Empower your AI Platform-trained serverless endpoints with machine learning on Google Cloud Functions
Hannes Hapke
VP of AI and Engineering, Caravel
Editor’s note: Today’s post comes from Hannes Hapke at Caravel. Hannes describes how Cloud Functions can accelerate the process of hosting machine learning models in production for conversational AI, based on serverless infrastructure.
At Caravel, we build conversational AI for digital retail clients — work that relies heavily on Google Cloud Functions. Our clients experience website demand fluctuations that vary by the day of the week or even by time-of-day. Because of the constant change in customer requests, Google Cloud Platform’s serverless endpoints help us handle fluctuating demand for our service. Unfortunately, serverless functions are limited in available memory and CPU cycles, which makes them an odd place to deploy machine learning models. However, Cloud Functions offer a tremendous ease in deploying API endpoints, so we decided to integrate machine learning models without deploying them to the endpoints directly.
If your organization is interested in using serverless functions to help address its business problems, but you are unsure how you can use your machine learning models with your serverless endpoints, read on. We’ll explain how our team used Google Cloud Platform to deploy machine learning models on serverless endpoints. We’ll focus on our preferred Python solution and outline some ways you can optimize your integration. If you would prefer to build out a Node.js implementation, check out “Simplifying ML Prediction with Google Cloud Functions.”
Architecture Overview
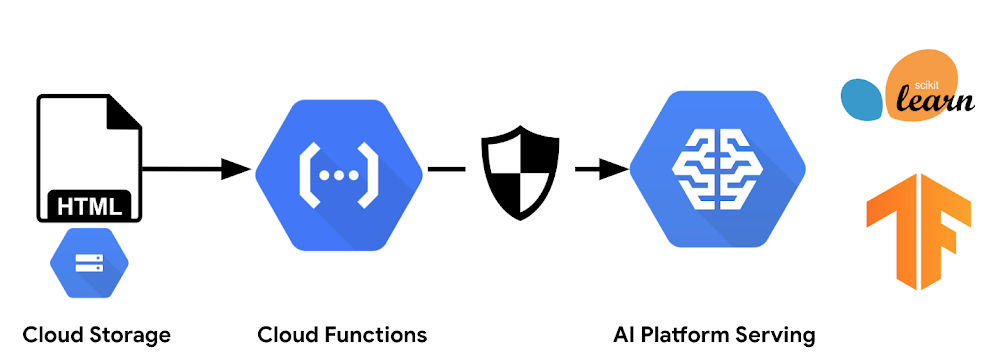
First, let’s start with the architecture. As shown in Figure 1, this example consists of three major components: a static page accessible to the user, a serverless endpoint that handles all user requests, and a model instance running on AI Platform. While other articles suggest loading the machine learning model directly onto the serverless endpoint for online predictions, we found that approach to have a few downsides:
Loading the model will increase your serverless function memory footprint, which can accrue unnecessary expenses.
The machine learning model has to be deployed with the serverless function code, meaning the model can’t be updated independently from a code deployment.
For the sake of simplicity, we’re hosting the model for this example on an AI Platform serving instance, but we could also run our own Tensorflow Serving instance.
Model setup
Before we describe how you might run your inference workload from a serverless endpoint, let’s quickly set up the model instance on Cloud AI Platform.
1. Upload the latest exported model to a Cloud Storage bucket. We exported our model from TensorFlow’s Keras API.
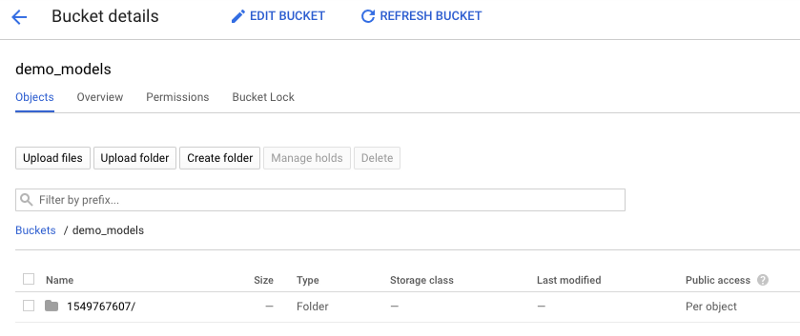
Create a bucket for your models and upload the latest trained model into its own folder.
2. Head over to AI Platform from the Console and register a new model.
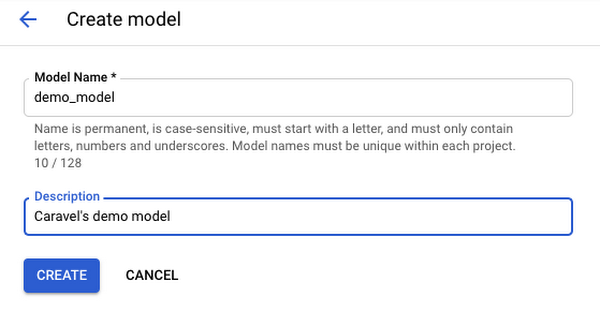
Set up a new model on AI Platform.
3. After registering the model, set up a new model version, probably your V1. To start the setup steps, click on ‘Create version.’
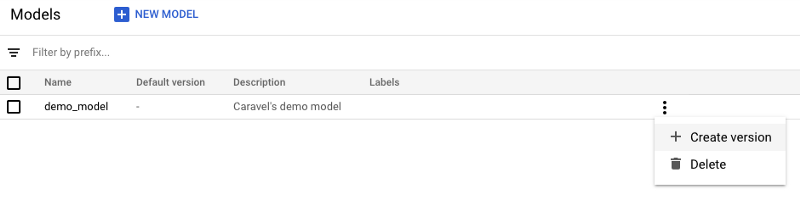
Note: Under Model URI link to the Cloud Storage Bucket where you saved the exported model.
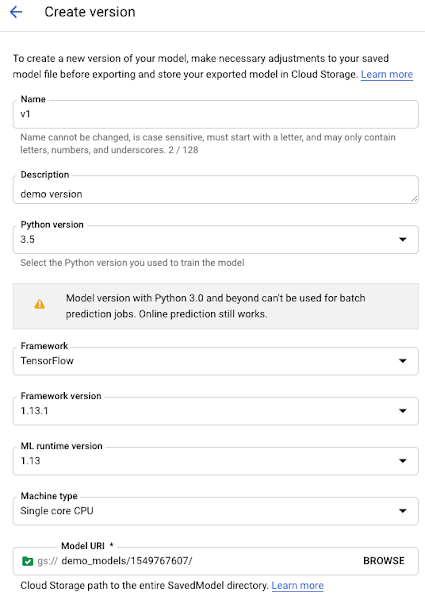
You can choose between different ML frameworks. In our case, our model is based on TensorFlow 1.13.1.
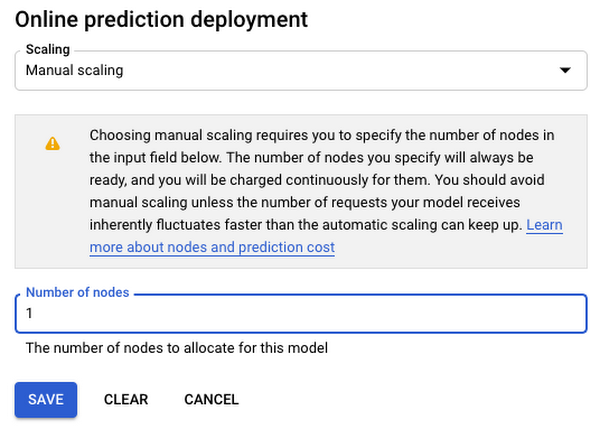
For our demo, we disable model autoscaling.
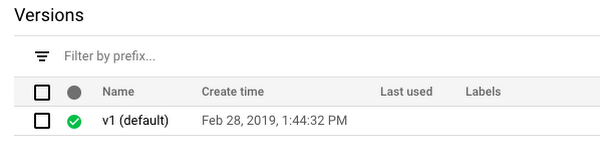
Once the creation of the instance is completed and the model is ready to serve, you’ll see a green icon next to the model’s version name.
Inferring a prediction from a serverless endpoint
Inferring a prediction with Python is fairly straightforward. You need to generate a payload that you would like to submit to the model endpoint, and then you submit it to that endpoint. We’ll cover the generation of the payload in the following sections, but for now, let’s focus on inferring an arbitrary payload.
Google provides a Python library google-api-python-client that allows you to access its products through a generic API interface. You can install it with:
Once installed, you need to “discover” your desired service. In our case, the service name is ml. However, you aren’t limited to just the prediction functionality; depending on your permissions (more later on that), you can access various API services of AI Platform. You’ll now want to execute any API request you created thus far. If you don’t encounter any errors, the response should contain the model’s response: its prediction.
Permissions
Cloud Functions on Google Cloud Platform execute all requests as the user with the id:
By default, your account has Editor permissions for the entire project, and you should be able to execute online predictions. At the time of this blog post’s publication, you can’t control permissions per serverless function, but if you want to try out the functionality yourself, sign up for the Alpha Tester Program.
Generating a request payload
Before submitting our inference request, you need to generate your payload with the input data for the model. At Caravel, we trained a deep learning model to classify the sentiment of sentences. We developed our model on Keras and TensorFlow 1.13.1, and because we wanted to limit the amount of preprocessing required on the client side, we decided to implement our preprocessing steps with TensorFlow (TF) Transform. Using TF Transform has multiple advantages:
Preprocessing can occur server-side.
Because the preprocessing runs on the server side, you can update the preprocessing functionality without affecting the clients. If this weren’t the case, you could imagine a situation like the following: if you perform the preprocessing in a mobile client, you would have to update all clients in case you implement changes or provide new endpoints for every change (not scalable).
The preprocessing steps are consistent between the training, validation, and serving stages. Changes to the preprocessing steps will force you to re-train the model, which avoids misalignment between these steps and already trained models.
You can transform the dataset nicely and train and validate your datasets efficiently, but at time of writing, you still need to convert your Keras model to a TensorFlow Estimator, in order to properly integrate TF Transform with Keras. With TensorFlow Transform, you can submit raw data strings as inputs to the model. The preprocessing graph, which is running in conjunction with the model graph, will convert your string characters first into character indices and then into embedding vectors.
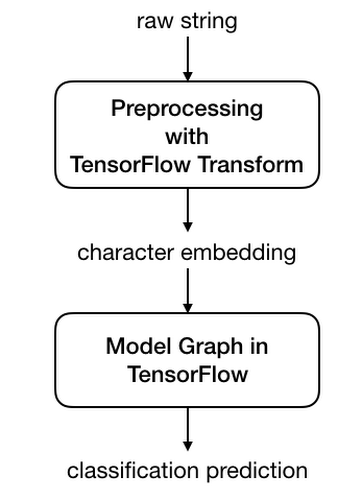
Connecting the preprocessing graph in TF Transform with our TensorFlow model
Our AI Platform instance and any TensorFlow Serving instance both expect a payload dictionary that includes the key instances, which contains a list of input dictionaries for each inference. You can submit multiple input dictionaries in a single request; the model server can infer the predictions all in a single request through the amazing batching feature of TensorFlow Serving. Thus, the payload for your sentence classification demo should look like this:
We moved the generation step into its own helper function to allow for potential manipulation of the payload—when we want to lower-case or tokenize the sentences, for example. Here, however, we have not yet included such manipulations.
_connect_service provides us access to the AI platform service with the service name “ML”. At the time of writing this post, the current version was “v1”. We have encapsulated the service discovery into its own function to be able to add more parameters like account credentials, if needed.
Once you generate a payload in the correct data structure and have access to the GCP service, you can infer predictions from the AI Platform instance. Here is an example:
Obtaining model meta-information from the AI Platform training instance
Something amazing happens when the Cloud Function setup interacts with the AI Platform instance: the client can infer predictions without any knowledge of the model. You don’t need to specify the model version during the inference, because the AI Platform Serving instance handles that for you. However, it’s generally very useful to know which version was used for the prediction. At Caravel, we track our models’ performance extensively, and our team prioritizes knowing when each model was used and deployed and consider this to be essential information.
Obtaining the model meta information from the AI Platform instance is simple, because the Serving API has its own endpoint for requesting the model information. This helps a lot when you perform a large number of requests and only need to obtain the meta information once.
The little helper function below obtains model information for any given model in a project. You’ll need to call two different endpoints, depending on whether we want to obtain the information for a specific model version or just for the default model. You can specify this in the AI Platform Command Console.
Here is a brief example of metadata returned from the AI Platform API endpoint:
Conclusion
Serverless functions have proven very useful to our team, thanks to their scalability and ease of deployment. The Caravel team wanted to demonstrate that both concepts can work together easily and share our best practices, as machine learning becomes an essential component of a growing number of today’s leading applications.
In this blog post, we introduced the setup of a machine learning model on AI Platform and how to infer model predictions from a Python 3.7 Cloud Function. We also reviewed how you might structure your prediction payloads, as well as an overview of how you can request model metadata from the model server. By splitting your application between the Cloud Functions and AI Platform, you can deploy your legacy applications in an efficient and cost-effective manner.
If you’re interested in ways to reduce network traffic between your serverless endpoints, we recommend our follow-up post on how to generate model request payloads with the ProtoBuf serialization format. To see this example live, check out our demo endpoint here, and if you want to start with some source code to build your own, you can find it in the ML on GCP GitHub repository.
Acknowledgements: Gonzalo Gasca Meza, Developer Programs Engineer contributed to this post.



