생성형 AI 워크로드 보안을 위한 Sensitive Data Protection
Scott Ellis
Senior Product Manager
Assaf Namer
Cloud Security Architect
Get original CISO insights in your inbox
The latest on security from Google Cloud's Office of the CISO, twice a month.
Subscribe*본 아티클의 원문은 2023년 10월 5일 Google Cloud 블로그(영문)에 게재되었습니다.
생성형 AI 모델은 거의 모든 산업에서 큰 관심을 받고 있습니다. 많은 기업에서 이 기술을 활용하여 비즈니스 서비스 및 고객과의 소통을 개선하고 운영을 간소화하며 비즈니스 프로세스의 속도를 높일 방법을 찾는 중입니다. 하지만 대부분의 AI/ML 애플리케이션과 마찬가지로 생성형 AI 모델도 데이터와 데이터 컨텍스트를 기반으로 작동합니다. 이러한 민감한 기업별 데이터를 이해하고 보호하는 일은 성공적인 배포와 적절한 사용을 보장하는 데 매우 중요합니다.
최근 Google이 Google 서니베일 캠퍼스에서 열린 최신 보안 관련 행사 참석자를 대상으로 실시한 설문조사에서 '현재 귀사에서 AI와 관련해 가장 우려되는 3대 리스크/위험/보안 문제는 무엇인가요?'라는 문항에 응답자가 가장 많이 선택한 3가지 답변 중 2개가 '데이터 유출'과 '개인 정보 보호'였습니다. 특히 데이터 유출은 프롬프트 인젝션과 관련된 위험 중 하나로, OWASP에서는 이를 기반 애플리케이션을 위협하는 상위 10대 위험 중 하나로 꼽은 바 있습니다. 학습 데이터와 기반 응답 데이터를 보호하는 일은 견고한 생성형 AI 애플리케이션을 빌드하는 데 있어 중요한 단계입니다.
다음으로는 Google Sensitive Data Protection을 사용해 생성형 AI 애플리케이션을 보호하는 데이터 중심 접근 방식을 알아보고 실제 예시가 담긴 Jupyter 노트북을 살펴보겠습니다.
데이터가 중요한 이유는 무엇일까요?
다른 AI/ML 워크로드와 마찬가지로 생성형 AI를 특정 비즈니스 니즈에 맞게 조정하거나 확장하기 위해서는 데이터가 필요합니다. Vertex AI 기반 생성형 AI에는 데이터와 모델이 파운데이션 모델을 학습시키는 데 사용되거나 다른 고객에게 노출되지 않도록 하는 강력한 데이터 보호 조치가 이미 적용되어 있습니다. 하지만 조직에서는 개인 정보(PI) 또는 개인 식별 정보(PII)와 같은 민감한 요소가 포함될 수 있는 자체 데이터로 모델을 맞춤설정하고 학습시키는 데 따른 위험을 어떻게 줄일지에 대한 고민이 있습니다. 이러한 개인 정보는 모델이 제대로 기능하는 데 필요한 컨텍스트와 관련이 있는 경우가 많습니다.
개인 정보를 찾아서 민감한 요소만 제거하기란 쉬운 일이 아닙니다. 게다가 수정 전략은 데이터 세트의 통계적 속성에 영향을 미치거나 통계적으로 부정확한 일반화를 만들 수 있습니다. Cloud Data Loss Prevention(DLP) API가 포함된 Google Cloud의 Sensitive Data Protection 서비스는 이러한 과제를 해결하는 데 도움이 되는 일련의 감지 및 변환 옵션을 제공합니다.
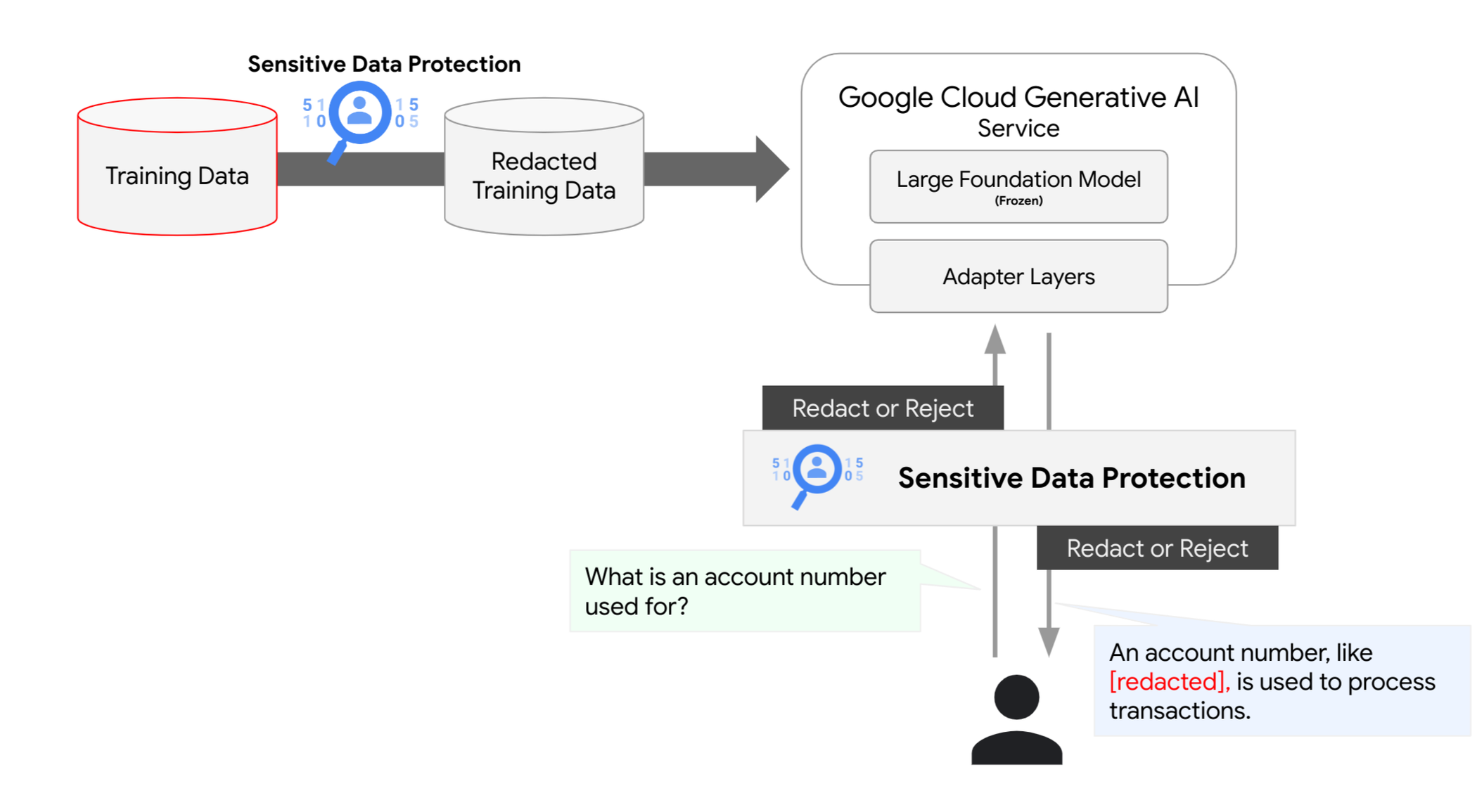
조직은 Google Cloud의 Sensitive Data Protection을 사용하여 학습부터 조정, 추론에 이르는 생성형 AI 모델의 수명 주기 전반에 데이터 보호 레이어를 추가할 수 있습니다. 이러한 보호 기술을 초기에 도입하면 모델 워크로드의 안전성과 규정 준수성을 강화하고 향후 재훈련 또는 재조정에 비용을 낭비할 위험을 줄일 수 있습니다.
데이터 중심 접근방식
Sensitive Data Protection에는 이름, 개인 정보, 재무 데이터, 의료 정보, 인구 통계 데이터와 같은 민감한 정보 요소를 신속하게 파악할 수 있도록 도와주는 기본 제공 infoType이 150개 이상 포함되어 있습니다. 이러한 요소를 파악하여 파이프라인에서 삭제할 기록을 선택하거나, 주변 컨텍스트는 유지하고 민감한 요소만 가리는 인라인 변환을 활용할 수 있습니다. 이를 통해 데이터의 유용성을 유지하면서도 위험을 줄일 수 있습니다. 인라인 변환은 AI 모델의 학습 또는 조정용 데이터를 준비할 때 사용할 수 있으며 AI로 생성된 응답을 실시간으로 보호해 줍니다.
아래의 예시에서 민감한 요소는 삭제하고 이를 데이터 유형으로 대체하는 것을 볼 수 있습니다. 이런 방식으로 원시 콘텐츠를 노출할 필요 없이 데이터 유형과 주변 컨텍스트를 인지한 상태로 모델을 학습시킬 수 있습니다.
원시 데이터 입력:
[상담사] 안녕하세요, 저는 제이슨이라고 합니다. 성함을 여쭤봐도 될까요?
[고객] 제 이름은 발레리아라고 해요.
[상담사] 연락이 필요할 수 있으니 이메일 주소를 알려주시겠어요?
[고객] 제 이메일은 v.racer@example.org입니다.
[상담사] 감사합니다. 어떻게 도와드릴까요?
[고객] 청구서에 문제가 있는 것 같아서요.
익명 처리된 결과:
[상담사] 안녕하세요, 저는 [PERSON_NAME]이라고 합니다. 성함을 여쭤봐도 될까요?
[고객] 제 이름은 [PERSON_NAME]라고 해요.
[상담사] 연락이 필요할 수 있으니 이메일 주소를 알려주시겠어요?
[고객] 제 이메일은 [EMAIL_ADDRESS]입니다.
[상담사] 감사합니다. 어떻게 도와드릴까요?
[고객] 청구서에 문제가 있는 것 같아서요.
위의 예시처럼 단순히 대체하는 방식으로는 충분하지 않은 경우도 가끔 있습니다. Sensitive Data Protection에는 특정 니즈에 적합하게 맞춤설정할 수 있는 몇 가지 익명화 옵션이 있습니다. 우선 고객에게는 어떤 infoType을 중요하게 감지 및 수정하고, 어떤 infoType을 그대로 유지할지 결정할 수 있는 완전한 제어권이 있습니다. 게다가 단순한 수정에서 무작위 대체, 형식 유지 암호화에 이르기까지 니즈에 가장 잘 맞는 데이터 변환 방식을 선택할 수도 있습니다.
무작위 대체 방식을 사용하는 다음 예시를 살펴보세요. 이 방식은 입력 샘플과 매우 유사한 출력을 생성하지만, 민감한 요소를 파악해 그 자리를 무작위 값으로 대체합니다.
입력:
[상담사] 안녕하세요, 저는 제이슨이라고 합니다. 성함을 여쭤봐도 될까요?
[고객] 제 이름은 발레리아라고 해요.
[상담사] 연락이 필요할 수 있으니 이메일 주소를 알려주시겠어요?
[고객] 제 이메일은 v.racer@example.org입니다.
[상담사] 감사합니다. 어떻게 도와드릴까요?
[고객] 청구서에 문제가 있는 것 같아서요.
익명 처리된 결과:
[상담사] 안녕하세요, 저는 가바니아라고 합니다. 성함을 여쭤봐도 될까요?
[고객] 제 이름은 비잘이라고 해요.
[상담사] 연락이 필요할 수 있으니 이메일 주소를 알려주시겠어요?
[고객] 제 이메일은 happy.elephant44@example.org입니다.
[상담사] 감사합니다. 어떻게 도와드릴까요?
[고객] 청구서에 문제가 있는 것 같아서요.
데이터 준비 단계에서의 보호
예측 엔드포인트에 AI 모델을 배포하는 경우처럼 고객은 커스텀 AI 모델 학습을 위한 데이터 세트를 생성하는 데 자체 데이터를 사용할 때가 많습니다. 또한 LLM 응답의 관련성을 높이고 비즈니스 목표를 강화하기 위해 고객만의 고유한 데이터를 사용하여 언어와 코드 같은 모델을 미세 조정하기도 합니다.
생성형 AI 기능을 사용하여 파운데이션 모델을 조정하고 특정 작업과 비즈니스 니즈에 맞게 파운데이션 모델을 배포하는 고객도 있습니다. 이 조정 프로세스는 고객별 데이터 세트를 사용하고 파라미터를 생성한 다음 추론 시 사용합니다. 파라미터는 사용자 프로젝트 내 '고정'된 파운데이션 모델 앞에 상주합니다. 이러한 데이터 세트에 민감한 정보가 포함되지 않도록 Sensitive Data Protection 서비스를 사용하여 데이터 세트 생성에 사용된 데이터를 검사할 수 있습니다. 마찬가지로 Vertex AI Search에 이 방법을 사용하여 업로드된 데이터에 민감한 정보가 포함되지 않도록 할 수 있습니다.
인라인 프롬프트 및 응답 보호
학습 파이프라인을 보호하는 일은 중요하지만 Sensitive Data Protection에서 제공되는 보안 장치의 일부에 불과합니다. 생성형 AI 모델은 사용자의 비정형 프롬프트를 받아 전에 없던 새로운 응답을 생성할 수 있기 때문에 인라인에서도 민감한 정보를 보호해야 할 경우가 있습니다. 알려진 많은 프롬프트 인젝션 공격이 실제 상황에서 목격되고 있습니다. 이러한 공격의 주요 목적은 의도치 않은 정보를 공유하도록 모델을 조작하는 것입니다.
프롬프트 인젝션을 방어하는 방법에는 여러 가지가 있지만 Sensitive Data Protection은 입력 프롬프트와 생성되는 응답을 검사하여 민감한 요소를 파악하거나 삭제하는 방식으로 생성형 AI 기반 모델과 주고받는 데이터에 데이터 중심 보안 제어 기능을 적용할 수 있습니다.
다음 단계
AI/ML 및 생성형 AI의 데이터와 워크로드를 보호하기 위해 적극적으로 조치를 취하는 방법을 확인하려면 Sensitive Data Protection을 자세히 알아보고 Colab 노트북을 살펴보세요. Vertex AI를 사용하면 머신러닝 지식이 없어도 파운데이션 모델과 상호작용하고, 이를 맞춤설정하며, 애플리케이션에 임베딩할 수 있습니다. Model Garden에서 파운데이션 모델에 액세스하거나, Generative AI Studio에서 간단한 인터페이스를 통해 모델을 조정하거나 또는 데이터 과학 노트북에서 모델을 바로 사용할 수 있습니다.


