Pre-processing for TensorFlow pipelines with tf.Transform on Google Cloud

Matthias Feys
Chief Technology Officer, ML6
Machine learning models need data to train, but often this data needs to be preprocessed in order to be useful in training a model. This preprocessing, often referred to as “feature engineering,” takes a variety of forms such as: normalizing and scaling data, encoding categorical values as numerical values, forming vocabularies, and binning of continuous numerical values.
When using machine learning in production, it can often be a challenge to ensure that the feature engineering steps applied during offline training of a model are identical to the feature engineering steps applied when the model is used to serve predictions. Moreover, in today’s world, machine learning models are trained on very large data sets, and hence the pre-processing steps applied during training are implemented on large-scale distributed computing frameworks (such as Google Cloud Dataflow or Apache Spark). Thus, the training environment is often very different from the serving environment, possibly creating inconsistency between the feature engineering performed during training and serving.
Luckily, we now have tf.Transform, a library for TensorFlow that provides an elegant solution to ensure consistency of the feature engineering steps during training and serving. In this blog post we will provide a concrete example of using tf.Transform on Google Cloud Dataflow, along with model training and serving on Cloud ML Engine.
Transforms applied to a machine simulation use case
ecc.ai is a platform that helps optimize machine configurations. We simulate physical machines (e.g. a bottle filler or a cookie machine) to find more optimal parameter settings. Since the goal of each simulated physical machine is to have the same input/output characteristics as the actual machine, we call this the "digital twin".
This blog post will describe the design and implementation process for this “digital twin”. In the last paragraph you can find more info on how we subsequently use these digital twins to optimize machine configurations.
tf.Transform explained
tf.Transform is a library for TensorFlow that allows users to define preprocessing pipelines and run these using large scale data processing frameworks, while also exporting the pipeline in a way that can be run as part of a TensorFlow graph. Users define a pipeline by composing modular Python functions, which tf.Transform then executes with Apache Beam. The TensorFlow graph exported by tf.Transform enables the preprocessing steps to be replicated when the trained model is used to make predictions, such as when serving the model with TensorFlow Serving.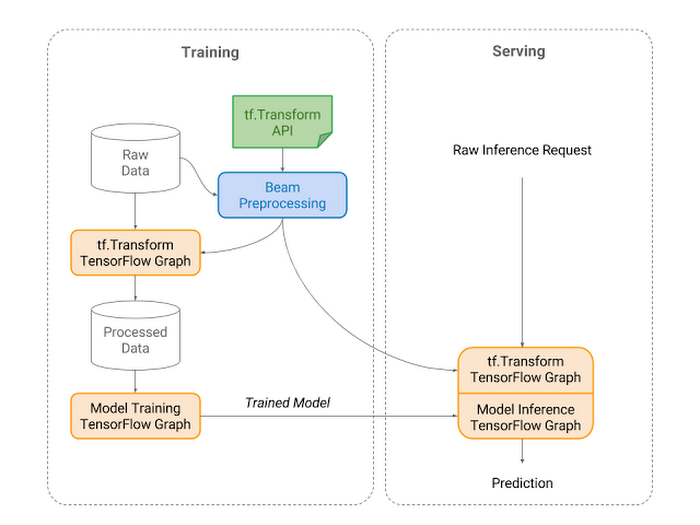
tf.Transform for building digital twins
The goal of the digital twin model is to be able to predict all the output parameters of the machine, based on its inputs. To train this model, we analyze the log data that contains an observed, recorded history of this relationship. Since the amount of log data can be quite extensive, one should ideally run this step in a distributed manner. Furthermore, one has to use the same concepts and code between training and serving time with minimal changes to the preprocessing code.
This functionality is something that we didn’t find in any existing open source project when we started our development. Accordingly, we started to build our custom tools for the preprocessing on Apache Beam, which allowed us to distribute our workload and easily switch between multiple machines. Unfortunately, this approach didn’t allow us to reuse the same code to be run as part of a TensorFlow graph at serving time (i.e. when using the trained model in the production environment).
In practice, we had to write custom analysis steps in Apache Beam that calculated and saved the required metadata for each variable to do the actual preprocessing in a follow-up step. We executed subsequent preprocessing step with Apache Beam during training, and as part of the API during serving. Unfortunately, since it wasn’t part of the TensorFlow graph, we couldn’t simply use ML Engine to deploy our models as APIs and our APIs always consisted of a preprocessing part and a model part, which makes it harder to do unified upgrades. Furthermore, we needed to implement and maintain the analysis and transforms steps ourselves for every existing and new transformation that we wanted to use.
TensorFlow Transform solves these issues. Since its announcement, we integrated it directly as a main building block of our complete pipeline.
Simplified digital twin example flow
We will now focus on building and using a digital twin of a specific machine. As an example, we will turn to a hypothetical brownie dough machine. This machine takes different raw components, and then heats and mixes them until a perfect texture arises. We will start with a batch problem, which means that the data is summarized over a complete production batch, rather than in a continuous stream.
The data
We have 2 types of data:
- Input data: description of the raw materials (green) and the settings of the brownie dough machine (blue). Below you can find the column names and 3 example rows.

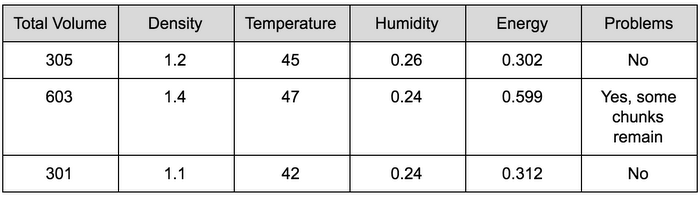
- Output data: the results of the settings of the machine with these raw materials: energy consumed, quality metrics of the output, and volume of the output. Below you can find the column names and 3 example rows.
Making the digital twin

Here we train the digital twin of the system based on historical log data stored as two different types of files in Cloud Storage. This digital twin will be able to predict the output data based on the input data. The figure above illustrates which Google Services we use for this process.
Preprocessing
The preprocessing (making training examples) will be done with Apache Beam using tf.Transform functions.
The preprocessing stage consists of 4 steps illustrated with code below:
1. Combining the input/output data and make the raw data PCollection.2. Define the preprocessing function that will preprocess the raw data. This function will combine multiple TF-Transform functions to make the Examples for the TensorFlow Estimators.
3. Analyze and Transform the complete dataset using the preprocessing function.This part of the code will take the preprocessing function and first Analyze the dataset, i.e. do a full pass of the dataset to calculate the vocabularies for categorical columns and then calculate the mean and standard deviation for the normalized columns. Next, the output of the Analyze step is used to transform the complete dataset.
4. Save the data and serialize the TransformFn and metadata-file.
Training
With the preprocessed data available as `TFRecords` we can now easily train a TensorFlow model with standard TensorFlow code using Estimators.
Exporting the trained model
Next to the very structured way of analyzing your dataset, the real power of tf.Transform lies in the possibility to export the preprocessing graph. This allows you to export a TensorFlow model that incorporates exactly the same preprocessing steps as used for the training data.
To do this, we only need to export the trained model with the tf.Transform input function:
Where the _make_serving_input_fn function is a very general function that you can simply reuse between different projects regardless of the project logic:
Using the digital twin

The final part of the digital twin example flow uses the saved model to predict the outputs of the system based on the inputs. This is where we can fully leverage tf.Transform, since this makes it very easy to deploy a `TrainedModel` (with preprocessing included) on Cloud ML Engine.
To deploy the trained model you only need to run 2 commands:
Now we can easily interact with our digital twin using the following code:
At ecc.ai we use digital twins for optimizing parameters of physical machines.
Simplified, our approach consists of 3 steps (outlined in figure 1 below):
Make a simulated environment using historical machine data. This ‘digital twin’ of the machine will serve as the environment that allows the reinforcement agent to learn an optimal control policy.
Use the digital twin to find (new) optimal parameter settings using our Reinforcement Learning (RL) agent.
Use the RL agent to configure the parameters of the real machines.

Summary
With tf.Transform we now have deployed our model on ML Engine as an API that works as a digital twin for a specific brownie dough machine: it takes the raw input features (ingredient descriptions and machine settings) and will return the predicted output of the machine.
The nice thing is that we don’t need to maintain the API and that everything is included—since the preprocessing is part of the serving graph. If we need to update the API, all that needs to be done is to refresh the model with the new version and all the relevant preprocessing steps will automatically be updated for you.
Furthermore, if we need to make a digital twin model for another brownie dough machine (one that uses the same data format), but that is running in a different factory or setting, we can easily rerun the same code without manually having to adjust preprocessing code or do a custom analysis step.
The code for this post is available on GitHub here.


