Documentation sur AutoML Vision Object Detection
Aperçu des fonctionnalités
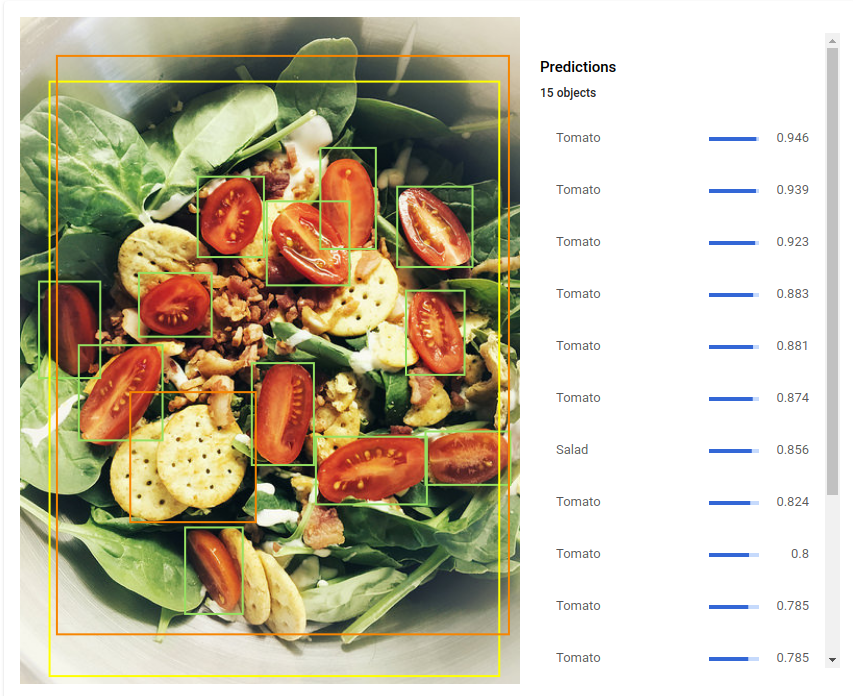
AutoML Vision Object Detection permet aux développeurs d'entraîner des modèles de machine learning personnalisés capables de détecter des objets individuels dans une image donnée, ainsi que son cadre de délimitation et son étiquette.
La version de AutoML Vision Object Detection inclut les fonctionnalités suivantes :
Localisation d'objets : détecte plusieurs objets dans une image et fournit des informations sur l'objet et son emplacement dans l'image.
API/UI : fournit une API et une interface utilisateur personnalisée pour importer votre ensemble de données à partir d'un fichier CSV hébergé dans Google Cloud Storage ainsi que des images d'entraînement, pour ajouter et supprimer des annotations dans les images importées, pour entraîner et examiner les statistiques d'évaluation des modèles et pour utiliser votre modèle avec la prédiction en ligne.
AutoML Vision Edge vous permet désormais d'exporter vos modèles AutoML Vision Object Detection personnalisés.
- AutoML Vision Edge vous permet d'entraîner et de déployer des modèles haute précision à faible latence optimisés pour les appareils de périphérie.
- Grâce à TensorFlow Lite, à Core ML et aux formats d'exportation de conteneurs, AutoML Vision Edge est compatible avec de nombreux appareils.
- Architectures matérielles compatibles : Edge TPU, ARM et NVIDIA.
- Pour créer une application sur des appareils iOS ou Android, vous pouvez utiliser la solution AutoML Vision Edge du kit ML. Cette solution est disponible via Firebase et offre un processus de développement de bout en bout pour créer et déployer des modèles personnalisés sur les appareils mobiles à l'aide des bibliothèques clientes du kit ML.
Ressources de documentation
Guides
-
Guide de démarrage rapide : Ajouter des libellés à des images à l'aide de l'API dans la console
-
Guide de démarrage rapide : Ajouter des libellés à des images à l'aide de l'API AutoML Vision Edge
-
Guide de démarrage rapide : Ajouter des libellés à des images à l'aide de l'API AutoML Vision
-
Préparer les données d'entraînement
-
Mettre en forme un fichier CSV de données d'entraînement
-
Annoter des images d'entraînement importées
-
Évaluer des modèles
-
Effectuer des prédictions individuelles
-
Exporter des modèles Edge
-