Après avoir entraîné un modèle, AutoML Vision utilise des éléments de l'ensemble de TEST pour évaluer la qualité et la précision du nouveau modèle.
Présentation de l'évaluation
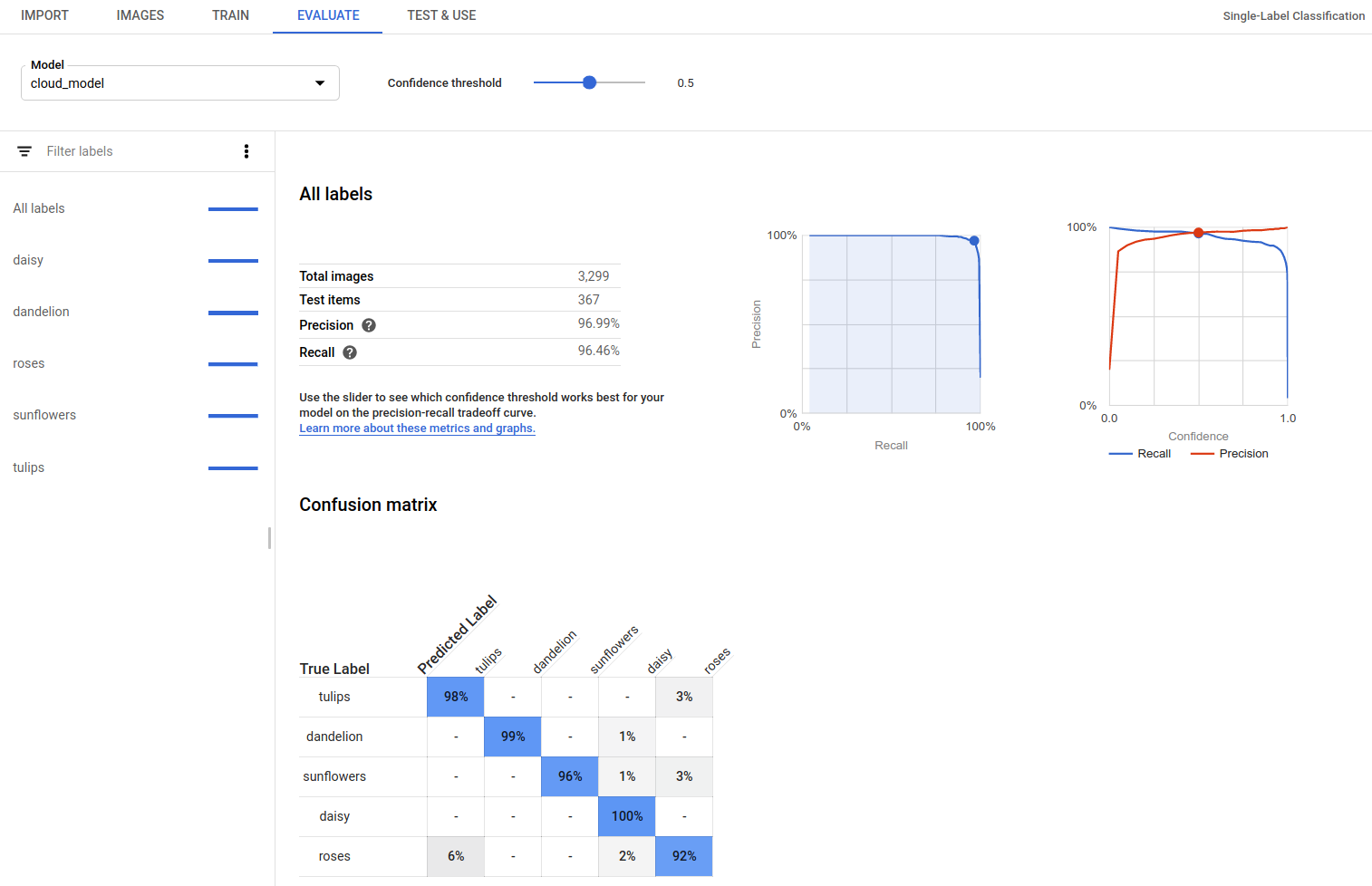
AutoML Vision fournit un ensemble de statistiques d'évaluation indiquant les performances globales du modèle, ainsi que pour chaque libellé de catégorie, de façon à évaluer les performances du modèle pour un libellé donné.
AuPRC : Area under Precision/Recall Curve (aire sous la courbe de précision/rappel), également appelée "précision moyenne". Cette valeur est généralement comprise entre 0,5 et 1. Plus les valeurs sont élevées, plus les modèles sont précis.
Les courbes de seuil de confiance montrent comment différents seuils de confiance peuvent influer sur la précision, le rappel, ainsi que les taux de vrais et faux positifs. Découvrez la relation qui existe entre la précision et le rappel.
Matrice de confusion : elle n'est disponible que pour les modèles avec un seul libellé par document. La matrice représente le pourcentage de fois où chaque libellé de l'ensemble d'entraînement a été prédit au cours de l'évaluation.
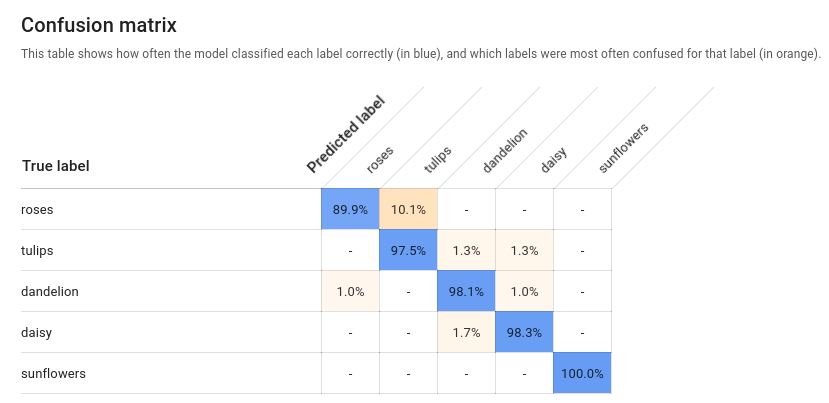
Il est préférable de n'attribuer le libellé
onequ'aux images classifiées dans la catégorieone, et ainsi de suite pour les autres libellés. La matrice idéale se présentera donc comme suit :100 0 0 0 0 100 0 0 0 0 100 0 0 0 0 100Dans l'exemple ci-dessus, si une image est classifiée avec le libellé
onealors que le modèle a prédit le libellétwo, la première ligne se présente comme suit :99 1 0 0Pour en savoir plus sur ce sujet, effectuez une recherche sur les termes matrice de confusion machine learning.
AutoML Vision crée la matrice de confusion pour 10 libellés au maximum. Si vous disposez d'un plus grand nombre de libellés, la matrice inclut les 10 libellés pour lesquels la confusion est la plus importante (prédictions incorrectes).
Évaluez l'état de préparation de votre modèle à l'aide de ces données. Une confusion importante, des scores AUC bas ou des valeurs de précision et de rappel faibles peuvent indiquer que votre modèle requiert des données d'entraînement supplémentaires ou que ses libellés sont incohérents. Si vous obtenez un score AUC très élevé et des valeurs de précision et de rappel parfaites, cela peut signifier que les données sont trop simples et risquent de ne pas être correctement généralisées.
Répertorier des évaluations de modèle
Une fois que vous avez entraîné un modèle, vous pouvez répertorier ses statistiques d'évaluation.
UI Web
Ouvrez l'interface AutoML Vision, puis cliquez sur l'onglet Modèles (icône représentant une ampoule) dans la barre de navigation de gauche pour afficher les modèles disponibles.
Pour afficher les modèles d'un autre projet, sélectionnez le projet dans la liste déroulante située en haut à droite de la barre de titre.
Cliquez sur la ligne du modèle que vous souhaitez évaluer.
Si nécessaire, cliquez sur l'onglet Évaluation situé juste en dessous de la barre de titre.
Si le modèle a été entraîné, AutoML Vision affiche ses statistiques d'évaluation.
REST
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- project-id : ID de votre projet GCP.
- model-id : ID de votre modèle, issu de la réponse obtenue lors de sa création. L'ID est le dernier élément du nom du modèle.
Exemple :
- Nom du modèle :
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID du modèle :
IOD4412217016962778756
- Nom du modèle :
- model-evaluation-id : ID d'évaluation du modèle. Vous pouvez obtenir les ID d'évaluation de modèle à partir de l'opération
listdes évaluations de modèle.
Méthode HTTP et URL :
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Exécutez la commande suivante :
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID"
PowerShell
Exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID" | Select-Object -Expand Content
Vous devriez recevoir une réponse JSON semblable à l'exemple ci-dessous. Les champs spécifiques de la détection des objets clés sont en gras et une version abrégée des entrées classificationEvaluationMetrics est affichée pour plus de clarté :
Go
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Java
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Node.js
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Python
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Langages supplémentaires
C# : Veuillez suivre les Instructions de configuration pour C# sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Vision pour C#.
PHP : Veuillez suivre les Instructions de configuration pour PHP sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Vision pour PHP.
Ruby : Veuillez suivre les Instructions de configuration pour Ruby sur la page des bibliothèques clientes, puis consultez la Documentation de référence sur AutoML Vision pour Ruby.
Obtenir les valeurs d'évaluation du modèle
Vous pouvez également obtenir une évaluation de modèle spécifique pour un libellé (displayName) en utilisant un ID d'évaluation. Pour obtenir l'ID d'évaluation de votre modèle, exécutez la fonction pour répertorier les évaluations de modèles indiquée dans la section Répertorier des évaluations de modèle.
UI Web
Accédez à Vision Dashboard, puis cliquez sur l'icône représentant une ampoule dans la barre de navigation de gauche pour afficher les modèles disponibles.
Pour afficher les modèles d'un autre projet, sélectionnez le projet dans la liste déroulante située en haut à droite de la barre de titre.
Cliquez sur la ligne du modèle que vous souhaitez évaluer.
Si nécessaire, cliquez sur l'onglet Évaluation situé juste en dessous de la barre de titre.
Si le modèle a été entraîné, AutoML Vision affiche ses statistiques d'évaluation.
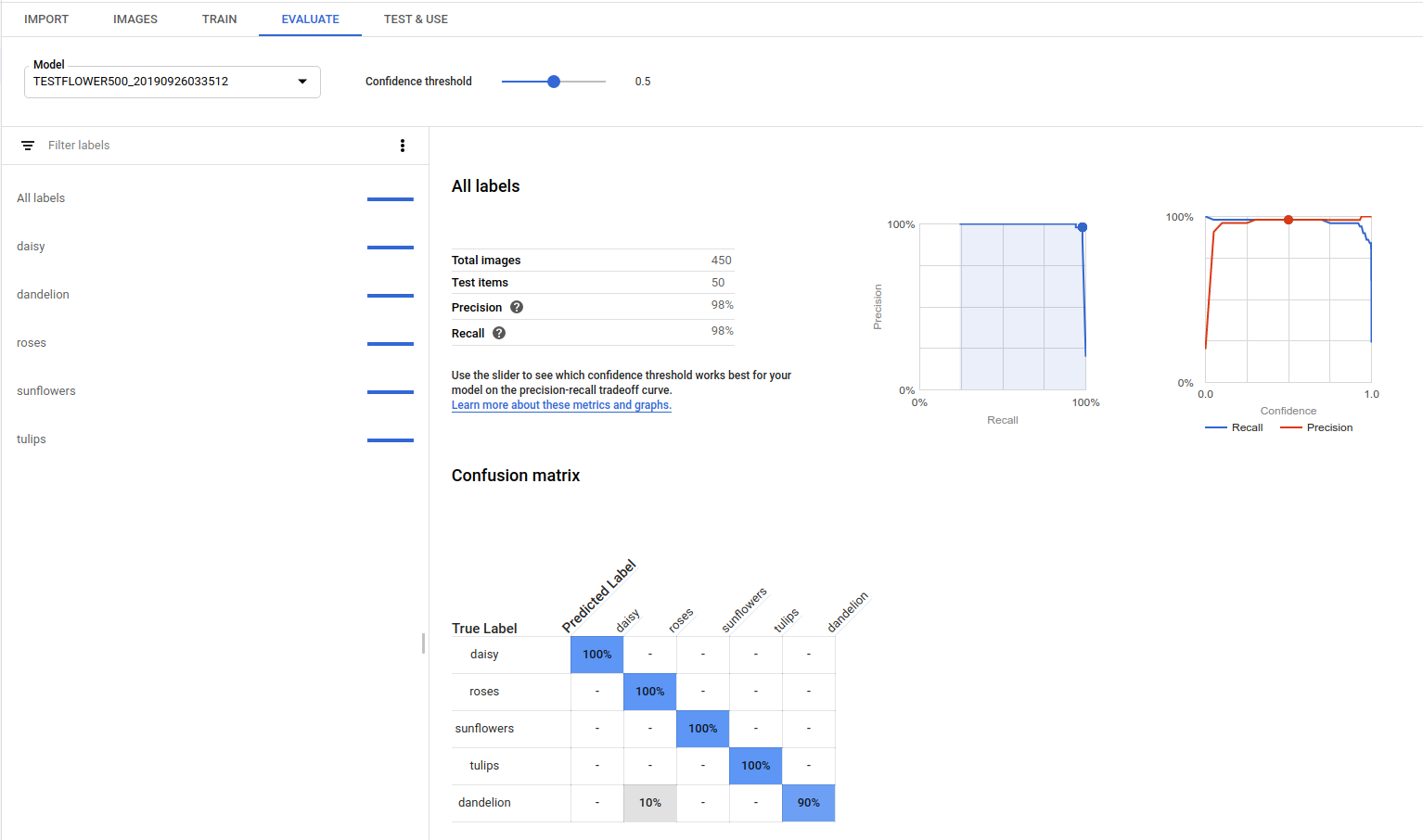
Pour afficher les statistiques correspondant à un libellé spécifique, sélectionnez le nom du libellé dans la liste située dans la partie inférieure de la page.
REST
Pour n'obtenir que les statistiques d'évaluation d'un libellé spécifique, ajoutez /{MODEL_EVALUATION_ID} à la requête ci-dessus, provenant d'une réponse à une opération.
Par exemple, vous pouvez trouver l'ID d'évaluation du modèle pour le libellé rose (displayName) dans le nom d'évaluation renvoyé par l'opération list :
"name": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/858136867710915695"
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- project-id : ID de votre projet GCP.
- model-id : ID de votre modèle, issu de la réponse obtenue lors de sa création. L'ID est le dernier élément du nom du modèle.
Exemple :
- Nom du modèle :
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID du modèle :
IOD4412217016962778756
- Nom du modèle :
- model-evaluation-id : ID d'évaluation du modèle. Vous pouvez obtenir les ID d'évaluation de modèle à partir de l'opération
listdes évaluations de modèle.
Méthode HTTP et URL :
GET https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Exécutez la commande suivante :
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID"
PowerShell
Exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID/modelEvaluations/MODEL_EVALUATION_ID" | Select-Object -Expand Content
Vous devriez recevoir une réponse JSON de ce type :
Go
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Java
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Node.js
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Python
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
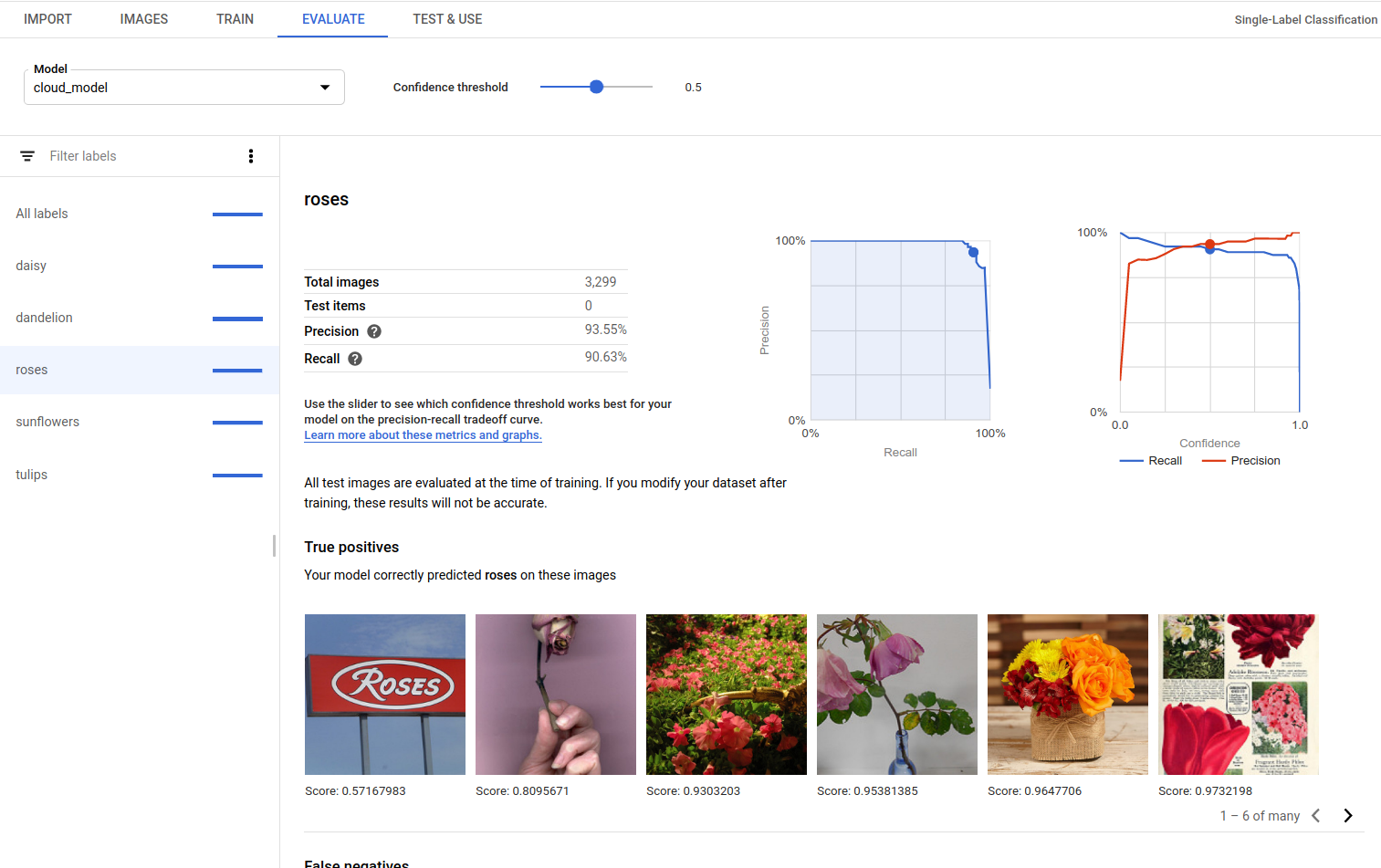
Vrais positifs, faux négatifs et faux positifs (UI uniquement)
Dans l'interface utilisateur, vous pouvez observer des exemples spécifiques de performances du modèle, à savoir les vrais positifs (VP), faux négatifs (FN)et faux positifs (FP) de vos ensembles d'ENTRAÎNEMENT et de VALIDATION.
UI Web
Avant d'essayer l'exemple ci-dessous, suivez les instructions de configuration pour ce langage sur la page Bibliothèques clientes.
Pour accéder aux vues "VP", "FN", et "FP" dans l'UI, sélectionnez l'onglet Évaluer, puis sélectionnez un libellé spécifique.
En affichant les tendances de ces prédictions, vous pouvez modifier votre ensemble d'entraînement pour améliorer les performances du modèle.
Les images de la catégorie True positives (Vrais positifs) sont des exemples d'images fournis au modèle entraîné et annotés correctement par le modèle :

Les images de la catégorie False negatives (Faux négatifs) sont également fournies au modèle entraîné, mais le modèle n'a pas correctement annoté l'image pour le libellé donné :
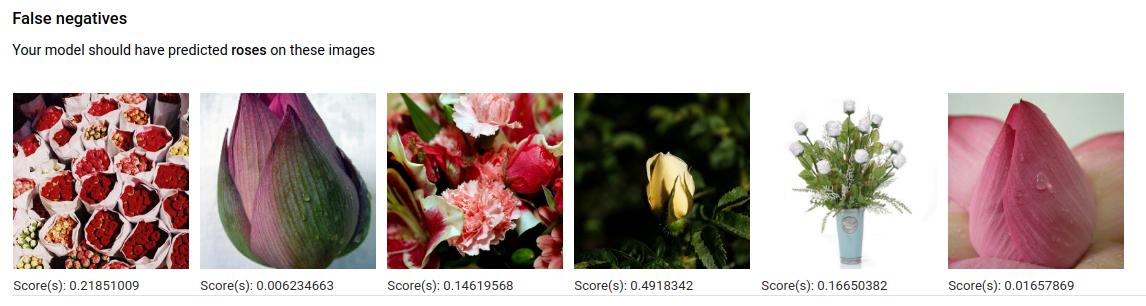
Enfin, les images de la catégorie False positives (Faux positifs) sont celles fournies au modèle entraîné qui étaient annotées avec le libellé donné, alors qu'elles n'auraient pas dû être annotées :

Le modèle sélectionne des cas intéressants, ce qui permet d'affiner les définitions et les libellés pour aider le modèle à comprendre les interprétations de libellés. Par exemple, une définition plus stricte peut aider le modèle à comprendre si vous considérez une peinture abstraite d'une rose comme une rose ou non.
Avec des boucles libellé-entraînement-évaluation répétées, votre modèle dégage d'autres ambiguïtés de vos données.
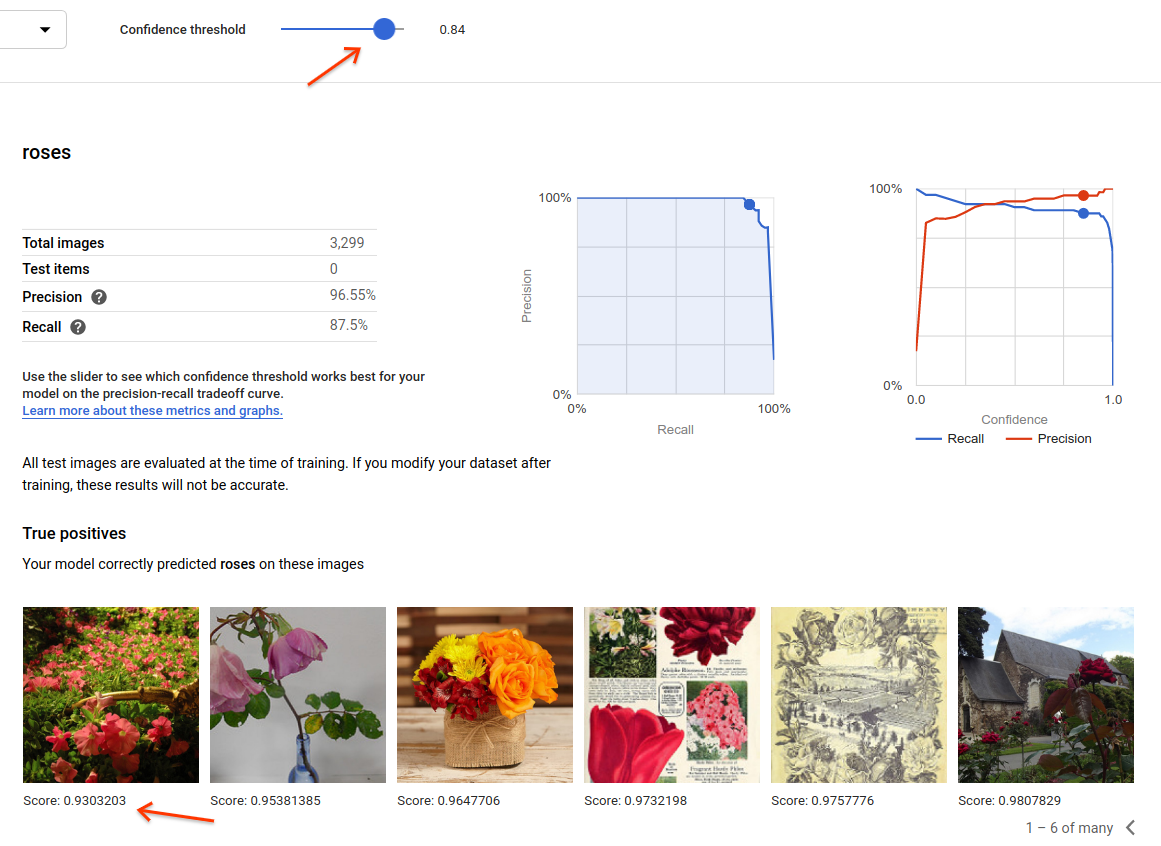
Vous pouvez également ajuster le seuil de score dans cette vue de l'interface utilisateur. Les images VP, FN et FP affichées reflètent le changement de seuil :
Itérer sur le modèle
Si vous n'êtes pas satisfait des niveaux de qualité, vous pouvez revenir aux étapes précédentes pour les améliorer en suivant les consignes ci-après :
- AutoML Vision vous permet de trier les images en fonction du degré de "confusion" du modèle, du libellé réel et du libellé prédit. Examinez ces images et assurez-vous que le libellé approprié leur a été attribué.
- Essayez d'ajouter plus d'images aux libellés de faible qualité.
- Vous devrez peut-être ajouter d'autres types d'images (par exemple, un angle plus large, une résolution supérieure ou inférieure, des points de vue différents).
- Supprimez totalement les libellés si vous ne disposez pas d'images d'entraînement en quantité suffisante.
- N'oubliez pas que les machines ne peuvent pas lire le nom de votre libellé : pour elles, il s'agit seulement d'une chaîne de lettres aléatoire. Si vous avez un libellé "porte" et un autre libellé "porte_avec_poignée", la machine ne peut se baser que sur les images que fournissez pour déterminer la nuance.
- Enrichissez vos données avec davantage d'exemples de vrais positifs et négatifs. Les exemples particulièrement importants sont ceux qui sont proches de la frontière de décision, c'est-à-dire susceptibles de créer une confusion alors que leur libellé est approprié.
- Spécifiez votre propre répartition des ensembles ENTRAÎNEMENT, TEST et VALIDATION. L'outil attribue des images au hasard, mais des quasi-doublons peuvent se retrouver dans ENTRAÎNEMENT et VALIDATION, ce qui peut entraîner un surapprentissage et nuire aux performances de l'ensemble TEST.
Une fois les modifications apportées, entraînez et évaluez un nouveau modèle jusqu'à ce que vous ayez atteint un niveau de qualité suffisant.