Implantação inicial do modelo
A implantação de um modelo de detecção de objetos gera cobranças. Para mais informações, consulte a página de preços.
Depois de criar (treinar) um modelo, é preciso implantá-lo antes de fazer chamadas on-line (ou síncronas) para ele.
Agora também é possível atualizar a implantação do modelo se precisar de mais capacidade de previsão on-line.
IU da Web
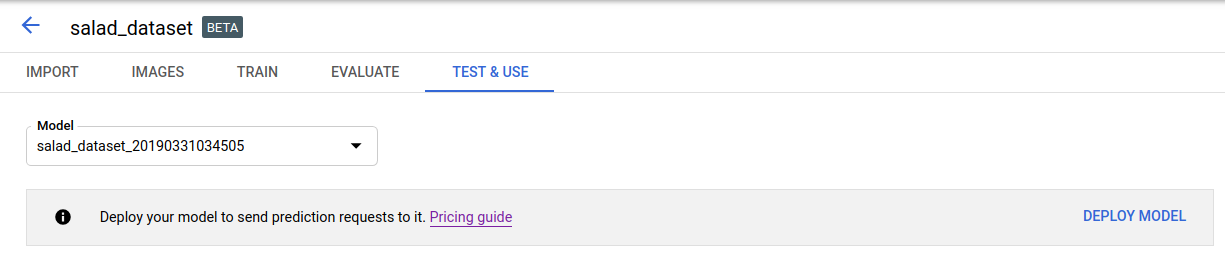
Abra a IU do AutoML Vision Object Detection e selecione a guia Modelos na barra de navegação à esquerda para exibir os modelos disponíveis.
Para ver os modelos de outro projeto, selecione o projeto na lista suspensa na parte superior direita da barra de título.
- Selecione a linha do modelo que você quer usar para rotular as imagens.
- Selecione a guia Testar e usar logo abaixo da barra de título.
-
Selecione Implantar modelo no banner abaixo do nome do modelo para abrir a janela de opções de implantação.
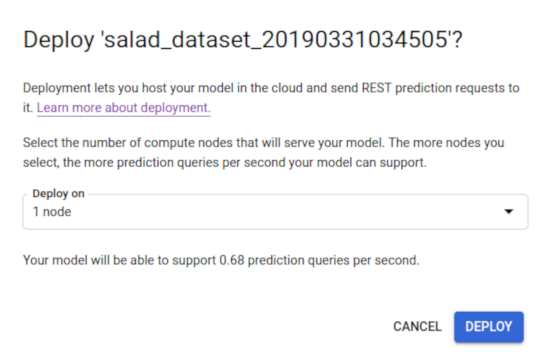
Nessa janela, é possível selecionar o número de nós a serem implantados e visualizar as consultas de previsão por segundo (QPS, na sigla em inglês) disponíveis.
-
Selecione Implantar para iniciar a implantação do modelo.
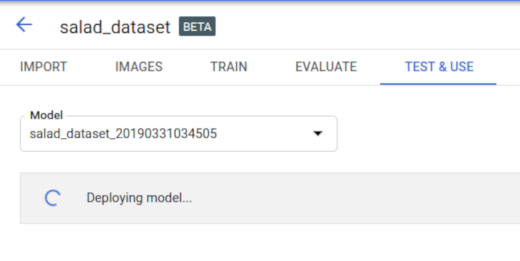
Você receberá um e-mail quando a implantação do modelo for concluída.

REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- project-id: o ID do projeto do GCP.
- model-id: o ID do seu modelo, a partir da
resposta de quando você o criou. Ele é o último elemento no nome do modelo.
Por exemplo:
- Nome do modelo:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID do modelo:
IOD4412217016962778756
- Nome do modelo:
Considerações de campo:
nodeCount: o número de nós para implantar o modelo. O valor precisa estar entre 1 e 100, inclusive nas duas extremidades. Um nó é uma abstração de um recurso de máquina que pode processar consultas de previsão por segundo (QPS) on-line, conforme fornecido noqps_per_nodedo modelo.
Método HTTP e URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
Corpo JSON da solicitação:
{
"imageObjectDetectionModelDeploymentMetadata": {
"nodeCount": 2
}
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Será exibido um código semelhante a este. É possível usar o ID da operação para saber o status da tarefa. Veja um exemplo em Como trabalhar com operações de longa duração.
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
É possível ver o status de uma operação com o seguinte método HTTP e URL:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID
O status de uma operação concluída será semelhante ao seguinte:
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-06-21T16:47:21.704674Z",
"updateTime": "2019-06-21T17:01:00.802505Z",
"deployModelDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Java
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Node.js
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Outras linguagens
C#: Siga as Instruções de configuração do C# na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Vision Object Detection para .NET.
PHP: Siga as Instruções de configuração do PHP na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Vision Object Detection para PHP.
Ruby Siga estas instruções:Instruções de configuração do Ruby na página das bibliotecas de cliente e, em seguida, visite oDocumentação de referência do AutoML Vision Object Detection para Ruby.
Atualizar o número do nó de um modelo
Depois de ter um modelo implantado treinado, atualize o número de nós em que o modelo é implantado para responder à sua quantidade específica de tráfego. Por exemplo, se você tiver uma quantidade maior de consultas por segundo (QPS) do que o esperado.
É possível alterar este número de nós sem ter que desfazer a implantação do modelo primeiro. A atualização da implantação alterará o número de nós sem interromper o tráfego de previsão exibido.
IU da Web
Em AutoML Vision Object Detection UI e selecionando a guia Modelos (com o ícone de lâmpada) na barra de navegação esquerda, você verá os modelos disponíveis.
Para ver os modelos de outro projeto, selecione o projeto na lista suspensa na parte superior direita da barra de título.
- Selecione o modelo treinado implantado.
- Selecione a guia Testar e usar logo abaixo da barra de título.
-
Uma mensagem é exibida em uma caixa na parte superior da página que diz "Seu modelo foi implantado e está disponível para solicitações de previsão on-line". Selecione a opção Atualizar implantação na parte lateral deste texto.
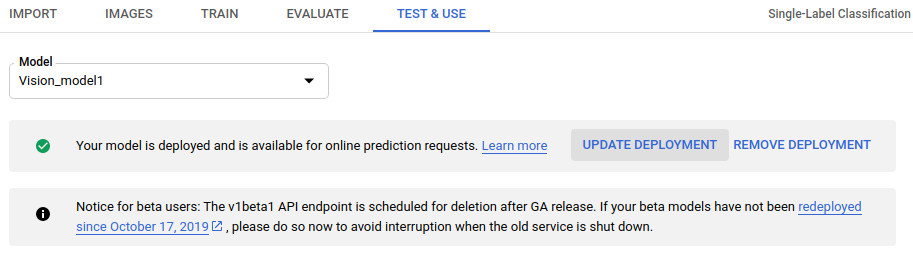
- Na janela Atualizar implantação que é aberta, selecione o novo número de nó para implantar o modelo na lista. Números de nós exibem as consultas de previsão estimadas por segundo (QPS, na sigla em inglês).
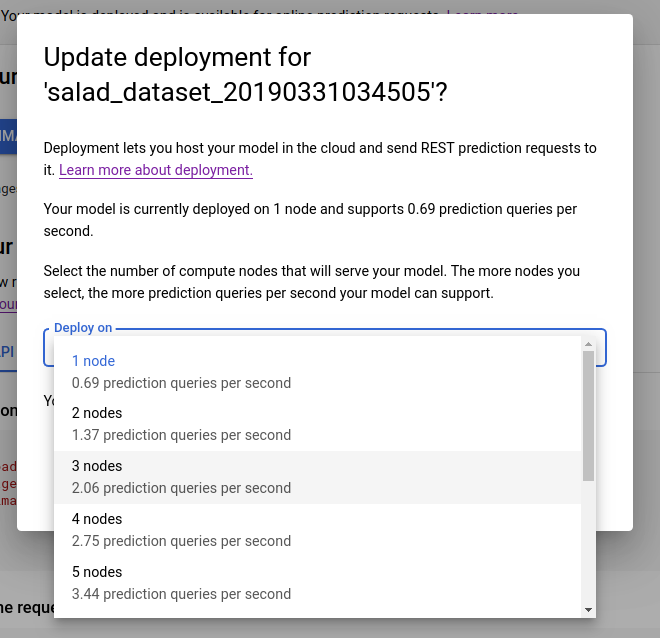
Depois de selecionar um novo número de nó na lista, selecione Atualizar implantação para atualizar o número do nó no qual o modelo é implantado.
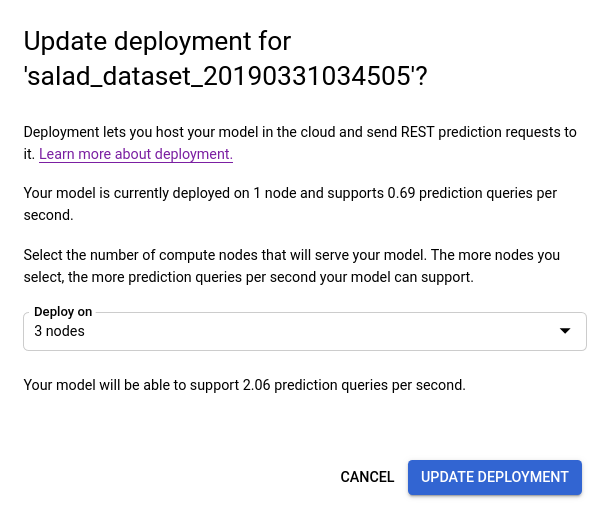
- Você retornará à janela Testar e usar e verá a caixa de texto exibindo "Implantando modelo...".
Depois que seu modelo for implantado com sucesso no novo número de nó, você receberá um e-mail no endereço associado ao projeto.
REST
O mesmo método usado inicialmente para implantar um modelo é usado para alterar o número do nó do modelo implantado.Antes de usar os dados da solicitação abaixo, faça estas substituições:
- project-id: o ID do projeto do GCP.
- model-id: o ID do seu modelo, a partir da
resposta de quando você o criou. Ele é o último elemento no nome do modelo.
Por exemplo:
- Nome do modelo:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID do modelo:
IOD4412217016962778756
- Nome do modelo:
Considerações de campo:
nodeCount: o número de nós para implantar o modelo. O valor precisa estar entre 1 e 100, inclusive nas duas extremidades. Um nó é uma abstração de um recurso de máquina que pode processar consultas de previsão por segundo (QPS) on-line, conforme fornecido noqps_per_nodedo modelo.
Método HTTP e URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy
Corpo JSON da solicitação:
{
"imageObjectDetectionModelDeploymentMetadata": {
"nodeCount": 2
}
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:deploy" | Select-Object -Expand Content
Será exibido um código semelhante a este. É possível usar o ID da operação para saber o status da tarefa. Veja um exemplo em Como trabalhar com operações de longa duração.
{
"name": "projects/PROJECT_ID/locations/us-central1/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-08-07T22:00:20.692109Z",
"updateTime": "2019-08-07T22:00:20.692109Z",
"deployModelDetails": {}
}
}
Go
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Java
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Node.js
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Python
Antes de testar esta amostra, siga as instruções de configuração dessa linguagem na página Bibliotecas de cliente.
Outras linguagens
C#: Siga as Instruções de configuração do C# na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Vision Object Detection para .NET.
PHP: Siga as Instruções de configuração do PHP na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Vision Object Detection para PHP.
Ruby: Siga as Instruções de configuração do Ruby na página das bibliotecas de cliente e acesse a Documentação de referência do AutoML Vision Object Detection para Ruby.