Documentação do AutoML Vision Object Detection
Visão geral dos recursos
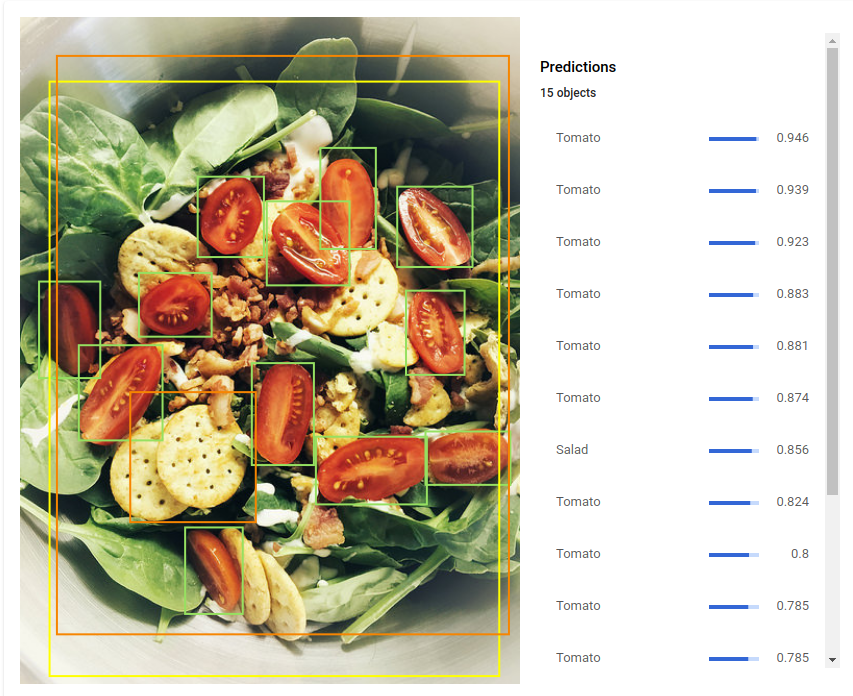
Com o Cloud AutoML Vision Object Detection, os desenvolvedores podem treinar modelos personalizados de machine learning capazes de detectar objetos individuais em uma determinada imagem junto com a caixa delimitadora e o rótulo.
A versão do Cloud AutoML Vision Object Detection inclui os seguintes atributos:
Localização de objetos: detecta vários objetos em uma imagem e fornece informações sobre o objeto e onde ele foi encontrado na imagem.
API/IU: fornece uma API e uma interface do usuário personalizada para importar o conjunto de dados de um arquivo CSV hospedado do Google Cloud Storage e imagens de treinamento, adicionar e remover anotações de imagens importadas, treinar e analisar métricas de avaliação de modelos e usar seu modelo com previsão on-line.
O AutoML Vision Edge agora permite que você exporte modelos personalizados treinados pelo AutoML Vision Object Detection.
- O AutoML Vision Edge permite treinar e implantar modelos de baixa latência e alta precisão otimizados para dispositivos de borda.
- Com o TensorFlow Lite, o Core ML e os formatos de exportação de contêiner, o AutoML Vision Edge é compatível com vários dispositivos.
- Arquiteturas de hardware compatíveis: TPUs do Edge, ARM e NVIDIA.
- Para criar um aplicativo em dispositivos iOS ou Android, é possível usar o AutoML Vision Edge no kit de ML. Essa solução está disponível por meio do Firebase e oferece um fluxo de desenvolvimento completo para criar e implantar modelos personalizados em dispositivos móveis usando bibliotecas de cliente do kit de ML.
Recursos de documentação
Guias
-
Guia de início rápido: rotular imagens usando a API no Console
-
Guia de início rápido: rotular imagens usando a API AutoML Vision Edge
-
Guia de início rápido: rotular imagens usando a API AutoML Vision
-
Como preparar os dados de treinamento
-
Como formatar um CSV de dados de treinamento
-
Como anotar imagens de treinamento importadas
-
Como avaliar modelos;
-
Como fazer previsões individuais
-
Como exportar modelos do Edge
-