Making Your Pictures Worth a Thousand Labels! (with Cloud Vision API)
Alicia Williams
Developer Advocate, Google Cloud
In this post, I'll be showing some amazing ways the Vision API can extract meaning from your images - keep reading, or jump directly into a tutorial using Python, Node.js, Go, or Java! This tutorial can be completed at no cost within the Google Cloud Free Tier.
They say a picture is worth a thousand words. But how do you make those words available and useful? Around the world, we are generating more images than ever before, and it's no surprise that businesses are turning to image recognition technology to help meet the immense opportunities created with this growing set of data.
Cloud Vision API is a powerful tool that enables you to perform a variety of tasks including label detection, text recognition, and object tracking on your image data. Whether it's identifying products in a retail store, analyzing social media posts for brand mentions, or scanning through millions of images to find a specific object, the Cloud Vision API can help businesses automate their image analysis workflows and gain valuable insights from their visual data. To protect privacy, and help you build responsibly, the Cloud Vision API offers features to limit personal identification, such as person blur, which hides identifiable features.
Let's explore a few of the key features of the Cloud Vision API.
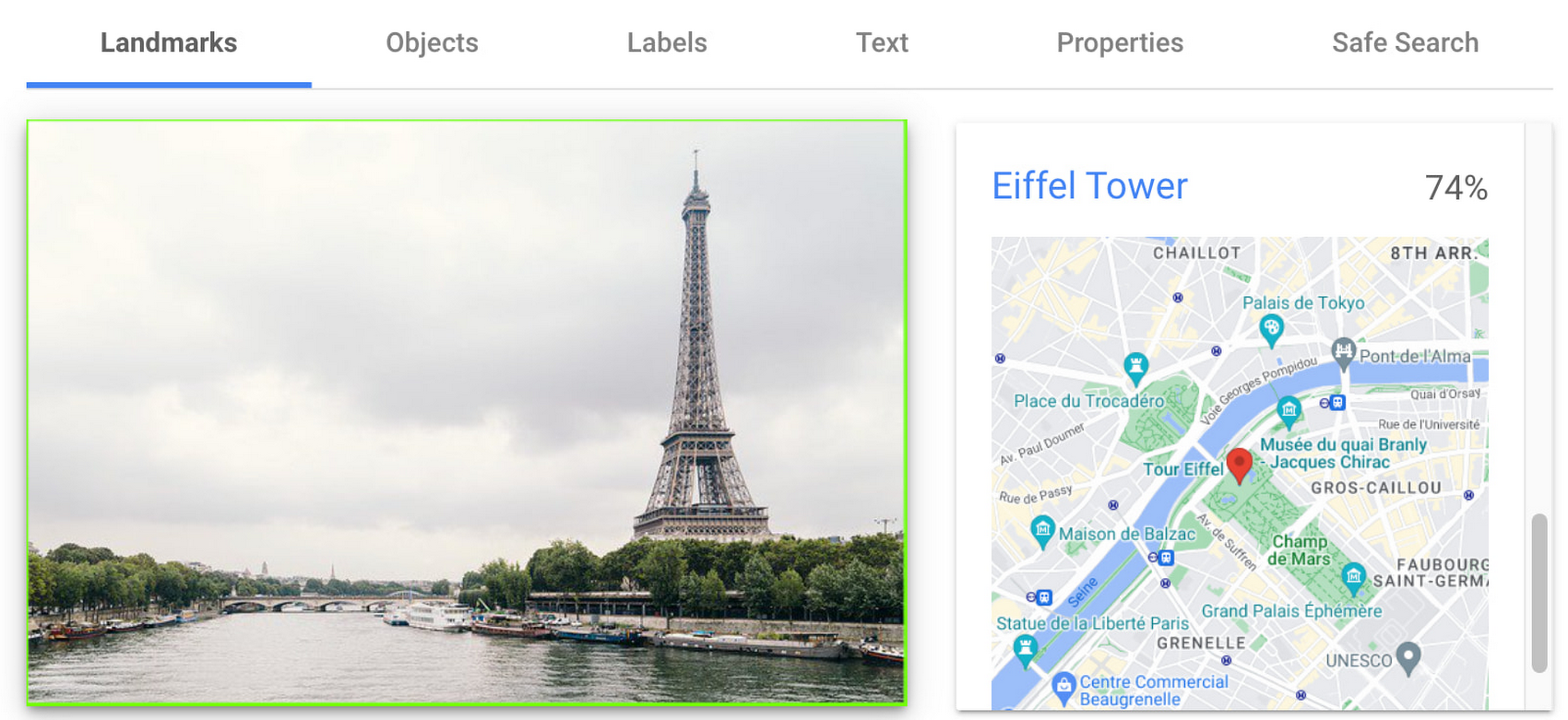
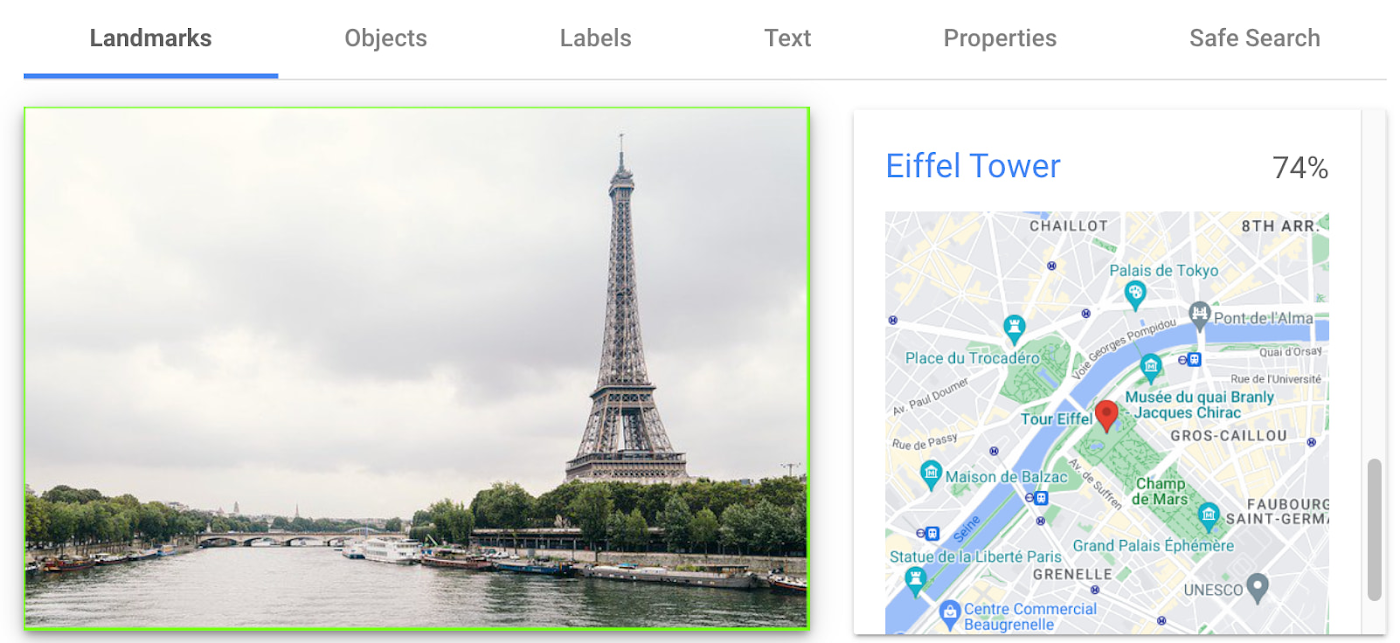
Detect famous landmarks
Landmark detection allows you to analyze images to identify specific landmarks such as buildings, natural features, and other recognizable locations. Cloud Vision API recognizes landmarks and provides information about them, including their name, location, and other relevant details. Perhaps you are trying to identify the landmarks in images shared by customers as part of social campaigns, or want to build a mobile app that provides information to tourists on famous landmarks.
In the below left-hand side image, Cloud Vision API has detected the Eiffel Tower, shown in the visualized response. Not shown in this visualization here, but also detected, were Pont de Bir-Hakeim (the bridge) and Champs de Mars (the park in front of the Eiffel Tower).
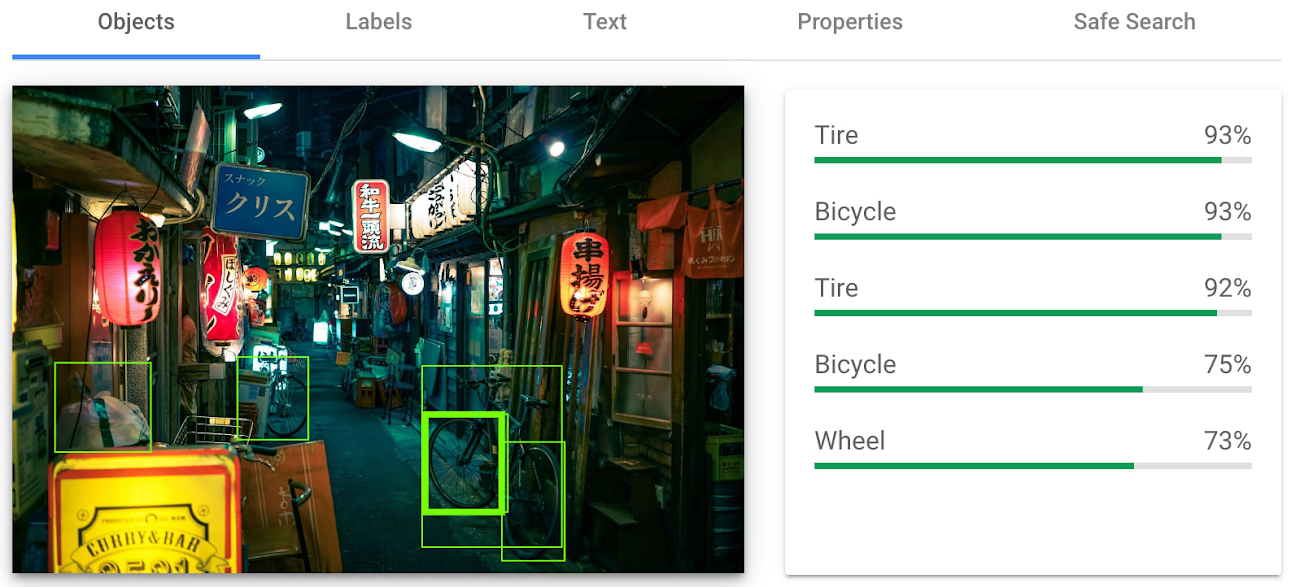
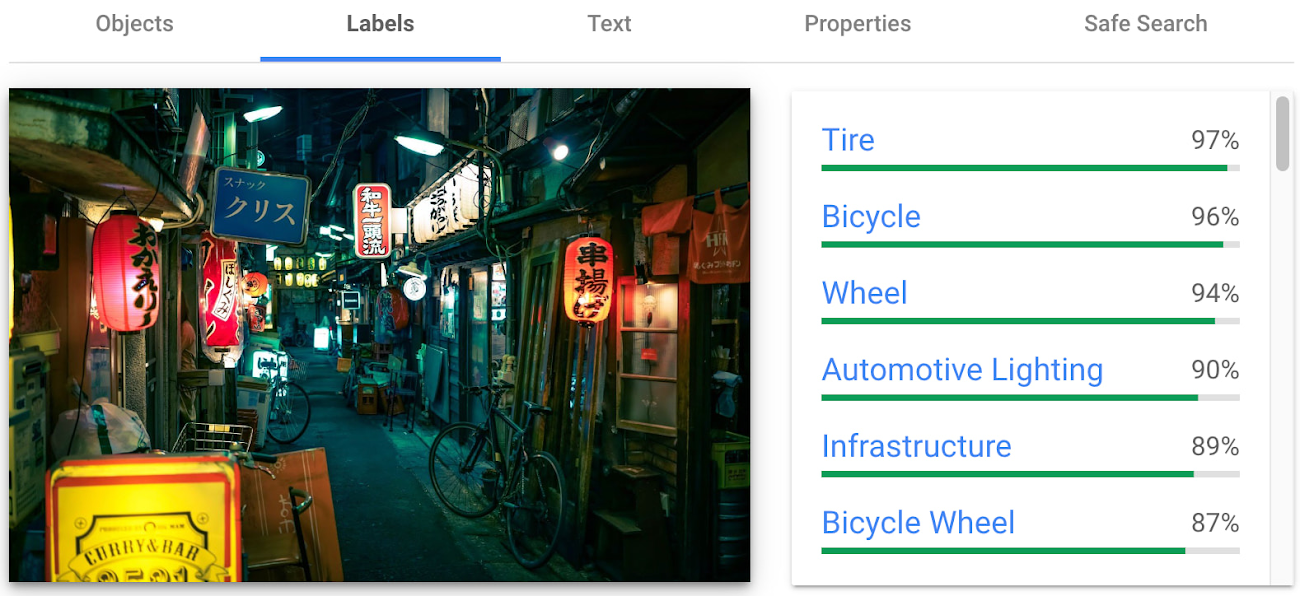
Detect objects and label images
Object detection and labels are two related features that enable you to identify and classify objects within an image. Object detection detects and locates objects within an image, and provides information such as the position, size, and orientation of each object. Labels, on the other hand, provide a general classification of the content within an image.
Object detection has practical applications in many industries such as self-driving vehicles (where it's critical), retail, manufacturing and more, while labels can be used to help classify and organize large collections of images, or to categorize and filter content.
You can see the similarities and differences in the responses provided by the object detection and labeling features in this image taken in Setagaya.
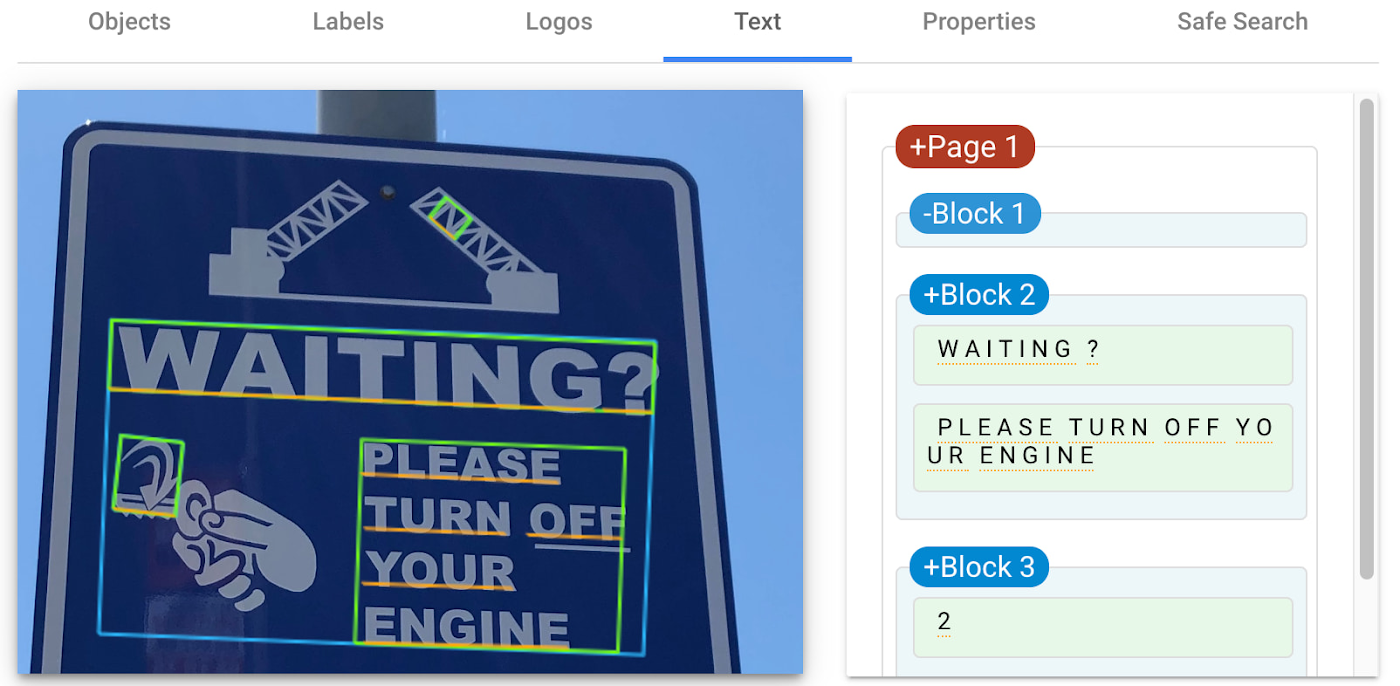
Detect text
Cloud Vision API detects and extracts text from any image, even if it's handwritten or in different languages. Once it detects text, the API can provide information about the position, orientation, and size of each text element, as well as individual words, and their bounding boxes.
In this image of a traffic sign, Cloud Vision API has detected the text and provided it in the response.
Detect explicit content
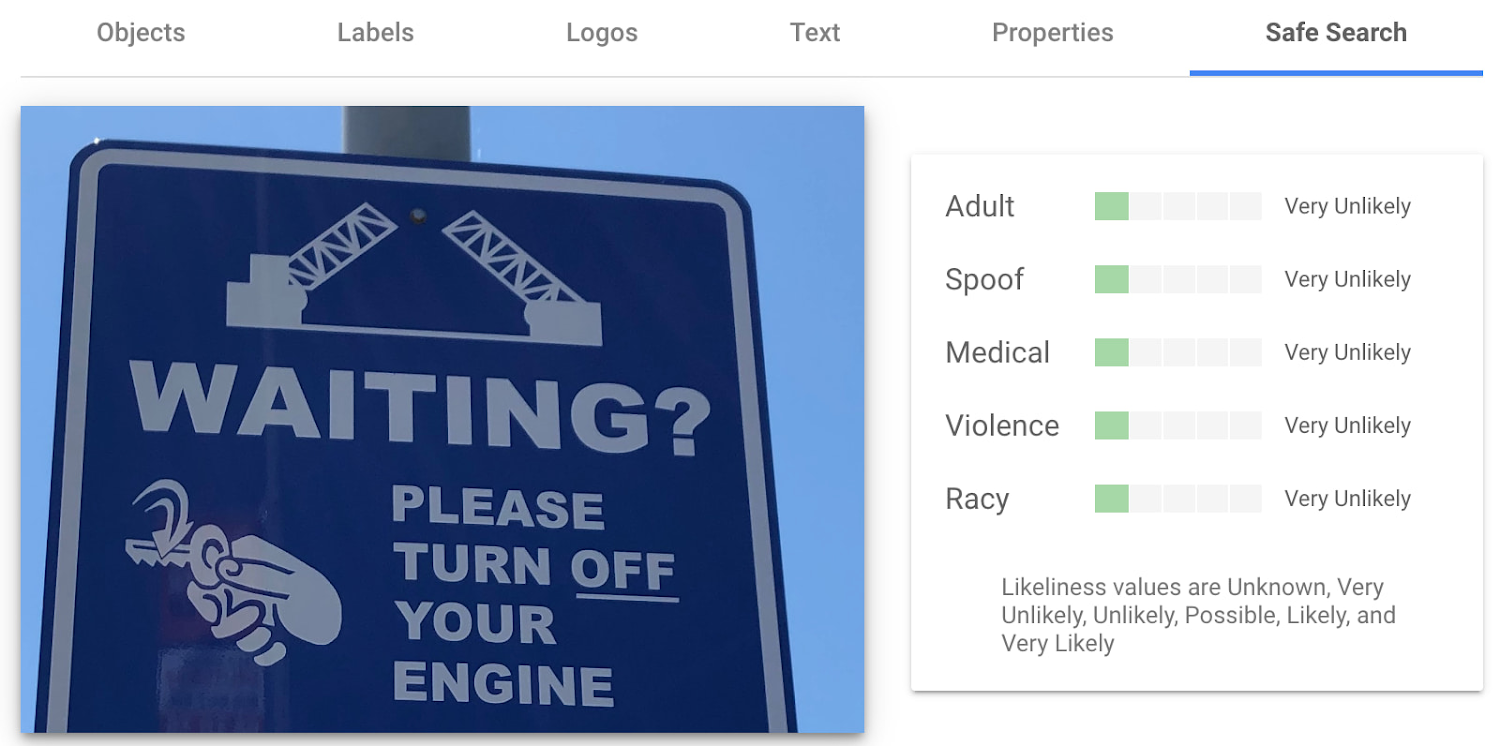
Cloud Vision API can automatically identify and flag explicit or inappropriate content within an image using five categories: adult, spoof, medical, violence, and racy. The API provides a score that indicates the likelihood for each category in the image, which you can use to set thresholds in your application and decide how to handle those that exceed them. This feature is particularly useful for filtering or moderating user-generated content.
Luckily for the images I shared here, each category has been deemed "very unlikely" to be present. Phew!


Next Steps
These are just a few features of the Cloud Vision API and how it can help your business with automating image analysis workflows and gaining valuable insights from your visual data.
Head to the interactive walkthrough tutorials in Python, Node.js, Go, and Java to see step-by-step how to access the API and learn more about all the features that you can integrate into your own applications! Again, this tutorial can be completed at no cost within the Google Cloud Free Tier.



