Build your own gen AI-powered vector search applications with Vertex AI Search
Eran Lewis
Sr. Product Manager, Vertex AI Vector Search, Google Cloud
The world has been amazed in the last year by the power of generative AI — and vector embeddings are part of the behind-the-scenes magic. Embeddings are a way of representing data – text, images, videos, users, music, and more – as points in space. When two points are close, they are semantically related. For instance, embeddings can represent that both ice cream and broccoli are foods, but only ice cream is commonly a dessert.
Vector embeddings enable developers to build a multitude of user experiences: for example, finding the most relevant passage from a document, matching the right product to the right person at the right time, or recommending a visually similar fashion item.
They also enable developers to build highly relevant large language model (LLM)-based generative AI applications, with a method called retrieval-augmented generation (RAG). Out of the box, LLMs are only familiar with the data used to train them. In the RAG model, developers use embeddings to ground the LLMs on relevant business information, and use them to generate highly relevant responses.

Vector embeddings cluster visually similar items together, enabling fast vector similarity search
In order to power these online, mission-critical applications, developers need a reliable service they can trust to be fast and handle the load. For this, we offer vector search capability as part of the Vertex AI Search platform. Vector search (formerly Vertex Matching Engine) finds the most relevant embeddings at scale, blazingly fast. It is based on the same technology that powers core Google services. Today, we’re introducing new features and improvements to make vector search even more useful to developers.
Inside vector search
Vector search’s previously-available features cover a wide range of developer needs and enterprise requirements:
Scales to match your needs
With vector search, developers don’t need to worry about scaling the service up and down; the service auto-scales based on the load. Vector search also enables customization and tunability. For example, developers can easily tune between recall rate and latency, adjusting to match their use case.
Keeps your vector data up to date
Your business data might change over time and vector search can quickly adapt to these changes. With incremental streaming updates, developers don’t have to wait for the entire index to be rebuilt. You can stream your embeddings into vector search and have them ready to query within a few seconds.
Private and secure
Vector search offers enterprise users peace of mind with security and compliance features, such as VPC Service Controls, Customer Managed Encryption Keys (CMEK), and Access Transparency.
These capabilities help meet the security, privacy, and compliance requirements for developers’ mission-critical workloads.
While vector search supports easy-to-use public endpoint deployment, developers can also choose to set up VPC or Private Service Connect (in Public Preview) endpoints, for added data security.
Easy to integrate
Vector search pairs well with other Vertex AI platform offerings. For example, in order to easily build a highly relevant gen AI or search user experience, developers can use LLMs from Vertex AI Model Garden to generate embeddings from their business data, and index them into vector search for fast retrieval.
What’s new: easier to get started and new capabilities
Today, we announce new search features for vector search, and a set of improvements that make it easier for developers to get up and running. With these improvements, Vector search makes it simple to pair LLMs and other embedding foundation models with business data to power fast and relevant user experiences.
- Vector search UI: With the new UI, now available in Public Preview, developers can get started more easily, as well as monitor index and vector performance. Developers can also create and deploy their indexes directly from the UI – no coding required.
- Faster to get started: Now generally available, new enhancements reduce the index build time for smaller indexes from hours to minutes, minimizing development friction and getting developers up and running faster.
- New filtering capabilities: With new filtering capabilities now available in Public Preview, app developers can define and filter on numerical range metadata at query time, in addition to the tag-based filtering available today. This improvement opens up support for new vector-based application use cases.
- Improved documentation: Improved documentation makes it easier to learn how to get started, explore different capabilities, and follow along with step-by-step examples of building apps with vector search.
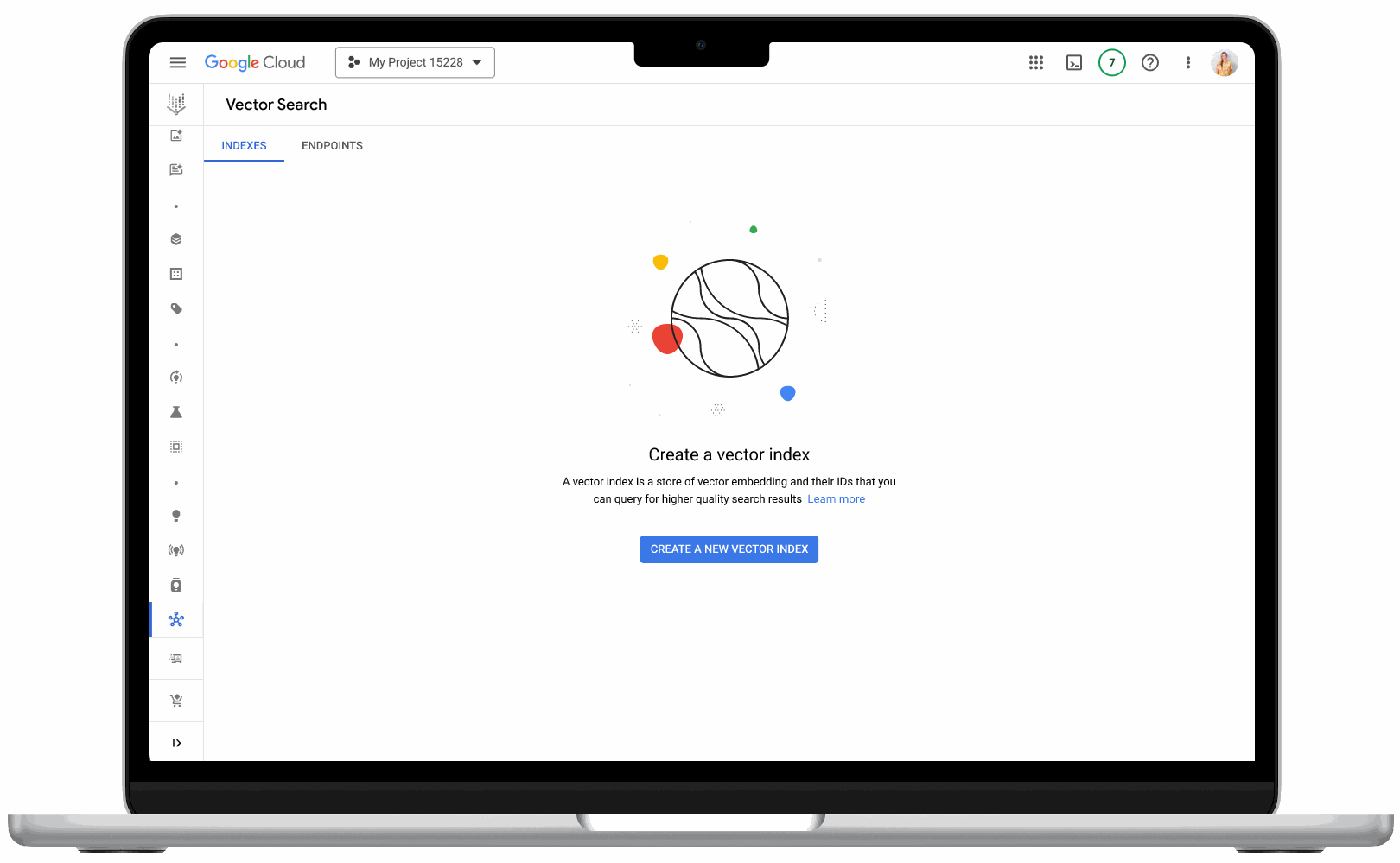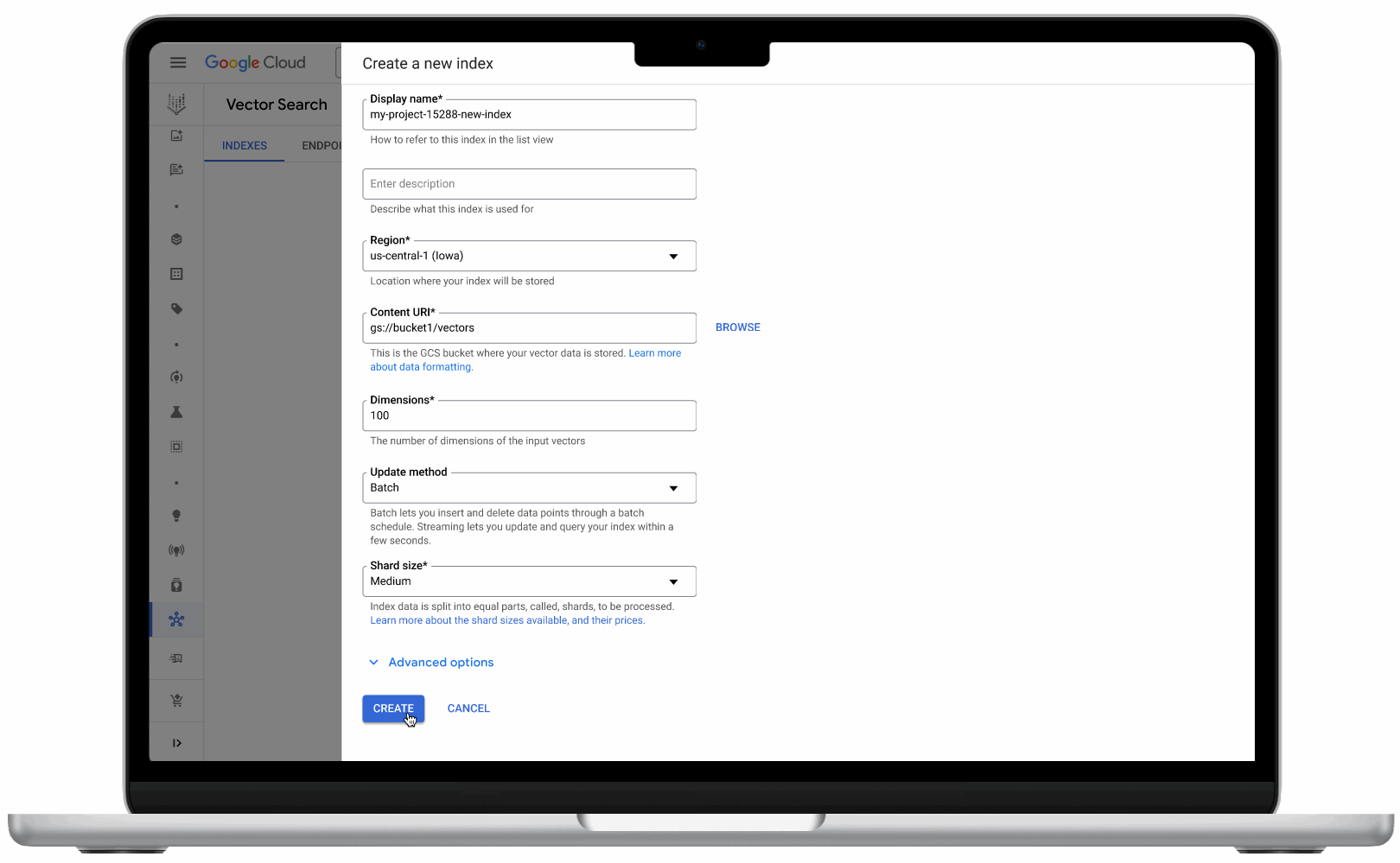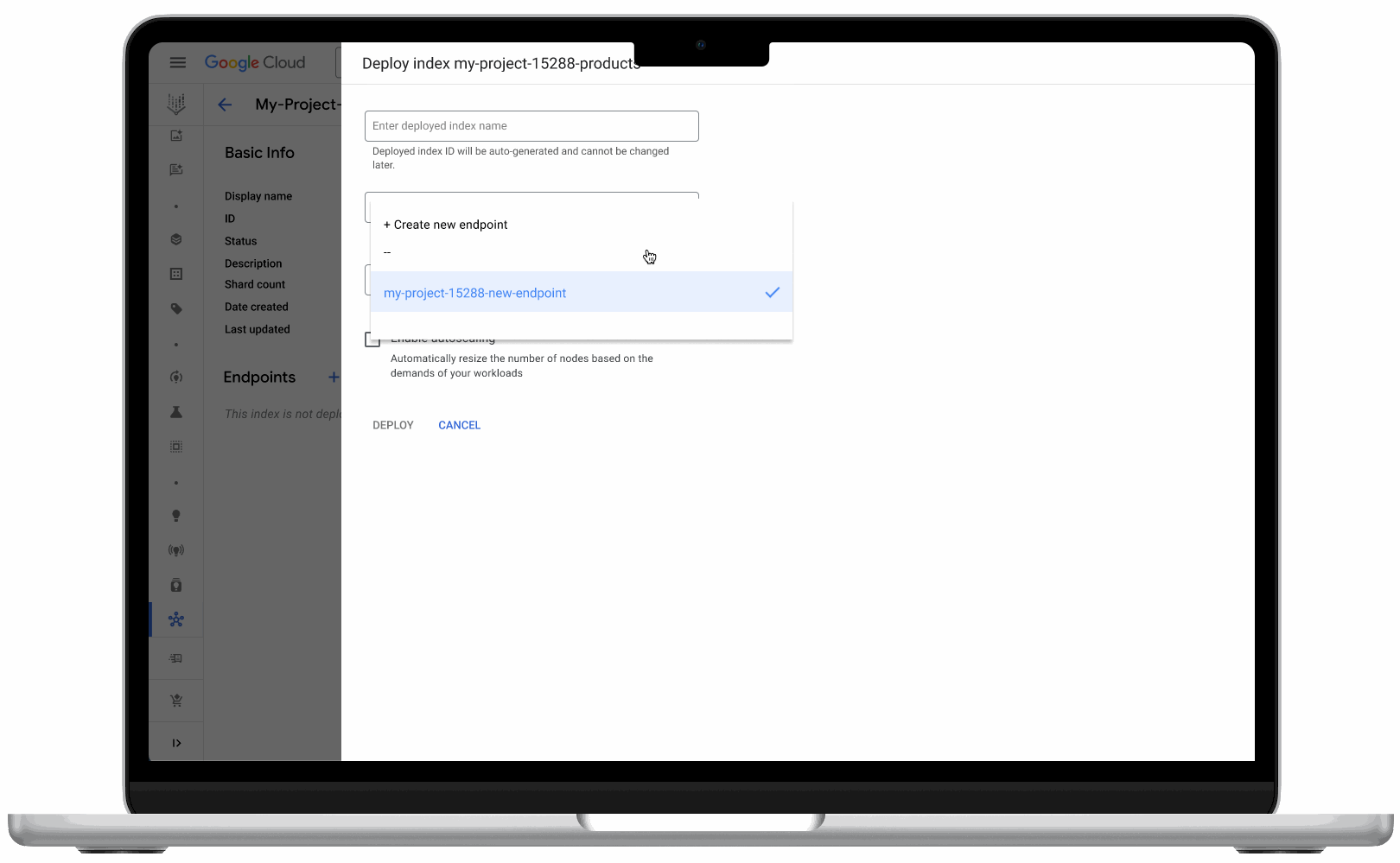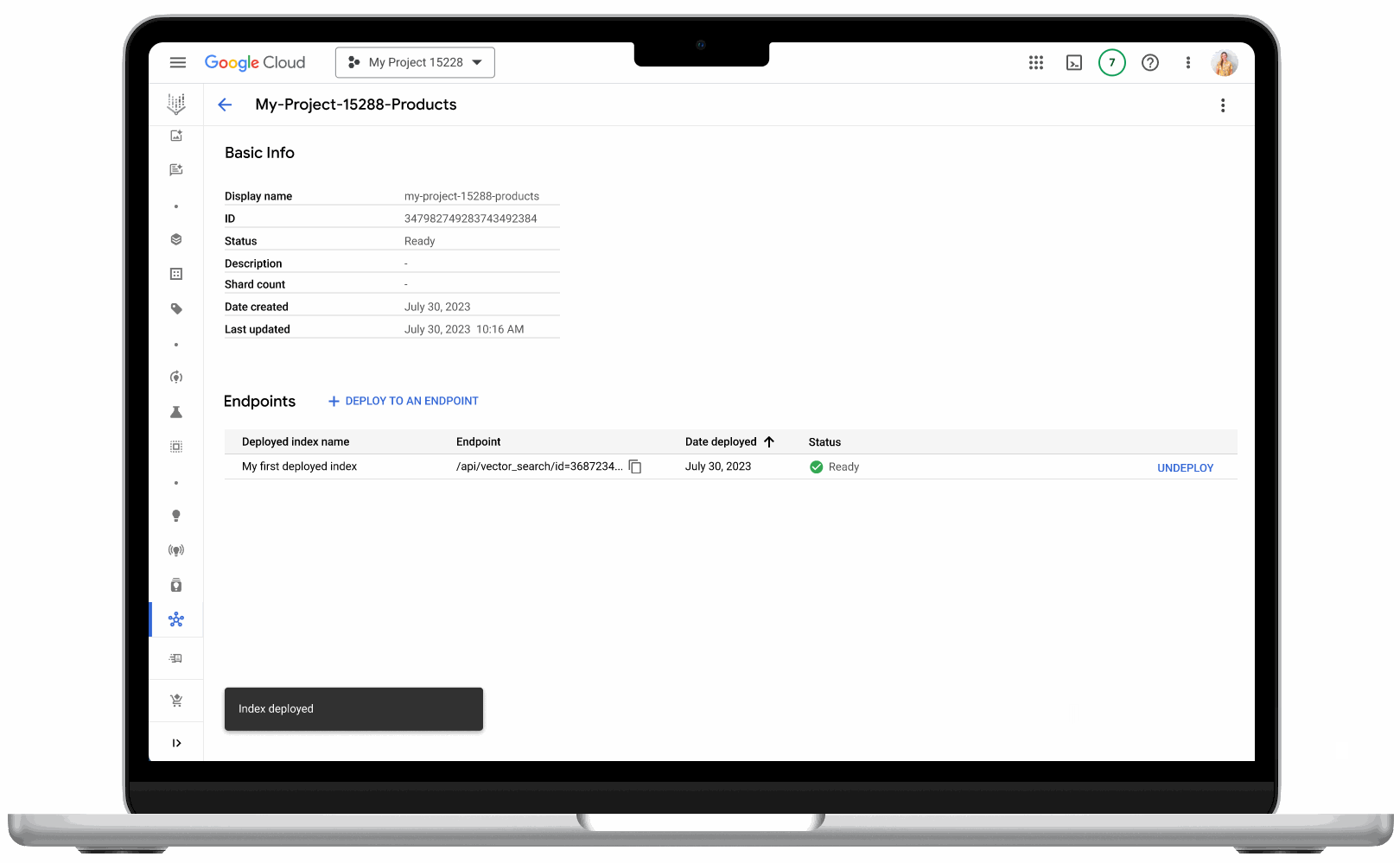
Vector search’s new user interface makes it easy for developers to use the product, no coding required
Looking ahead
We continue to invest in Vertex AI Search by adding new generative AI features and capabilities. Read more in this blog. For vector search we’ll be introducing new features soon and continuing to make it even easier for developers of all skill levels to incorporate search and gen AI capabilities into their tech stack, in order to create new and exciting user experiences. Get started now with vector search at g.co/cloud/vectorsearch.



