Is that a device driver, golf driver, or taxi driver? Building custom translation models with AutoML Translate
Sara Robinson
Software Engineer
Earlier this year at Google Next ‘18, we announced two new variants of AutoML: Natural Language and Translate. You may have seen me present a live demo of AutoML Natural Language in the keynote, but in this post I want to focus on AutoML Translate, a tool for building custom, domain-specific neural machine translation models without writing any model code. If you want to dive right in, check out the AutoML Translate quickstart.
Why do we need custom translation?
Before we get into AutoML Translate, let’s understand when and why you might need a custom translation model. Many translation applications won’t need custom translation, and can achieve high accuracy from a pre-trained translation model like the one provided in the Cloud Translation API. For example, let’s say I’m in France and I’d like to order some wine and cheese. I could use the Translation API to produce the following translation:
Je voudrais un verre de vin rouge et du fromage.
For examples like this where the source text being translated is not domain specific, the Translation API works well and there’s no need for a custom solution. When would a custom neural machine translation (NMT) model improve results? Let’s take the following sentence as an example:
The driver is not working
Now let’s say I want to translate this sentence. Taken in isolation, the Translation API doesn’t know the context of the word “driver.” The sentence could take on a couple of different meanings. The word “driver” here could be referring to a broken driver golf club:

Alternatively, it could describe a taxi driver who is on a break and therefore not working:

In a software context, it could even refer to a broken device driver:

And if I translate “The driver is not working” into French using the Translation API, here’s what I get:
Le pilote ne fonctionne pas.
“Pilote” in this translation is ambiguous. If I wanted to translate this text into the “device driver” context mentioned above, I’d really want “driver” to be translated as “pilote de périphérique,” but we wouldn’t expect the Translation API to know this.
There are probably even more ways to interpret this sentence, but you get the idea. If our particular application requires translating text specific to software, we’d need to train a translation model on sentences specific to this domain. And that’s where AutoML Translate comes in handy: all we need to do is upload our sentence translation pairs, press the “train” button, and we get access to an API endpoint to make predictions on our custom model.
Getting started with AutoML Translate
Now that you know when to use custom translation, let’s dive into the specifics of building a model. Each AutoML Translate model you create will translate one source language into one target language (i.e. English to Spanish). AutoML Translate supports 100 different language pairs, all of which are listed in the documentation.
In the AutoML Translate UI, first select the source and target language for your model:
The training data for your model will consist of sentence pairs: translating the same text from the source to the target language for your model. You can upload them as a TSV (tab separated values) or TMX (translation memory exchange) file. TMX files are XML designed specifically for storing translation data. A TSV file for an English to Spanish model might look like the following:
In the AutoML Translate quickstart, several example datasets are provided so you can get the hang of building custom models before you start generating translation pairs. Once you select your training data files and create a dataset, you’ll receive an email when the data import job completes (it should only take a couple of minutes).
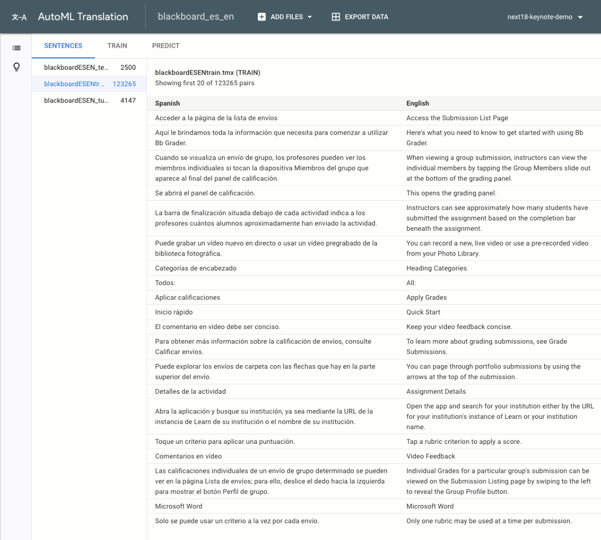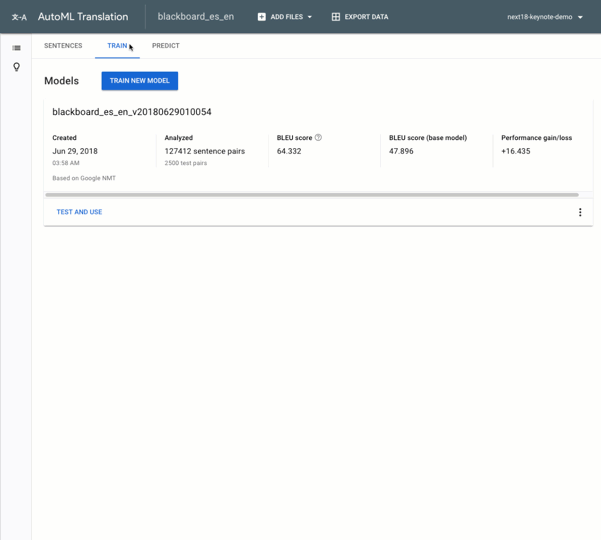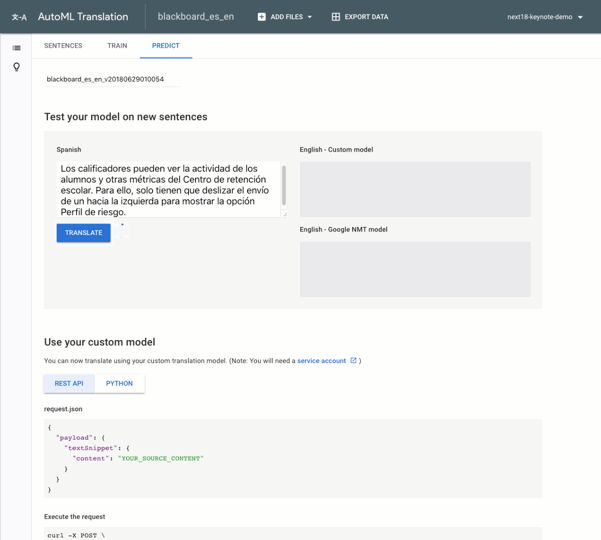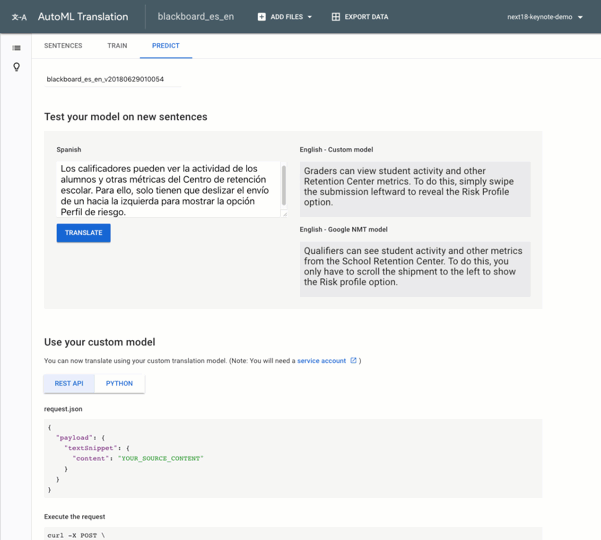
Training your model is as simple as pressing the Train New Model button in the Train tab of the UI:
Translate models take a few hours to train and you’ll get an email when the job completes. After training, you can see how your model performed and generate translations on new text.
Machine translation experts use a metric called the BLEU score to evaluate the quality of a translation. BLEU score is a value between 0 and 100% that indicates how close the machine translation is to a reference translation of the input text. A BLEU score closer to 100% means the machine-translated text is very similar to the reference. High BLEU scores often correlate with text translated by a human, but note that even human translators don’t achieve a BLEU score of 100%. We can see the BLEU score for our custom model in the Translate UI:
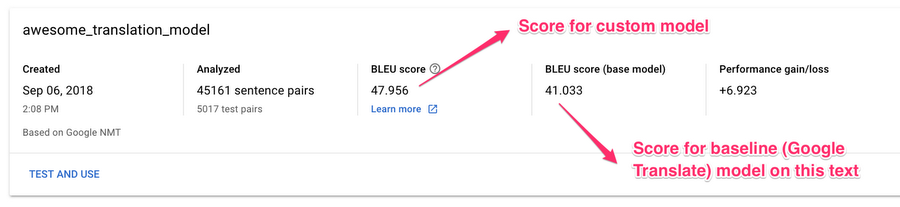
In the third column above, we see the BLEU score for our custom model: 47.9%. We can compare this to how the base model performed on our particular text inputs: 41%. This means that there was roughly 48% overlap between the translations performed by our custom model on the test set, and the reference translations. We want to see a higher BLEU score for our custom model compared to the baseline, since the baseline indicates how Google Translate would perform on the same text.
Next, we’ll use our model to generate translations on text it hasn’t seen before.
Translation at scale with Welocalize
To show you how to generate translations from a custom model, let’s look at real world data from our customer Welocalize. Welocalize is one of the largest localization providers in the US, with a mission to help their customers localize content for global audiences. Welocalize’s customers include Fortune 500 companies and span a wide variety of industries: legal, healthcare, education, technology, and more.
With a team of linguists and subject matter experts, Welocalize helps their customers build translation datasets and evaluate the quality of trained models. They’ve been using AutoML Translate since the alpha. One of the customers they’ve helped using AutoML Translate models is the education platform Blackboard. Blackboard lets teachers post course materials, grade assignments, and interact with students. Much of the content on the site is very specific to the education industry and Blackboard’s own platform-specific terminology. Welocalize is helping Blackboard translate their content using AutoML Translate, specifically translating documentation explaining how to use different parts of the platform, along with UI elements like buttons and links.
On the Predict tab of the Translate UI, we can enter text in the model’s source language and compare the translation from our custom model to the translation we’d get from Google Translate. Welocalize originally built a model to translate from English to Spanish. So that readers can understand the translation output, I’ve reversed the training sentence pairs to build a model that translates from Spanish into English. The quality of the model with the reversed sentence pairs will be very similar to the original.
Let’s see how our model translates the following Spanish sentence into English:
Los calificadores pueden ver la actividad de los alumnos y otras métricas del Centro de retención escolar. Para ello, solo tienen que deslizar el envío de un hacia la izquierda para mostrar la opción Perfil de riesgo en la página Lista de envíos.
Here’s what we get in the AutoML Translate UI:

You can see a few instances where the custom model results in a higher quality translation. Here are a few:
The word “Graders” is more accurate than “Qualifiers”
“Retention Center” is a proper noun specific to Blackboard’s application, which the base model incorrectly translates as “School Retention Center”
In the context of Blackboard, “swiping” and “submission” are better translations than “scroll” and “shipment”
Finally, here’s the full process of building Blackboard’s model in AutoML Translate, from gathering training data to generating predictions:
The Predict tab of the Translate UI is only one of several ways to generate translations. Chances are you’ll want to build an app that lets you dynamically make translation requests on your trained model. To do that, AutoML Translate gives you access to a REST API for making predictions. Once your model is trained, custom translations are as simple as one REST request. Here’s what your request JSON would look like:
And here’s how you’d make a request to your model using `curl`:
It’s important to note that only you, and any developers you’ve shared your project with, have access to this model. Your data is not used to improve the Translation API or Google Translate.
AutoML Translate, under the hood
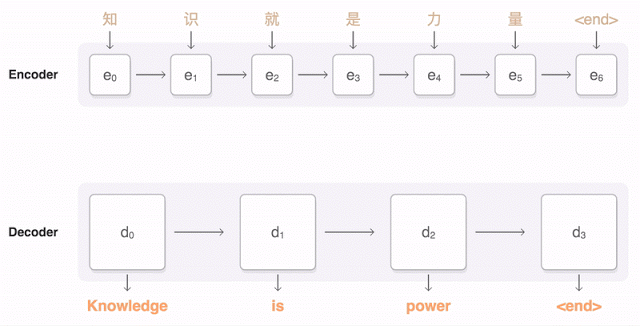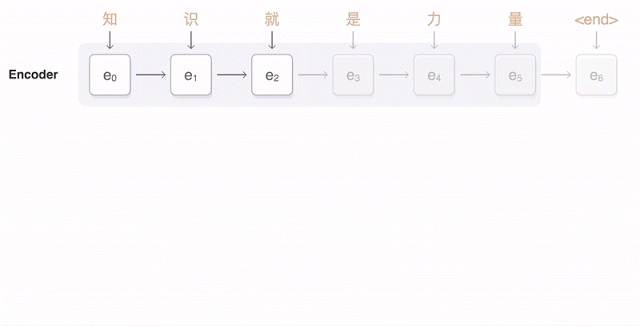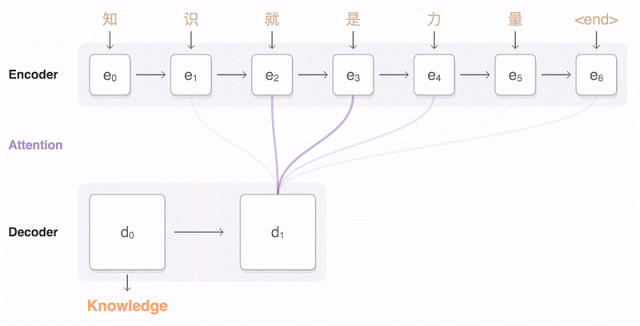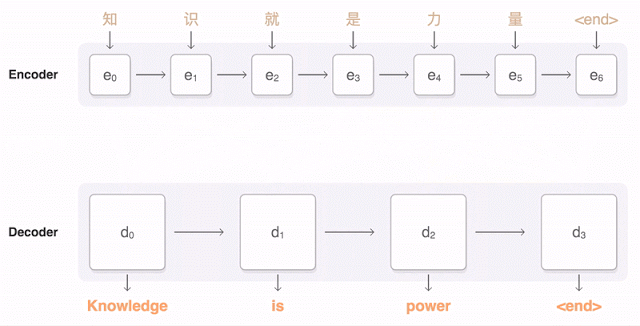
If the “Auto” in AutoML sounds too magical, you may wonder what’s happening behind the scenes to make these custom models work. ML is increasingly being used for translation tasks, specifically with neural machine translation (NMT). NMT uses deep learning to predict translations from one language to another. Before NMT, translation models would break a document down into words and short phrases and then translate each block largely independently. NMT is able to produce higher quality translations by taking an entire sentence as input and translating a word by looking at the context of surrounding words in the sentence. The Translation API uses NMT models by default. This visualization shows the progression of a NMT model as it translates a sentence from English into Chinese:
Training quality NMT models requires lots of training data. So that you don’t need to start from scratch, AutoML Translate employs a technique called transfer learning. With transfer learning, you take the weights and variables of a pre-existing model that has already been trained on lots of data and leverage it for your own data and prediction task. AutoML Translate uses the pre-trained NMT model behind the Translation API as its baseline, and then continues to train it on the sentence pairs you provide. Because it utilizes transfer learning, the process requires much less of your own training data—you’ll need thousands of training sentences rather than hundreds of thousands to get a high quality model.
Start training your own custom models
Ready to build your own custom translation model with AutoML Translate? The quickstart and documentation is a great place to start. For more details on Welocalize’s use case, check out the AutoML Translate section of my talk from Cloud Next 2018. And if you’re interested in more details about how NMT models work, this Google AI blog post is a great resource. Have questions or feedback? Find me on Twitter at @SRobTweets.



