How to evaluate the impact of LLMs on business outcomes
Ivan Nardini
Developer Relations Engineer
Irina Sigler
Product Manager, Cloud AI
How can you make sure that you are getting the desired results from your large language models (LLMs)? How to pick the model that works best for your use case? Evaluating the output of an LLM is one of the most difficult challenges in working with Generative AI. While these models excel across a wide range of tasks, understanding their performance for your specific use case is crucial.
Leaderboards and technical reports provide an overview of model capabilities, but a tailored evaluation approach is essential to pick the best model for your needs and align it with the appropriate tasks.
To address this challenge, we introduced the Vertex Gen AI Evaluation Service, which provides a toolkit that works for your specific use case with our set of quality controlled and explainable methods. It empowers you to make informed decisions throughout your development lifecycle, ensuring that your LLM applications reach their full potential.
This blog post introduces the Vertex Gen AI Evaluation Service, shows how to use it, and presents how Generali Italia used the Gen AI Evaluation Service to put a RAG-based LLM Application into production.
Evaluating LLMs with the Vertex Gen AI Evaluation Service
The Gen AI Evaluation Service empowers you to evaluate any model with our rich set of quality controlled and explainable evaluators, choosing between an interactive or asynchronous evaluation mode. In the following section, we dive into these three dimensions in a bit more detail:
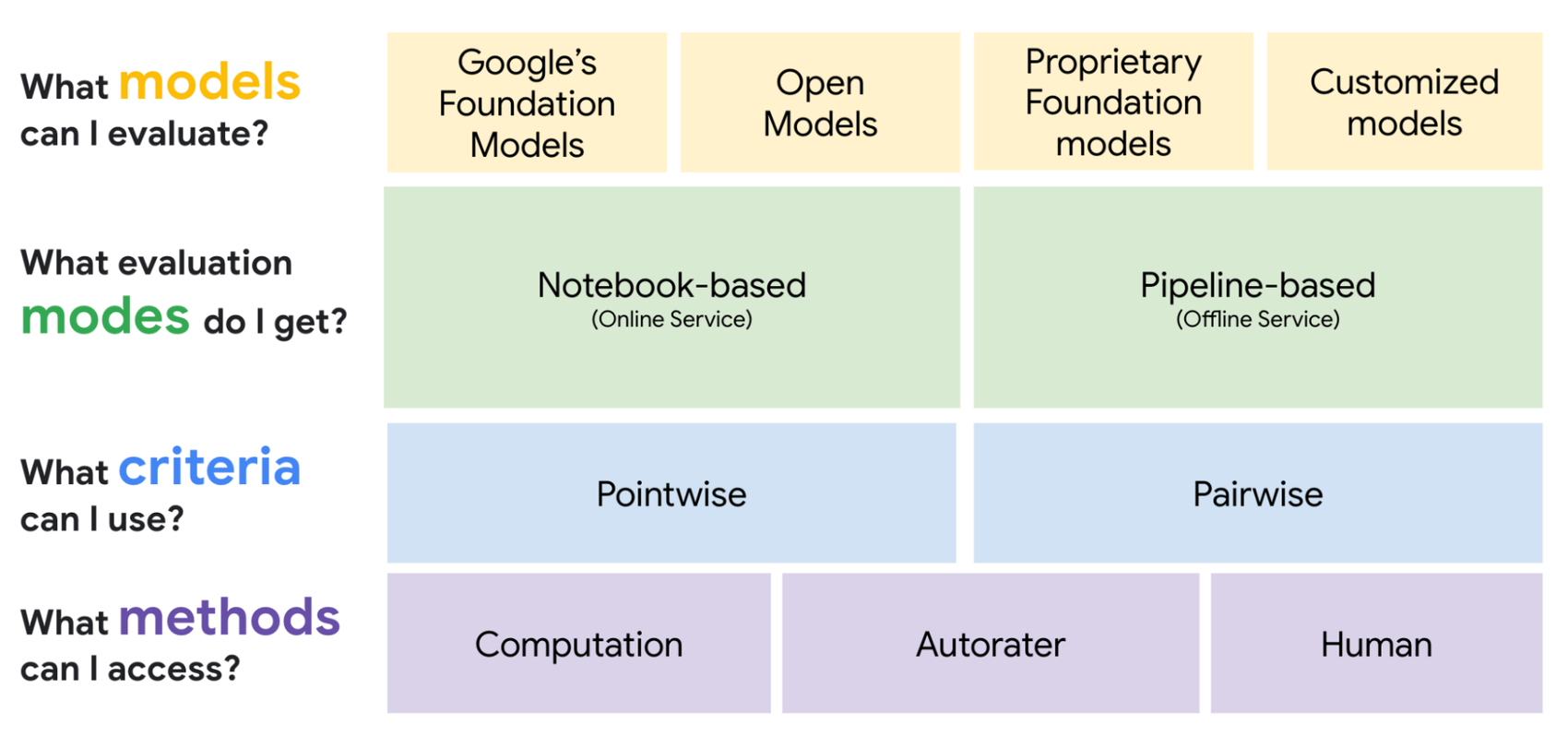
When you start developing a GenAI application, you have to make crucial decisions at various stages. Right at the very beginning of the development journey, you need to pick the right model for your task and design prompts that produce the optimal outputs. To speed up decision-making in this process of searching for the best fit between model, prompt and task, online evaluation helps iterate on prompt templates and compare models on the fly. However, evaluation is not limited to the initial stages of development. A more systematic offline evaluation using a large dataset is essential for robust benchmarking, e.g. to understand if tuning improved model performance or assess if a smaller model might do the job. After deployment, you need to continuously assess performance and check for the opportunity to upgrade. In essence, evaluation is not merely one step in the development process, but a continuous practice that Gen AI developers need to embrace.
To best support throughout the diverse set of evaluation use cases, the Gen AI Evaluation Service enables developers with both online and offline evaluations via the Vertex AI SDK within their preferred IDE or coding environments. All evaluations are autologged in Vertex AI Experiments so that you do not have to manually track experiments. The Gen AI Evaluation Service also provides pre-built pipeline components for running evaluation and monitoring in production using Vertex AI Pipelines.
The available evaluation methods can be grouped into three families. The first family is Computation-based metrics, which require ground truth and involve comparing a new output to a golden dataset of labeled input-output pairs. We maintain a rich library of pre-built metrics and give you the option to customize - you can define your evaluation criteria and implement any metric of your choice. To help you navigate through a wide range of available metrics, we also created metric bundles that get you to the right set of metrics per use case with only one click. In the following code, you have an example that shows how to use Vertex AI SDK for evaluating a summarization task.
The code uses metric bundles for evaluating a summarization task and it automatically logs evaluation parameters and metrics in Vertex AI Experiments. The resulting aggregated evaluation metrics can be visualized as the following:
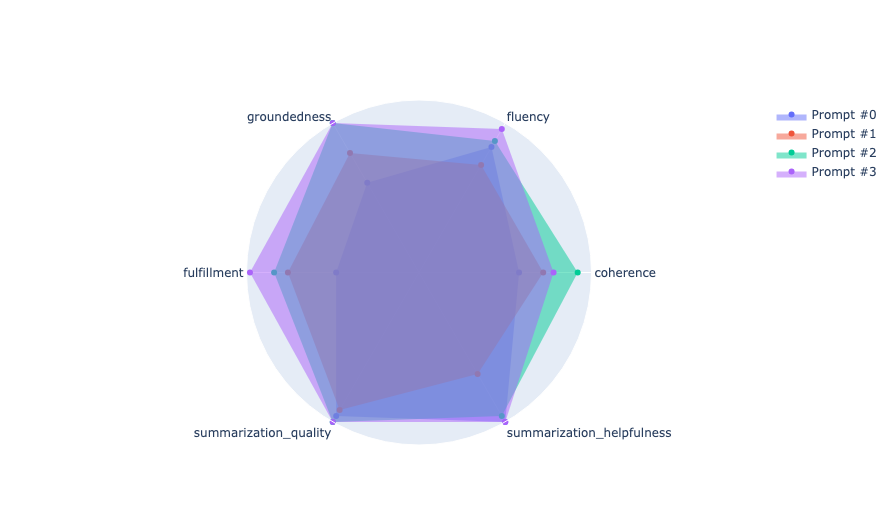
These metrics are efficient and inexpensive, providing a sense of progress. However, these metrics fall short in capturing the full essence of generative tasks. It is challenging to incorporate all desired summary qualities into a formula. Moreover, even with a carefully crafted golden dataset, you might prefer summaries that differ from the labeled examples. This is why you need an additional evaluation method to assess generative tasks.
Autoraters are the second family of methods and use LLMs as a judge. Here, an LLM is specifically tailored to perform the tasks of evaluation. This method does not require ground truth. You can choose to evaluate one model or compare two models against each other. Our autoraters are carefully calibrated with human raters to ensure their quality. They are managed and available out of the box. It is key to us that you can scrutinize and build trust in an autorater’s evaluation. And this is why we provide explanations for each judgment and a confidence score. The image below shows an exemplary AutoSxS output:
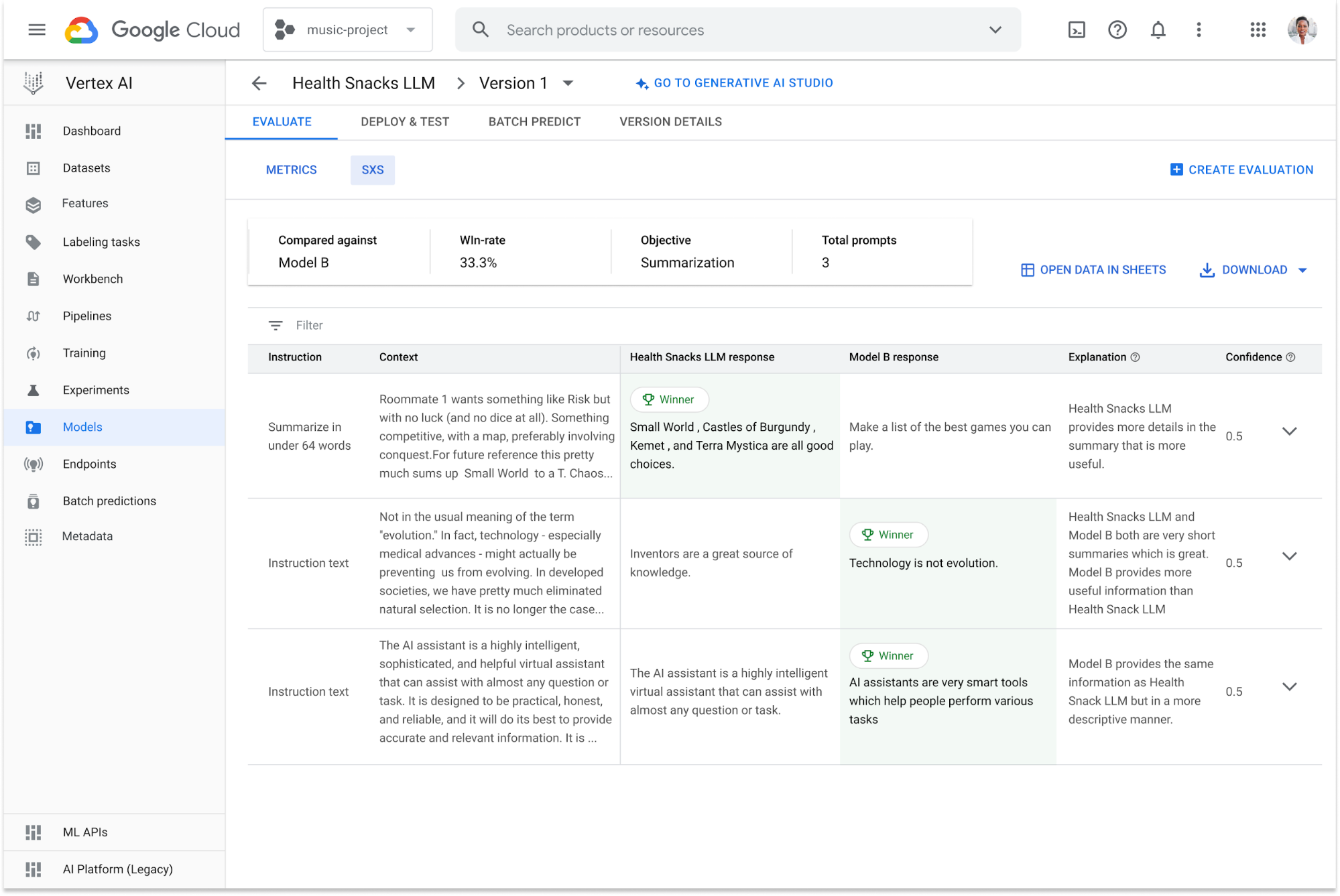
The overview box at the top offers a quick summary: It displays the inputs (competing models and evaluation dataset) and the overall result, known as the win rate. The win rate, expressed as a percentage, indicates how often Health Snacks LLM provided better summaries compared to Model B. To empower you to get a deeper understanding of the win rate, we also show the row-based results, accompanied by the autorater's explanations and confidence scores. By aligning the results and explanations with your expectations, you can evaluate the autorater’s accuracy for your use case. For each input prompt, the responses from the Health Snack LLM and Model B are listed. The response marked green with a winner icon in the top left corner represents the better summarization according to the autorater. The explanation provides the rationale behind the selection, and the confidence score indicates the autorater's certainty in their choice based on self-consistency.
In addition to the explanations and confidence scores, you can choose to calibrate the autorater to gain greater confidence in the accuracy and reliability of the overall evaluation process. To do this, you need to provide human-preference data directly to AutoSxS, which outputs alignment-aggregate statistics. These statistics measure the agreement between our autorater and the human-preference data, accounting for random agreement (Cohen’s Kappa).
While incorporating human evaluation is crucial, collecting human evaluations remains one of the most time-consuming tasks in the entire evaluation process. That is why we decided to integrate human review as the third family of methods of the GenAI Evaluation framework. And we partner with third-party data-centric providers such as LabelBox to help you easily access human evaluations against a wide range of tasks and criteria.
In conclusion, Gen AI Evaluation Service provides a rich set of methods, accessible through diverse channels (online and offline), that you can use with any LLM model to build your customized evaluation framework for efficiently assessing your GenAI application.
How Generali Italia used the Gen AI Evaluation Service to productionize a RAG-based LLM Application
Generali Italia, a leading insurance provider in Italy, was one of the first users of our Gen AI Evaluation Service. As Stefano Frigerio, Head of Technical Leads, Generali Italia, says:
“The model eval was the key to success in order to put a LLM in production. We couldn’t afford a manual check and refinement in a non-static ecosystem.”
Similar to other insurance companies, Generali Italia produces diverse documents, including policy statements, premium statements with detailed explanations and deadlines and more. Generali Italia created a GenAI application, leveraging retrieval-augmented generation (RAG) technology. This innovation empowers employees to interact with documents conversationally, expediting information retrieval. However, the application's successful deployment would not be possible without a robust framework to assess both its retrieval and generative functions. The team started by defining the dimensions of performance that mattered to them and used the Gen AI Evaluation Service to measure performance against their baseline.
According to Ivan Vigorito, Tech Lead Data scientist at Generali Italia, Generali Italia decided to use the Vertex Gen AI Evaluation Service for several reasons: The evaluation method AutoSxS gave Generali Italia access to autoraters that emulated human ratings in assessing the quality of LLM responses. This reduced the need for manual evaluation, saving both time and resources. Furthermore, the Gen AI Evaluation Service allowed the team to perform evaluations based on predefined criteria, making the evaluation process more objective. Thanks to explanations and confidence scores, the service helped make model performance understandable and guided the team to avenues for improving their application. Finally, the Vertex Gen AI Evaluation Service helped the Generali team in evaluating any model by using pre-generated or external predictions. This feature has been particularly useful for comparing outputs from models not hosted in Vertex AI.
According to Domenico Vitarella, Tech Lead Machine Learning Engineer in Generali Italia, the Gen AI Evaluation Service not only saves time and effort for their team when it comes to evaluation. It is seamlessly embedded within Vertex AI and allows the team access to a comprehensive platform for training, deploying, and evaluating both generative and predictive applications.
Conclusion
Are you struggling to evaluate your GenAI application?
The Gen AI Evaluation Service empowers you to build an evaluation system that works for your specific use case with our set of quality controlled and explainable methods over different modes. The Gen AI Evaluation Service helps you find the right model for your task, iterate faster and deploy with confidence.
What’s next
Do you want to know more about Gen AI Evaluation Service on Vertex AI? Check out the following resources:
Documentation
Notebooks
Videos and Blog posts



