Discover insights from text with AutoML Natural Language, now generally available
Lewis Liu
Group Product Manager, Google Cloud
Organizations are managing and processing greater volumes of text-heavy, unstructured data than ever before. To manage this information more efficiently, organizations are looking to machine learning to help with the complex sorting, processing, and analysis this content needs. In particular, natural language processing is a valuable tool used to reveal the structure and meaning of text, and today we’re excited to announce that AutoML Natural Language is generally available.
AutoML Natural Language has many features that make it a great match for these data processing challenges. It includes common machine learning tasks like classification, sentiment analysis, and entity extraction, which have a wide variety of applications, such as:
Categorizing digital content, including news, blogs, and tweets, in real time to allow content creators to see patterns and insights—a great example is Meredith, which is categorizing text content across its entire portfolio of media properties in months instead of years
Identifying sentiment in customer feedback
Turning dark, unstructured scanned data into classified and searchable content
We’re also introducing support for PDFs, including native PDFs and PDFs of scanned images. To further unlock the most complex and challenging use cases—such as understanding legal documents or document classification for organizations with large and complex content taxonomies—AutoML Natural Language now supports 5,000 classification labels, training up to 1 million documents, and document size up to 10 MB.
One customer using this new functionality is Chicory, which develops custom digital shopping and marketing solutions for the grocery industry.
“AutoML Natural Language allows us to solve complex classification problems at scale. We are using AutoML to classify and translate recipe ingredient data across a network of 1,300 recipe websites into actual grocery products that consumers can purchase seamlessly through our partnerships with dozens of leading grocery retailers like Kroger, Amazon, and Instacart,” Asaf Klibansky, Director of Engineering at Chicory explains. “With the expansion of the max classification label size to the thousands, we can expand our label/ingredient taxonomy to be more detailed than ever, providing our shoppers with better matches during their grocery shopping experience—a business challenge we have been trying to perfect since Chicory began.
“Also, we see better model performance than we were able to achieve using open source libraries, and we have increased visibility into the individual label performance that we did not have before,” Klibansky continues. “This has allowed us to identify insufficient or poor quality training data per label quickly and reduce the time and cost between model iterations.”
We’re continuously improving the quality of our models in partnership with Google AI research through better fine-tuning techniques, and larger model search spaces. We’re also introducing more advanced features to help AutoML Natural Language understand documents better.
For example, AutoML Text & Document Entity Extraction will now look at more than just text to incorporate the spatial structure and layout information of a document for model training and prediction. This spatial awareness leads to better understanding of the entire document, and is especially valuable in cases where both the text and its location on the “page” are important, such as invoices, receipts, resumes, and contracts.
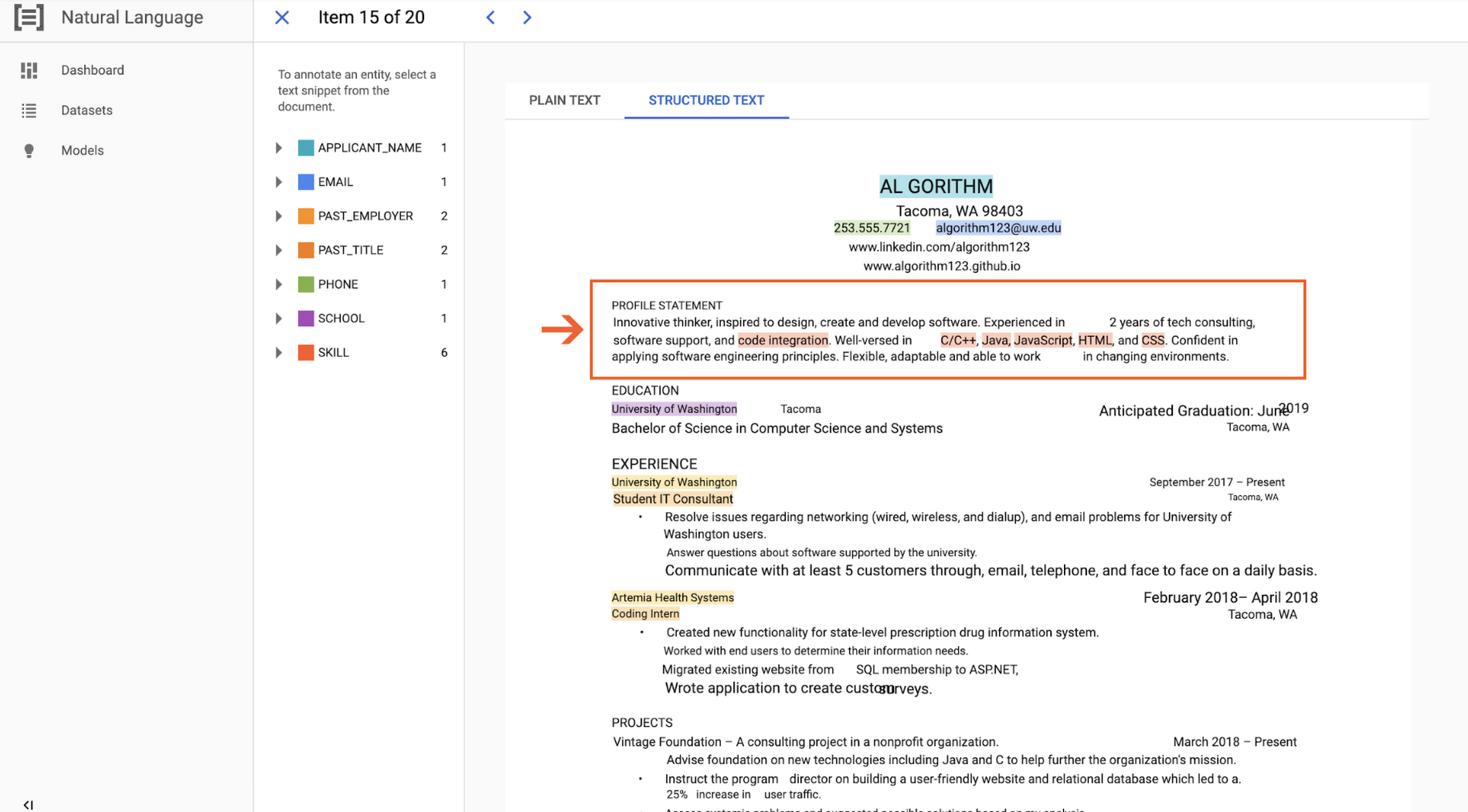
We also launched preferences for enterprise data residency for AutoML Natural Language customers in Europe and across the globe to better serve organizations in regulated industries. Many customers are already taking advantage of this functionality, which allows you to create a dataset, train a model, and make predictions while keeping your data and related machine learning processing within the EU or any other applicable region. Finally, AutoML Natural Language is FedRAMP-authorized at the Moderate level, making it easier for federal agencies to benefit from Google AI technology.
To learn more about AutoML Natural Language and the Natural Language API, check out our website. We can't wait to hear what you discover with your data.



