Your RAGs powered by Google Search technology, part 2
Kaz Sato
Developer Advocate, Cloud AI
Guangsha Shi
Senior Product Manager, Google Cloud
In the first post of this series, we explored the concept of retrieval augmented generation (RAG) and how the same technologies that power Google Search can greatly enhance the effectiveness of the information retrieval capabilities of a RAG system. In this follow-up post, we will now take a deeper look at the other critical technologies that are essential for building a successful RAG system to help ground large language models (LLM) when building applications.
Deep re-ranking with Google signals
Approximate nearest neighbors (ANN) algorithms like ScaNN are proficient at quickly retrieving results in semantic search, but they are not as strong at scoring and ordering them precisely. Anyone who has ever used Google Search knows how important it is for the top results to be the most relevant to our queries and carefully sorted by relevance.
That's why modern semantic search engines use a two-stage retrieval approach to generate results. First, they use an ANN retriever to do a quick first pass and bring up results, and then apply a re-ranking model to fine-tune the results and make sure the most relevant ones are at the top — all in milliseconds. This same approach also applies in RAG systems to provide production-quality search.
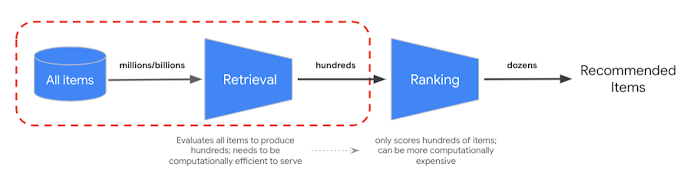
The two staged retrieval approach
(from Scaling deep retrieval with TensorFlow Recommenders and Vertex AI Matching Engine)
For example, Google Search provides an advanced ranking system that looks at dozens of signals to determine the final ranking of results for every single query. Using deep learning models in its ranking system, RankBrain, Google Search can understand the relevance between queries and documents and re-rank the results with the signals from those models to optimize the user experience.
Vertex AI Search leverages the same cutting-edge technologies and unique ranking signals available in Google Search to combine results from embedding-based and keyword-based retrieval and power its advanced re-ranking model specifically designed for enterprise needs. As a result, there is no need for developers to spend precious time or additional resources on LLMs for re-ranking results.
Furthermore, while Vertex AI Search has already fine-tuned the retrieval and ranking models using Google's proprietary data, customers can further enhance these models with their own data to better align them with their specific business use cases and data characteristics.
Filtering and boosting
Filtering and boosting search results is one of the most common business needs for search capabilities. Similarly, a RAG system also requires the ability to filter and boost results when retrieving information. For instance, a streaming service typically prefers to highlight premium content while avoiding the display of content that is no longer available. Likewise, a healthcare directory often prioritizes highly-rated providers and filters out those who are not accepting new patients.
Vertex AI Search provides a flexible filter expression syntax to meet these filtering and boosting requirements for both search and information retrieval engines. This syntax enables developers to define complex business logic, providing precise and dynamic control over search results with associated metadata. In addition, Vertex AI Search makes it easy to reduce the presence of irrelevant content in search results and enhance search precision, automatically extracting filters from natural language queries to align with metadata fields, such as category and price.
Extraction and generation
Once you have the re-ranked and filtered list of relevant documents, you might consider extracting the sections that best capture the essence of each document in relation to the query, for use as input for LLMs for answer generation or summarization. Otherwise, the results may contain too much content and too much extra noise.
Below, we’ll discuss these technologies in further detail.
Smart content extraction
Vertex AI Search provides multiple ways to extract highly relevant content from documents, helping to surface and isolate the most valuable information for an LLM from the sources. With this functionality, a RAG system can provide a spot-on answer to a query rather than generating results from an entire document that might include a lot of irrelevant, unnecessary information.
Each search result may contain the following types of content:
- Snippet: A brief text extract from search result documents, providing a preview of a result’s content. Snippets are displayed below each result, similar to snippets in Google Search, and help users assess the relevance and usefulness of that result.
- Extractive answer: A verbatim text extract from the original document, similar to Google Search Featured Snippets, typically positioned at the top of pages to offer concise, contextually relevant answers to user queries.
- Extractive segments: A more detailed verbatim text extract from a document to provide more context for LLMs than an extractive answer. Extractive segments can be further processed or used as input for an LLM for various tasks, including, question answering, content summarization, or a conversation where the text extract relevant to the query is added with the context around it.
Let’s take a look at an example of each type of extracted content for the following query “What is Vertex AI Search and Conversation?”:
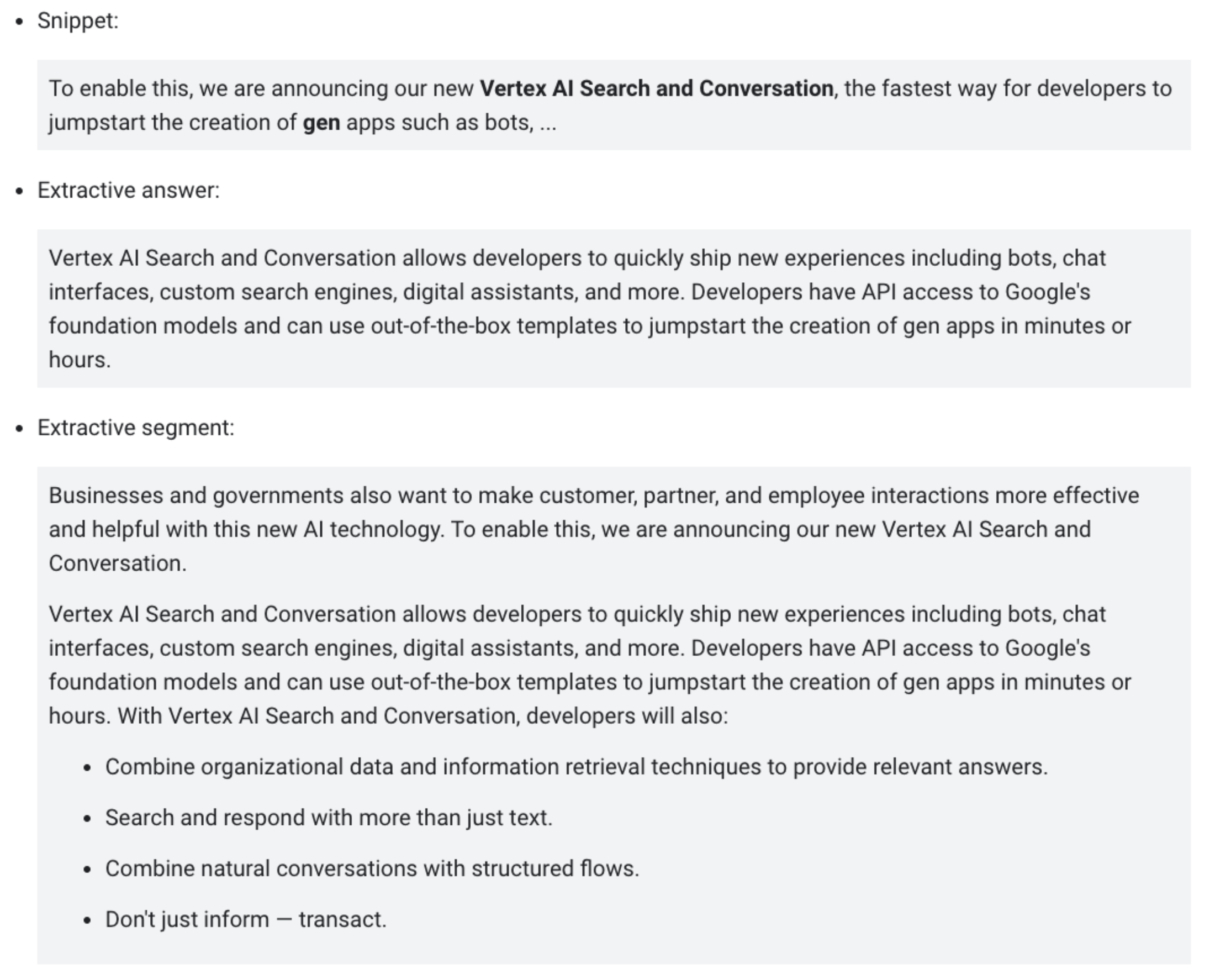
Snippet, Extractive answer, and Extractive Segment with Vertex AI Search
For even deeper customization, Vertex AI Search can pull extractive segments from a result document according to specific business requirements. For instance, a customer can adjust the number of segments to extract from each document, incorporate adjacent segments for extra context, and even select top segments or filter out less relevant ones based on segment relevant scores. These options are particularly useful for improving the performance of your RAG systems as you can extract the most important part of the documents to the LLM, so it can generate highly relevant and reliable outputs.
Summarization and multi-turn search
If the primary use case for your RAG system is to simply summarize the search results or provide a chatbot-style context-aware search interface, then you don't even have to build a RAG system at all. Vertex AI Search comes with built-in LLMs that specialize in generating search result summaries and also supports follow-up questions with multi-turn search to provide a context-aware search.
These built-in LLMs are fine-tuned to work seamlessly with the extracted content, ensuring the creation of precise, well-grounded answers with citations. The following is an example response to the query "What are the benefits of BigQuery?"

Summarization with citations
Furthermore, you have the flexibility to customize summarization and perform multi-turn search to your specific needs, such as specifying a condition that triggers generating a response and defining a preamble to make prompts more effective. Preambles serve to influence the nature of the response by providing additional context or instructions to the LLMs.
For instance, you can include a preamble in a prompt like "explain like you would to a ten year old" or "give a very detailed answer." The following is an example response to the same query used to generate the response above but with a preamble "please show the answer format in an ordered list" added.

Summarization with a customization instruction
Using a built-in LLM from Vertex AI Search to summarize and enable multi-turn search is a quick way to introduce the power of large models into your enterprise systems, rather than building your own RAG system from scratch.
Google-quality document processing
Another challenge when developing a gen AI application for tasks like question answering, content summarization, or conversation with proprietary enterprise data is effectively handling documents in various formats and lengths.
Before performing retrieval and ranking, it's essential to understand the structure of each document and properly process them, making large volumes of textual information accessible and manageable for the retrieval and generation components of your RAG system.
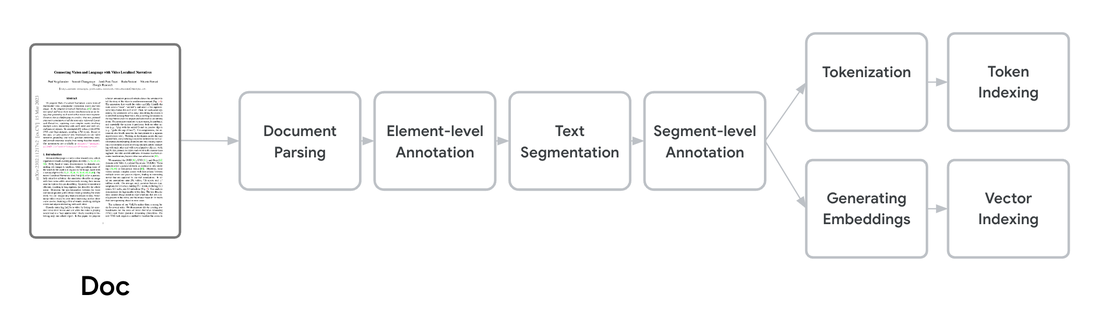
Document processing in Vertex AI Search
Document understanding and text chunking
Vertex AI Search goes beyond only extracting text from documents. It also identifies structural and content elements, including titles, section headings, paragraphs, and tables, which define the organization and hierarchy of a wide variety of documents. This information is used to intelligently segment the document objects into smaller, retrievable segments (chunks), preserving the coherence of semantic elements while minimizing noise. This segmentation is more effective than the widely-used simple text chunking, which often fails to maintain semantic coherence.
Additionally, Vertex AI Search can extract information from each segment as annotations to enhance the search experience. The document segments are tokenized and embedded to create indexes for retrieval and ranking.
Once Vertex AI Search has identified the relevant document segments through retrieval and ranking, it can further process their content or use them as input for generating responses, resulting in higher quality and more relevant generated output.
Document and query annotation with Knowledge Graph
As we covered in our previous post, keyword search uses keywords to find relevant information while semantic search looks at similarity in the meaning of content. Knowledge Graph finds information by using the graph relationship between entities. Using Knowledge Graph can be more beneficial when you want to extract entities and their relationships from text, helping to create structure from text. This approach is similar to embeddings, except the result is structured as a graph, making it easier for humans to comprehend it. As a result, Knowledge Graph is another promising option for retrieving information in RAG systems.
At Google, we have been utilizing Knowledge Graph in Google Search since 2012, helping add more context to search queries by providing information about things, people, or places that Google already knows about. Google Search leverages Knowledge Graph to tap into its existing intelligence and understanding of the web to find and return results related to a user’s search query, such as landmarks, celebrities, cities, geographical features, movies, and more.
Knowledge Graph is also integrated with Vertex AI Search to enhance its search capabilities including web and media search. When documents and queries are processed or summarized, Vertex AI Search will also automatically identify relevant entities with Knowledge Graph and add it to any annotations.
For instance, imagine your document or query contains the keyword "Buffett," and it is highly probable that the keyword refers to Warren Buffett. Vertex AI Search will automatically annotate documents with additional information about him from the Google Search Knowledge Graph and add related Buffettt keywords to the original query. This increases the likelihood of retrieving this document with other keywords or topics related to him.
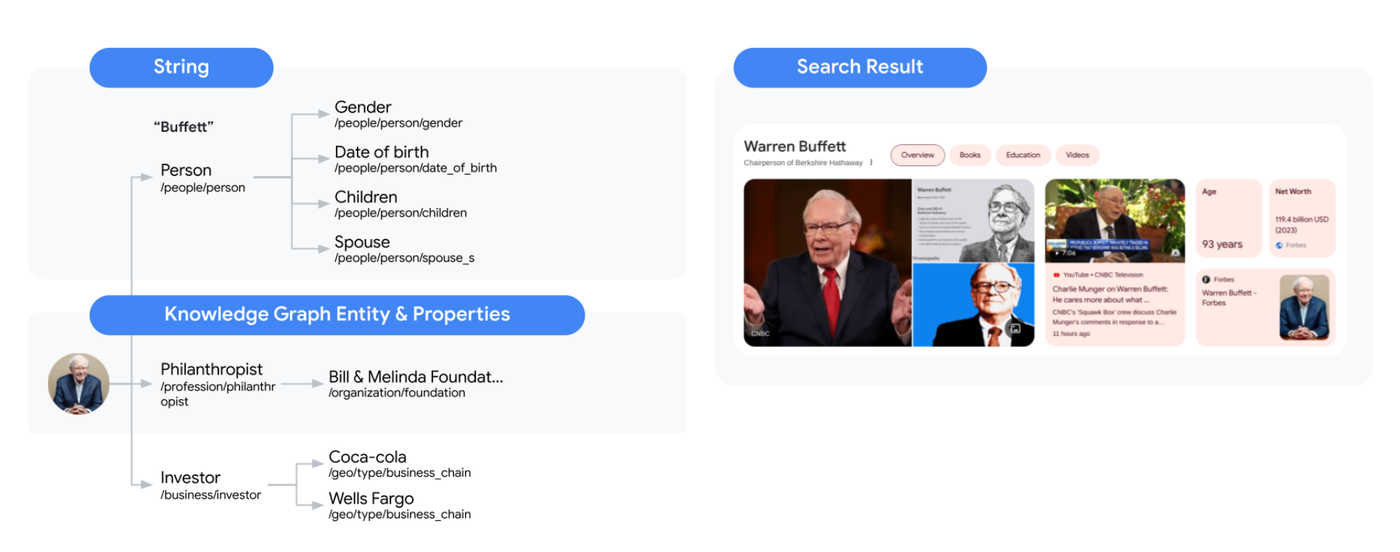
Document and query annotation with Knowledge Graph relationships
Collect scattered enterprise data
While supporting a wide range of enterprise data sources with a single search engine may not seem like the most exciting or widely discussed topic, it’s a significant challenge that will need to be addressed — especially as LLMs and RAG systems get implemented into existing production applications and users discover the value they bring. More and more, you’ll likely encounter questions like: “Can I search documents across our databases, file servers, and web pages?” or “Will my search results also include documents from Google Drive, Salesforce, and Confluence?”.
Here are some of the ways Vertex AI Search can make it easier to bring these capabilities to real-word services.
Blended Search and web crawling
One recent accomplishment with Vertex AI Search is Blended Search, which allows you to run a single query across all your data, including:
- Structured data, such as tables imported from BigQuery, databases, CSV, JSON, etc.
- Unstructured data like PDFs or web page content imported from storage
- Public website content
This means you don't have to issue queries on multiple search indexes for each data type and then integrate them. Instead, you can run a single query across different systems and data sources simultaneously and get merged results back from all of them.
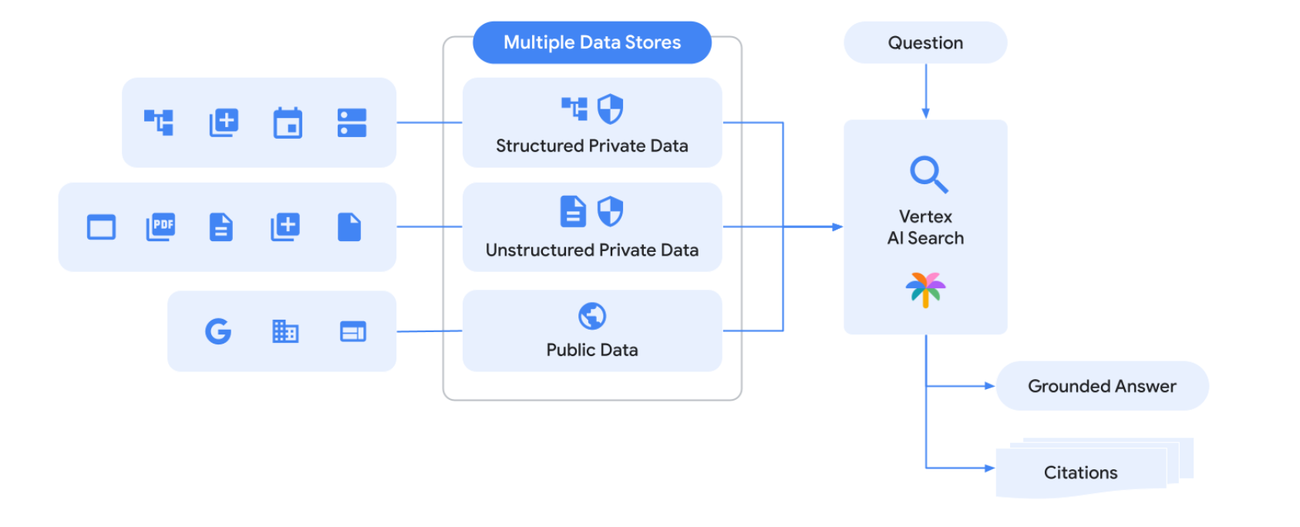
Blended Search in Vertex AI Search
Vertex AI Search also enables you to crawl all your company’s websites and easily generate a website index that you can easily search with advanced website indexing. All you have to do is specify the URL or URL pattern and Vertex AI Search will instantly create a data store with all the relevant website pages. You can then use Google Search Central, to manage site crawling on your website.
Connectors
In addition to supporting and enabling search across various datasets, Vertex AI Search also offers a wide variety of Connectors for popular third-party data sources, including:
Available as Private Preview:
- Jira
- Salesforce
- Confluence
Features under development:
- Google Drive
- Microsoft SharePoint and OneDrive
- Slack
- Box
- DropBox
- ServiceNow
When paired with an RAG system, Vertex AI Search Connectors can quickly grab valuable information stored in various data stores scattered throughout the enterprise and across the web. Then, they use the human-level intelligence of LLM to digest the information, summarize and serve it to users in a way that is easy to understand and use.
Everything is fully managed
Now you might be thinking, "This is a lot to take on." And if you plan to build a RAG system from scratch — you’re right. Implementing advanced search technologies that could reproduce search quality comparable to Google Search, whether you’re using them for gen AI apps or not, would take years of development and hiring a host of data scientists and engineers with specialized skills in ML, search engines, DevOps, and MLOps.
We believe that developers should be able to focus on utilizing the power of LLMs and RAGs to solve business-specific problems, instead of trying to solve the same problems that Google has been working on for the past 25+ years. That’s why Vertex AI Search shares most of its technology and infrastructure with Google Search, which is operated 24x7 for billions of users by our top-notch SRE team. You don't need to worry about managing any server instances or containers because there are none. Everything is packaged as an out-of-the-box, fully managed serverless service — just like BigQuery.
Building RAG systems with Vertex AI Search
In this article, we have seen the benefits of using Vertex AI Search as an information retrieval engine in a RAG system. Even for developers who do not have any experience on building a RAG system, Vertex AI Search provides a great foundation to get started faster with new gen AI technologies.
For more information about how to build your own RAG systems with Vertex AI search, we recommend explore the following resources:
- LangChain-based samples and documents: RAG sample notebooks using Vertex AI Search, PaLM, and LangChain and Vertex AI Search support in LangChain
- Grounding in Vertex AI: provides a quick and easy way for grounding
- Check Grounding API provides a grounding score for an answer candidate
- Vertex AI Conversation-based grounding: Vertex AI Search and Conversation: search with follow-ups
- How to use custom embedding with Vertex AI Search
- Vertex AI Search and Conversation product page
- Get started with Vertex AI Search
- Vertex AI Search sample notebooks on GitHub Gen AI repo
- Video: Harnessing the power of generative AI to deliver next-gen search experiences




