Add intelligence to your document processing with Google's Enterprise Knowledge Graph
Lewis Liu
Group Product Manager, Google Cloud
Will Lu
Senior Staff Software Engineer
Google Cloud introduced Document AI to automate document processing and to streamline workflows with state-of-the-art machine learning models. With the deep neural networks, the models generalize the learning from seeing hundreds of thousands variations of the documents. But when information is missing or ambiguous on a document - like a missing address or entity name - a human may need to search for it...often on Google.
With Document AI, we are bringing the power of this “Google search” to help customers understand their documents. This means that the same Google knowledge graph technology that helps you find the name, address or phone number of your favorite restaurant can now enrich your document extraction with the right name, fully qualified address, and updated phone number.
Here is a sample payslip…
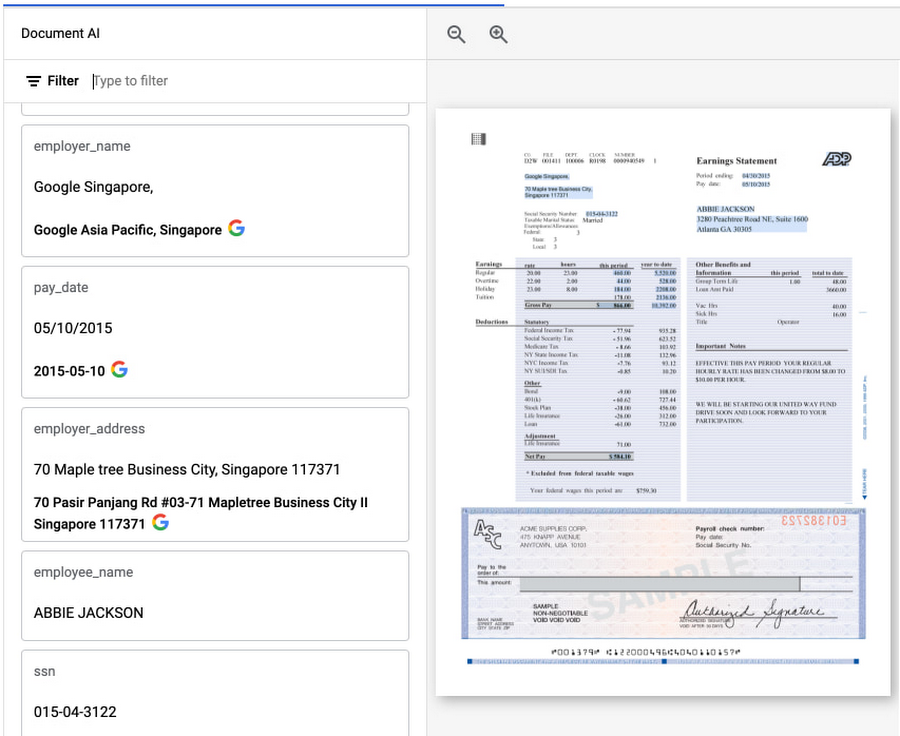
Imagine a bank employee entering this to capture a customer's income to qualify them for a loan. When extracting information from this payslip, what employer name should she key in? She might take the time to go into Google and find the right correct legal entity name; or she might just guess and move on, potentially creating data reconciliation headaches down the line.
With Document AI, there is a better way. Our native integration with the knowledge graph means that we can deliver both the specific text from the payslip as well as Google’s best understanding of the actual name of the company that operates at this address. This is an important step to translate from “what has been said” on a document to “what does it mean”. By normalizing the value as you process millions of documents, you are improving accuracy and consistency at the beginning of the data processing workflow, making downstream integration, data analytics and business intelligence tasks at ease.
How EKG Enrichment Works
In a nutshell, Knowledge Graph is a knowledge base that uses a graph data model to integrate interlinked entities, including objects, events, processes or abstracted concepts. Google announced its Knowledge Graph in 2012 as a way to organize information from the Web and to enhance Search results. Different from Google Knowledge Graph, Cloud EKG (Enterprise Knowledge Graph) focuses on entities that are more relevant to enterprise customers, such as organization, product, people, locations, etc.
In EKG, every node is called an entity. Each entity in the graph represents an object, such as an organization. EKG aggregates all the information about a thing into a single entity, thus each entity represents a distinct and identifiable real world concept. The uniqueness of these entities in the graph is one of the reasons that make EKG useful. The edges between nodes are called relationships. When representing attributes, the relationships can be considered as properties, such as the name of a company, the price of a product, etc. When representing relationships, they connect entities in the graph, such as the CEO of a company, the seller of a product.
Entity linking, as its name suggests, is the task of assigning a unique identity to entities mentioned in text, images or videos. In the context of EKG, it connects the text mentions to entities in the graph. Under the hood, the recognition takes both the mention and its context information into consideration for linking to the best matching candidates in the graph.
Entity Enrichment, is essentially linking entities in EKG to documents, and using the attributes of linked entities to enrich the extracted information. The entity linking on documents is based on the understanding of both documents and the entities in the graph. First the document parser annotates entity mentions, which provides semantic meanings to the content of the document. Then Entity Linking selects a list of entities from EKG based on the types of these mentions, and matches to the best entity by comparing the attributes found in the document with the the relationships of the selected entities.
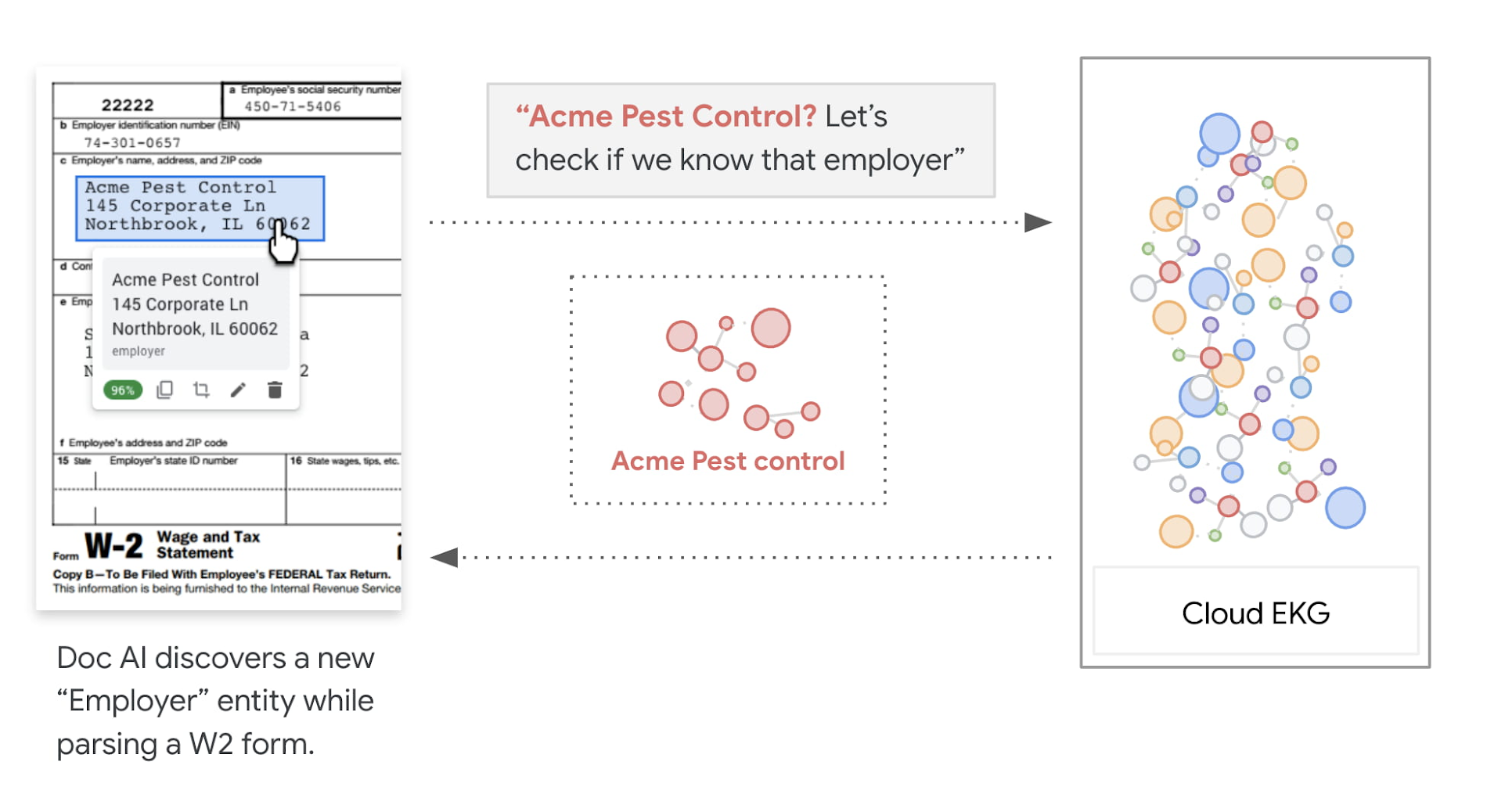
How to leverage the enrichment result
Knowledge graph enrichment is a built-in feature for Lending DocAI , Procurement DocAI and Contract DocAI today, and we are actively working on expanding it to cover more document types and parsers on the platform. To use the knowledge graph enriched values, look out for the entities fields under normalizedValue, returned by the API.
To learn more, check out the Document AI webpage, and EKG Enrichment page to see the list of supported parsers and fields.




