original training data. For instance, in crafting a medical chatbot, RAG allows the LLM to access a database containing up-to-date medical journals, research papers, and clinical guidelines. As a result, when a user inquires about the latest treatment for a specific condition, the LLM can retrieve and integrate current data from this database to offer a comprehensive answer, grounded in the most up-to-date medical knowledge.
Google’s Vertex AI Search is a fully managed end-to-end RAG search pipeline, empowering users to create AI-enabled search experiences for both public and internal websites. In addition, Vertex AI Vector Search , formerly known as the Vertex AI Matching Engine, offers a vector database that seamlessly integrates with your own LLM, enabling the development of RAG-based question-answering chatbots, as elaborated in this article.
It is essential to note that although building a RAG prototype is relatively simple, the development of a production-level RAG system entails considerable complexity. This process often requires iterative quality improvements and necessitates making complex design decisions, such as selecting appropriate embeddings, choosing the most suitable vector database, and determining the most effective chunking algorithms.
For those looking to dive deeper into the nuances of RAG technology, I recommend exploring the insights shared in the Medium article titled "Advanced RAG Techniques: an Illustrated Overview," and the detailed discussions found in this Google Cloud blog post "Your RAGs powered by Google Search technology." These resources shed light on the complexities and critical design decisions that are fundamental to the development of advanced RAG systems.
Step 3: Fine-tuning
Fine-tuning allows you to specialize a pre-trained LLM like PaLM 2 for Text (text-bison) on Vertex AI (Gemini support coming soon). This involves training the model on a smaller, domain-specific dataset. As a result, the model becomes inherently more adept in that particular area. For instance, fine-tuning an LLM already equipped with RAG for medical knowledge improves its understanding of medical topics. This allows the model to provide more accurate and informative responses, as RAG supplies relevant medical knowledge while fine-tuning ensures the response is expressed using appropriate medical terminology and phrasing.
You can refer to tuning language foundational models on Vertex AI for more information about how to tune a model on Google Cloud.
Note: The sequence of these approaches represents a recommended way of tailoring LLMs, but it isn't a strict progression. Each technique can be used independently, and its adoption should align with your project's needs. You might choose to use any of these steps individually, in combination, or omit some entirely. For a deeper understanding, the following section offers a detailed comparison of each technique.
Comparing prompt engineering, RAG, and fine-tuning
The table below shows a side-by-side comparison of the key benefits of prompt engineering, RAG, and fine-tuning.
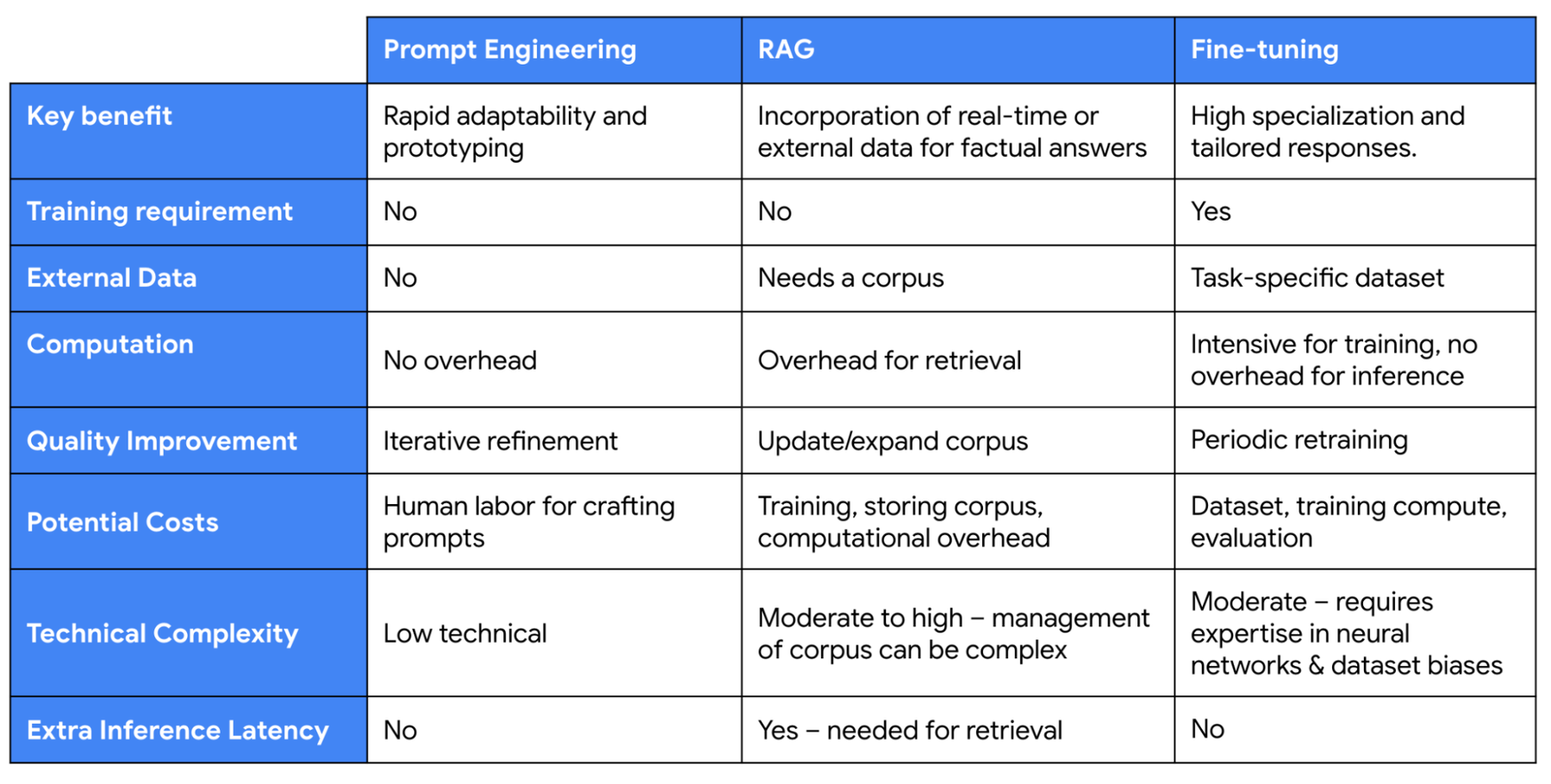
Comparison of prompt engineering, RAG, and fine-tuning
Here’s an analogy that can help to further elucidate the differences between the concepts of prompt engineering, RAG, and fine-tuning.
Think of an LLM as a student from a non-English speaking background who is interested in learning the language. Training the LLM from scratch on a large corpus of data is akin to immersing the student in a vast library filled with books, articles, and web pages. Through this immersion, the student grasps the syntax, semantics, and common phrases, and as a result, can respond well to high-level questions. However, they might not fully comprehend specific technical jargon or domain-specific knowledge.
Prompt engineering, RAG, and fine-tuning in turn can prepare the student for domain-specific questions as described below.
Prompt engineering: Think of this as giving the student a set of instructions to guide their responses. For instance, we might instruct them to "Always provide a comprehensive answer using a professional tone when addressing the following question." The student can tailor their response; however, their domain knowledge is unchanged.
RAG: Here, we provide the student with a domain-specific book and then conduct an open-book exam. During the test, the student is allowed to skim through the book to retrieve relevant information for each question. The student can double check their response and make sure that the final response is factual, as well as citing the section that they used in their response.
Fine-tuning: In this phase, we hand the student a domain-specific book and ask them to study it in depth, preparing for a closed-book exam. Once the exam begins, the student cannot consult the book and must rely solely on what they've internalized from their study. In this case, the student can respond to the questions well. However, unlike the previous case, they may mistakenly offer incorrect answers and may not be able to provide accurate references.
For rapid prototyping and deployment, we recommend getting started with prompt engineering. It requires minimal resources and offers the most immediate improvements. Once you're ready for a more extensive setup, you can integrate RAG for real-time, up-to-date information retrieval. Lastly, you can invest in fine-tuning when you have a sufficiently large and diverse dataset at hand.



