Ask your documents: Document AI and PaLM2 for question answering
Mona Mona
AI/ML Specialist
Jill Daley
Product Manager
Documents, physical or digital, contain a goldmine of information—assuming all that data and content can actually be leveraged to help employees to do their jobs. Internal IT and content management teams have long sought to provide knowledge workers with the ability to interact with a document — or better yet, a corpus of documents — without needing to manually dig through them.
This goal went unfulfilled for years because, prior to generative AI models such as PaLM 2, technologies struggled to provide the contextual understanding required to perform question-and-answering across different document types. Today, however, developers can build an “Ask your documents” tool for employees by leveraging Google Cloud Document AI, text embedding models, and PaLM 2. In this post, we’ll show you how.
Why use Document AI and PaLM2 to build a document Q&A application
Document Question-Answering (Document Q&A) involves extracting information from a given document to answer questions in natural language. The use cases applicable to this type of workflow cover a wide variety of industries and domains. For example:
- Lawyers and legal professionals can use Document Q&A to search through legal documents, statutes, and case law to find relevant information and precedents for their cases.
- Students and educators can benefit from Document Q&A to better understand concepts in research papers, textbooks, and educational materials.
- IT support teams can employ Document Q&A to help resolve technical issues by quickly finding information from technical documentation and troubleshooting guides.
A retrieval Augmented Generation (RAG) can help you to generate more accurate and informative answers to questions by grounding responses in relevant information from a knowledge base, such as a vector store. For this task, Document AI OCR (optical character recognition) and PaLM provide powerful capabilities.
The solution and architecture proposed in this blog create a serverless and scalable framework for implementing a RAG-based architecture at scale. Here, we’ll focus on Q&A use cases for long documents.
High-level architecture
For the purpose of this post, we used Document AI, which provides high-quality, enterprise-ready AI document processing models. It’s a fully managed, scalable, and serverless solution capable of processing millions of documents without needing to spin up infrastructure.
More specifically, we used Enterprise Document OCR, a pre-trained model that extracts text and layout information from document files. We also used the textembedding-gecko model from Vertex AI to create a text embedding — a vector representation of text — with generative AI. Lastly, we leveraged PaLM2, specifically the Vertex AI text-bison foundation model, to answer questions on the embedding data store. Below is a diagram of the serverless architecture for Document Q&A with Document AI and PaLM2 generative AI foundation models:
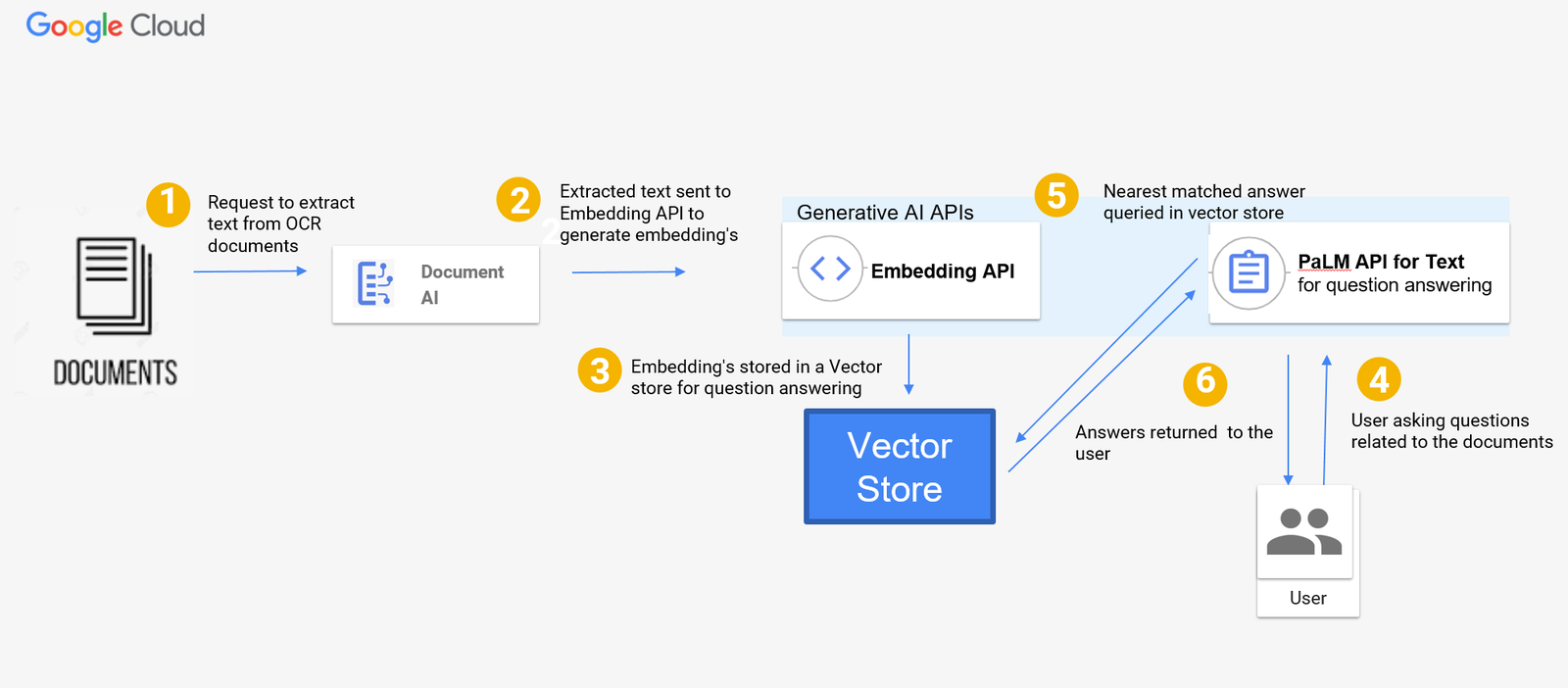
The flow in the architecture diagram for the Q&A tool can be described as follows:
- Documents, such as scanned PDFs or images, are sent to Document AI for OCR processing and text extraction.
- The extracted text is sent to the textembedding-gecko model to generate embeddings.
- Embeddings can be stored in any vector store. In this blog, we didn’t use a vector store and instead stored the vectors in a data structure to show you what the implementation is for a small set of documents. However, in order to scale the solution, you can use vector search, a petabyte-scale vector store to store the embeddings.
- A user asks questions related to the documents.
- The PaLM text-bison model searches the vector store and outputs the answer using the most similar embeddings in the vector store.
- The response is returned to the user.
Implementation
Now that we’ve explored the architecture, we’ll outline the high-level steps required to build a Q&A tool so that you can architect a Question-Answering application using Vertex AI SDKs.
You can follow along using this notebook, which provides additional step-by-step details for implementation.
Getting Started
For our example, we used Alphabet earnings reports. You can find the PDFs hosted in this public Google Cloud Storage bucket:
Step 1: Create a Document AI OCR processor
A Document AI processor is an interface between a document file and a machine learning model that performs document processing actions. Processors can be used to classify, split, parse, or analyze a document. Each Google Cloud project needs to create its own processor instances.
The Document AI processor takes a PDF or image file as input and outputs the data in the Document format. We used the Python Client for Document AI library to create an Enterprise Document OCR processor and then called this processor method to process documents.
Step 2: Process the documents
With the Enterprise Document OCR processor you just created, you can start processing documents. To process documents, provide the processor name and file path as input to invoke the document processing function below:
Step 3: Create data chunks
For some tasks, solutions like Vertex AI Search let you simply select a corpus of documents – but for the most flexibility, a bespoke approach may help your company to balance cost, complexity, and accuracy. For these custom implementations, LLMs produce the best results when a document’s text is broken up into small 'chunks' before being added to the prompt. Chunking is a technique used to break a document into smaller chunks that are easier to process. This can be done by dividing the document into sentences, paragraphs, or even sections.
The current token size limit for the PaLM2 text-bison@02 model is 8,196 tokens. This means that a single request to the PaLM API can only process a document that is up to 8,196 tokens long. If the document is longer than this, it will need to be broken up into smaller chunks. You can also use PaLM2 32K, which is in preview and can handle up to 32,000 tokens as input.
Note: If you already use PaLM2 32K text-bison models, you can skip the following step. For a complete list of model versions, check this list.
Step 4: Import models
Now, use the PaLM2 text-bison and gecko-embedding models from the Vertex AI SDK for python to perform the embeddings for the next step. They will also be used in Step 6 to do question answering.
Step 5: Getting the embeddings for each chunk
With the chunking you did in step 3, you can start the implementation by simply calling the embeddings for each chunk using the Embeddings API. If you did not do chunking in Step 3, you can use the Embeddings API to generate embeddings.
The code below adds the embeddings (vector/number representation) of each chunk as a separate column.
The function below returns custom relevant context for questions you ask. You can call it for every new question. This code searches the vector store where embeddings are stored and finds the most relevant answer.
Step 6 Calling PaLM text generation APIs to ask questions
Next, let’s cover how to use the PaLM text-bison APIs with the get_context_from_question (question, vector store, sort_index_value) function you created in the previous step to get answers from the vector store.
Using the function below, pass the top N results from the vector embedding search to the PaLM2 text-bison model as a prompt to get answers to your question. The top N data is picked by the model based on user questions and used as the context that is passed to the prompt for the generative AI model.
Next, use the code below to create a prompt for question answering. This code defines the custom context (embeddings from the vector store) and the questions asked to create a prompt for question answering for the PaLM2 text-bison model.
The response you get from the PaLM APIs will contain the answer to your question.
Conclusion
Congrats! If you’ve reached the end of this post, we hope that you now understand how to use Document AI and PaLM2 for question answering. You should now know how to:
- Extract text from PDF documents using a Document AI OCR processor.
- Use the textembedding-gecko model to generate embeddings for the extracted text.
- Use the PaLM text-bison model to answer questions on the embeddings data store. Please feel free to explore the solution and contribute to the code in the Github repository.
We hope this post showed you how easy it is to build a serverless, RAG-based architecture with Document AI and large language models. You may also consider checking other Google Cloud products which may better suit your needs like:
- Document AI Custom Extractor to extract specific fields from documents like contracts, invoices, W2s & bills of lading.
- Document AI Summarizer to customize summaries based on your preferences for length and format with no training required. It can provide summaries for documents up to 250 pages long, and you won’t need to manage document chunks or model context windows.
- Use Vertex AI Search and Conversation, an enterprise end-to-end RAG solution, to not only search and summarize against digital pdfs, html and txt documents, but also, to build a chat bot on top of those documents.
We can’t wait to see how you use it to transform workflows in your organization!




