Après avoir créé (entraîné) un modèle et l'avoir déployé, vous pouvez effectuer des requêtes de prédiction en ligne (ou synchrones).
Exemple de prédiction en ligne (individuelle)
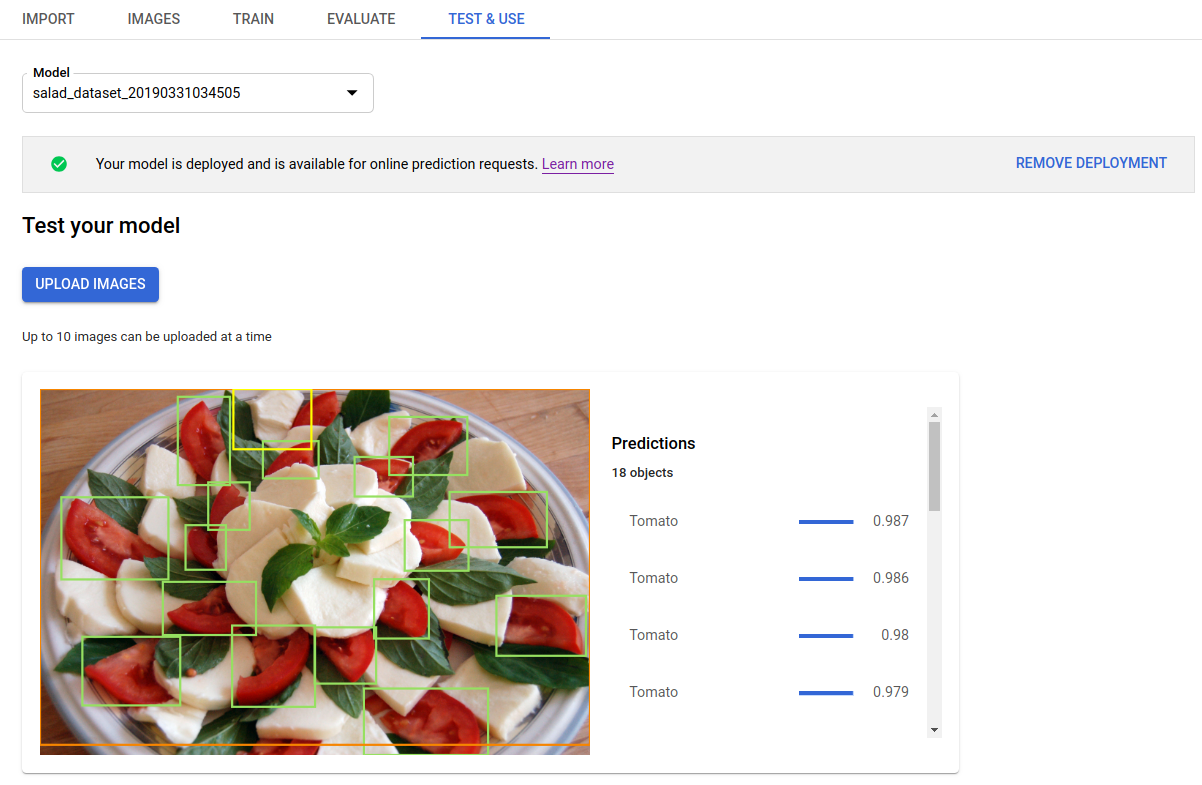
Après avoir déployé le modèle que vous avez entraîné, vous pouvez lui demander de faire une prédiction pour une image à l'aide de la méthode predict ou utiliser l'UI pour obtenir des annotations de prédiction. La méthode predict applique des étiquettes aux cadres de délimitation des objets dans votre image.
Des frais vous sont facturés pour le déploiement du modèle. Après avoir effectué des prédictions avec le modèle entraîné, vous pouvez annuler le déploiement de votre modèle si vous ne souhaitez plus payer de frais d'utilisation pour son hébergement.
UI Web
Ouvrez l'UI de AutoML Vision Object Detection et cliquez sur l'onglet Modèles (avec l'icône représentant une ampoule) dans la barre de navigation de gauche pour afficher les modèles disponibles.
Pour afficher les modèles d'un autre projet, sélectionnez le projet dans la liste déroulante située en haut à droite de la barre de titre.
Cliquez sur la ligne du modèle que vous souhaitez utiliser pour étiqueter vos images.
Si votre modèle n'est pas encore déployé, déployez-le maintenant en sélectionnant Déployer le modèle.
Pour pouvoir utiliser les prédictions en ligne, le modèle doit être déployé. Le déploiement de votre modèle entraîne des frais. Pour plus d'informations, reportez-vous à la page des tarifs.
Cliquez sur l'onglet Test et utilisation situé juste en dessous de la barre de titre.
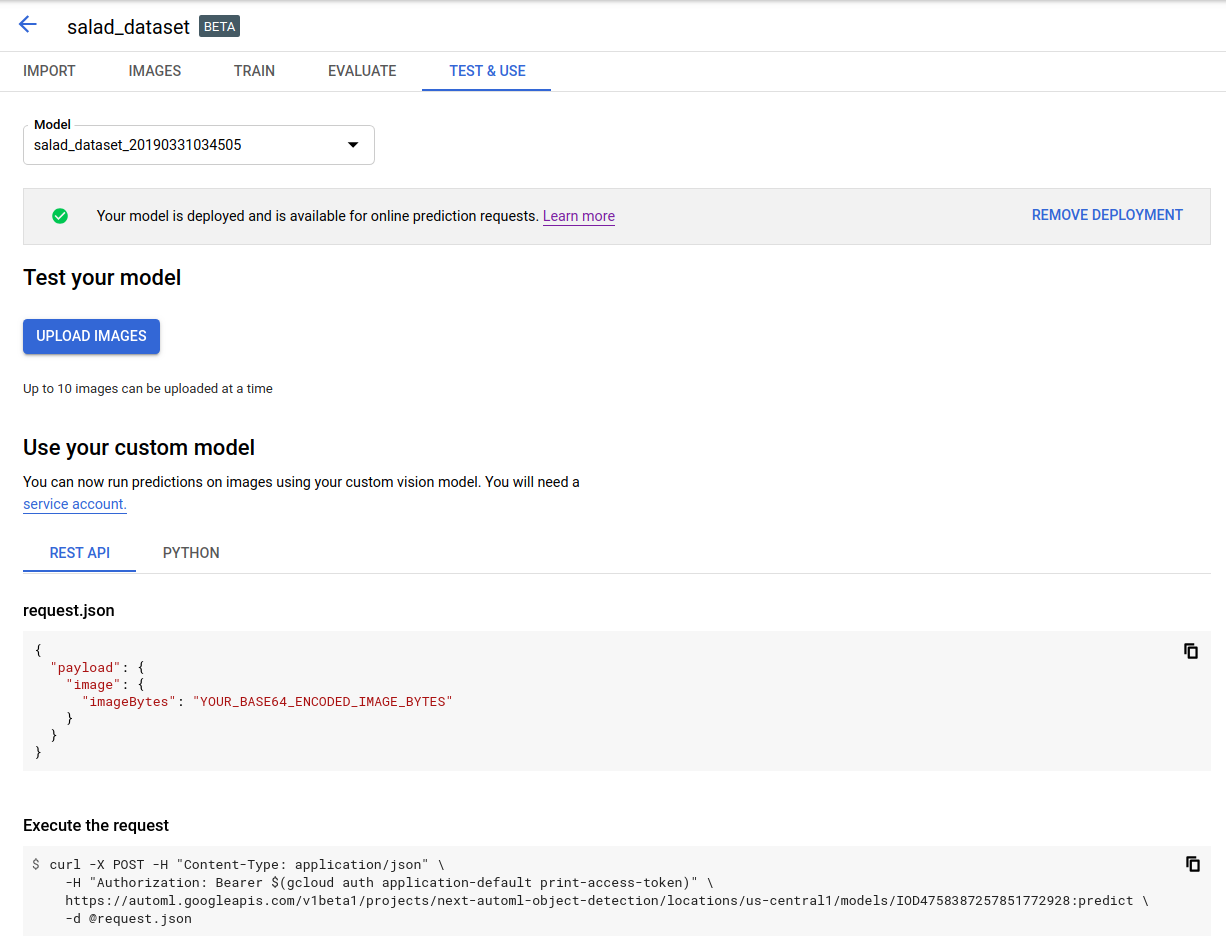
Cliquez sur Importer des images pour importer les images que vous souhaitez labelliser.
REST
Pour tester la prédiction, vous devez d'abord déployer votre modèle hébergé dans le cloud.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- project-id : ID de votre projet GCP.
- model-id : ID de votre modèle, issu de la réponse obtenue lors de sa création. L'ID est le dernier élément du nom du modèle.
Exemple :
- Nom du modèle :
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID du modèle :
IOD4412217016962778756
- Nom du modèle :
- base64-encoded-image : représentation en base64 (chaîne ASCII) de vos données d'image binaires. Cette chaîne doit ressembler à la chaîne suivante :
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==Pour plus d'informations, consultez la section Encodage Base64.
Remarques sur les champs :
scoreThreshold: une valeur comprise entre 0 et 1. Pour être affichées, les valeurs associées devront être supérieures ou égales à ces seuils de score. La valeur par défaut est 0,5.maxBoundingBoxCount: nombre maximal (limite supérieure) de cadres de délimitation à afficher dans une réponse. La valeur par défaut est 100 et la valeur maximale est 500. Cette valeur est soumise à des contraintes de ressources et peut être limitée par le serveur.
Méthode HTTP et URL :
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict
Corps JSON de la requête :
{
"payload": {
"image": {
"imageBytes": "BASE64_ENCODED_IMAGE"
}
},
"params": {
"scoreThreshold": "0.5",
"maxBoundingBoxCount": "100"
}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict" | Select-Object -Expand Content
Le résultat est renvoyé au format JSON. Les prédictions de votre modèle de détection d'objets AutoML Vision sont contenues dans le champ payload :
boundingBoxd'un objet est spécifié par des sommets diagonalement opposés.displayNamecorrespond à l'étiquette de l'objet prédit par le modèle de détection d'objets AutoML Vision.scorereprésente le niveau de confiance que l'étiquette spécifiée applique à l'image. Ce score varie de0(aucune confiance) à1(confiance élevée).
{
"payload": [
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.034553755,
"y": 0.015524037
},
{
"x": 0.941527,
"y": 0.9912563
}
]
},
"score": 0.9997793
},
"displayName": "Salad"
},
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.11737197,
"y": 0.7098793
},
{
"x": 0.510878,
"y": 0.87987
}
]
},
"score": 0.63219965
},
"displayName": "Tomato"
}
]
}
Go
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Java
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Node.js
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Python
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Langages supplémentaires
C# : Veuillez suivre les Instructions de configuration pour C# sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur la détection d'objets AutoML Vision pour .NET.
PHP : Veuillez suivre les Instructions de configuration pour PHP sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur la détection d'objets AutoML Vision pour PHP.
Ruby : Veuillez suivre les Instructions de configuration de Ruby sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur la détection d'objets AutoML Vision pour Ruby.