Gemini 및 OSS 텍스트 임베딩이 이제 Big Query ML에 포함됩니다
Jasper Xu
Software Engineer
Haiyang Qi
Software Engineer, BigQuery ML
* 본 아티클의 원문은 2025년 09월 17일 Google Cloud 블로그(영문)에 게재되었습니다.
고품질 텍스트 임베딩은 시맨틱 검색, 분류, 검색 증강 생성(RAG)과 같은 최신 AI 애플리케이션의 엔진입니다. 하지만 이러한 임베딩을 생성할 모델을 선택할 때, 한 가지 솔루션으로 모든 기준을 만족시킬 수는 없습니다. 일부 사용 사례에서는 최첨단 품질을 요구하는 반면, 다른 사용 사례에서는 비용, 속도 또는 오픈소스 생태계와의 호환성가 중요할 수 있습니다.
선택의 폭을 넓히기 위해 BigQuery ML의 텍스트 임베딩 기능을 대폭 확장했습니다. 기존의 text-embedding-004/005 및 text-multilingual-embedding-OO2 모델 외에도 이제 BigQuery 내에서 직접 Google의 강력한 Gemini 임베딩 모델과 13,000개 이상의 오픈소스(OSS) 모델을 사용할 수 있습니다. 데이터가 있는 곳에서 작업에 적합한 모델을 사용하여 간단한 SQL 명령어로 임베딩을 생성할 수 있습니다.
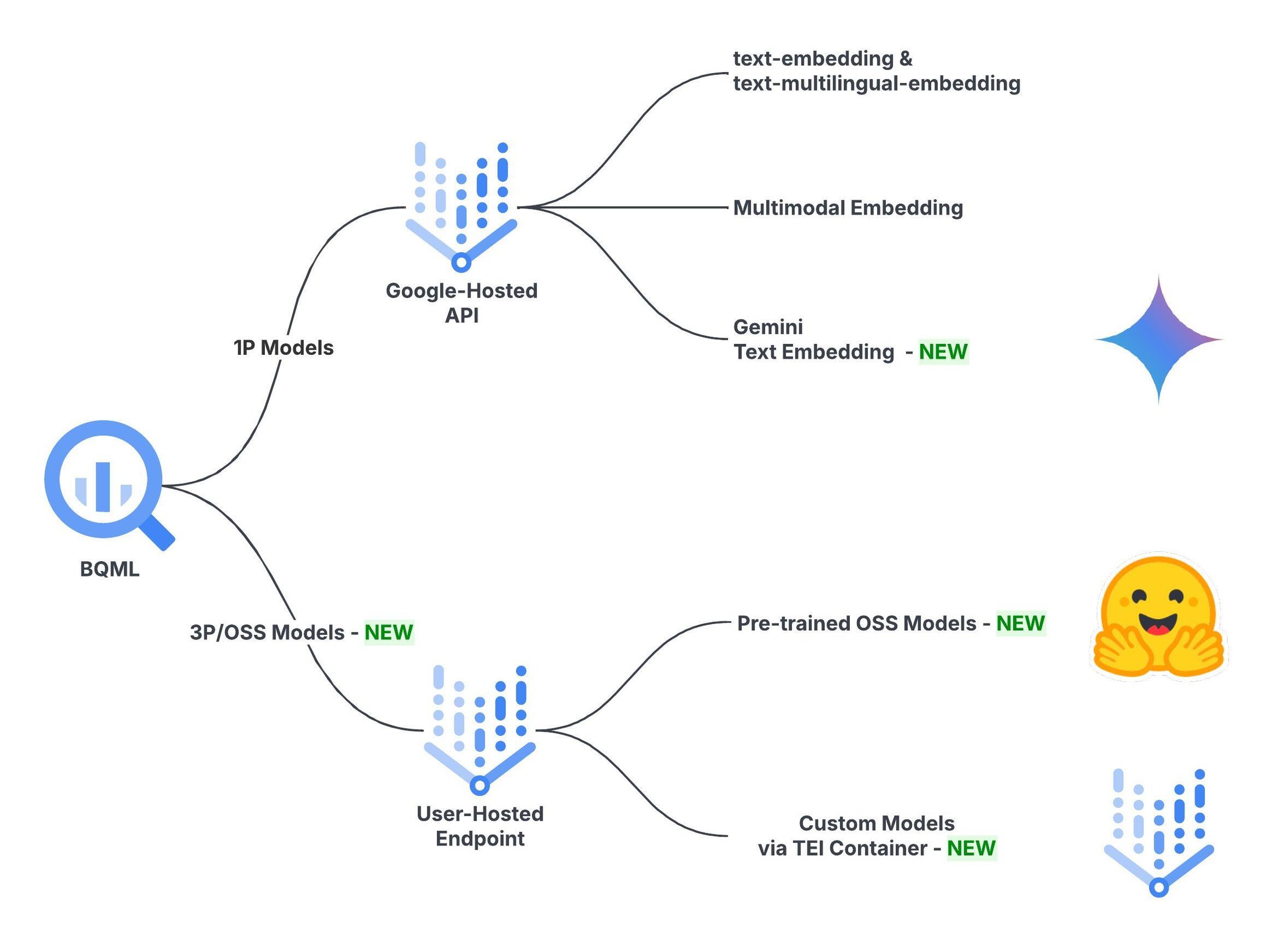
요구사항에 따라 임베딩 모델 선택
Gemini와 다양한 OSS 모델이 추가됨에 따라 BigQuery는 이제 포괄적인 텍스트 임베딩 옵션 목록을 제공합니다. 모델 품질, 비용, 확장성 등 필요에 따라 적절한 모델을 선택할 수 있습니다. 결정하는 데 도움이 되도록 각 유형을 자세히 살펴보겠습니다.
BigQuery ML의 Gemini 임베딩 모델
Gemini 임베딩 모델은 업계 최고의 텍스트 임베딩 벤치마크인 Massive Text Embedding Benchmark(MTEB) 리더보드에서 지속적으로 1위를 차지한 최첨단 텍스트 임베딩 모델입니다. MTEB 리더보드에서 1위를 차지한 이 모델은 고품질 임베딩을 직접적으로 보여줍니다.
BigQuery에서 새로운 Gemini 임베딩 모델을 사용하는 방법은 다음과 같습니다.
1. BigQuery에서 Gemini 임베딩 모델 만들기
다음 SQL 문을 사용하여 BigQuery에서 Gemini 임베딩 모델을 만듭니다. 엔드포인트를 `gemini-embedding-001`로 지정합니다.
2. 일괄 임베딩 생성
이제 BigQuery에서 직접 gemini-embedding 모델을 사용하여 임베딩을 생성할 수 있습니다. 다음 예시는 bigquery-public-data.hacker_news.full 데이터 세트에 텍스트를 임베딩합니다.
Gemini 임베딩 모델은 분당 토큰 수(TPM)라는 새로운 할당량 제어 방법을 활용합니다. 평판 점수가 높은 프로젝트의 경우 기본 TPM 값은 500만 개입니다. 고객이 수동 승인 없이 설정할 수 있는 최대 TPM은 2,000만 개입니다.
작업이 처리할 수 있는 총 행 수는 행당 토큰 수에 따라 달라집니다. 예를 들어 행당 300개의 토큰이 있는 테이블을 처리하는 작업은 단일 작업으로 최대 1,200만 개의 행을 처리할 수 있습니다.
BigQuery ML의 OSS 임베딩 모델
OSS 커뮤니티는 텍스트 임베딩 모델 환경을 빠르게 발전시키고 있으며, 모든 요구사항에 맞는 다양한 선택지를 제공하고 있습니다. 최근 출시된 Qwen3-Embedding 및 EmbeddingGemma와 같은 최고 순위 모델부터 multilingual-e5-small과 같은 작고 효율적이며 비용 효율적인 소규모 모델까지 다양한 제품을 제공합니다.
이제 BigQuery ML에서 Vertex AI Model Garden에 배포된 모든 Hugging Face 텍스트 임베딩 모델(13,000개 이상의 옵션)을 사용할 수 있습니다. 이 기능을 보여주기 위해 이 예시에서는 multilingual-e5-small을 사용합니다. 이 모델은 대규모로 확장 가능하고 비용 효율적이면서도 상당한 성능을 제공하여 대규모 분석 작업에 적합합니다.
오픈소스 텍스트 임베딩 모델을 사용하려면 다음 단계를 따르세요.
1. Vertex 엔드포인트에서 모델 호스팅
먼저 Hugging Face에서 텍스트 임베딩 모델을 선택합니다. 이 경우 위에서 언급한 multilingual-e5-small을 선택합니다. 그런 다음 Vertex AI Model Garden > Hugging Face에서 배포로 이동합니다. 모델 URL을 입력하고 엔드포인트 액세스를 '공개(공유 엔드포인트)'로 설정합니다. 요구사항에 맞게 엔드포인트 이름, 리전, 머신 사양을 맞춤설정할 수도 있습니다. 기본 설정은 아래에 지정된 머신 유형의 단일 복제본을 프로비저닝합니다.
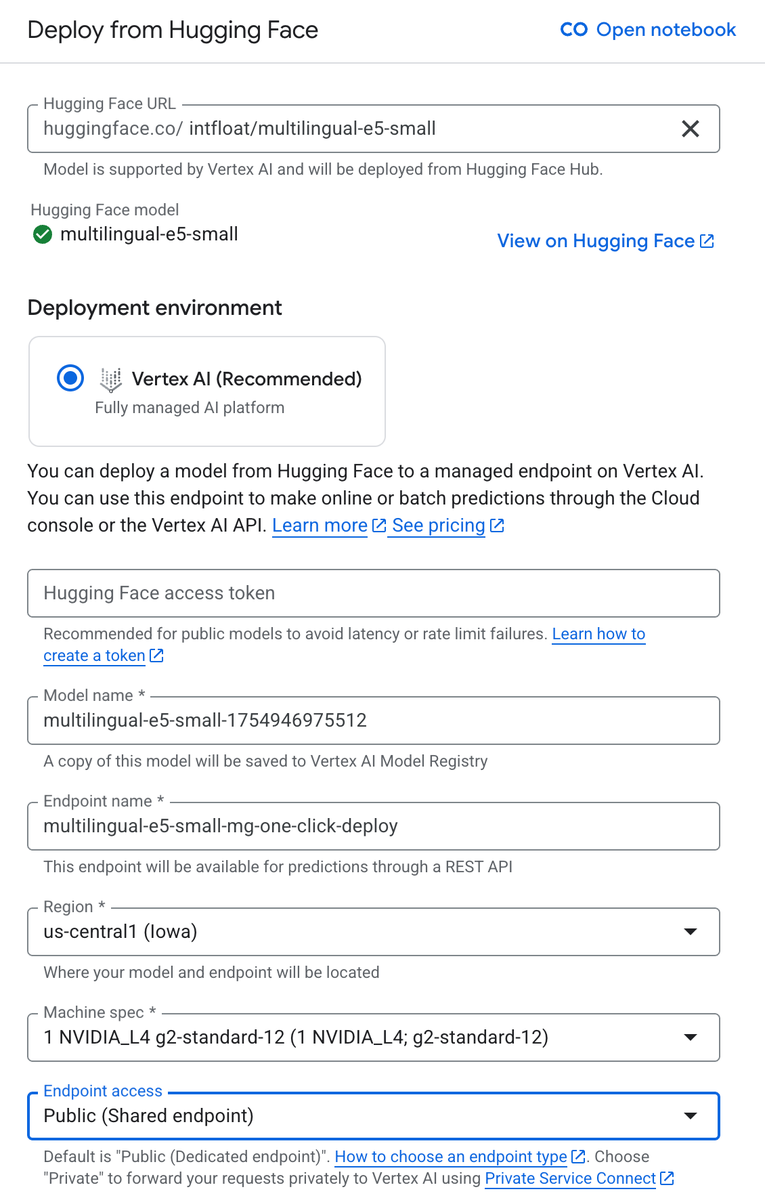
또는 BigQuery 노트북(튜토리얼 노트북 예시 참고)이나 공개 문서에 언급된 다른 방법을 사용하여 이 단계를 프로그래매틱 방식으로 수행할 수 있습니다.
2. BigQuery에서 원격 모델 만들기
모델 배포를 배포하는 데 몇 분 정도 걸릴 수 있습니다. 완료되면 다음 SQL 문을 사용하여 BigQuery에서 해당 원격 모델을 만듭니다.
위 코드 샘플의 자리표시자 엔드포인트를 엔드포인트 URL로 바꿉니다. endpoint_id에 대한 정보는 Vertex AI > 온라인 예측> 엔드포인트> 샘플 요청을 통해 콘솔에서 가져올 수 있습니다.
3. 일괄 임베딩 생성
이제 BigQuery에서 직접 OSS multilingual-e5-small 모델을 사용하여 임베딩을 생성할 수 있습니다. bigquery-public-data.hacker_news.full 데이터 세트에 텍스트를 임베딩하는 다음 예시를 참고하세요.
모델 배포를 위한 기본 리소스를 선택하면 쿼리가 hacker_news 데이터 세트의 3,800만 개 행을 약 2시간 10분 만에 처리할 수 있습니다. 이는 단일 모델 복제본으로 달성한 기준 처리량입니다.
더 많은 컴퓨팅 리소스를 프로비저닝하거나 엔드포인트 자동 확장을 사용 설정하여 워크로드를 확장할 수 있습니다. 예를 들어 복제본 10개를 선택하면 쿼리가 10배 빨라지고 6시간 쿼리 작업당 수십억 개의 행을 처리할 수 있습니다.
4. 모델 배포 취소
Vertex AI 엔드포인트는 머신이 유휴 상태일 때도 활성 상태인 동안에는 비용이 발생합니다. 일괄 작업이 완료되고 예상치 못한 비용이 발생하지 않도록 하려면 일괄 추론 후 모델을 '배포 취소'해야 합니다. Google Cloud 콘솔(Vertex AI > 엔드포인트 > 나의 엔드포인트 > 엔드포인트에서 모델 배포 취소)을 사용하거나 예시 Colab 스크립트를 사용하여 이 작업을 수행할 수 있습니다.
일괄 워크로드의 경우 배포, 추론, 배포 취소를 연속적인 워크플로로 취급하여 유휴 상태의 비용을 최소화하는 것이 가장 비용 효율적인 패턴입니다. 이를 위한 한 가지 방법은 샘플 Colab을 순차적으로 실행하는 것입니다. 결과는 놀라웠습니다. 3,800만 개의 행을 모두 처리하는 데 드는 비용은 약 2~3달러에 불과했습니다.
지금 시작하기
다음 AI 애플리케이션을 빌드할 준비가 되셨나요? 지금 바로 BigQuery에서 Gemini 또는 즐겨 사용하는 오픈소스 모델로 임베딩을 생성해 보세요. 문서를 자세히 살펴보거나 단계별 Colab 튜토리얼을 따라해 보면서 실제로 작동하는 모습을 확인하세요.


