정식 버전으로 제공되는 Cloud Spanner의 변경 내역
Yang Song
Software Engineer
Le Chang
Software Engineer
* 본 아티클의 원문은 2022년 5월 28일 Google Cloud 블로그(영문)에 게재되었습니다.
올해 Google Data Cloud Summit에서 Google은 Cloud Spanner 변경 내역을 발표했습니다. 오늘 변경 내역의 정식 버전이 출시된다는 반가운 소식을 전해드립니다. Spanner 사용자는 변경 내역을 사용하여 Cloud Spanner 데이터베이스의 변경사항(삽입, 업데이트, 삭제)을 거의 실시간으로 캡처하고 스트리밍할 수 있습니다.
변경 내역은 변경 데이터를 다른 Google Cloud 서비스와 통합할 수 있는 다양한 옵션을 제공합니다. 일반적인 사용 사례는 다음과 같습니다.
- 분석: 분석에 사용할 수 있는 최신 데이터가 BigQuery에 있도록 BigQuery에 변경 이벤트를 보냅니다.
- 이벤트 트리거링: 다운스트림 시스템에서 추가 처리를 위해 Pub/Sub에 데이터 변경 이벤트를 보냅니다.
- 규정 준수: 보관 목적으로 Google Cloud Storage에 변경 이벤트를 저장합니다.
변경 내역 시작하기
이 섹션에서는 변경 내역을 만들고, 변경 내역 데이터를 읽고, 분석을 위해 BigQuery로 데이터를 보내는 간단한 예시를 살펴봅니다.
아직 숙지하지 않은 경우 Spanner Qwiklab을 통해 Cloud Spanner에 대한 기본사항을 숙지하세요.
변경 내역 만들기
Spanner 변경 내역은 테이블 및 색인 생성 작업과 유사하게 DDL을 사용하여 생성됩니다. 변경 내역 DDL에는 다른 스키마 변경(spanner.databases.updateDdl)과 동일한 IAM 권한이 필요합니다.
변경 내역을 사용하면 열 집합, 테이블 집합 또는 전체 데이터베이스의 변경사항을 추적할 수 있습니다 각 변경 내역의 보관 기간은 1~7일이며, 여러 변경 내역을 설정하여 특정 목표에 필요한 변경사항을 정확하게 추적할 수 있습니다. 변경 내역 만들기 및 관리를 자세히 알아보세요.
다음과 같은 Orders라는 테이블이 있다고 가정해 보겠습니다.
기본(암시적) 보관 기간이 1일인 전체 Orders 테이블을 추적하는 변경 내역을 만들기 위한 DDL은 다음과 같이 정의됩니다.
변경 내역 만들기는 장기 실행 작업입니다. Cloud 콘솔의 변경 내역 페이지에서 진행 상황을 확인할 수 있습니다.
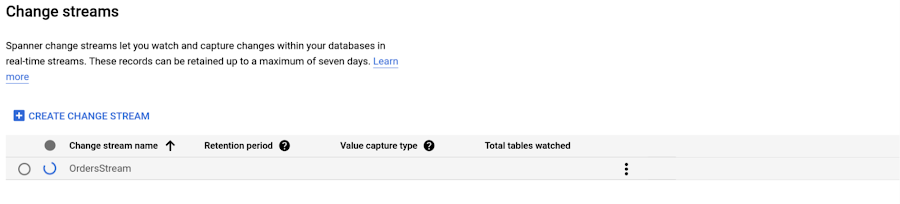
생성된 변경 내역의 이름을 클릭하면 추가 세부정보가 표시됩니다.
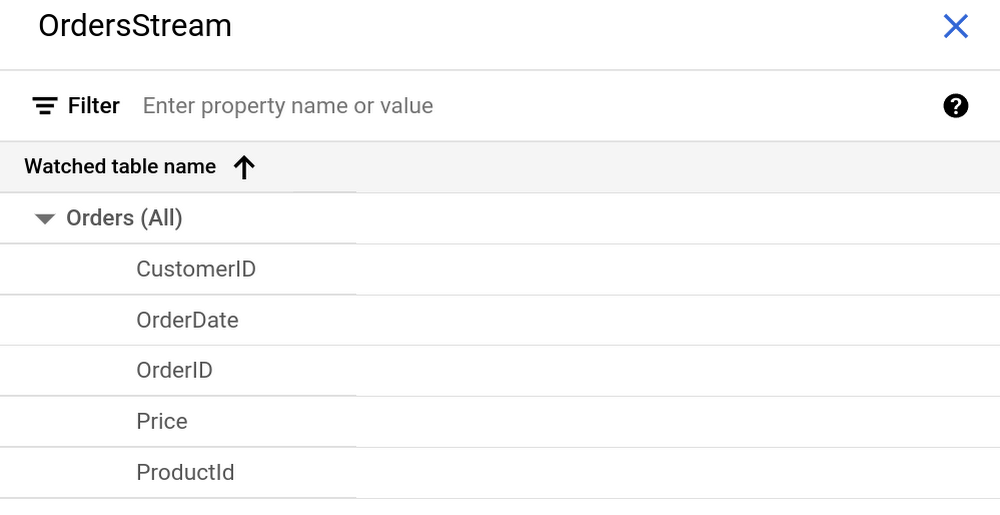
데이터베이스 DDL은 다음과 같이 나타납니다.

이제 변경 내역이 생성되었으므로 변경 내역 데이터를 처리할 수 있습니다.
데이터를 BigQuery로 스트리밍하기
여러 가지 방법으로 변경 내역 데이터를 처리할 수 있습니다. 가장 쉬운 방법은 Apache Beam용 Spanner 커넥터를 사용하는 것으로 이 방법을 통해 Google Cloud Dataflow를 위한 확장 가능한 데이터 처리 파이프라인을 빌드할 수 있습니다. 변경 데이터를 처리하고 BigQuery 또는 Google Cloud Storage에 각각 변경 데이터를 쓸 수 있는 Dataflow 템플릿이 제공됩니다. Cloud Spanner 변경 내역과 Dataflow의 작동 방식을 자세히 알아보세요.
이 예시에서는 BigQuery에 Spanner 변경 내역 작성 템플릿을 사용하여 변경 내역 데이터를 BigQuery에 씁니다.
먼저 Google Cloud 콘솔에서 Dataflow 작업 페이지로 이동합니다. '템플릿에서 작업 만들기'를 클릭하고 'BigQuery에 변경 내역 작성' 템플릿을 선택한 다음 필수 입력란을 작성합니다.
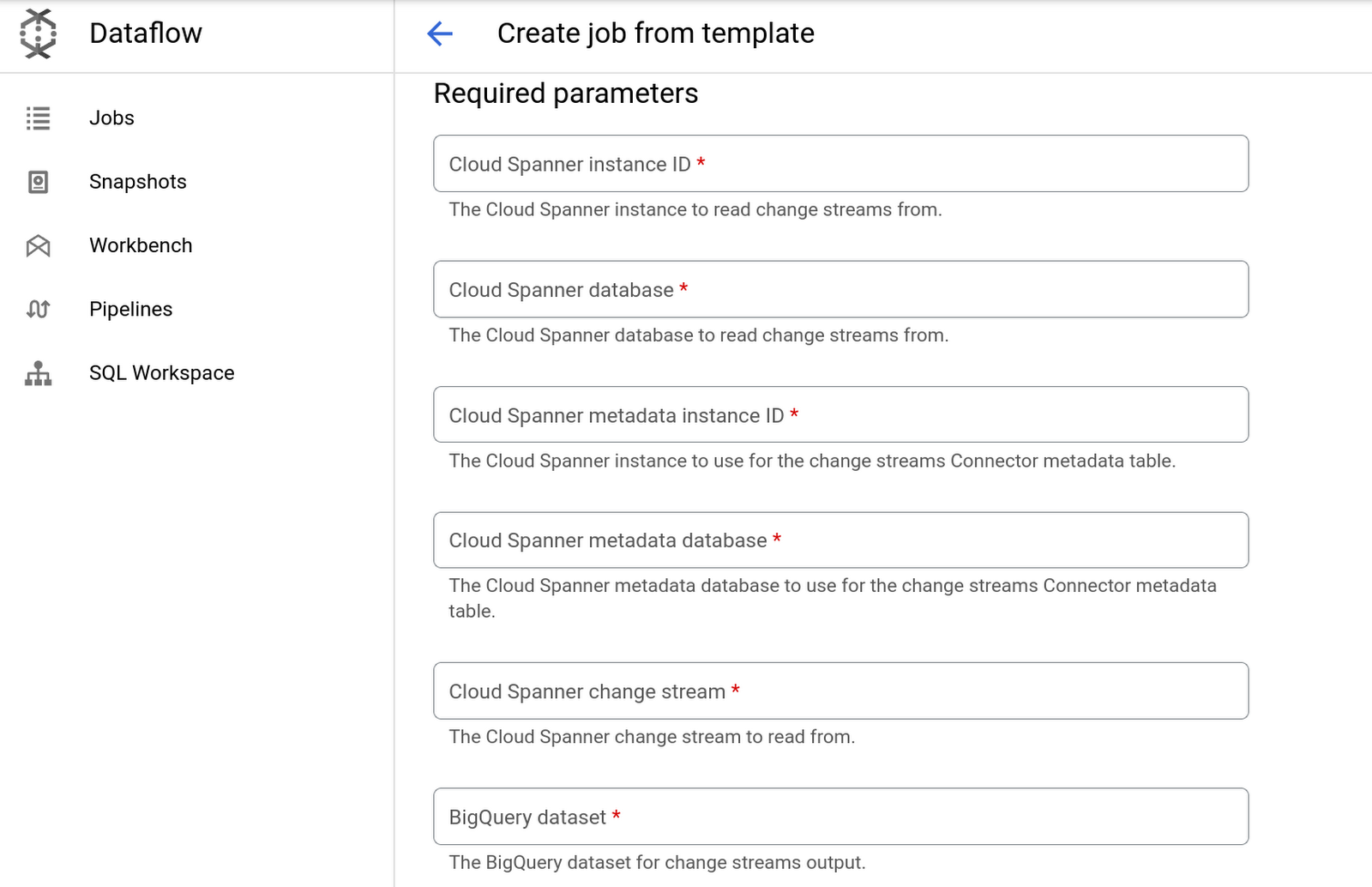
'작업 실행'을 클릭한 다음 Dataflow에서 파이프라인을 빌드하고 작업이 시작될 때까지 기다립니다. Dataflow 파이프라인이 실행되면 Dataflow 작업 페이지에서 작업 그래프, 실행 세부정보, 측정항목을 볼 수 있습니다.
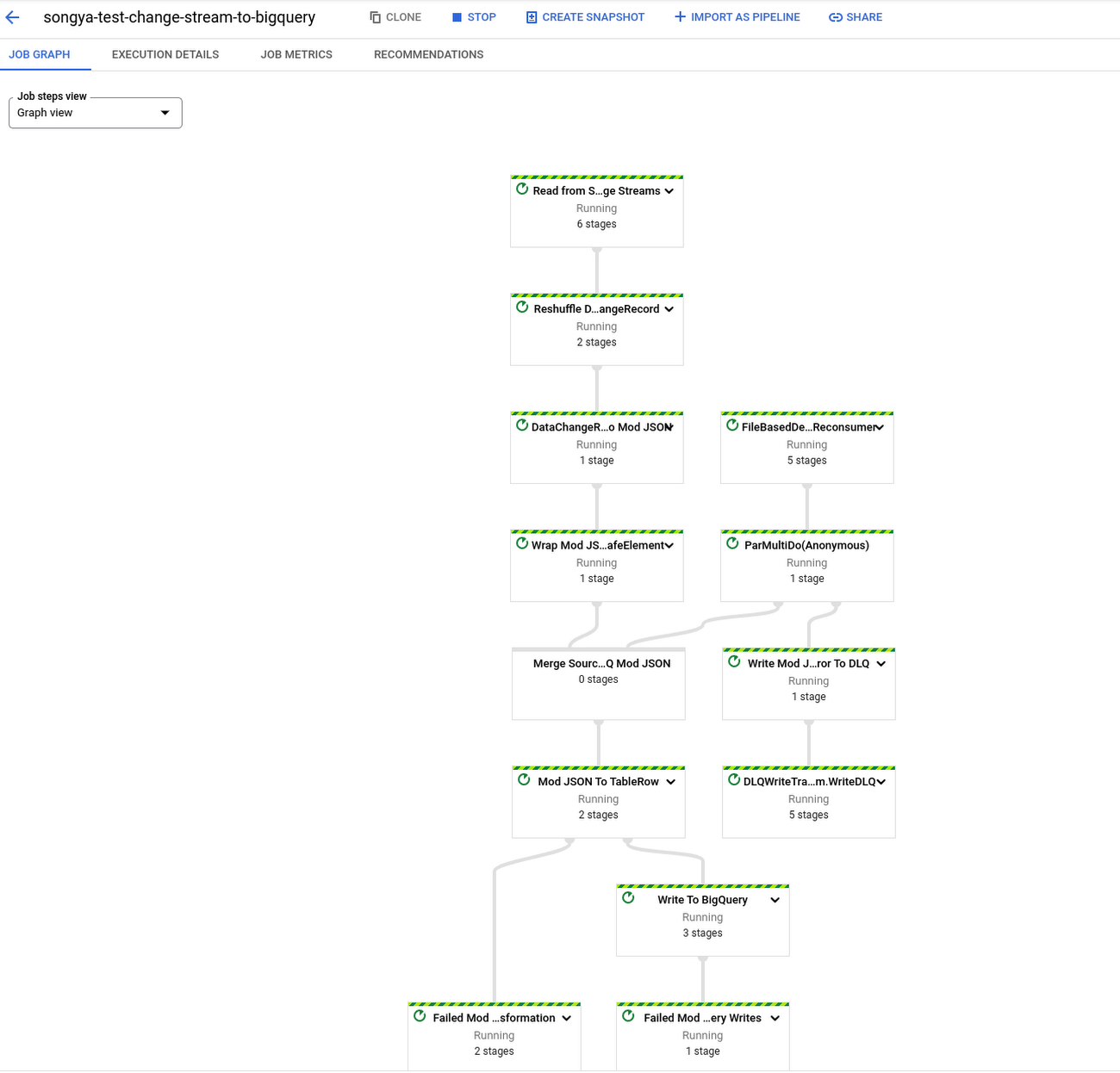
이제 추적 대상인 Orders 테이블에 데이터를 작성해 보겠습니다.

Spanner가 변경 내역에서 추적하는 데이터 세트의 데이터 변경을 감지하면 동일한 트랜잭션 내에서 해당 데이터 변경과 동기화하는 방식으로 데이터 변경 레코드를 씁니다. Spanner는 이러한 쓰기를 모두 같은 위치에 배치하기 때문에 동일한 서버에서 처리되어 쓰기 처리가 최소화됩니다. Spanner가 변경 내역을 쓰고 저장하는 방법을 자세히 알아보세요.
마지막으로 BigQuery 데이터 세트를 보면 변경 내역 레코드에 대한 몇 가지 추가 정보와 함께 방금 삽입한 행이 표시됩니다.

준비가 완료되었습니다. Dataflow 파이프라인이 실행되는 한 추적 대상 테이블의 데이터 변경사항이 BigQuery 데이터 세트로 원활하게 스트리밍됩니다. 파이프라인 모니터링을 자세히 알아보세요.
변경 내역 데이터를 처리하는 다양한 방법
BigQuery 및 Google Cloud Storage용으로 Google에서 제공하는 Dataflow 템플릿을 사용하는 대신 커스텀 Dataflow 파이프라인을 빌드하여 Apache Beam으로 변경 데이터를 처리할 수 있습니다. 이 경우 DataChangeRecord 객체의 Apache Beam PCollection으로 변경 데이터를 출력하는 SpannerIO Dataflow 커넥터가 제공됩니다. 자체 데이터 변환을 정의하거나 BigQuery 또는 Google Cloud Storage와 다른 싱크가 필요한 경우에 적합합니다. 변경 내역 데이터를 소비 및 전달하는 커스텀 Dataflow 파이프라인을 만드는 방법을 자세히 알아보세요.
또는 Spanner API를 사용하여 변경 내역을 처리할 수 있습니다. 이 접근 방식은 특히 지연 시간에 민감한 애플리케이션에 적합하며 Dataflow에 의존하지 않습니다. Spanner API는 변경 내역에서 직접 읽고 자체 커넥터를 구현하며 선택한 파이프라인으로 변경사항을 스트리밍할 수 있는 강력한 인터페이스입니다. Spanner API를 사용하면 변경 내역이 여러 파티션으로 나뉘며, 각 파티션을 사용하여 변경 내역의 쿼리를 병렬로 실행해 처리량을 높일 수 있습니다. Spanner는 부하 및 크기를 기반으로 이러한 파티션을 동적으로 생성합니다. 각 파티션은 Spanner 데이터베이스 분할과 연결되어 변경 내역이 Spanner의 다른 부분처럼 간편하게 확장될 수 있습니다. 변경 내역 쿼리 API 사용 방법을 자세히 알아보세요.
다음 단계
이제 모든 고객이 추가 비용 없이 Spanner 변경 내역을 사용할 수 있습니다. 일반 Spanner 요율에 따라 변경 스트림 데이터의 추가 컴퓨팅 및 저장에 대해서만 비용을 지불하면 됩니다. 변경 내역이 Spanner에 내장되어 있기 때문에 소프트웨어를 설치할 필요가 없으며, 외부 일관성 및 업계 최고의 가용성을 누릴 수 있을 뿐만 아니라 데이터베이스의 다른 부분과도 쉽게 확장할 수 있습니다.
지금 변경 내역 개요에서 변경 내역에 대해 살펴보세요.


