GenOps : s’inspirer du monde des microservices et du DevOps classique
Sam Weeks
AI/ML Customer Engineer, UKI, Google Cloud
Mais qui donc va gérer les applications d’IA générative ? Bien que la responsabilité de l'IA soit souvent confiée aux équipes de données, nous constatons que les exigences spécifiques aux applications d'IA générative diffèrent sensiblement de celles des équipes de données et d'IA traditionnelles.
En fait, ces exigences s'apparentent parfois davantage à celles d'une équipe DevOps. Nous allons ici explorer ces similitudes et différences, et examiner la nécessité de créer une nouvelle équipe "GenOps" pour répondre aux caractéristiques spécifiques des applications d'IA générative.
Contrairement aux pratiques de la Data Science, qui vise à créer des modèles à partir de données, l'IA générative se concentre sur la création de services dopés à l'IA à partir de modèles IA. Dit autrement, la GenAI implique une complexe intégration de données préexistantes, de modèles et d'API. Vu sous cet angle, l'IA générative ressemble dès lors étonnamment à un environnement de microservices traditionnel : plusieurs services distincts, découplés et interopérables, consommés via des API. Si le paysage présente des similitudes, il est logique que ces domaines partagent des exigences opérationnelles communes. Alors, quelles pratiques pouvons-nous emprunter au monde des microservices et du DevOps pour les appliquer au nouveau domaine du GenOps ?
Que mettons-nous en œuvre ? L'agent IA versus le microservice
En quoi les exigences opérationnelles d'une application d'IA générative diffèrent-elles des autres applications ?
Dans les applications traditionnelles, l'unité « opérationnelle » est le microservice : une unité de code fonctionnelle et distincte, encapsulée dans un conteneur et déployée dans un environnement d'exécution compatible avec les conteneurs, comme Kubernetes.
Pour les applications d'IA générative, l'unité comparable est l'agent d'IA générative, ou Agent IA. Il s'agit également d'une unité de code fonctionnelle et distincte, conçue pour gérer une tâche spécifique, mais avec des composants supplémentaires qui en font plus qu'un "simple" microservice.
Ces composants lui confèrent sa caractéristique distinctive clé : un comportement non déterministe tant dans son traitement que dans ses résultats. Voici ces composants :
1- Boucle de raisonnement - La logique de contrôle qui définit ce que fait l'agent et comment il fonctionne. Elle inclut souvent une logique itérative ou des chaînes de réflexion pour décomposer une tâche initiale en une série d'étapes animées par des modèles IA, qui travaillent à l'accomplissement de la tâche.
2- Définitions de modèles - Une ou plusieurs méthodes d'accès prédéfinies pour communiquer avec les modèles, lisibles et utilisables par la boucle de raisonnement.
3- Définitions d'outils - Un ensemble de méthodes d'accès prédéfinies pour agir sur d’autres services externes à l’agent, tels que d’autres agents, des flux d’accès aux données (RAG), et des API externes. Ces définitions devraient être partagées entre les agents et exposées via des API. Par conséquent, une définition d’outil prendra la forme d’une norme lisible par machine, comme une spécification OpenAPI.

Les composants logiques d’un Agent d’IA Générative
En poursuivant les analogies évoquées plus haut, on peut considérer que « la boucle de raisonnement » correspond essentiellement au spectre fonctionnel d'un microservice, autrement dit à l’ensemble des fonctions, opérations, processus et responsabilités typiques d’un microservice. Les définitions de modèles et d'outils constituent des capacités supplémentaires qui en étendent le potentiel.
Il est important de noter que, bien que la logique de la boucle de raisonnement ne soit que du code et donc soit de nature déterministe, elle est pilotée par les réponses de modèles d'IA qui sont, eux, non déterministes. Cette nature non déterministe justifie le besoin d'outils, car l'agent "choisit par lui-même" quel service externe utiliser pour accomplir une tâche. Au contraire, un microservice traditionnel est typiquement entièrement déterministe. Il n'a pas besoin de ce "livre de recettes" d'outils parmi lesquels choisir : ses appels aux services externes sont prédéterminés et codés en dur.
D’autres similarités émergent par ailleurs. Tout comme un microservice, un agent :
- Est une unité fonctionnelle distincte qui devrait être partagée entre plusieurs applications, utilisateurs et équipes dans un modèle multi-locataire (multi-tenant).
- Offre une grande flexibilité dans les approches de développement, avec un large éventail de langages de programmation disponibles. Chaque agent peut être construit d'une manière différente des autres.
- Présente une très faible interdépendance d'un agent à l'autre : les cycles de développement sont découplés, avec des pipelines de CI/CD indépendants pour chacun. La mise à jour d'un agent ne devrait pas affecter un autre agent.

Plateformes opérationnelles et répartition des responsabilités
Ce que le tableau ci-dessus ne dit pas, c’est qu’il existe une autre différence majeure : la découverte de services.
Dans le monde des microservices, ce problème est déjà résolu. Les microservices n’ont plus à se soucier de la disponibilité, de l’emplacement ou des aspects réseau leur permettant de communiquer entre eux. Ces difficultés leur ont été retirées en les regroupant dans des conteneurs et en les déployant sur des plateformes communes comme Kubernetes et Istio.
Pour les agents d’IA générative, cette standardisation n’existe pas encore. Il y a plusieurs façons de créer et de déployer un agent d’IA générative, allant des solutions “bricolées” avec des bouts de code aux environnements managés de création d’agents en no-code. Bien que ces outils soient utiles, ils créent un paysage de déploiement plus varié que celui des microservices, ce qui pourrait à l’avenir engendrer des complications opérationnelles.
Pour résoudre cette difficulté, il est par exemple possible d’adopter un modèle en étoile (ou hub-and-spoke) au lieu du traditionnel modèle point-à-point utilisé sur les microservices. Dans un modèle en étoile, la découverte des agents, des outils et des modèles se fait via la publication d'API sur une passerelle API. Cette dernière vient offrir une couche d’abstraction cohérente au-dessus de ce paysage hétérogène d’agents. En d’autres termes, au lieu d’avoir des connexions directes entre tous les éléments (comme dans les microservices), on crée un point central (le hub) qui gère toutes les connexions. Cela simplifie la gestion et la communication entre les différents composants, même s’ils sont très variés.
Il en résulte un avantage supplémentaire : une séparation claire et nette des responsabilités entre, d'une part, les applications et les agents créés par les équipes de développement et, d'autre part, les composants spécifiques à l'IA générative, comme les modèles et les outils.
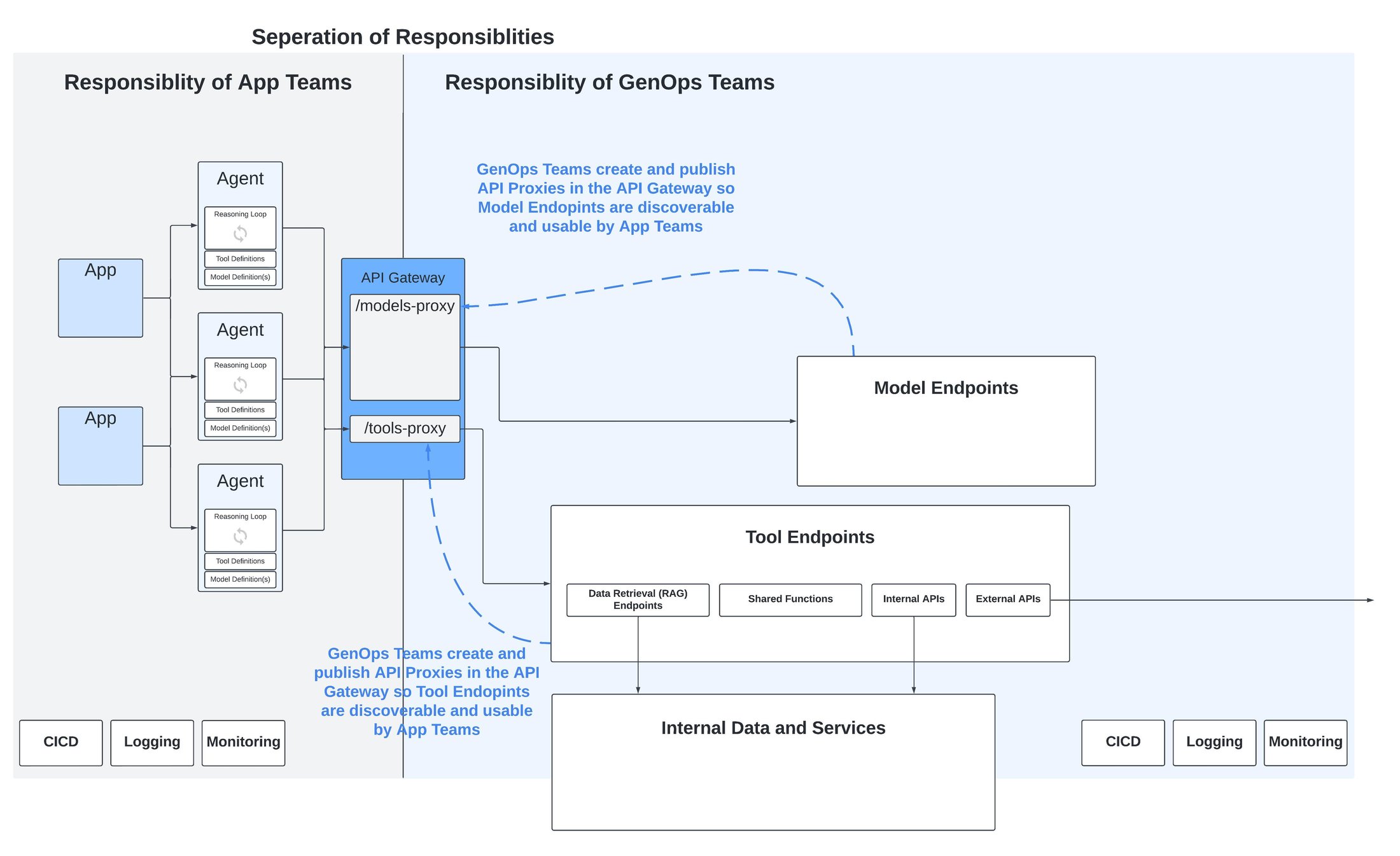
Séparation des responsabilités grâce à une API Gateway (Passerelle d’API)
En pratique, toute plateforme vraiment opérationnelle se doit de bien séparer les rôles et responsabilités entre les équipes de développements (d’apps et microservices) et les équipes des opérations IT.
Dans le cas des applications basées sur des microservices, le transfert des responsabilités se fait au moment du déploiement. À partir de ce moment clé, l'attention se porte sur les exigences non fonctionnelles telles que la fiabilité, la scalabilité, l'efficacité de l'infrastructure, la gestion du réseau, la sécurité.
Bien évidemment ces exigences restent tout aussi importantes pour une application d'IA générative. Néanmoins, j’estime qu'il existe des considérations supplémentaires spécifiques aux agents IA et aux applications IA génératives. Ces considérations nécessitent des outils opérationnels particuliers que je vais ici détailler :
- Contrôles de conformité et d'approbation des modèles
Le monde des modèles d'IA est une vraie jungle ! On en trouve à toutes les sauces : open source, sous-licence, avec ou sans protection de la propriété intellectuelle. Chacun vient avec son lot de conditions d'utilisation, souvent complexes et pleines de pièges juridiques. Décrypter tout ça est un vrai casse-tête qui demande du temps et les compétences adéquates.
Soyons réalistes : on ne peut pas demander aux développeurs de jongler avec ces considérations quand ils choisissent un modèle. Ce serait comme leur demander d'être à la fois codeurs et avocats ! Dès lors, il devient essentiel de mettre en place un processus dédié de révision et d'approbation des modèles. Ce processus, géré par les équipes juridiques et de conformité, doit être soutenu techniquement par des procédures d'approbation ou de refus claires, gouvernables et auditées, qui se répercutent en cascade dans les environnements de développement.
Ainsi, l’entreprise s'assure que les choix de modèles sont non seulement techniquement solides, mais aussi juridiquement blindés. C'est la garantie d'une utilisation sereine et maîtrisée de l'IA dans votre organisation !
2 – Gestion des versions des prompts
Les prompts, ou invites ou encore instructions en français, ces petites phrases magiques qui font danser les modèles, doivent être optimisés pour chacun d’eux. Dit autrement, chaque modèle a besoin de prompts rédigés sur mesure pour donner le meilleur de lui-même.
Dès lors se pose une question fondamentale : est-ce vraiment le boulot des équipes de développements d’application de passer des heures à peaufiner des prompts ? Ne devraient-elles pas plutôt se concentrer sur ce qu'elles font de mieux : créer des apps d’exception qui font la différence pour les métiers ?
La gestion des prompts est un peu comme la plomberie d'un bâtiment, essentielle mais invisible. Évolutive, elle a tout à gagner à être séparée du code source des applications et à être gérée de manière centralisée. Il devient ainsi possible d’évaluer périodiquement les prompts et de les faire évoluer sans modifier les codes sources. Mieux encore, il est ainsi plus aisé de réutiliser les meilleurs prompts (et rentabiliser le travail nécessaire à leur création) à travers différentes applications et agents.
- Évaluation des modèles (et des prompts)
Les modèles sont comparables à des athlètes de haut niveau dont il faut mesurer en permanence l’évolution des performances.
Tout comme avec une plateforme MLOps, il existe un réel besoin d'évaluations continues de la qualité des réponses des modèles. Objectif ? Disposer d’une approche basée sur les données pour évaluer et sélectionner les modèles les plus adaptés au cas d'utilisation considéré.
La principale différence avec les modèles d'IA générative est que l'évaluation est intrinsèquement plus qualitative par rapport à l'analyse quantitative du biais ou de la détection de dérive d'un modèle ML traditionnel.
L'IA générative vient cependant pimenter les choses avec son lot de subtilités ! Contrairement aux modèles ML traditionnels, où l'on peut facilement mesurer des dérives ou des biais avec des chiffres, l’IA générative demande d’évaluer, de juger, la qualité des réponses. Or il n’est pas toujours évident de mettre une note précise !
Les évaluations subjectives et qualitatives effectuées par des humains ne sont clairement pas évolutives et introduisent de l'incohérence lorsqu'elles sont réalisées par plusieurs personnes. À la place, nous avons besoin de pipelines automatisés cohérents alimentés par des évaluateurs IA qui, bien qu'imparfaits, assureront une cohérence dans les évaluations et fourniront une base de référence pour comparer les modèles entre eux.
Une telle approche basée sur l’IA offre une perspective plus précise, reproductible et impartiale sur les performances et les évolutions des modèles et des prompts. Elle permet d’intégrer une surveillance continue et « data-driven » pour garantir une utilisation optimale et éclairée des ressources IA.
- Passerelle de sécurité des modèles
La fonctionnalité opérationnelle dont j'entends le plus souvent parler dans les grandes entreprises est un proxy de sécurité. Son rôle ? Effectuer des vérifications (éthiques et de sécurité/conformité) avant de transmettre une requête à un modèle (et vice versa : vérifier la réponse générée avant de la renvoyer à l’utilisateur).
Les points clés à considérer au niveau du Proxy de Sécurité :
- Anticiper, détecter et bloquer les attaques par injection de prompt et autres menaces identifiées par l'OWASP Top 10 pour les LLM.
- Détecter et bloquer les prompts nuisibles ou contraires à l'éthique
- Repérer et traiter les données personnelles des clients ou autres informations sensibles nécessitant une censure ou une anonymisation avant d'être envoyées au modèle et aux systèmes IA en aval.
Certains modèles disposent de contrôles de sécurité intégrés. Toutefois cette intégration peut créer de l'incohérence et augmenter la complexité. Autre solution ? Mettre en place un point d'accès sécurisé indépendant du modèle, placé en amont de tous les modèles. Il en résulte une plus grande cohérence globale et une facilité accrue pour passer d'un modèle à l'autre.
- Gestion centralisée des outils
Pour finir, les outils accessibles à l'agent IA devraient être séparés de celui-ci. Pourquoi ? Pour permettre leur réutilisation et une gouvernance centralisée. C'est la bonne façon de répartir les responsabilités, surtout quand il s'agit d’exploiter des données dont l'accès doit être contrôlé.
Les modèles RAG (Retrieval-Augmented Generation) ont tendance à se multiplier et à se complexifier. En pratique, ils ne sont pas toujours très robustes ni bien entretenus, ce qui peut engendrer une dette technique importante. D'où l'importance d'un contrôle centralisé pour garder les méthodes d'accès aux données aussi saines et visibles que possible.
Au-delà de ces considérations spécifiques, il est essentiel — comme nous l'avons évoqué ci-dessus — de disposer d’une passerelle API pour créer de la cohérence et une couche d'abstraction au-dessus de ces services d'IA générative. Utilisées à leur plein potentiel, les passerelles API peuvent jouer un rôle bien plus important qu'un simple point d'accès API. Elles peuvent devenir un centre de coordination et de regroupement pour une série d'appels API intermédiaires, de logiques diverses, de fonctionnalités de sécurité et de suivi d'utilisation.
Prenons l'exemple d'une API publiée pour envoyer une requête à un modèle. Elle peut être le point de départ d'un processus en plusieurs étapes :
- Récupérer et "hydrater" le modèle de prompt optimal pour ce cas d'utilisation et ce modèle spécifique.
- Effectuer des vérifications de sécurité via le service de sécurité du modèle.
- Envoyer la requête au modèle.
Enregistrer le prompt, la réponse et d'autres informations pour les utiliser dans des processus opérationnels tels que les pipelines d'évaluation des modèles et des prompts.
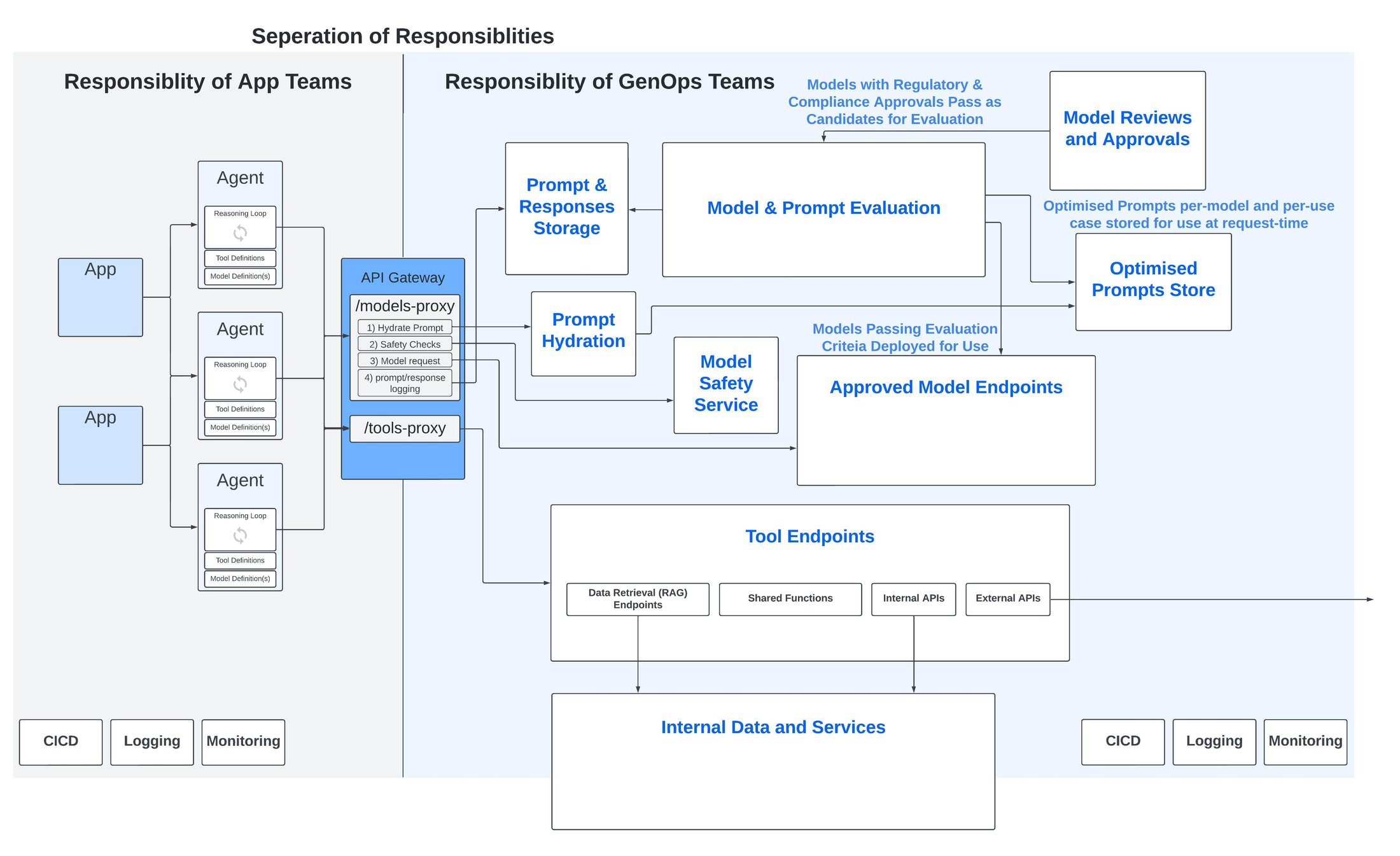
Les principales composantes d’une plateforme GenOps
Concrétiser le GenOps avec Google Cloud
Bien évidemment (mais en doutiez-vous ?), pour chacune des considérations évoquées ci-dessus, Google Cloud propose des services managés uniques et différenciants pour aider à évaluer, déployer, sécuriser et mettre à niveau les applications et agents d'IA générative :
- Pour les contrôles de conformité et d'approbation des modèles :
Le "Model Garden" de Google Cloud est la bibliothèque centrale regroupant plus de 150 modèles propriétaires de Google, de partenaires ou open source, avec des milliers d'autres disponibles grâce à une intégration directe avec Hugging Face. - Pour la sécurité des modèles :
Le tout nouveau "Model Armor", actuellement en preview, permet l'inspection, le routage et la protection des prompts et des réponses des modèles fondation. Il peut aider à atténuer les risques tels que les injections de prompts, les contournements de sécurité, les contenus toxiques et les fuites de données sensibles. - Pour la gestion des versions de prompts :
De nouvelles fonctionnalités de gestion des prompts ont été annoncées lors de Google Cloud Next '24, incluant le contrôle de version centralisé, la création de modèles, la gestion de branches et le partage de prompts. Nous avons également présenté des capacités d'assistance IA pour critiquer et réécrire automatiquement les prompts. - Pour l’évaluation des modèles (et des prompts) :
Les services d'évaluation automatisée de modèles de Google Cloud offrent des évaluations par l’IA avec une large gamme de métriques, de prompts et de réponses. Ils permettent des schémas d'évaluation flexibles et extensibles. Par exemple, vous pouvez comparer les réponses de deux modèles différents pour une même entrée, ou encore analyser les résultats obtenus avec deux prompts distincts sur un seul modèle. - Pour la gestion centralisée des outils :
Une suite complète de services managés est disponible pour soutenir la création d'outils. Parmi ceux-ci, on peut citer Document AI Layout Parser pour le découpage intelligent de documents, l'API d'embeddings multimodaux, Vertex AI Vector Search, et je tiens particulièrement à souligner Vertex AI Search : un service RAG entièrement managé, prêt à l'emploi, qui gère toutes les complexités, de l'analyse et du découpage des documents à la création et au stockage des embeddings.
Cette approche intégrée de Google Cloud permet aux entreprises de tirer pleinement parti des technologies d'IA générative tout en maintenant un contrôle et une sécurité optimaux.
En ce qui concerne la passerelle API, Apigee de Google Cloud permet de publier et d'exposer des modèles et des outils IA sous forme de proxies API. Ces proxies peuvent englober plusieurs appels API en aval, tout en intégrant une logique conditionnelle, des mécanismes de réessai, ainsi que des outils pour la sécurité, le suivi de l'utilisation et la refacturation interne.
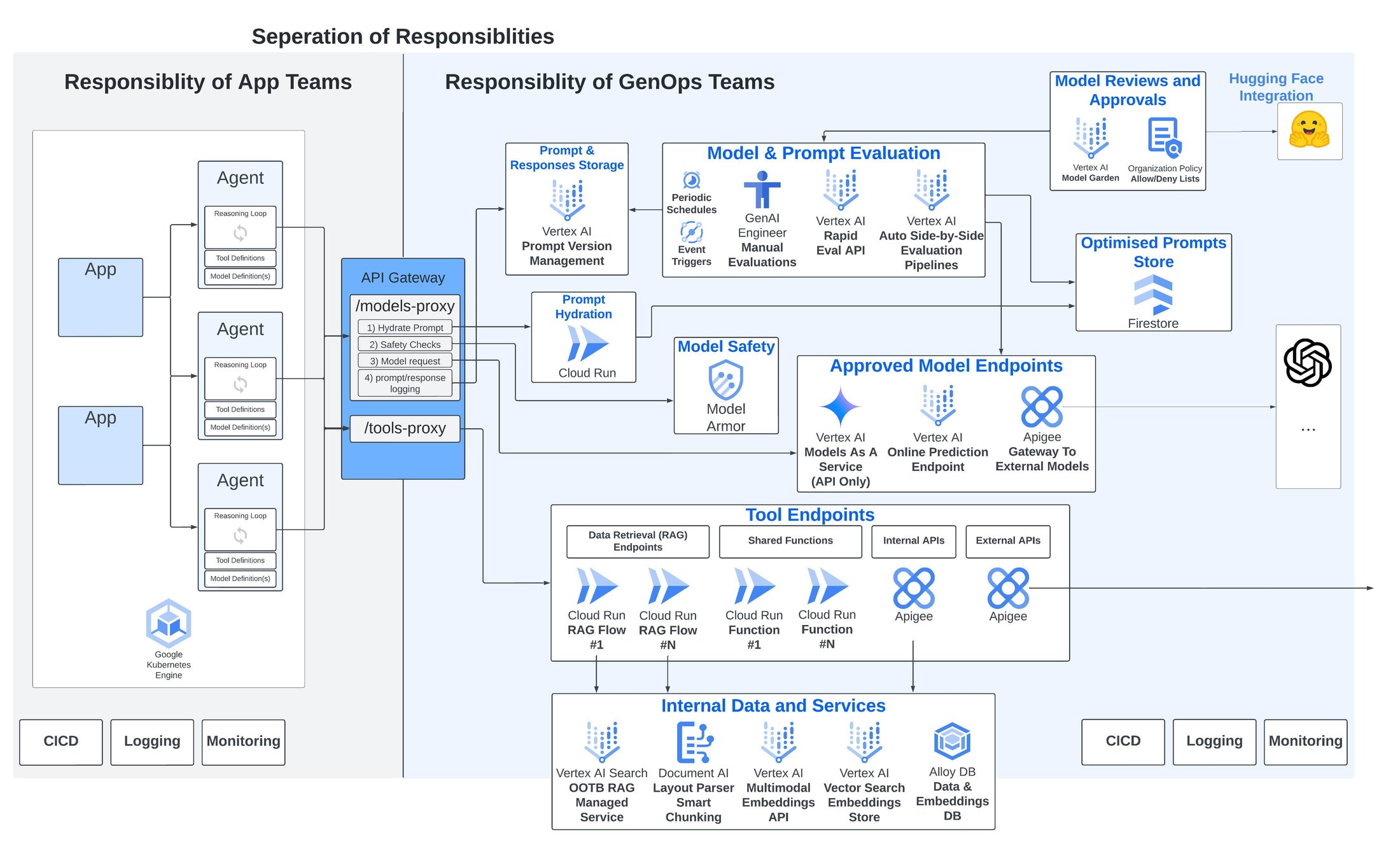
La plateforme GenOps de Google Cloud avec ses outils et services managés
Peu importe la taille de votre entreprise, pour réussir avec l'IA générative, un impératif s'impose : maîtriser les spécificités et les besoins uniques de vos applications d'IA. C'est là qu'entre en jeu une plateforme opérationnelle taillée sur mesure, votre meilleure arme pour relever ces défis. Et c’est là que Google Cloud vous vient en aide avec sa plateforme GenOps Cloud pour l’IA générative.
J'espère que les idées présentées dans ce billet vous seront utiles pour naviguer dans cette ère technologique révolutionnaire. L'IA générative bouleverse nos façons de faire, et c'est passionnant !
Envie d'en savoir plus ? N'attendez pas ! Contactez votre équipe Google Cloud ou lancez-moi un message directement. Ensemble, explorons les possibilités infinies de l'IA générative pour booster votre business.


