Data scientists assist medical researchers in the fight against COVID-19
Devvret Rishi
Kaggle Product Manager
Paul Mooney
Kaggle Developer Advocate
Cutting-edge technological innovation will be a key component to overcoming the COVID-19 pandemic. Kaggle—the world’s largest community of data scientists, with nearly 5 million users—is currently hosting multiple data science challenges focused on helping the medical community to better understand COVID-19, with the hope that AI can help scientists in their quest to beat the pandemic.
The Kaggle community has been working hard forecasting COVID-19 fatalities, summarizing the COVID-19 literature, and sharing their work under open-source Apache 2.0 licenses (on Kaggle.com). In this post, we’ll take a detailed look at a few of the challenges underway right now, and some interesting strategies our community is using to solve them.
NLP vs. COVID-19
The volume of COVID-19 research is becoming unmanageable. In May there were about 357 scientific papers on COVID-19 published per day, up from 16 per day in February. In March, officials from the White House and global research organizations asked Kaggle to host a natural language processing (NLP) challenge with the goal of distilling knowledge from a large number of continuously released pre-print publications.
Specifically, Kaggle’s community is trying to answer nine key questions that were drawn from both the National Academies of Sciences, Engineering, and Medicine’s Standing Committee on Emerging Infectious Diseases research topics and the World Health Organization’s R&D Blueprint for COVID-19. To answer these questions, we’re sharing a corpus of more than 139,000 scientific articles that have been stored in a machine-readable format. Already, there’s a lot of interesting work being done using transformer language models such as SciBERT, BioBERT, and other similar models, and we encourage you to check out the code (Python/R), which has all been open-sourced.
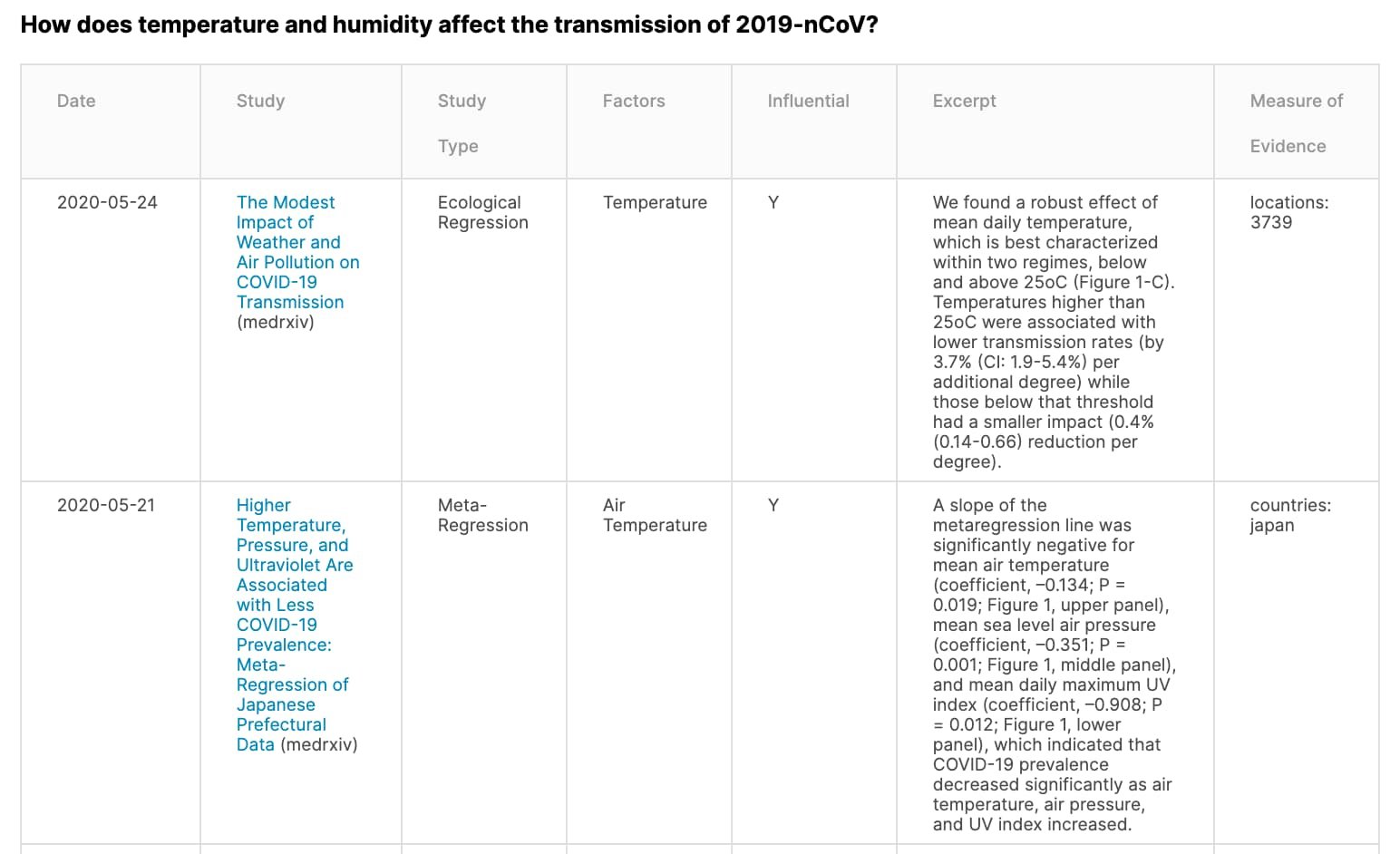
Figure 1, for instance, illustrates the first two rows from an article summary table that describes recent findings concerning the impact of temperature and humidity on the transmission of COVID-19. Preliminary tables are generated by Kaggle notebooks that extract as much relevant information as possible, and then the results are double-checked for accuracy and missing values by a team of medical experts. The article summary tables contain text excerpts that were extracted directly from the original publications. Summary tables like these, which can be produced in an expedited fashion, make it much easier for researchers to keep up with the rapid rate of publication.
Figure 1
“My initial approach was to build a semantic similarity index over the data, enabling researchers to find topic/keyword matches. I learned that while search is important, researchers need more context to evaluate the study behind the paper,” explained David Mezzetti, a US-based contributor on Kaggle and founder of NeuML. “Much of my efforts have been focused on using NLP to extract study metadata (design, sample size/method, risk factor stats), allowing researchers to not only find relevant papers but also judge the credibility of its conclusions.”
Time series forecasting vs. COVID-19
On March 23, Kaggle also started hosting a series of global transmission forecasting competitions, to explore new approaches to modeling that may be useful for epidemiologists. The goal is to predict the total number of infections and fatalities for various regions—with the idea being that these numbers should correlate well with the actual number of hospitalizations, ICU patients, and deaths—as well as the total number of scarce resources that will be needed to respond to the crisis.
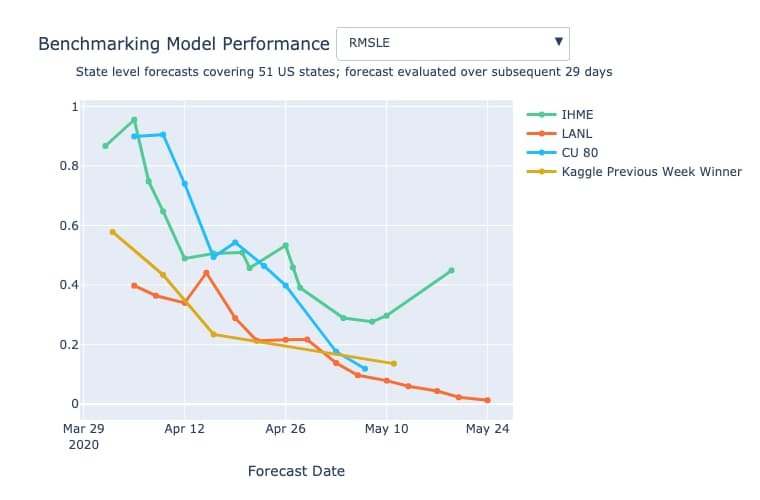
Forecasting COVID-19 has been a very challenging task, but we hope that our community can generate approaches to forecasting that can be useful for medical researchers. So far, the results have been promising. As we can see in the plot below, the winning solution from the Kaggle competitions performed on par with the best epidemiological models in April in terms of RMSLE—Root Mean Square Log Error, a measure of the differences between the log of predicted values and actual values—for predicting fatalities in 51 U.S. states and territories over the following 29 days. (Models may have been optimized for varying objective functions, and so this is an approximate comparison.)
Figure 2
“This competition series showed that it is still a challenging problem to solve and currently a combination of transforming data into a consumable format from various sources, understanding the difference in modelling short-term forecasts vs. long-term forecasts, and using simpler machine learning models with some adjustments seems to perform the best,” said Rohan Rao, a Kaggle competitor based in India. “I hope with more data availability and research of how the virus spreads in various countries, we should be able to add intelligent features to improve and optimize these forecasts and tune it for each geography.”
Participants have had success using advanced ensembles of machine learning models such as XGBoost and LightGBM (ex1, ex2, ex3). Participants have also identified important sources of external data that can potentially help to make more accurate predictions (ex1), including population size, population density, age distribution, smoking rates, economic indicators, and nation-wide lockdown dates. By examining the relative contribution of different model features using techniques such as feature importances and SHAP Values (SHapley Additive exPlanations), participants have been able to shed light on the factors that are most predictive in forecasting COVID-19 infections and fatalities. There is a lot of interesting work being done using neural networks and gradient boosted machines, and we encourage you to check out the code (Python/R), which has all been open-sourced.
Public data vs. COVID-19
Kaggle also hosted a dataset curation challenge with the goal of finding, curating, and sharing useful COVID-19-related datasets—especially those that can be useful for forecasting the virus’s spread. Winning submissions thus far include:
County-level Dataset for Informing the United States' Response to COVID-19: describes behaviors concerning demographics, healthcare, and social distancing interventions, that can potentially be used to predict the progress of the pandemic.
COVID-19 Lockdown Dates by Country: can potentially inform models by indicating a point in time when the rate of growth should slow.
COVID-19 Tests Conducted by Country: can potentially inform models of whether the increased number of infections is due to a spread of the disease or due to a spread of our testing capabilities.
By considering these regional policies, dates of enforcement, and testing protocols you can make much better data-driven conclusions.
Along those same lines, dataset publishers can also quickly spin up self-service tasks or challenges on Kaggle. For example, the Roche Data Science Coalition (RDSC) recently published a collection of publicly available COVID-related datasets and formed a challenge focused on attempting to answer the most pressing questions forwarded to them from frontline responders in healthcare and public policy. Kaggle is a free platform that allows all users to upload datasets, host data analysis challenges, and publish notebooks—and we encourage data scientists and data publishers to come together to fight COVID-19.
Looking ahead
Data scientists across the globe are collaborating to help the medical community to defeat COVID-19, and we could use your help. You can keep up-to-date with our challenges at kaggle.com/covid19, and see the progress our community is making towards achieving the goals we’ve discussed here at kaggle.com/covid-19-contributions.