Enabling connected transformation with Apache Kafka and TensorFlow on Google Cloud Platform
Kai Waehner
Technology Evangelist, Confluent
Editor’s note: Many organizations depend on real-time data streams from a fleet of remote devices, and would benefit tremendously from machine learning-derived, automated insights based on that real-time data. Founded by the team that built Apache Kafka, Confluent offers a a streaming platform to help companies easily access data as real-time streams. Today, Confluent’s Kai Waehner describes an example describing a fleet of connected vehicles, represented by Internet of Things (IoT) devices, to explain how you can leverage the open source ecosystems of Apache Kafka and TensorFlow on Google Cloud Platform and in concert with different Google machine learning (ML) services.
Imagine a global automotive company with a strategic initiative for digital transformation to improve customer experience, increase revenue, and reduce risk. Here is the initial project plan:

The main goal of this transformation plan is to improve existing business processes, rather than to create new services. Therefore, cutting-edge ML use cases like sentiment analysis using Recurrent Neural Networks (RNN) or object detection (e.g. for self-driving cars) using Convolutional Neural Networks (CNN) are out of scope and covered by other teams with longer-term mandates.
Instead, the goal of this initiative is to analyze and act on critical business events by improving existing business processes in the short term, meaning months, not years, to achieve some quick wins with machine learning:
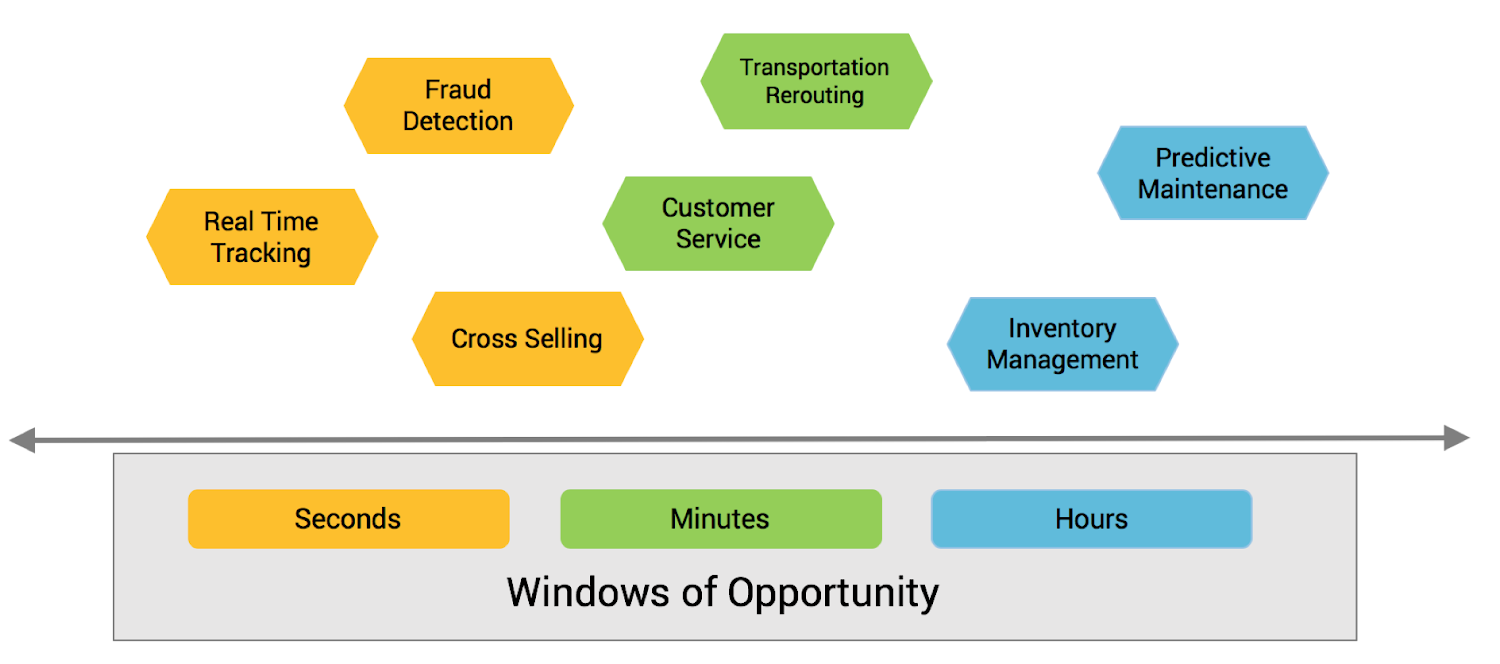
All these business processes are already in place, and the company depends on them. Our goal is to leverage ML to improve these processes in the near term. For example, payment fraud is a consistent problem in online platforms, and our automotive company can use a variety of data sources to successfully analyze and help identify fraud in this context. In this post, we’ll explain how the company can leverage an analytic model for continuous stream processing in real-time, and use IoT infrastructure to detect payment fraud and alert them in the case of risk.
Building a scalable, mission-critical, and flexible ML infrastructure
But before we can do that, let’s talk about the infrastructure needed for this project.
If you’ve spent some time with TensorFlow tutorials or its most popular wrapper framework, Keras, which is typically even easier to use, you might not think that building and deploying models is all that challenging. Today, a data scientist can build an analytic model with only a few lines of Python code that run predictions on new data with very good accuracy.
However, data preparation and feature engineering can consume most of a data scientist’s time. This idea may seem to contradict what you experience when you follow tutorials, because these efforts are already completed by the tutorial’s designer. Unfortunately, there is a hidden technical debt inherent in typical machine learning systems:
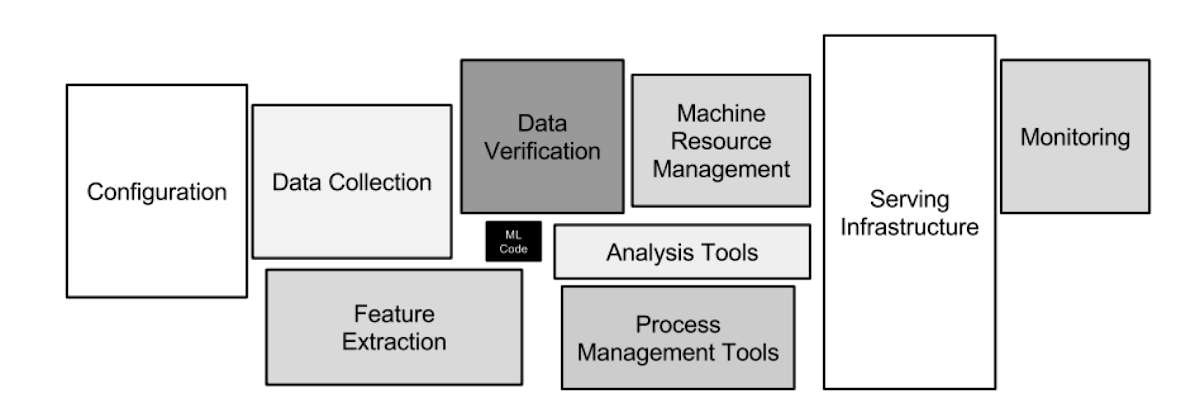
Thus, we need to ask the fundamental question that addresses how you’ll add real business value to your big data initiatives: how can you build a scalable infrastructure for your analytics models? How will you preprocess and monitor incoming data feeds? How will you deploy the models in production, on real-time data streams, at scale, and with zero downtime?
Many larger technology companies faced these challenges some years before the rest of the industry. Accordingly, they have already implemented their own solutions to many of these challenges. For example, consider:
- Netflix’ Meson: a scalable recommendation engine
- Uber’s Michelangelo: a platform and technology independent ML framework
- PayPal’s real time ML pipeline for fraud detection
All of these projects use Apache Kafka as their streaming platform. This blog post explains how to solve the above described challenges for your own use cases leveraging the open source ecosystem of Apache Kafka and a number of services on Google Cloud Platform (GCP).
Apache Kafka: the rise of a streaming platform
You may already be familiar with Apache Kafka, a hugely successful open source project created at LinkedIn for big data log analytics. But today, this is just one of its many use cases. Kafka evolved from a data ingestion layer to a feature-rich event streaming platform for all the use cases discussed above. These days, many enterprise data-focused projects build mission-critical applications around Kafka. As such, it has to be available and responsive, round the clock. If Kafka is down, their business processes stop working.
The practicality of keeping messaging, storage, and processing in one distributed, scalable, fault-tolerant, high volume, technology-independent streaming platform is the primary reason for the global success of Apache Kafka in many large enterprises, regardless of industry. For example, LinkedIn processes over 4.5 trillion messages per day1 and Netflix handles over 6 petabytes of data on peak days2.
Apache Kafka also enjoys a robust open source ecosystem. Let’s look at its components:
- Kafka Connect is an integration framework for connecting external sources / destinations into Kafka.
- Kafka Streams is a simple library that enables streaming application development within the Kafka framework. There are also additional Clients available for non-Java programming languages, including C, C++, Python, .NET, Go, and several others.
- The REST Proxy provides universal access to Kafka from any network connected device via HTTP.
- The Schema Registry is a central registry for the format of Kafka data—it guarantees that all data is in the proper format and can survive a schema evolution. As such, the Registry guarantees that the data is always consumable.
- KSQL is a streaming SQL engine that enables stream processing against Apache Kafka without writing source code.
All these open source components build on Apache Kafka’s core messaging and storage layers, leveraging its high scalability, high volume and throughput, and failover capabilities. Then, if you need coverage for your Kafka deployment, we here at Confluent offer round-the-clock support and enterprise tooling for end-to-end monitoring, management of Kafka clusters, multi-data center replication, and more, with Confluent Cloud on GCP. This Kafka ecosystem as a fully managed service includes a 99.95% service level agreement (SLA), guaranteed throughput and latency, and commercial support, while out-of-the-box integration with GCP services like Cloud Storage enable you to build out your scalable, mission-critical ML infrastructure.
Apache Kafka’s open-source ecosystem as infrastructure for Machine Learning
The following picture shows an architecture for your ML infrastructure leveraging Confluent Cloud for data ingestion, model training, deployment, and monitoring:

Now, with that background, we’re ready to build scalable, mission-critical ML infrastructure. Where do we start?
Replicating IoT data from on-premises data centers to Google Cloud
The first step is to ingest the data from the remote end devices. In the case of our automotive company, the data is already stored and processed in local data centers in different regions. This happens by streaming all sensor data from the cars via MQTT to local Kafka Clusters that leverage Confluent’s MQTT Proxy. This integration from devices to a local Kafka cluster typically is its own standalone project, because you need to handle IoT-specific challenges like constrained devices and unreliable networks. The integration can be implemented with different technologies, including low-level clients in C for microcontrollers, a REST Proxy for HTTP(S) communication, or an integration framework like Kafka Connect or MQTT Proxy. All of these components integrate natively with the local Kafka cluster so that you can leverage Kafka's features like high scalability, fault-tolerance and high throughput.
The data from the different local clusters then needs to be replicated to a central Kafka Cluster in GCP for further processing and to train analytics models:
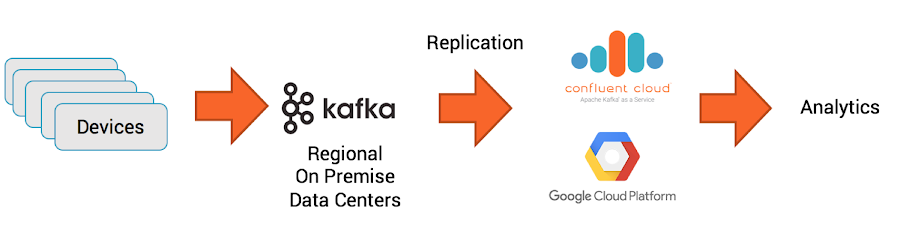
Confluent Replicator is a tool based on Kafka Connect that replicates the data in a scalable and reliable way from any source Kafka cluster—regardless of whether it lives on premise or in the cloud—to the Confluent Cloud on GCP.
GCP also offers scalable IoT infrastructure. If you want to ingest MQTT data directly into Cloud Pub/Sub from devices, you can also use GCP’s MQTT Bridge. Google provides open-source Kafka Connect connectors to get data from Cloud Pub/Sub into Kafka and Confluent Cloud so that you can make the most of KSQL with both first- and third-party logging integration.
Data preprocessing with KSQL
The next step is to preprocess your data at scale. You likely want to do this in a reusable way, so that you can ingest the data into other pipelines, and to preprocess the real-time feeds for predictions in the same way once you’ve deployed the trained model.
Our automotive company leverages KSQL, the open source streaming SQL engine for Apache Kafka, to do filtering, transformation, removal of personally identifiable information (PII), and feature extraction:
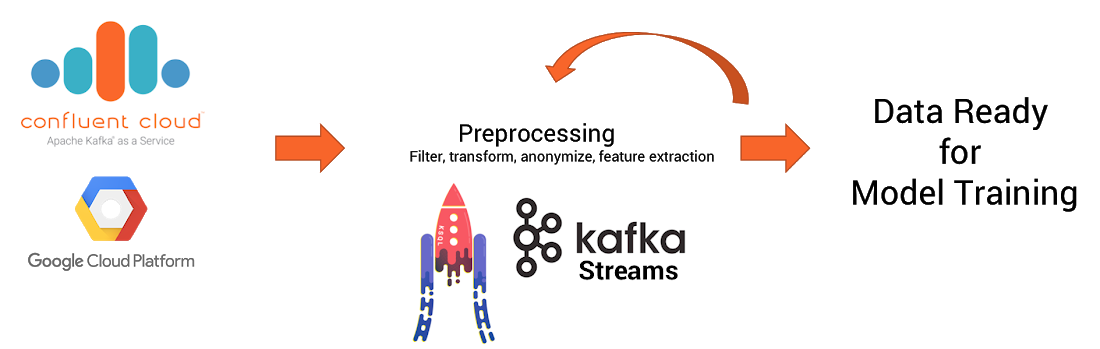
This results in several tangible benefits:
- High throughput and scalability, failover, reliability, and infrastructure-independence, thanks to the core Kafka infrastructure
- Preprocessing data at scale with no code
- Use SQL statements for interactive analysis and at-scale deployment to production
- Leveraging Python using KSQL’s REST interface
- Reusing preprocessed data for later deployment, even at the edge (outside of the cloud, possibly on embedded systems)
Here’s what a continuous query looks like:
You can then deploy this stream to one or more KSQL server instances to process all incoming sensor data in a continuous manner.
Data ingestion with Kafka Connect
After preprocessing the data, you need to ingest it into a data store to train your models. Ideally, you should format and store in a flexible way, so that you can use it with multiple ML solutions and processes. But for today, the automotive company focuses on using TensorFlow to build neural networks that perform anomaly detection with autoencoders as a first use case. They use Cloud Storage as scalable, long-term data store for the historical data needed to train the models.
In the future, the automotive company also plans to build other kinds of models using open source technologies like H2O.ai or for algorithms beyond neural networks. Deep Learning with TensorFlow is helpful, but it doesn’t fit every use case. In other scenarios, a random forest tree, clustering, or naïve Bayesian learning is much more appropriate due to simplicity, interpretability, or computing time.
In other cases, you might be able to reduce efforts and costs a lot by using prebuilt and managed analytic models in Google’s API services like Cloud Vision for image recognition, Cloud Translate for translation between languages, or Cloud Text-to-Speech for speech synthesis. Or if you need to build custom models, Cloud AutoML might be the ideal solution to easily build out your deployment without the need for a data scientist.
You can then use Kafka Connect as your ingestion layer because it provides several benefits:
- Kafka’s core infrastructure advantages: high throughput and scalability, fail-over, reliability, and infrastructure-independence
- Out-of-the-box connectivity to various sources and sinks for different analytics and non-analytics use cases (for example, Cloud Storage, BigQuery, Elasticsearch, HDFS, MQTT)
- A set of out-of-the-box integration features, called Simple Message Transformation (SMT), for data (message) enrichment, format conversion, filtering, routing, and error-handling
Model training with Cloud ML Engine and TensorFlow
After you’ve ingested your historical data into Cloud Storage, you’re now able to train your models at extreme scale using TensorFlow and TPUs on Google ML Engine. One major benefit of running your workload on a public cloud is that you can use powerful hardware in a flexible way. Spin it up for training and stop it when finished. The pay-as-you-go principle allows you to use cutting-edge hardware while still controlling your costs.
In the case of our automotive company, it needs to train and deploy custom neural networks that include domain-specific knowledge and experience. Thus, they cannot use managed, pre-fabricated ML APIs or Cloud AutoML here. Cloud ML Engine provides powerful API and an easy-to-use web UI to train and evaluate different models:
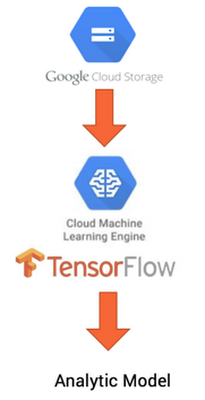
Although Cloud ML Engine supports other frameworks, TensorFlow is a great choice because it is open source and highly scalable, features out-of-the-box integration with GCP, offers a variety of tools (like TensorBoard for Keras), and has grown a sizable community.
Replayability with Apache Kafka: a log never forgets
With Apache Kafka as the streaming platform in your machine learning infrastructure, you can easily:
- Train different models on the same data
- Try out different ML frameworks
- Leverage Cloud AutoML if and where appropriate
- Do A/B testing to evaluate different models
The architecture lets you leverage other frameworks besides TensorFlow later—if appropriate. Apache Kafka allows you to replay the data again and again over time to train different analytic models with the same dataset:
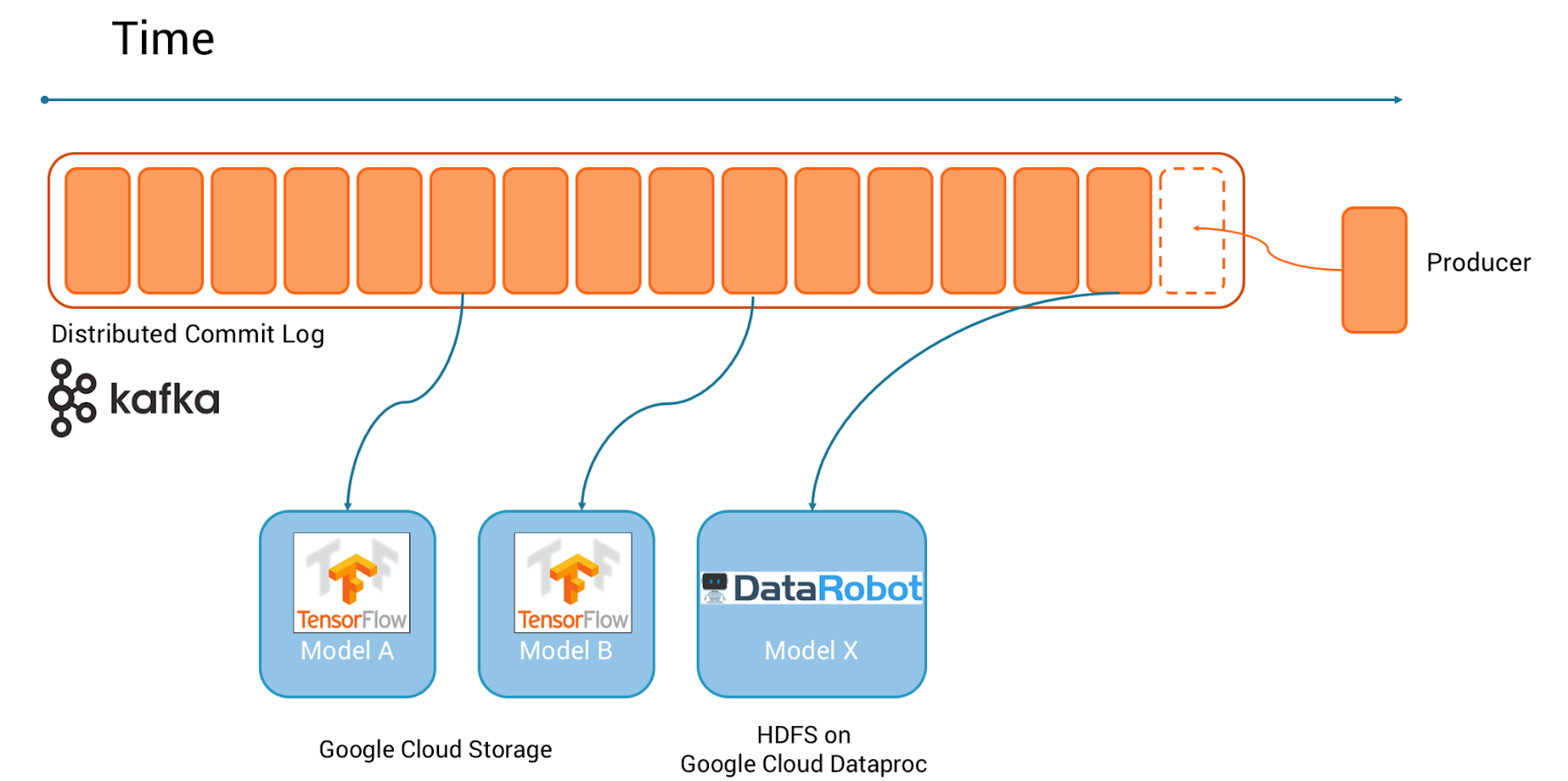
In the above example, using TensorFlow, you can train multiple alternative models on historical data stored in Cloud Storage. In the future, you might want or need to use other machine learning techniques. For example, if you want to offer AutoML services to less experienced data scientists, you might train Google AutoML on Cloud Storage, or experiment with alternative, third party AutoML solutions like DataRobot or H2O Driverless, which leverage HDFS as storage on Cloud Dataproc, a managed service for Apache Hadoop and Spark.
Alternative methods for model deployment and serving (inference)
The automotive company is now ready to deploy its first models to do real-time predictions at scale. Two alternatives exist for model deployment:
Option 1: RPC communication for model inference on your model server
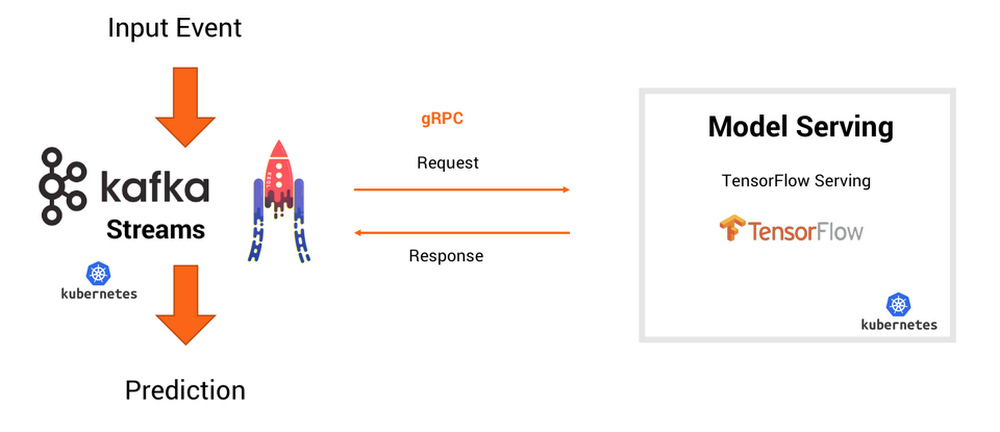
Cloud ML Engine allows you to deploy your trained models directly to a model server (based on TensorFlow Serving).
Pros of using a model server:
- Simple integration with existing technologies and organizational processes
- Easier to understand if you come from the non-streaming (batch) world
- Ability to migrate to true streaming down the road
- Model management built-in for different models, versioning and A/B testing
Option 2: Integrate model inference natively into your streaming application
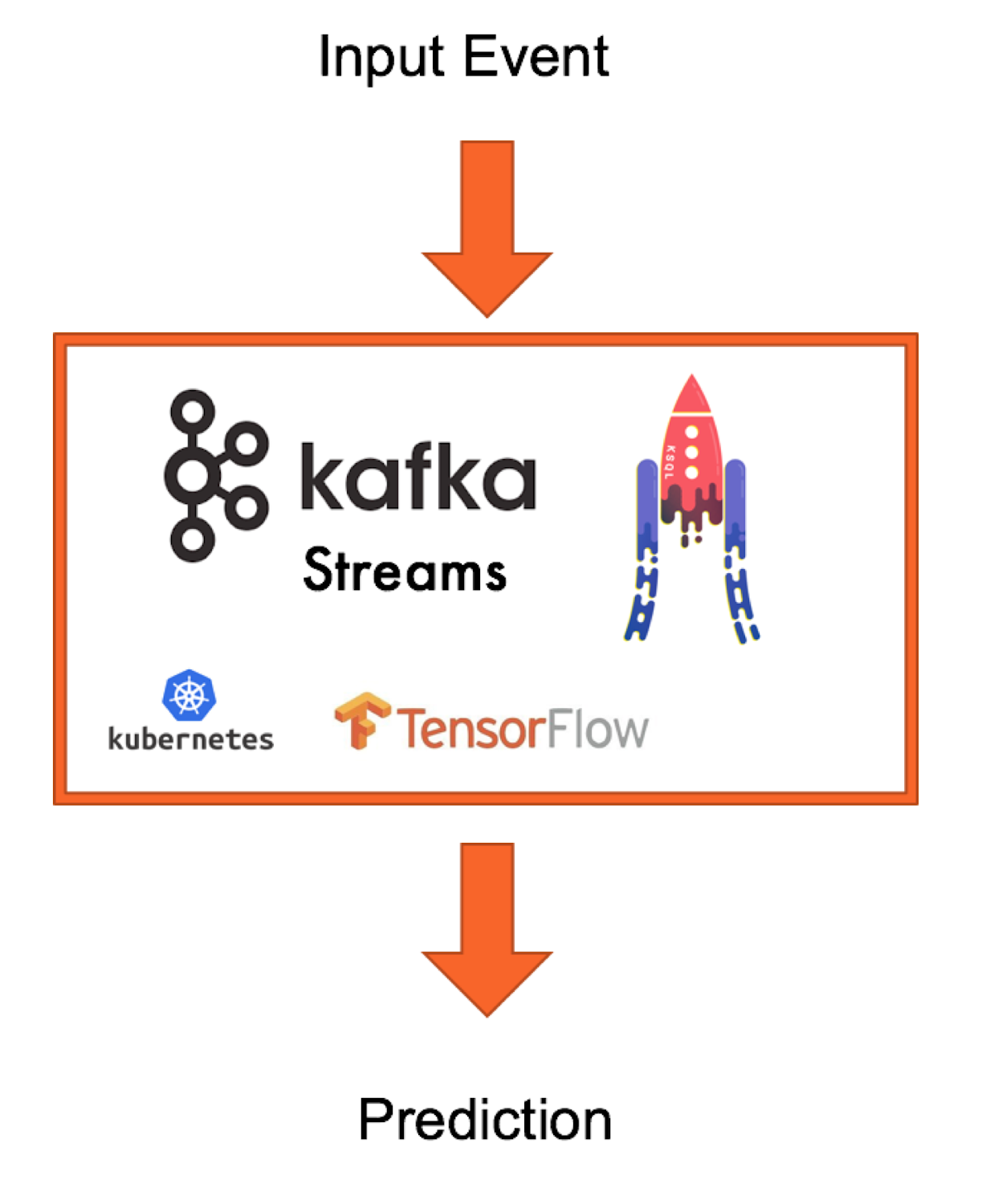
Here are some challenges you might encounter as you deploy your model natively in your streaming application:
- Worse latency: classification requires a remote call instead of local inference
- No offline inference: on a remote or edge device, you might have limited or no connectivity
- Coupling the availability, scalability, and latency/throughput of your Kafka Streams application with the SLAs of the RPC interface
- Outliers or externalities (e.g., in case of failure) not covered by Kafka processing
For each use case, you have to assess the trade-offs and decide whether you want to deploy your model in a model server or natively in the application.
Deployment and scalability of your client applications
Confluent Cloud running in conjunction with GCP services ensures high availability and scalability for the machine learning infrastructure described above. You won’t need to worry about operations, just use the components to build your analytic models. However, what about the deployment and dynamic scalability of the Kafka clients, which use the analytic models to do predictions on new incoming events in real-time?
You can write these clients using any programming language like (Java, Scala, .NET, Go, Python, JavaScript), Confluent REST Proxy, Kafka Streams or KSQL applications. Unlike on a Kafka server, clients need to scale dynamically to accommodate the load. Whichever option you choose for writing your Kafka clients, Kubernetes is a more and more widely adopted solution that handles deployment, dynamic scaling, and failover. Although it would be out of scope to introduce Kubernetes in this post, Google Kubernetes Engine Quickstart Guide can help you set up your own Kubernetes cluster on GCP in minutes. If you need to learn more details about the container orchestration engine itself, Kubernetes’ official website is a good starting point.
The need for local data processing and model inference
If you’ve deployed analytics models on Google Cloud, you’ll have noticed that the service (and by extension, GCP) takes over most of the burden of deployment and operations. Unfortunately, migrating to the cloud is not always possible due to legal, compliance, security, or more technical reasons.
Our automotive company is ready to use the models it built for predictions, but all the personally identifiable information (PII) data needs to be processed in its local data center. However, this demand creates a challenge, because the architecture (and some future planned integrations) would be simpler if everything were to run within one public cloud.
Self-managed on-premise deployment for model serving and monitoring with Kubernetes
On premises, you do not get all the advantages of GCP and Confluent Cloud—you need to operate the Apache Kafka cluster and its clients yourself.
What about scaling brokers, external clients, persistent volumes, failover, and rolling upgrades? Confluent Operator takes over the challenge of operating Kafka and its ecosystem on Kubernetes, with automated provisioning, scaling, fail-over, partition rebalancing, rolling updates, and monitoring.
For your clients, you face the same challenges as if you deploy in the cloud. What about dynamic load-balancing, scaling, and failover? In addition, if you use a model server on premise, you also need to manage its operations and scaling yourself.
Kubernetes is an appropriate solution to solve these problems in an on-premises deployment. Using it both on-premises and on Google Cloud allows you to re-use past lessons learned and ongoing best practices.
Confluent schema registry for message validation and data governance
How can we ensure that every team in every data center gets the data they’re looking for, and that it’s consistent across the entire system?
- Kafka’s core infrastructure advantages: high throughput and scalability, fail-over, reliability, and infrastructure-independence
- Schema definition and updates
- Forward- and backward-compatibility
- Multi-region deployment
A mission-critical application: a payment fraud detection system
Let’s begin by reviewing the implementation of our first use case in more detail, including some code examples. We now plan to analyze historical data about payments for digital car services (perhaps for a car’s mobile entertainment system or paying for fuel at a gas station) to spot anomalies indicating possible fraudulent behavior. The model training happens in GCP, including preprocessing that anonymizes private user data. After building a good analytic model in the cloud, you can deploy it at the edge in a real-time streaming application, to analyze new transactions locally and in real time.
Model training with TensorFlow on TPUs
Our automotive company trained a model in Cloud ML Engine. They used Python and Keras to build an autoencoder (anomaly detection) for real-time sensor analytics, and then trained this model in TensorFlow on Cloud ML Engine leveraging Cloud TPUs (Tensor Processing Units):
Google Cloud’s documentation has lots of information on how to train a model with Cloud ML Engine, including for different frameworks and use cases. If you are new to this topic, the Cloud ML Engine Getting Started guide is a good start to build your first model using TensorFlow. As a next step, you can walk through more sophisticated examples using Google ML Engine, TensorFlow and Keras for image recognition, object detection, text analysis, or a recommendation engine.
The resulting, trained model is stored in Cloud Storage and thus can either deployed on a “serving” instance for live inference, or downloaded for edge deployment, as in our example above.
Model deployment in KSQL streaming microservices
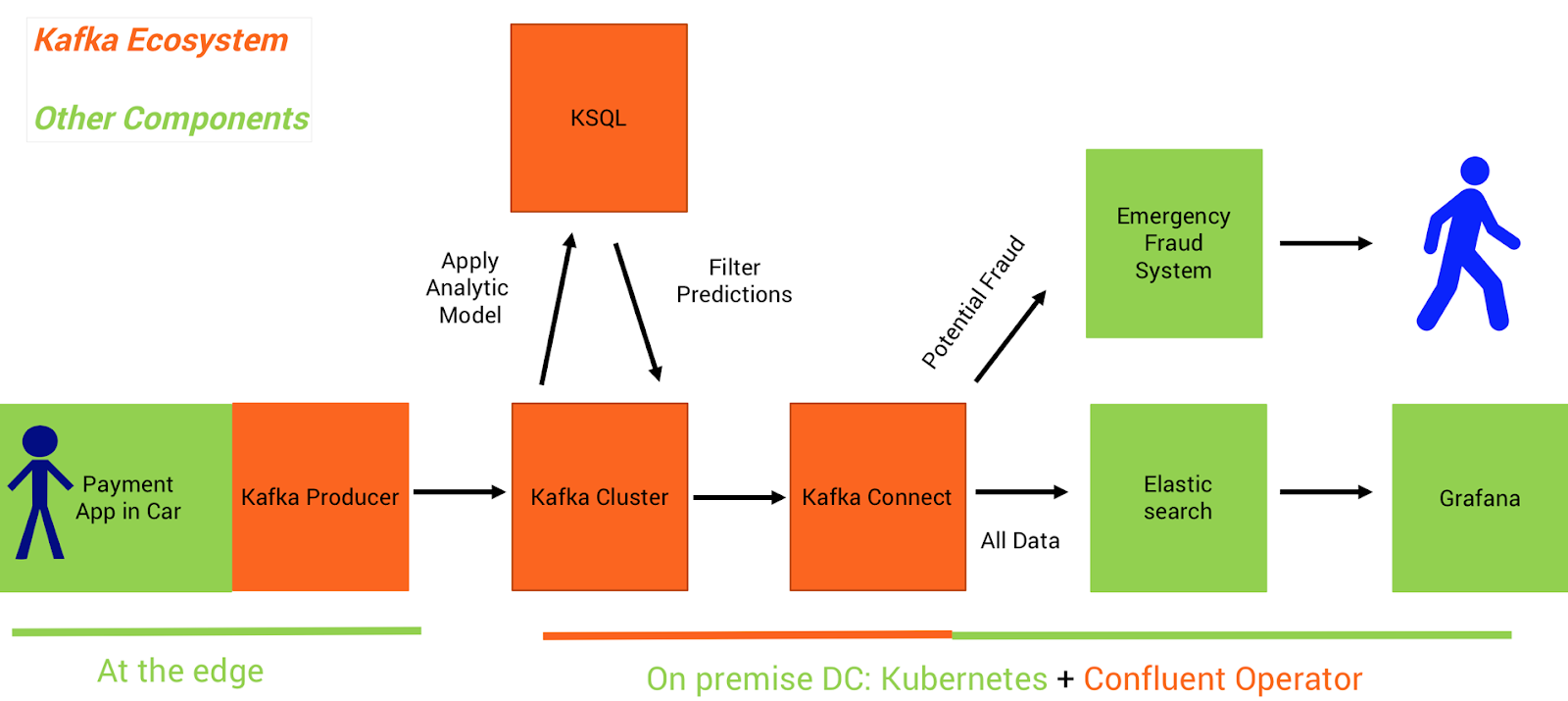
There are different ways to build a real-time streaming application in the Kafka ecosystem. You can build your own application or microservice using any Kafka Client API (Java, Scala, .NET, Go, Python, node.js, or REST). Or you might want to leverage Kafka Streams (writing Java code) or KSQL (writing SQL statements)—two lightweight but powerful stream-processing frameworks that natively integrate with Apache Kafka to process high volumes of messages at scale, handle failover without data loss, and dynamically adjust scale without downtime.
Here is an example of model inference in real-time. It is a continuous query that leverages the KSQL user-defined function (UDF) ‘applyFraudModel’, which embeds an autoencoder:
You can deploy this KSQL statement as a microservice to one or more KSQL servers. The called model performs well and scales as needed, because it uses the same integration and processing pipeline for both training and deploying the model, leveraging Kafka Connect for real-time streaming ingestion of the sensor data, and KSQL (with Kafka Streams engine under the hood) for preprocessing and model deployment.
You can build your own stateless or stateful UDFs for KSQL easily. You can find the above KSQL ML UDF and a step-by-step guide on using MQTT sensor data.
If you’d prefer to leverage Kafka Streams to write your own Java application instead of writing KSQL, you might look at some code examples for deployment of a TensorFlow model in Kafka Streams.
Monitoring your ML infrastructure
On GCP, you can leverage tools like Stackdriver, which allows monitoring and management for services, containers, applications, and infrastructure. Conventionally, organizations use Prometheus and JMX notifications for notifications and updates on their Kubernetes and Kafka integrations. Still, there is no silver bullet for monitoring your entire ML infrastructure, and adding an on-premises deployment creates additional challenges, since you have to set up your own monitoring tools instead of using GCP.
Feel free to use the monitoring tools and frameworks you and your team already know and like. Ideally, you need to monitor your data ingestion, processing, training, deployment, accuracy, A/B testing workloads all in a scalable, reliable way. Thus, the Kafka ecosystem and GCP can provide the right foundation for your monitoring needs. Additional frameworks, services, or UIs can help your team to effectively monitor its infrastructure.
Scalable, mission-critical machine learning infrastructure with GCP and Confluent Cloud
In sum, we’ve shown you how you might build scalable, mission-critical, and even vendor-agnostic machine learning infrastructure. We’ve also shown you how you might leverage the open source Apache Kafka ecosystem to do data ingestion, processing, model inference, and monitoring. GCP offers all the compute power and extreme scale to run the Kafka infrastructure as a service, plus out-of-the-box integration with platform services such as Cloud Storage, Cloud ML Engine, GKE, and others. No matter where you want to deploy and run your models (in the cloud vs. on-premises; natively in-app vs. on a model server), GCP and Confluent Cloud are a great combination to set up your machine learning infrastructure.
If you need coverage for your Kafka deployment, Confluent offers round-the-clock support and enterprise tooling for end-to-end monitoring, management of Kafka clusters, multi-data center replication, and more. If you’d like to learn more about Confluent Cloud, check out:
- The Confluent Cloud site, which provides more information about Confluent’s Enterprise and Professional offerings.
- The Confluent Cloud Professional getting started video.
- Our instructions to spin up your Kafka cloud instance on GCP here.
- Our community Slack group, where you can post questions in the #confluent-cloud channel.
1. https://conferences.oreilly.com/strata/strata-ca/public/schedule/detail/63921
2. https://qconlondon.com/london2018/presentation/cloud-native-and-scalable-kafka-architecture



