Cosa creerai
In questo tutorial scaricherai un modello TensorFlow Lite personalizzato esportato da AutoML Vision Edge. Eseguirai quindi un'app per iOS predefinita che utilizza il modello per rilevare più oggetti all'interno di un'immagine (con riquadri di delimitazione) e fornire un'etichettatura personalizzata delle categorie di oggetti.
Obiettivi
In questa procedura dettagliata introduttiva end-to-end, utilizzerai il codice per:
- Esegui un modello AutoML Vision Object Detection Edge in un'app per iOS utilizzando l'interprete TF Lite.
Prima di iniziare
Clona il repository Git
Utilizzando la riga di comando, clona il seguente repository Git con il seguente comando:
git clone https://github.com/tensorflow/examples.git
Vai alla directory ios del clone locale del repository (examples/lite/examples/object_detection/ios/). Eseguirai tutti i seguenti esempi di codice dalla directory ios:
cd examples/lite/examples/object_detection/ios
Prerequisiti
- Git installato.
- Versioni di iOS supportate: iOS 12.0 e versioni successive.
Configura l'app per iOS
Generare e aprire il file dell'area di lavoro
Per iniziare a configurare l'app per iOS originale, devi prima generare il file dell'area di lavoro utilizzando il software richiesto:
Vai alla cartella
iosse non l'hai ancora fatto:cd examples/lite/examples/object_detection/ios
Installa il pod per generare il file dell'area di lavoro:
pod install
Se hai già installato questo pod, utilizza il seguente comando:
pod update
Dopo aver generato il file dell'area di lavoro, puoi aprire il progetto con Xcode. Per aprire il progetto dalla riga di comando, esegui questo comando dalla directory
ios:open ./ObjectDetection.xcworkspace
Creare un identificatore univoco e creare l'app
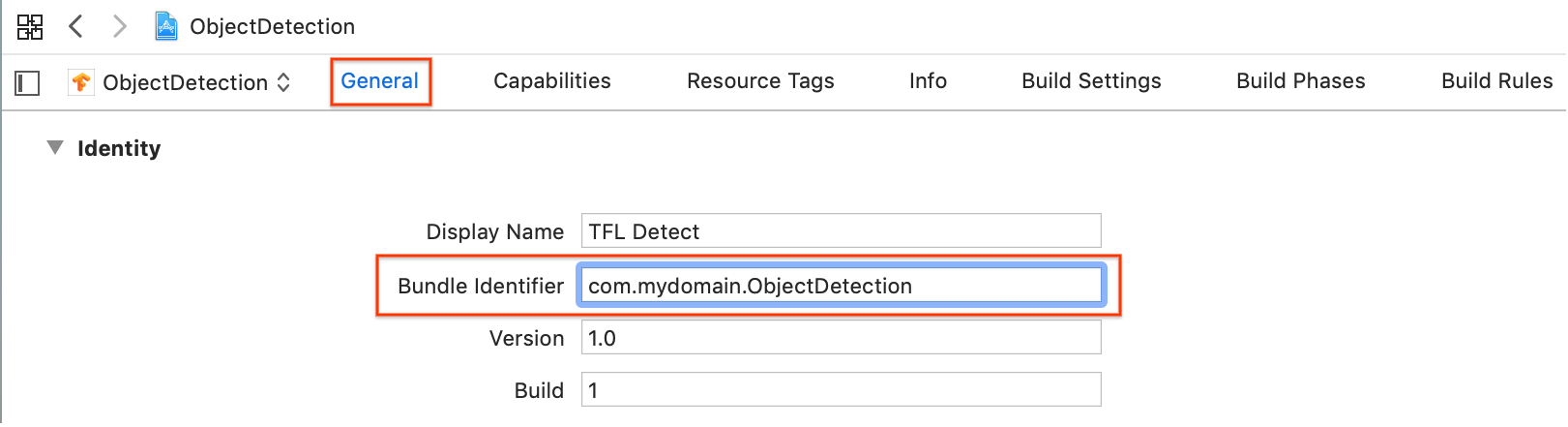
Con ObjectDetection.xcworkspace aperto in Xcode, devi prima modificare
l'identificatore bundle (ID bundle) impostandolo su un valore univoco.
Seleziona l'elemento del progetto
ObjectDetectionin primo piano nella barra di navigazione dei progetti a sinistra.
Assicurati di aver selezionato Destinazioni > Rilevamento oggetti.
Nella sezione Generale > Identità, modifica il campo Identificatore pacchetto impostandolo su un valore univoco. Lo stile preferito è la notazione inversa del nome di dominio.
Nella sezione Generali > Firma sotto Identità, specifica un team nel menu a discesa. Questo valore è fornito dal tuo ID sviluppatore.
Collega un dispositivo iOS al computer. Una volta rilevato il dispositivo, selezionalo dall'elenco.
Dopo aver specificato tutte le modifiche alla configurazione, crea l'app in Xcode utilizzando il seguente comando: Comando + B.
Esegui l'app originale
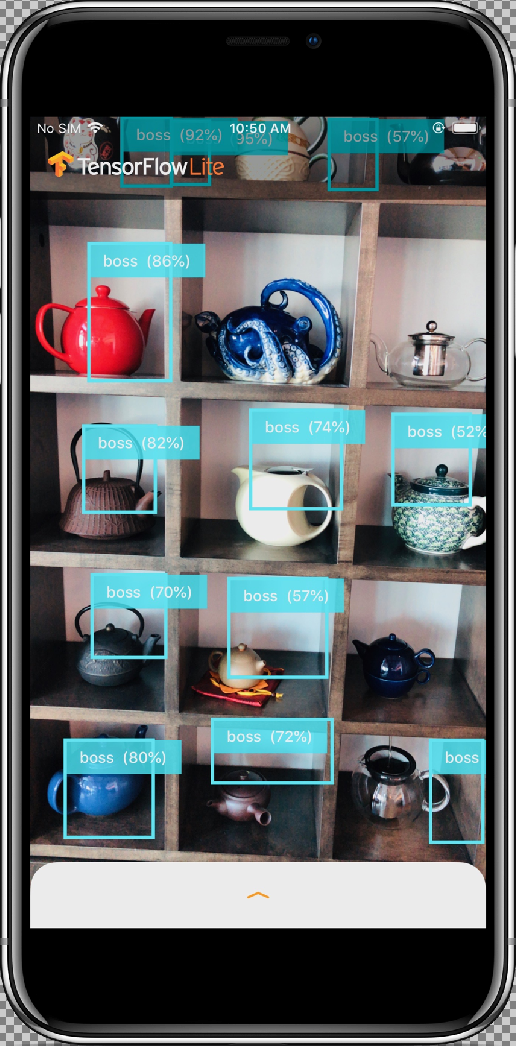
L'app di esempio è un'app per fotocamera che rileva continuamente gli oggetti (riquadro di delimitazione ed etichette) nei frame visti dalla fotocamera posteriore del dispositivo, utilizzando un modello SSD MobileNet quantizzato addestrato sul set di dati COCO.
Queste istruzioni illustrano la creazione e l'esecuzione della demo su un dispositivo iOS.
I file del modello vengono scaricati tramite script in Xcode quando crei ed eseguili. Non è necessario eseguire alcuna procedura per scaricare in modo esplicito i modelli TF Lite nel progetto.
Prima di inserire il modello personalizzato, testa la versione di base dell'app che utilizza il modello addestrato "mobilenet" di base.
Per avviare l'app nel simulatore, seleziona il pulsante di riproduzione
 nell'angolo in alto a sinistra della finestra di Xcode.
nell'angolo in alto a sinistra della finestra di Xcode.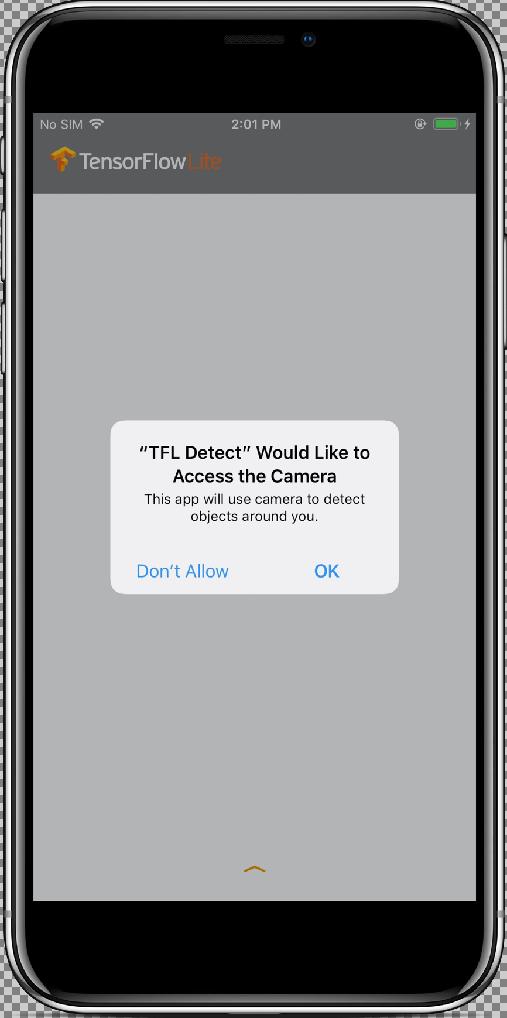
Dopo aver consentito all'app di accedere alla videocamera selezionando il pulsante Consenti, l'app avvierà il rilevamento e l'annotazione in tempo reale. Gli oggetti verranno rilevati e contrassegnati con un riquadro di delimitazione e un'etichetta in ogni fotogramma della videocamera.
Sposta il dispositivo in oggetti diversi nell'ambiente circostante e verifica che l'app rilevi correttamente le immagini.
Esegui l'app personalizzata
Modifica l'app in modo che utilizzi il modello riaddestrato con categorie di immagini di oggetti personalizzate.
Aggiungi i file del modello al progetto
Il progetto dimostrativo è configurato per cercare due file nella directory ios/objectDetection/model:
detect.tflitelabelmap.txt
Per sostituire questi due file con le tue versioni personalizzate, esegui questo comando:
cp tf_files/optimized_graph.lite ios/objectDetection/model/detect.tflite cp tf_files/retrained_labels.txt ios/objectDetection/model/labelmap.txt
Esegui l'app
Per riavviare l'app sul tuo dispositivo iOS, seleziona il pulsante riproduci ![]() nell'angolo in alto a sinistra della finestra di Xcode.
nell'angolo in alto a sinistra della finestra di Xcode.
Per testare le modifiche, sposta la fotocamera del dispositivo su una serie di oggetti per vedere previsioni in tempo reale.
I risultati dovrebbero essere simili a questi:
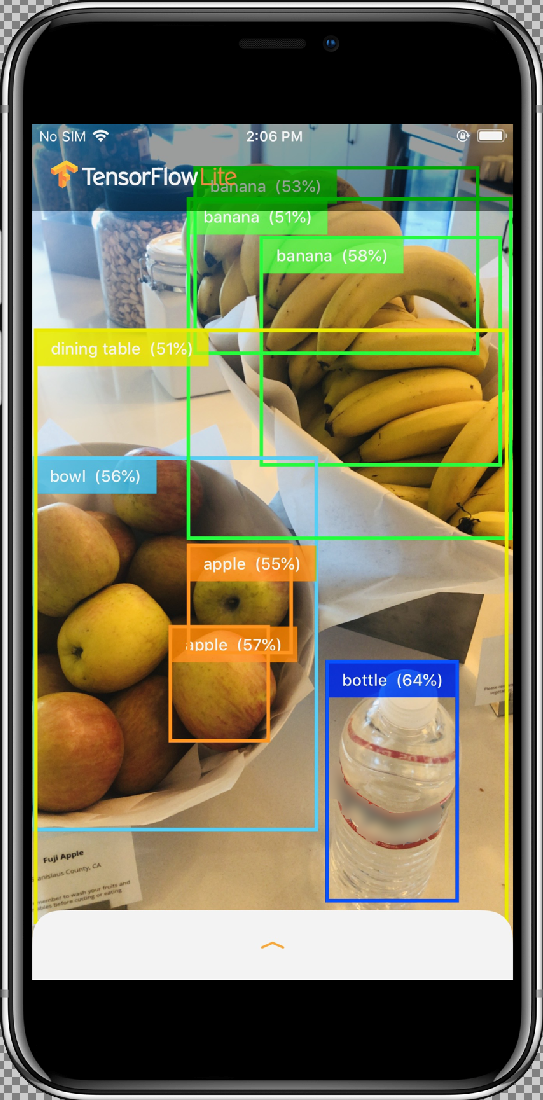
Come funziona?
Ora che l'app è in esecuzione, controlla il codice specifico di TensorFlow Lite.
Pod TensorFlowLite
Questa app utilizza un TFLite Cocoapod precompilato. Il Podfile include cocoapod nel progetto:
# Uncomment the next line to define a global platform for your project platform :ios, '12.0' target 'ObjectDetection' do # Comment the next line if you're not using Swift and don't want to use dynamic frameworks use_frameworks! # Pods for ObjectDetection pod 'TensorFlowLiteSwift' end
Il codice di interfacciamento con TF Lite è tutto contenuto nel
file ModelDataHandler.swift. Questa classe gestisce la pre-elaborazione di tutti i dati ed effettua chiamate per eseguire l'inferenza su un determinato frame richiamando Interpreter.
Quindi formatta le inferenze ottenute e restituisce i primi N risultati per un'inferenza riuscita.
Esplorare il codice
Il primo blocco di interesse (dopo le importazioni necessarie) riguarda le dichiarazioni
sulla proprietà. Puoi trovare i parametri inputShape del modello tfLite (batchSize, inputChannels, inputWidth, inputHeight) in tflite_metadata.json, avrai questo file quando esporterai il modello tflite. Per saperne di più, consulta l'argomento didattico Esportazione di modelli Edge.
L'esempio di tflite_metadata.json è simile al seguente codice:
{
"inferenceType": "QUANTIZED_UINT8",
"inputShape": [
1, // This represents batch size
512, // This represents image width
512, // This represents image Height
3 //This represents inputChannels
],
"inputTensor": "normalized_input_image_tensor",
"maxDetections": 20, // This represents max number of boxes.
"outputTensorRepresentation": [
"bounding_boxes",
"class_labels",
"class_confidences",
"num_of_boxes"
],
"outputTensors": [
"TFLite_Detection_PostProcess",
"TFLite_Detection_PostProcess:1",
"TFLite_Detection_PostProcess:2",
"TFLite_Detection_PostProcess:3"
]
}
...
Parametri del modello:
Sostituisci i valori seguenti in base al file tflite_metadata.json per il tuo modello.
let batchSize = 1 //Number of images to get prediction, the model takes 1 image at a time let inputChannels = 3 //The pixels of the image input represented in RGB values let inputWidth = 300 //Width of the image let inputHeight = 300 //Height of the image ...
init
Il metodo init, che crea Interpreter con percorso Model e InterpreterOptions, quindi alloca memoria per l'input del modello.
init?(modelFileInfo: FileInfo, labelsFileInfo: FileInfo, threadCount: Int = 1) {
let modelFilename = modelFileInfo.name
// Construct the path to the model file.
guard let modelPath = Bundle.main.path(forResource: modelFilename,ofType: modelFileInfo.extension)
// Specify the options for the `Interpreter`.
var options = InterpreterOptions()
options.threadCount = threadCount
do {
// Create the `Interpreter`.
interpreter = try Interpreter(modelPath: modelPath, options: options)
// Allocate memory for the model's input `Tensor`s.
try interpreter.allocateTensors()
}
super.init()
// Load the classes listed in the labels file.
loadLabels(fileInfo: labelsFileInfo)
}
…
runModel
Il seguente metodo runModel:
- Scala l'immagine di input in base alle proporzioni per cui il modello viene addestrato.
- Rimuove il componente alfa dal buffer dell'immagine per ottenere i dati RGB.
- Copia i dati RGB sul Tensor di input.
- Esegue l'inferenza richiamando
Interpreter. - Restituisce l'output dall'interprete.
- Formatta l'output.
func runModel(onFrame pixelBuffer: CVPixelBuffer) -> Result? {
Ritaglia l'immagine fino al quadrato più grande al centro e la riduce in base alle dimensioni del modello:
let scaledSize = CGSize(width: inputWidth, height: inputHeight)
guard let scaledPixelBuffer = pixelBuffer.resized(to: scaledSize) else
{
return nil
}
...
do {
let inputTensor = try interpreter.input(at: 0)
Rimuovi il componente alfa dal buffer dell'immagine per ottenere i dati RGB:
guard let rgbData = rgbDataFromBuffer(
scaledPixelBuffer,
byteCount: batchSize * inputWidth * inputHeight * inputChannels,
isModelQuantized: inputTensor.dataType == .uInt8
) else {
print("Failed to convert the image buffer to RGB data.")
return nil
}
Copia i dati RGB nell'input Tensor:
try interpreter.copy(rgbData, toInputAt: 0)
Esegui l'inferenza richiamando Interpreter:
let startDate = Date()
try interpreter.invoke()
interval = Date().timeIntervalSince(startDate) * 1000
outputBoundingBox = try interpreter.output(at: 0)
outputClasses = try interpreter.output(at: 1)
outputScores = try interpreter.output(at: 2)
outputCount = try interpreter.output(at: 3)
}
Formatta i risultati:
let resultArray = formatResults(
boundingBox: [Float](unsafeData: outputBoundingBox.data) ?? [],
outputClasses: [Float](unsafeData: outputClasses.data) ?? [],
outputScores: [Float](unsafeData: outputScores.data) ?? [],
outputCount: Int(([Float](unsafeData: outputCount.data) ?? [0])[0]),
width: CGFloat(imageWidth),
height: CGFloat(imageHeight)
)
...
}
Filtra tutti i risultati con punteggio di affidabilità < soglia e restituisce i primi N risultati ordinati in ordine decrescente:
func formatResults(boundingBox: [Float], outputClasses: [Float],
outputScores: [Float], outputCount: Int, width: CGFloat, height: CGFloat)
-> [Inference]{
var resultsArray: [Inference] = []
for i in 0...outputCount - 1 {
let score = outputScores[i]
Filtra i risultati con affidabilità < soglia:
guard score >= threshold else {
continue
}
Restituisce i nomi delle classi di output per le classi rilevate dall'elenco delle etichette:
let outputClassIndex = Int(outputClasses[i])
let outputClass = labels[outputClassIndex + 1]
var rect: CGRect = CGRect.zero
Traduce il riquadro di delimitazione rilevato in CGRect.
rect.origin.y = CGFloat(boundingBox[4*i])
rect.origin.x = CGFloat(boundingBox[4*i+1])
rect.size.height = CGFloat(boundingBox[4*i+2]) - rect.origin.y
rect.size.width = CGFloat(boundingBox[4*i+3]) - rect.origin.x
Gli angoli rilevati riguardano le dimensioni del modello. Quindi ridimensioniamo rect in base
alle dimensioni effettive dell'immagine.
let newRect = rect.applying(CGAffineTransform(scaleX: width, y: height))
Consente di ottenere il colore assegnato per il corso:
let colorToAssign = colorForClass(withIndex: outputClassIndex + 1)
let inference = Inference(confidence: score,
className: outputClass,
rect: newRect,
displayColor: colorToAssign)
resultsArray.append(inference)
}
// Sort results in descending order of confidence.
resultsArray.sort { (first, second) -> Bool in
return first.confidence > second.confidence
}
return resultsArray
}
CameraFeedManager
CameraFeedManager.swift gestisce tutte le funzionalità relative alla videocamera.
Inizializza e configura AV CaptureSession:
private func configureSession() {session.beginConfiguration()
Quindi prova ad aggiungere un
AVCaptureDeviceInpute aggiungebuiltInWideAngleCameracome input del dispositivo per la sessione.addVideoDeviceInput()
Quindi prova ad aggiungere un
AVCaptureVideoDataOutput:addVideoDataOutput()
session.commitConfiguration() self.cameraConfiguration = .success }Avvia la sessione.
Arresta la sessione.
Gestione degli errori:
- NSNotification.Name.AVCaptureSessionRuntimeError: viene pubblicata quando si verifica un errore imprevisto durante l'esecuzione dell'istanza
AVCaptureSession. Il dizionario userInfo contiene un oggettoNSErrorper la chiaveAVCaptureSessionErrorKey. - NSNotification.Name.AVCaptureSessionWasInterrupted: viene pubblicata quando si verifica un'interruzione (ad es. telefonata, sveglia e così via). Quando opportuno, verrà interrotta automaticamente l'esecuzione dell'istanza
AVCaptureSessionin seguito all'interruzione della risposta. Il campo userInfo conterràAVCaptureSessionInterruptionReasonKeyche indica il motivo dell'interruzione. - NSNotification.Name.AVCaptureSessionInterruptionEnded: viene pubblicata quando
AVCaptureSessioninterrompe l'interruzione. L'istanza della sessione può riprendere in seguito a un'interruzione, ad esempio al termine di una telefonata.
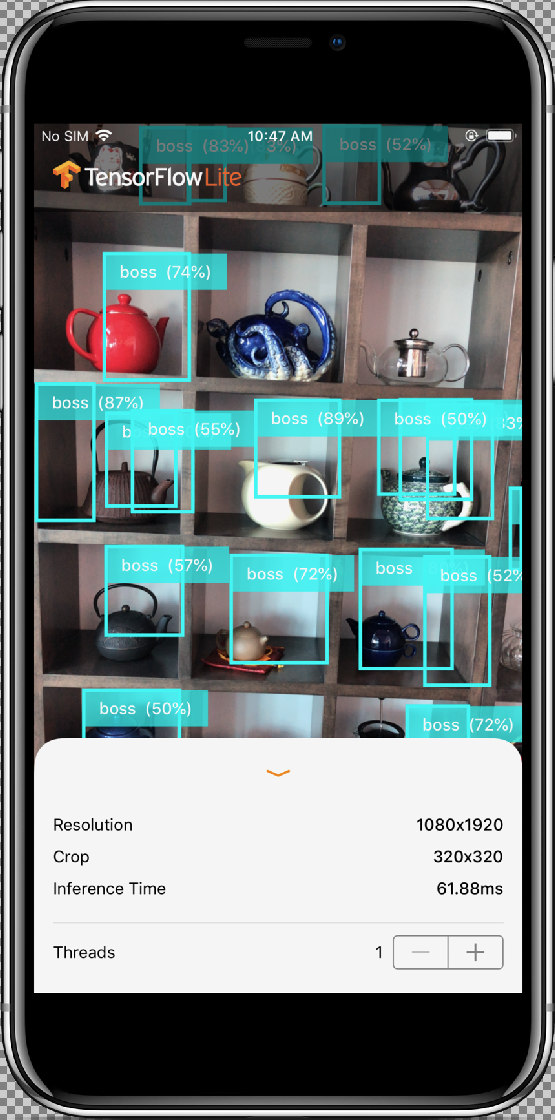
La classe InferenceViewController.swift è responsabile della schermata di seguito, in cui l'argomento principale è la parte evidenziata.
- Risoluzione: mostra la risoluzione del fotogramma corrente (immagine da sessione video).
- Ritaglia: mostra le dimensioni di ritaglio del frame corrente.
- InferenceTime: mostra il tempo impiegato dal modello per rilevare l'oggetto.
- Thread: viene visualizzato il numero di thread in esecuzione.
L'utente può aumentare o diminuire questo conteggio toccando il segno
+o-del passaggio. Il numero di thread corrente utilizzato dall'interprete di TensorFlow Lite.
La classe ViewController.swift contiene l'istanza di CameraFeedManager,
che gestisce le funzionalità relative alla videocamera e
ModelDataHandler. ModelDataHandler gestisce Model (modello addestrato) e ottiene l'output del frame immagine della sessione video.
private lazy var cameraFeedManager = CameraFeedManager(previewView: previewView)
private var modelDataHandler: ModelDataHandler? =
ModelDataHandler(modelFileInfo: MobileNetSSD.modelInfo, labelsFileInfo: MobileNetSSD.labelsInfo)
Avvia la sessione della videocamera chiamando:
cameraFeedManager.checkCameraConfigurationAndStartSession()
Quando modifichi il numero di thread, questa classe reinizializza il modello con il nuovo conteggio dei thread nella funzione didChangeThreadCount.
CameraFeedManager invierà ImageFrame come CVPixelBuffer a ViewController, che sarà inviato al modello per la previsione.
Questo metodo esegue la videocamera in diretta pixelBuffer tramite TensorFlow per ottenere il risultato.
@objc
func runModel(onPixelBuffer pixelBuffer: CVPixelBuffer) {
Esegui il pixelBuffer della videocamera in diretta tramite tensorFlow per ottenere il risultato:
result = self.modelDataHandler?.runModel(onFrame: pixelBuffer)
...
let displayResult = result
let width = CVPixelBufferGetWidth(pixelBuffer)
let height = CVPixelBufferGetHeight(pixelBuffer)
DispatchQueue.main.async {
Mostra i risultati trasferendoli a InferenceViewController:
self.inferenceViewController?.resolution = CGSize(width: width, height: height) self.inferenceViewController?.inferenceTime = inferenceTime
Disegna i riquadri di delimitazione e visualizza i nomi dei corsi e i punteggi di affidabilità:
self.drawAfterPerformingCalculations(onInferences: displayResult.inferences, withImageSize: CGSize(width: CGFloat(width), height: CGFloat(height)))
}
}
Passaggio successivo
Hai completato una procedura dettagliata di un'app per il rilevamento e l'annotazione di oggetti iOS utilizzando un modello Edge. Hai utilizzato un modello Edge Tensorflow Lite addestrato per testare un'app di rilevamento di oggetti prima di apportarvi modifiche e ottenere annotazioni di esempio. Hai quindi esaminato il codice specifico di TensorFlow Lite per comprenderne la funzionalità.
Le seguenti risorse possono aiutarti a continuare a conoscere i modelli TensorFlow e AutoML Vision Edge:
- Scopri di più su TFLite nella documentazione ufficiale e nel repository di codice.
- Prova altri modelli compatibili con TFLite, tra cui un rilevatore vocale di hot-word e una versione della risposta rapida sul dispositivo.
- Scopri di più su TensorFlow in generale nella documentazione di introduzione di TensorFlow.