Nach dem Training eines Modells verwendet AutoML Vision Elemente aus dem TEST-Dataset, um die Qualität und Genauigkeit des neuen Modells zu bewerten.
Bewertungsübersicht
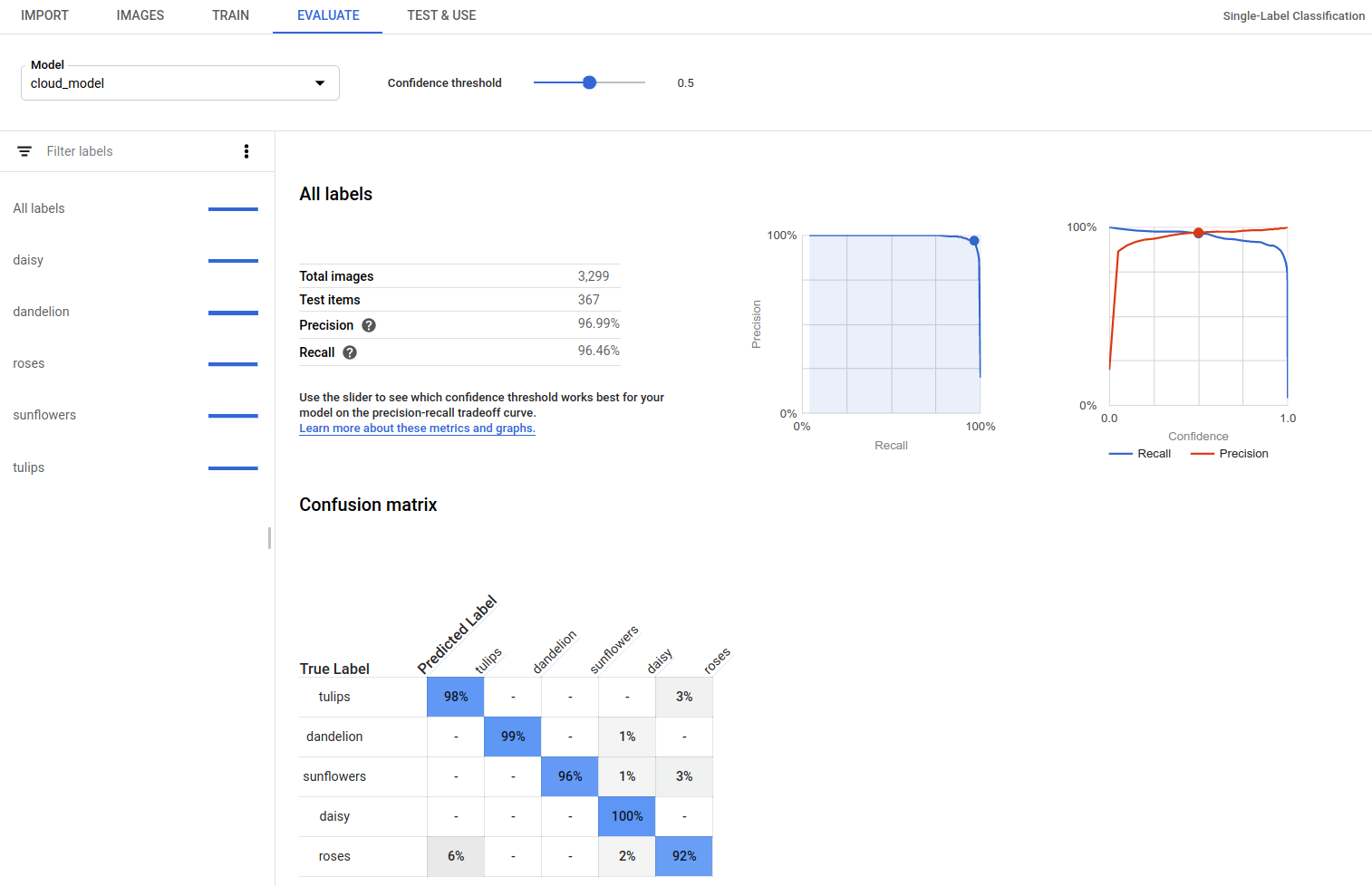
AutoML Vision bietet eine ganze Reihe von Bewertungsmesswerten, die angeben, wie gut das Modell insgesamt funktioniert. Auch für jedes Kategorielabel gibt es Bewertungsmesswerte. Sie geben an, wie gut das Modell für das jeweilige Label funktioniert.
AuPRC: Die Fläche unter der Precision/Recall, die auch als "durchschnittliche Genauigkeit" bezeichnet wird. Im Allgemeinen zwischen 0,5 und 1,0. Höhere Werte deuten auf genauere Modelle hin.
Die Konfidenzwertkurven zeigen, wie sich unterschiedliche Konfidenzwerte auf Precision, Recall sowie die Richtig- und Falsch-Positiv-Raten auswirken würden. Siehe auch die Beziehung von Precison und Recall.
Wahrheitsmatrix (auch Konfusionsmatrix genannt): Nur für Modelle mit einem Label pro Bild vorhanden. Stellt in Prozent dar, wie oft jedes Label während der Bewertung für jedes Label im Training-Dataset vorhergesagt wurde.
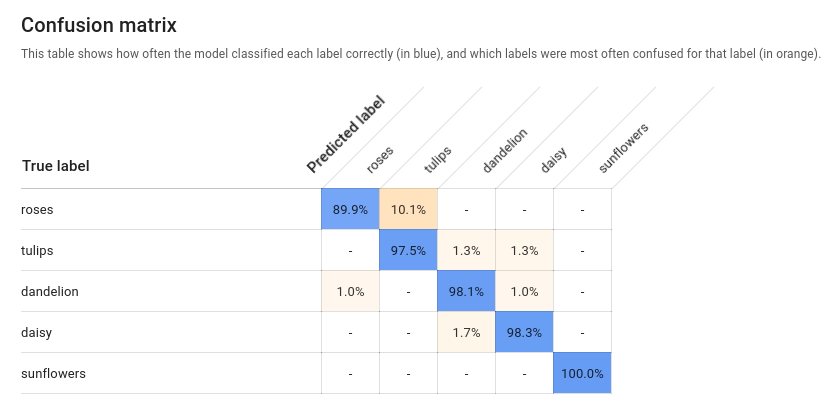
Idealerweise würde das
one-Label nur Bildern zugewiesen werden, die alsone-Label usw. klassifiziert wurden, sodass eine perfekte Matrix so aussähe:100 0 0 0 0 100 0 0 0 0 100 0 0 0 0 100Wenn im obigen Beispiel ein Bild als
oneklassifiziert wurde, das Modell jedochtwovorhergesagt hat, würde die erste Zeile stattdessen so aussehen:99 1 0 0Weitere Informationen erhalten Sie, wenn Sie nach Wahrheitsmatrix maschinelles Lernen suchen.
AutoML Vision erstellt die Wahrheitsmatrix für bis zu zehn Labels. Wenn Sie mehr als zehn Labels haben, enthält die Matrix die zehn Labels mit der höchsten Konfusion (falsche Vorhersagen).
Verwenden Sie diese Daten, um die Bereitschaft Ihres Modells zu bewerten. Hohe Konfusion, niedrige AUC-Werte oder niedrige Genauigkeits- und Trefferquotenwerte können darauf hinweisen, dass Ihr Modell zusätzliche Trainingsdaten benötigt. Ein sehr hoher AUC-Wert und eine perfekte Precision und Recallquote zeigen unter Umständen an, dass die Daten zu einfach sind und sich unter Umständen nicht gut verallgemeinern lassen.
Modellbewertungen auflisten
Nachdem Sie ein Modell trainiert haben, können Sie eine Liste von Bewertungsmesswerten für dieses Modell anlegen.
Web-UI
Öffnen Sie die AutoML Vision-UI und klicken Sie in der linken Navigationsleiste auf den Tab Modelle (mit dem Glühbirnensymbol), um die verfügbaren Modelle aufzurufen.
Wählen Sie zum Anzeigen der Modelle für ein anderes Projekt das Projekt in der Dropdown-Liste oben rechts in der Titelleiste aus.
Klicken Sie auf die Zeile für das Modell, das Sie bewerten möchten.
Klicken Sie ggf. unterhalb der Titelleiste auf den Tab Bewerten.
Sobald das Training für das Modell abgeschlossen ist, werden die entsprechenden Bewertungsmesswerte in AutoML Vision angezeigt.
REST
Ersetzen Sie dabei folgende Werte für die Anfragedaten:
- project-id: die ID Ihres GCP-Projekts.
- model-id: die ID Ihres Modells aus der Antwort beim Erstellen des Modells. Sie ist das letzte Element des Modellnamens.
Beispiel:
- Modellname:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - Modell-ID:
IOD4412217016962778756
- Modellname:
- model-evaluation-id: der ID-Wert der Modellbewertung. Sie können Modellbewertungs-IDs aus dem
list-Modellbewertungsvorgang abrufen.
HTTP-Methode und URL:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID
Senden Sie die Anfrage mithilfe einer der folgenden Optionen:
curl
Führen Sie folgenden Befehl aus:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID"
PowerShell
Führen Sie folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID" | Select-Object -Expand Content
Sie sollten eine JSON-Antwort ähnlich der folgenden erhalten. Spezifische Felder für die Schlüsselobjekterkennung sind fett formatiert. Der Übersichtlichkeit halber wird eine verkürzte Version von classificationEvaluationMetrics-Einträgen angezeigt:
Go
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Java
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Node.js
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Python
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Weitere Sprachen
C#: Folgen Sie der Anleitung zur Einrichtung von C# auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Vision-Referenzdokumentation für .NET auf.
PHP: Folgen Sie der Anleitung zur Einrichtung von PHP auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Vision-Referenzdokumentation für PHP auf.
Ruby: Folgen Sie der Anleitung zur Einrichtung von Ruby auf der Seite der Clientbibliotheken und rufen Sie dann die AutoML Vision-Referenzdokumentation für Ruby auf.
Werte der Modellbewertung abrufen
Sie können auch eine spezifische Modellbewertung für ein Label (displayName) anhand der Bewertungs-ID abrufen. Führen Sie die Funktion zum Auflisten von Modellbewertungen unter Modellbewertungen auflisten aus, um Ihre Modellbewertungs-ID abzurufen.
Web-UI
Öffnen Sie die Vision Dashboard und klicken Sie in der linken Navigationsleiste auf das Glühbirnensymbol, um die verfügbaren Modelle aufzurufen.
Wählen Sie zum Anzeigen der Modelle für ein anderes Projekt das Projekt in der Dropdown-Liste oben rechts in der Titelleiste aus.
Klicken Sie auf die Zeile für das Modell, das Sie bewerten möchten.
Klicken Sie ggf. unterhalb der Titelleiste auf den Tab Bewerten.
Sobald das Training für das Modell abgeschlossen ist, werden die entsprechenden Bewertungsmesswerte in AutoML Vision angezeigt.
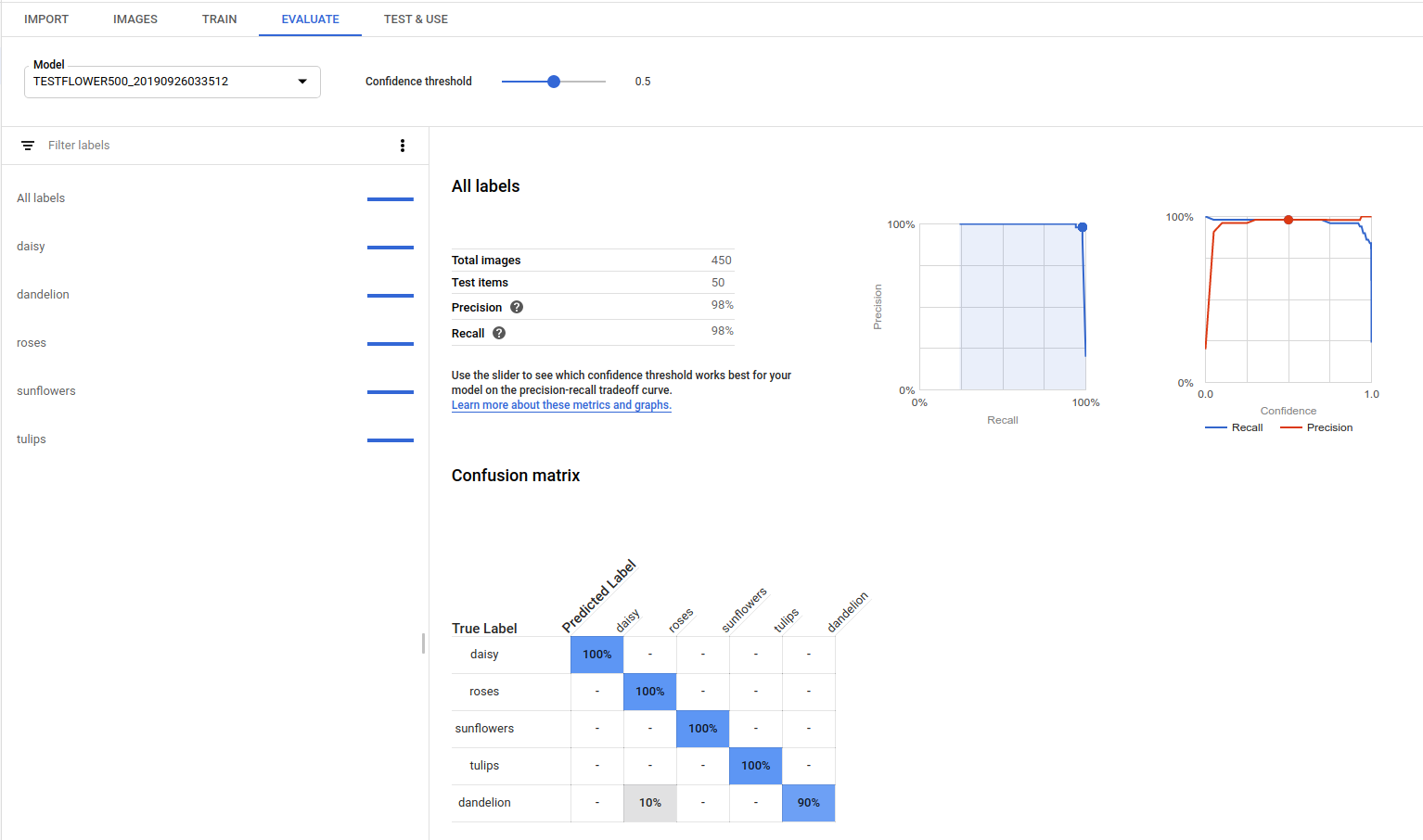
Wählen Sie unten auf der Seite in der Liste der Labels den Label-Namen aus, um Messwerte für ein bestimmtes Label anzeigen zu lassen.
REST
Wenn Sie nur die Bewertungsmesswerte für ein bestimmtes Label erhalten möchten, fügen Sie /{MODEL_EVALUATION_ID} in die Anfrage oben aus der Antwort ein.
Beispiel: Sie finden die Modellbewertungs-ID für das Label rose (displayName) im Bewertungsnamen, der vom list-Vorgang zurückgegeben wird:
"name": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/858136867710915695"
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- project-id: die ID Ihres GCP-Projekts.
- model-id: die ID Ihres Modells aus der Antwort beim Erstellen des Modells. Sie ist das letzte Element des Modellnamens.
Beispiel:
- Modellname:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - Modell-ID:
IOD4412217016962778756
- Modellname:
- model-evaluation-id: der ID-Wert der Modellbewertung. Sie können Modellbewertungs-IDs aus dem
list-Modellbewertungsvorgang abrufen.
HTTP-Methode und URL:
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID
Senden Sie die Anfrage mithilfe einer der folgenden Optionen:
curl
Führen Sie folgenden Befehl aus:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID"
PowerShell
Führen Sie folgenden Befehl aus:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID" | Select-Object -Expand Content
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
Go
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Java
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Node.js
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Python
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
Richtig positive (true positive, TP), falsch negative (false negative, FN) und falsch positive (false positive, FP) Ergebnisse (nur UI)
In der UI können Sie sich bestimmte Beispiele für die Modellleistung ansehen, nämlich: richtig positive, falsch negative und falsch positive Instanzen aus den Trainings- und Validierungs-Datasets.
Web-UI
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für diese Sprache auf der Seite Clientbibliotheken.
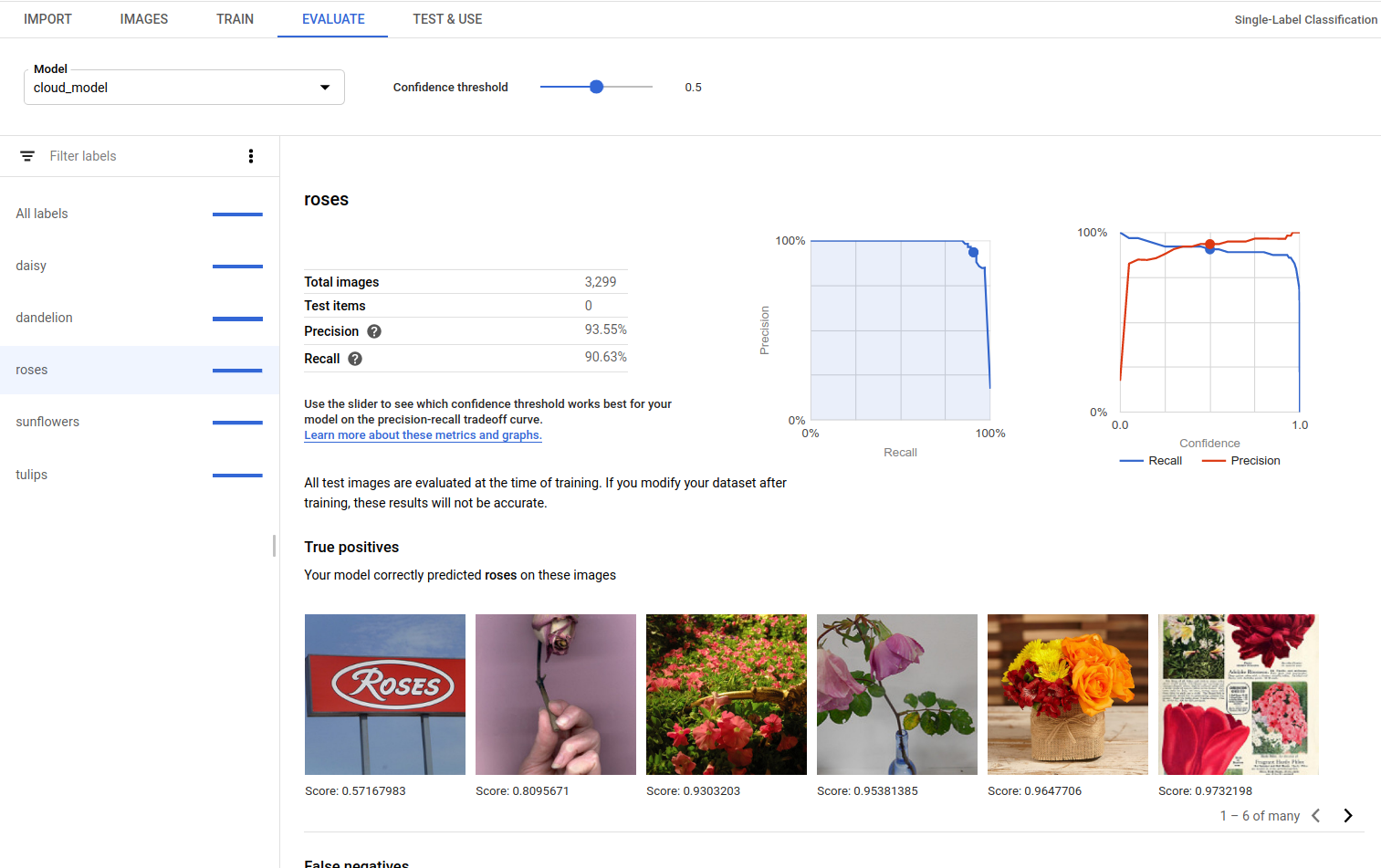
Sie können auf die Ansicht für richtig positive, falsch negative und falsch positive Instanzen in der UI zugreifen. Dazu rufen Sie den Tab Bewerten auf und wählen ein bestimmtes Label aus.
Auf Grundlage der Trends in diesen Vorhersagen können Sie Ihr Trainings-Dataset ändern, um die Modellleistung zu verbessern.
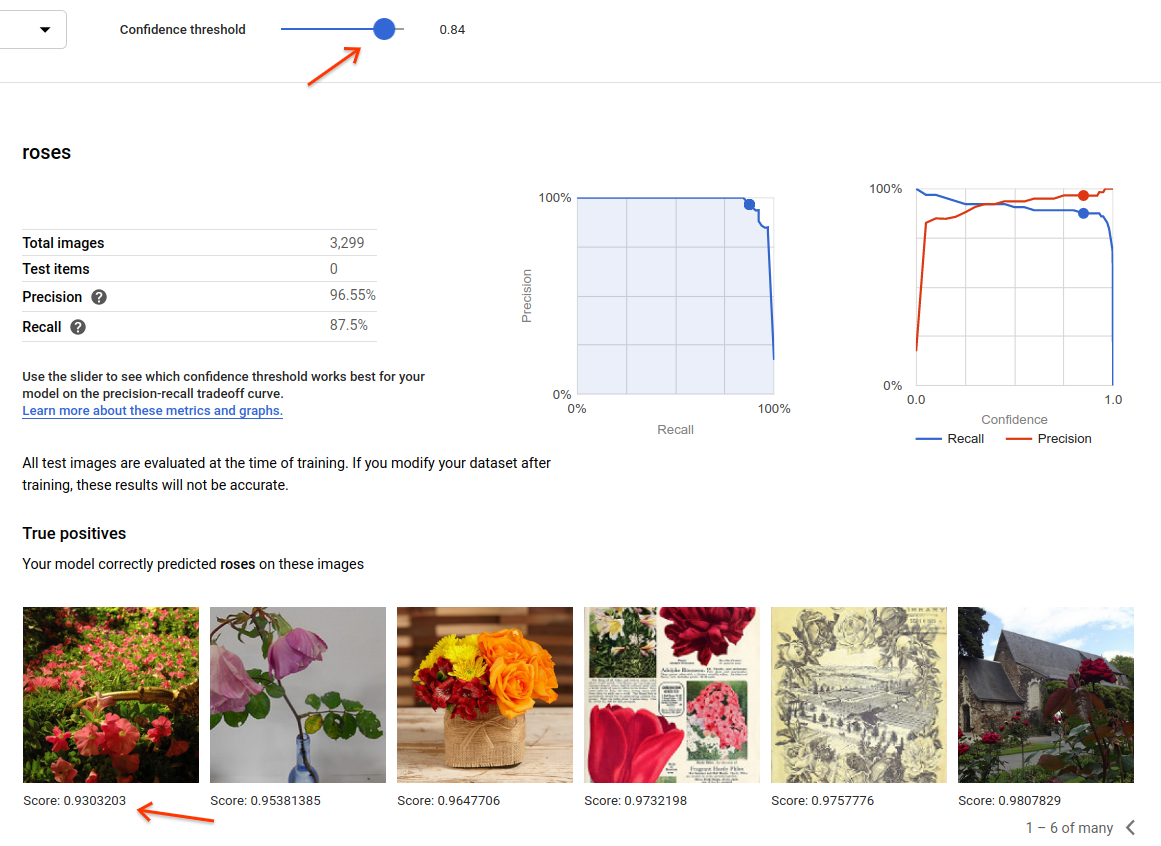
Richtig positive Bilder sind Beispielbilder, die für das trainierte Modell bereitgestellt wurden und die das Modell korrekt annotiert hat:

Falsch negative Bilder wurden dem trainierten Modell ebenfalls bereitgestellt, aber das Modell konnte die Bilder für das angegebene Label nicht richtig annotieren:
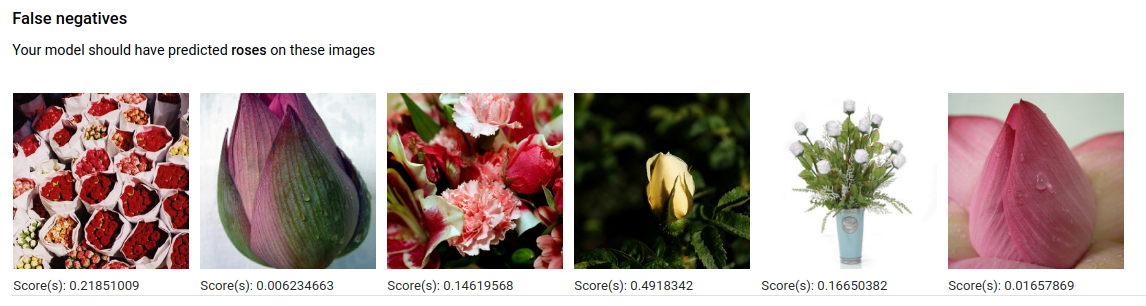
Falsch positive Bilder sind solche Bilder, die dem trainierten Modell bereitgestellt und mit dem angegebenen Label annotiert wurden, aber nicht hätten annotiert werden sollen:

Das Modell wählt interessante Grenzfälle aus, sodass Sie die Möglichkeit haben, Ihre Definitionen und Labels zu verfeinern, damit das Modell Ihre Labelinterpretationen besser nachvollziehen kann. Mit einer strikteren Definition könnte das Modell beispielsweise besser verstehen, ob Sie ein abstraktes Gemälde einer Rose als Rose betrachten oder nicht.
Bei wiederholten Label-, Trainings- und Bewertungsschleifen zeigt Ihr Modell weitere Unklarheiten dieser Art in Ihren Daten an.
Sie können den Punktzahl-Schwellenwert in dieser Ansicht der Benutzeroberfläche auch anpassen. Die angezeigten richtig positiven, falsch negativen und falsch positiven Bilder entsprechen der Schwellenwertänderung:
Modell durchlaufen
Wenn Sie mit dem Qualitätsniveau nicht zufrieden sind, können Sie zu den vorherigen Schritten zurückkehren, um die Qualität zu verbessern:
- Mit AutoML Vision können Sie Bilder nach dem Wahrheitsgehalt des Modells sortieren, d. h. nach tatsächlichem und vorhergesagtem Label. Sehen Sie sich diese Bilder an und achten Sie darauf, dass sie mit den richtigen Labels versehen sind.
- Erwägen Sie, allen Labels mit geringer Qualität weitere Bilder hinzuzufügen.
- Möglicherweise müssen Sie verschiedene Arten von Bildern einfügen (z. B. mit größerem Winkel, höherer oder geringerer Auflösung, unterschiedlichen Blickpunkten).
- Entfernen Sie Labels gegebenenfalls vollständig, wenn Sie nicht genügend Trainingsbilder haben.
- Vergessen Sie nicht, dass Maschinen Labelnamen nicht lesen können. Für Maschinen stellen sie lediglich eine zufällige Aneinanderreihung von Buchstaben dar. Wenn Sie ein Label mit der Aufschrift "Tür" und ein anderes mit der Aufschrift "Tür_mit_Klinke" haben, kann die Maschine den feinen Unterschied nur erkennen, wenn Sie ihr entsprechende Bilder bieten.
- Erweitern Sie Ihre Daten um mehr echt positive und negative Beispiele. Besonders wichtige Beispiele sind jene, die nahe an der Entscheidungsgrenze liegen, also solche, die wahrscheinlich zu Fehlern führen, aber trotzdem das richtige Label haben.
- Legen Sie Ihre eigenen Aufteilungen für TRAIN, TEST und VALIDATION fest. Das Tool weist Bilder nach dem Zufallsprinzip zu, aber Beinahe-Duplikate können im Dataset TRAIN und VALIDATION landen, was zu einer Überanpassung und dann zu einer schlechten Leistung des Datasets TEST führen kann.
Nachdem Sie Änderungen vorgenommen haben, trainieren und bewerten Sie ein neues Modell, bis Sie ein ausreichend hohes Qualitätsniveau erreicht haben.