Document AI Layout Parser를 사용하여 BigQuery에서 RAG 파이프라인을 간단하게 빌드하는 방법
Jeff Nelson
Developer Relations Engineer, Google Cloud
Eric Hao
Software Engineer
* 본 아티클의 원문은 2024년 11월 8일 Google Cloud 블로그(영문)에 게재되었습니다.
문서 전처리는 검색 증강 생성(RAG) 파이프라인을 빌드할 때 흔히 마주하게 되는 장벽입니다. PDF 같은 문서를, 임베딩 생성에 사용할 수 있도록 관리에 용이한 청크로 파싱하려면 Python 기술과 외부 라이브러리가 필요한 경우가 많습니다. 이 블로그에서는 이러한 프로세스를 간소화하는 BigQuery와 Document AI의 새로운 기능을 살펴보고, 단계별로 예를 들어 설명하겠습니다.
BigQuery의 문서 처리 간소화
BigQuery는 이제 Document AI와의 긴밀한 통합을 통해 RAG 파이프라인 및 기타 문서 중심 애플리케이션을 위한 문서 전처리 기능을 제공합니다. 현재 정식 버전으로 제공되는 ML.PROCESS_DOCUMENT 함수를 통해 Document AI의 Layout Parser 프로세서를 비롯한 새로운 프로세서에 액세스하여 SQL 문법으로 PDF 문서를 파싱하고 청킹할 수 있습니다.
ML.PROCESS_DOCUMENT의 정식 버전은 개발자에게 다음과 같은 새로운 이점을 제공합니다.
-
개선된 확장성: 최대 100페이지의 대용량 문서를 처리할 수 있을 뿐 아니라 더 빠른 속도로 처리할 수 있음
-
간소화된 문법: RAG 워크플로에 더 쉽게 통합할 수 있도록 간소화된 SQL 문법 기반으로 Document AI 프로세서와 상호 작용
-
문서 청킹: RAG 파이프라인에 필요한 문서 청크를 생성하기 위해 Layout Parser와 같은 추가적인 Document AI 프로세서 기능에 액세스
특히, 문서 청킹은 RAG 파이프라인을 빌드하는 데 핵심적이면서도 까다로운 구성요소입니다. Document AI의 Layout Parser는 이 프로세스를 간소화해 줍니다. 이 기능이 BigQuery에서 어떤 방식으로 작동하는지 살펴보고 곧바로 실제 시나리오를 사용하여 그 효과를 확인해 보겠습니다.
RAG용 문서 전처리
대규모 문서를 의미상 연관된 더 작은 단위로 나누면 검색된 정보의 관련성이 향상되어 대규모 언어 모델(LLM)에서 더 정확한 답을 얻을 수 있습니다.
문서 소스, 청크 위치, 구조 정보와 같은 메타데이터를 청크와 함께 생성하면 RAG 파이프라인을 더욱 향상시켜 검색 결과를 필터링하고, 정제하며, 코드를 디버깅하는 것이 가능해집니다.
다음 다이어그램은 기본 RAG 파이프라인의 전처리 단계를 간략하게 보여줍니다.
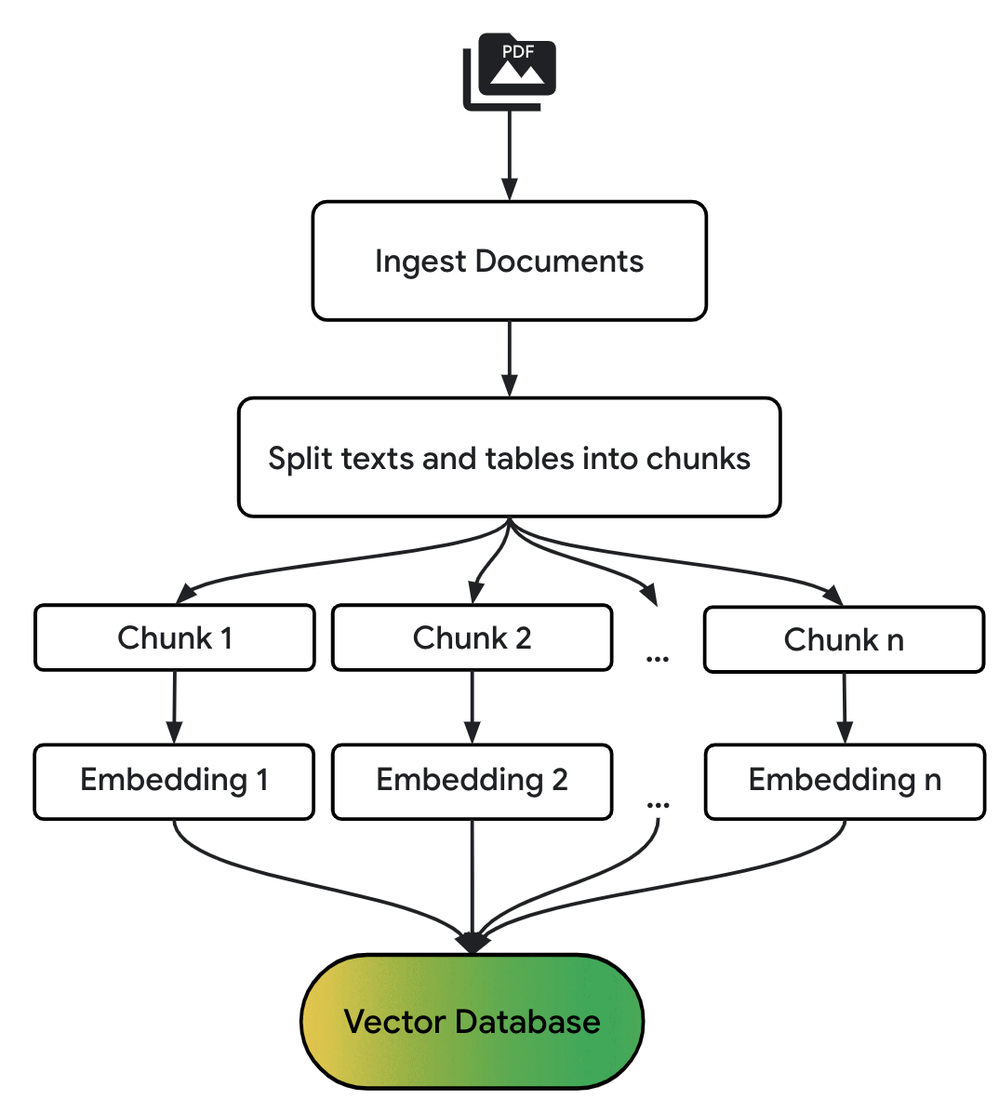
BigQuery에서 RAG 파이프라인 빌드
손익계산서와 같은 재무 문서는 구조가 복잡하고 텍스트, 숫자, 표가 섞여 있어 비교하기가 쉽지 않을 수 있습니다. Document AI의 Layout Parser로 BigQuery에서 RAG 파이프라인을 빌드하여 연방준비제도의 2023년 Survey of Consumer Finances(SCF, 소비자 재정조사) 보고서를 분석하는 방법을 알아보겠습니다. 이 노트북을 참고하면서 진행해 보세요.
연방준비제도(Federal Reserve)의 SCF 보고서와 같은 복잡한 재무 문서의 경우 기존 파싱 기법을 사용하는 데 큰 어려움이 있습니다. 이 문서는 60페이지에 가까운 분량에 텍스트, 상세한 표, 삽입된 차트가 섞여 있어 신뢰할 수 있는 정보를 추출하기가 어렵습니다. Document AI의 Layout Parser는 이처럼 복잡한 문서 레이아웃에서 주요 정보를 효과적으로 식별하고 추출하는 데 탁월합니다.
Document AI의 Layout Parser를 사용하여 BigQuery RAG 파이프라인을 빌드하는 작업은 일반적으로 다음과 같은 단계로 이루어집니다.
1. Layout Parser 프로세서 만들기
Document AI에서 LAYOUT_PARSER_PROCESSOR 유형의 새 프로세서를 만듭니다. 그런 다음, BigQuery에서 이 프로세서를 가리키는 원격 모델(Remote model)을 만들어 BigQuery가 문서에 액세스하여 처리할 수 있도록 합니다.
2. 프로세서를 호출하여 청크 만들기
Google Cloud Storage 상의 PDF에 액세스하려면 먼저 손익계산서가 있는 버킷에 대한 객체 테이블(Object table)을 만듭니다. 그런 다음, ML.PROCESS_DOCUMENT 함수를 사용하여 객체를 Document AI로 전달하고 BigQuery에서 결과를 반환합니다. Document AI는 문서를 분석하고 PDF를 청킹합니다. 결과는 JSON 객체로 반환되며 소스 URI나 페이지 번호와 같은 메타데이터를 추출하기 위해 쉽게 파싱할 수 있습니다.
Survey of Consumer Finances 보고서(p.12)의 표 요소 샘플 이미지
ML.PROCESS_DOCUMENT 함수를 사용하여 문서 파싱
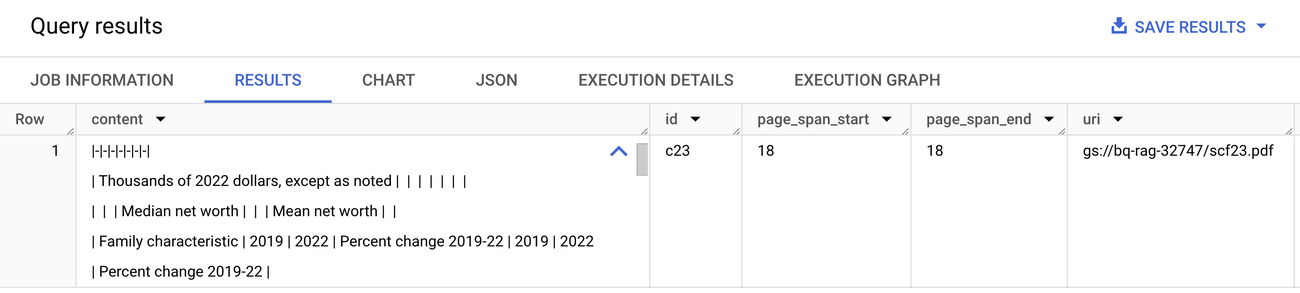
ML.PROCESS_DOCUMENT에서 JSON을 파싱한 후의 샘플 문서 청크
3. 청크에 대한 벡터 임베딩 만들기
시맨틱 검색을 수행할 수 있도록 ML.GENERATE_EMBEDDING 함수를 사용하여 각 문서 청크에 대한 임베딩을 생성하고 BigQuery 테이블에 작성합니다. 이 함수에는 두 개의 인수가 사용됩니다.
-
Vertex AI 임베딩 엔드포인트를 호출하는 원격 모델
-
임베딩할 데이터가 포함된 BigQuery 테이블의 열
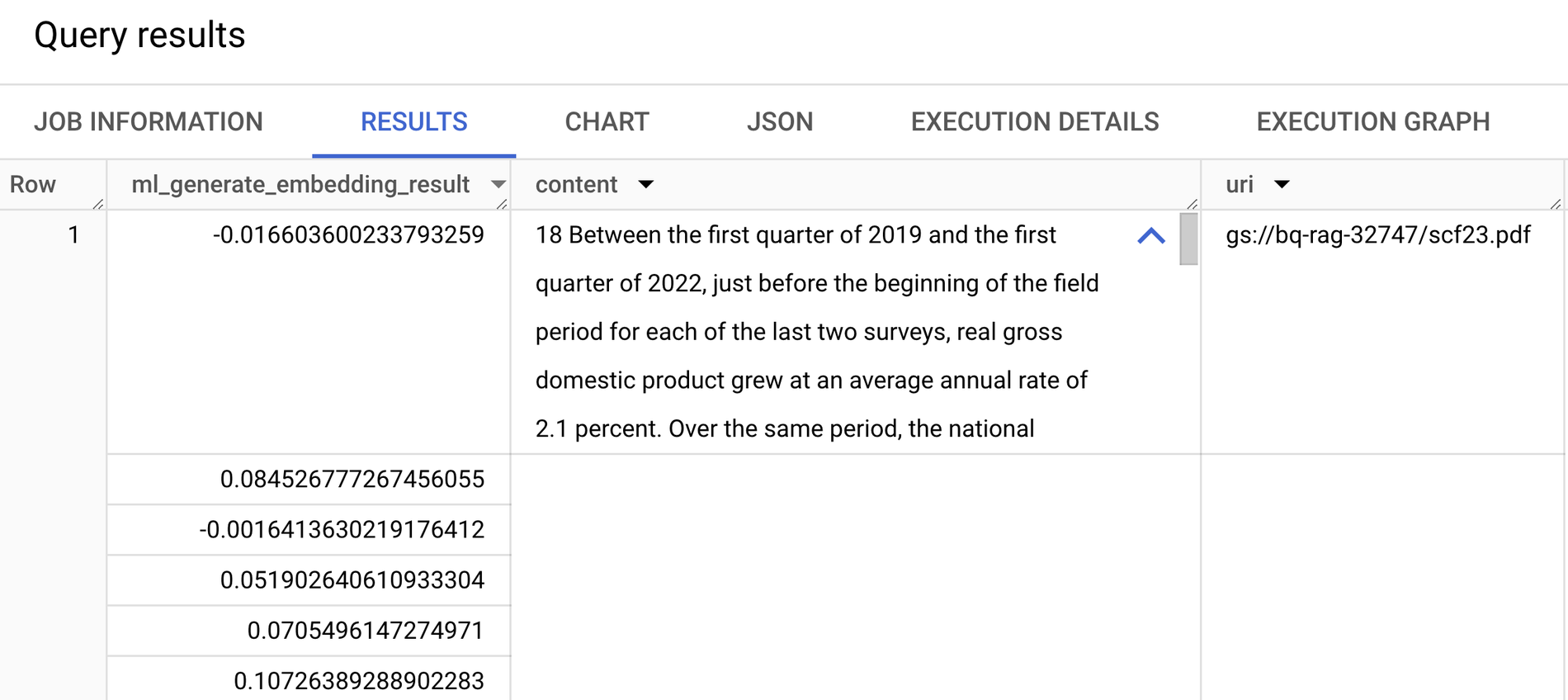
ML.GENERATE_EMBEDDINGS에서 반환된 BigQuery의 벡터 임베딩
4. 임베딩에 대한 벡터 색인(Vector Index) 만들기
시맨틱 유사성을 바탕으로 대규모 청크를 효율적으로 검색하기 위해 임베딩에 대한 벡터 색인을 만듭니다. 벡터 색인이 없으면 검색을 수행하기 위해 각 쿼리 임베딩을 데이터 세트의 모든 임베딩과 비교해야 하는데, 이러한 작업은 다수의 청크를 처리할 때 컴퓨팅 비용이 많이 들고 속도도 느립니다. 벡터 색인은 근사 최근접 이웃(Approximate Nearest Neighbor) 검색과 같은 기법을 사용하여 이 프로세스의 속도를 높입니다.
5. 관련 청크를 검색하여 LLM으로 보내고 답변 생성하기
이제 벡터 검색을 수행하여 입력 쿼리와 의미상 유사한 청크를 찾을 수 있습니다. 여기에서는 이 보고서에서 다루는 내용으로서 3년 동안 일반적인 가구의 순자산이 어떻게 변화했는지 살펴보겠습니다.
검색된 청크는 ML.GENERATE_TEXT 함수를 통해 전송되며 이 함수는 Gemini 1.5 Flash 엔드포인트를 호출하고 질문에 대한 간결한 답변을 생성합니다.
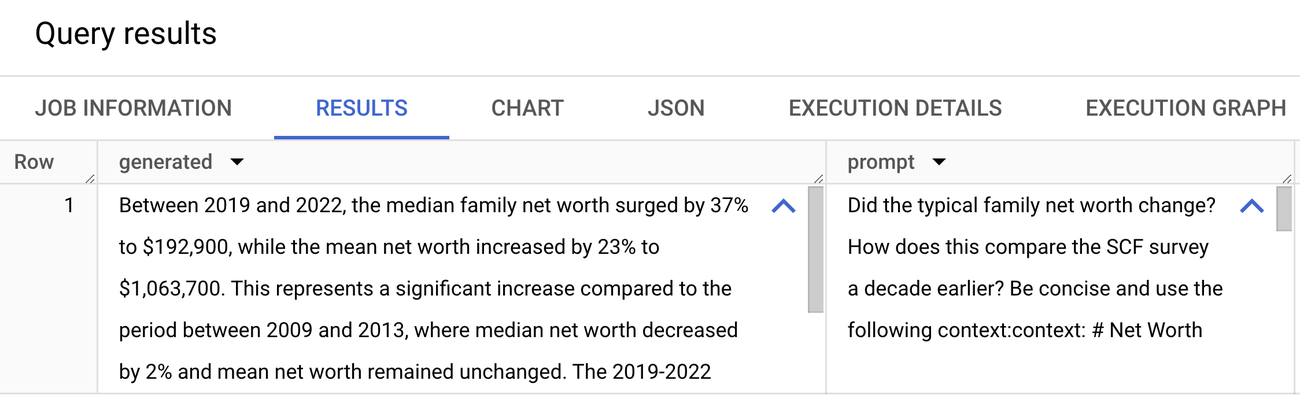
답을 확인해 보면, 중위 가구의 순자산은 2019년에서 2022년 사이에 37% 증가했습니다. 이는 10년 전 조사 기간에 확인된 2% 감소라는 결과에 비해 상당히 증가한 수치입니다. 원본 문서를 확인해 보면 이러한 정보가 텍스트, 표, 각주에 포함되어 있어 기존의 방식으로는 파싱하고 결과까지 함께 추론하기가 까다로운 부분임을 알 수 있습니다.
이 예에서는 기본적인 RAG 흐름을 살펴봤지만, 실제 애플리케이션에서는 지속적인 업데이트가 필요한 경우가 많습니다. 매일 새로운 재무 보고서가 Cloud Storage 버킷에 추가되는 시나리오를 생각해 보세요. RAG 파이프라인을 최신 상태로 유지하려면 BigQuery Workflows 또는 Cloud Composer를 사용하여 새로운 문서를 점진적으로 처리하고 BigQuery에서 임베딩을 생성하는 것을 고려하세요. 기본 데이터가 변경되면 벡터 색인이 자동으로 새로고침되어 항상 최신 정보를 쿼리할 수 있습니다.
BigQuery에서 문서 파싱 시작
Document AI의 Layout Parser와 BigQuery 간 통합 덕분에 개발자는 강력한 RAG 파이프라인을 더 쉽게 빌드할 수 있습니다. ML.PROCESS_DOCUMENT 및 기타 BigQuery 머신러닝 기능을 활용하면 SQL을 사용하여 BigQuery 내에서 문서 전처리 간소화, 임베딩 생성, 시맨틱 검색을 모두 수행할 수 있습니다.
자세히 알아볼 준비가 되셨나요? 아래 링크의 리소스와 문서를 살펴보세요.
의견이나 질문이 있다면 bqml-feedback@google.com을 통해 알려주세요.



