AutoML Vision Edge モデルを使用して画像にラベルを付ける
このクイックスタートでは、以下のプロセスを順を追って説明します。
- Google Cloud Storage に一連の画像をコピーする。
- 画像とそのラベルをリストした CSV を作成する。
- AutoML Vision でデータセットを作成し、カスタム AutoML Vision Edge モデルをトレーニングして(画像分類またはオブジェクト検出)、予測を行う。
- スマートフォン、ARM ベースのデバイス、Coral Edge TPU など、数種類のエッジデバイスに対して AutoML Vision Edge モデルをエクスポートしてデプロイする。
始める前に
プロジェクトを設定する
- Google Cloud アカウントにログインします。Google Cloud を初めて使用する場合は、アカウントを作成して、実際のシナリオでの Google プロダクトのパフォーマンスを評価してください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
- Google Cloud CLI をインストールします。
-
gcloud CLI を初期化するには:
gcloud init
-
Google Cloud プロジェクトを作成または選択します。
-
Google Cloud プロジェクトを作成します。
gcloud projects create PROJECT_ID
PROJECT_IDは、作成する Google Cloud プロジェクトの名前に置き換えます。 -
作成した Google Cloud プロジェクトを選択します。
gcloud config set project PROJECT_ID
PROJECT_IDは、実際の Google Cloud プロジェクト名に置き換えます。
-
-
AutoML and Cloud Storage API を有効にします。
gcloud services enable storage-component.googleapis.com
automl.googleapis.com storage-api.googleapis.com - Google Cloud CLI をインストールします。
-
gcloud CLI を初期化するには:
gcloud init
-
Google Cloud プロジェクトを作成または選択します。
-
Google Cloud プロジェクトを作成します。
gcloud projects create PROJECT_ID
PROJECT_IDは、作成する Google Cloud プロジェクトの名前に置き換えます。 -
作成した Google Cloud プロジェクトを選択します。
gcloud config set project PROJECT_ID
PROJECT_IDは、実際の Google Cloud プロジェクト名に置き換えます。
-
-
AutoML and Cloud Storage API を有効にします。
gcloud services enable storage-component.googleapis.com
automl.googleapis.com storage-api.googleapis.com - 環境変数
PROJECT_IDをプロジェクト ID に設定します。export PROJECT_ID=PROJECT_ID
AutoML API 呼び出しとリソース名には、プロジェクト ID が含まれています。環境変数PROJECT_IDは、ID の指定に便利です。
Cloud Storage バケットを作成する
Google Cloud コンソール プロジェクトに接続されたブラウザベースの Linux コマンドラインである Cloud Shell を使用して Cloud Storage バケットを作成します。
Google Cloud Storage バケットを作成します。バケット名の形式は、
project-id-vcmにする必要があります。次のコマンドによって、project-id-vcmという名前のus-central1リージョンにストレージ バケットが作成されます。利用可能なリージョンの一覧については、バケット ロケーション ページをご覧ください。gsutil mb -p ${PROJECT_ID} -c regional -l us-central1 gs://${PROJECT_ID}-vcm/BUCKET 変数を設定します。
export BUCKET=${PROJECT_ID}-vcm
バケットへのサンプル画像のコピー
次に、この Tensorflow のブログ投稿で使用されている花のデータセットをコピーします。画像は公開 Cloud Storage バケットに保存されるため、そこから直接自分のバケットにコピーできます。
Cloud Shell セッションで、次のように入力します。
gsutil -m cp -R gs://cloud-samples-data/ai-platform/flowers/ gs://${BUCKET}/img/ファイルのコピーには約 20 分かかります。
CSV ファイルの作成
サンプル データセットには、すべての画像の場所と各画像のラベルを含む CSV ファイルが含まれています。これを使用して独自の CSV ファイルを作成します。
CSV ファイルを更新して、自分のバケット内のファイルを指すようにします。
gsutil cat gs://${BUCKET}/img/flowers/all_data.csv | sed "s:cloud-ml-data/img/flower_photos/:${BUCKET}/img/flowers/:" > all_data.csvバケットに CSV ファイルをコピーします。
gsutil cp all_data.csv gs://${BUCKET}/csv/
データセットの作成
データセットの作成とモデルのトレーニングを開始するには、AutoML Vision UI にアクセスします。
プロンプトが表示されたら、Cloud Storage バケットに使用したプロジェクトを必ず選択します。
AutoML Vision ページから、[新しいデータセット] をクリックします。
![コンソールの [新しいデータセット] ボタン](https://cloud.google.com/static/vision/automl/docs/images/click-datasets.png?hl=ja)
このデータセットの名前を指定します(省略可)。モデルの目的を選択して [データセットを作成] をクリックし、データセットの作成プロセスを続けます。
![[New dataset name] フィールド](https://cloud.google.com/static/vision/automl/docs/images/dataset-name.png?hl=ja)
[インポートするファイルを選択します] 画面で、[Cloud Storage で CSV ファイルを選択] ラジオボタンをオンにします。CSV ファイルの Cloud Storage URI を指定します。このクイックスタートでは、CSV ファイルの場所は次のとおりです。
gs://${PROJECT_ID}-vcm/csv/all_data.csv
PROJECT_IDは、特定のプロジェクト ID に置き換えます。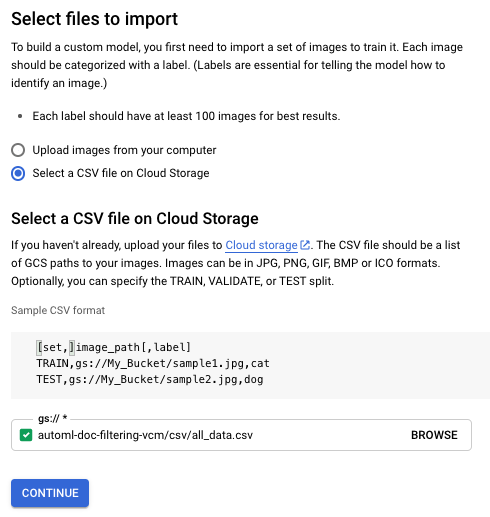
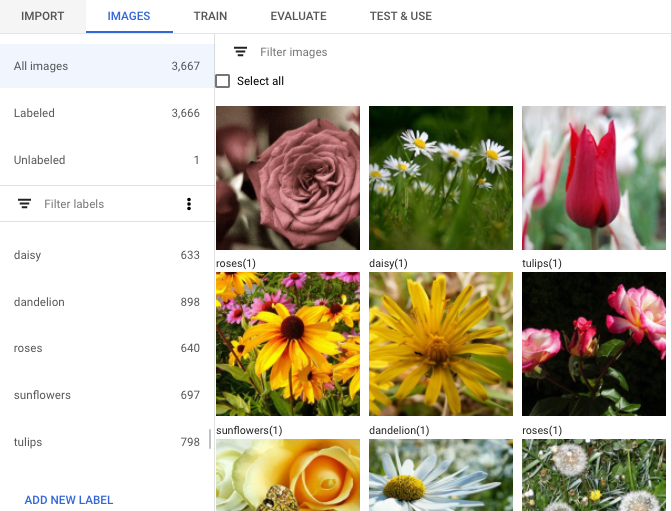
[続行] を選択して、画像のインポートを開始します。インポートには数分かかります。完了すると、次のページが表示され、データセットに対して識別されたすべての画像(ラベル付きの画像とラベルなし画像の両方)の詳細がそこに記載されます。
モデルのトレーニング
データセットが作成されて処理されたら、[トレーニング] タブを選択してモデルのトレーニングを開始します。
![[トレーニング] タブを選択](https://cloud.google.com/static/vision/automl/docs/images/train_tab.png?hl=ja)
続行するには [トレーニングを開始] を選択してください。これにより、[新しいモデルのトレーニング] ウィンドウが開き、トレーニング オプションが表示されます。
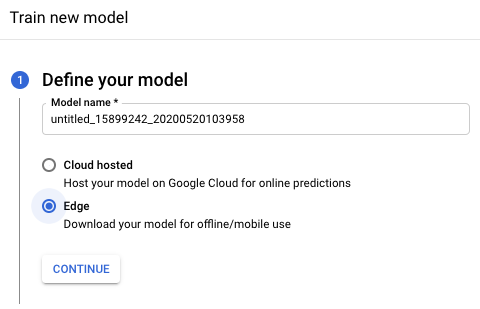
新しいモデル トレーニング ウィンドウの [モデルを定義する] セクションで、モデル名を変更し(省略可)、Edge モデルのラジオボタンを選択します。[続行] を選択して次のセクションに進みます。
[モデル最適化のオプション] セクションで、[最良のトレードオフ] オプションを使用し、[続行] を選択します。
[ノード時間予算の設定] セクションで、推奨されるノード予算(4 ノード時間)をそのまま使用します。
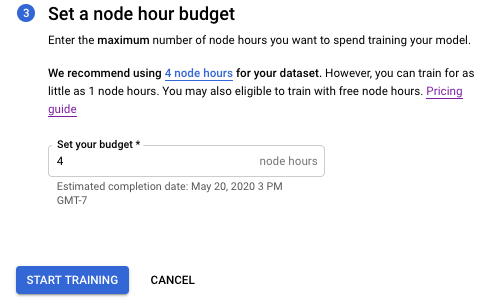
[トレーニングを開始] を選択して、モデルのトレーニングを開始します。
モデルのトレーニングが開始されます。これには約 1 時間かかります。トレーニングは、選択したノード時間より前に停止することがあります。トレーニングが完了した後、またはエラーが発生した場合は、メールが届きます。
モデルをデプロイする
モデルをエクスポートする前に、モデルをデプロイする必要があります。
モデルをデプロイするには、[テストと使用] タブを選択します。モデル名の近くにある [モデルをデプロイ] オプションをクリックします。
表示されたウィンドウで、デプロイするノードを 1 つ指定し、[デプロイ] を選択してモデルのデプロイ プロセスを開始します。
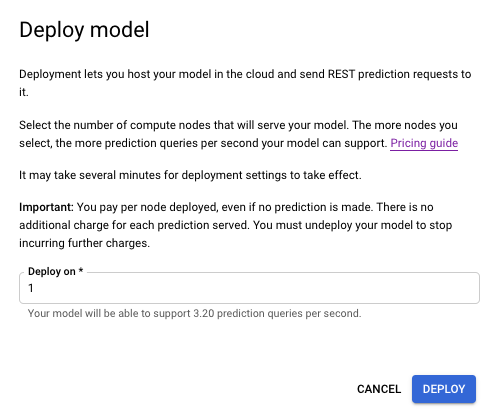
モデルのデプロイが完了すると通知が届きます。
モデルをエクスポートする
AutoML Vision Edge モデルを使用する最後のステップは、モデルをエクスポート(最適化とダウンロード)してデプロイ(使用)することです。
Edge デバイスで予測を行うために、モデルのエクスポートとデプロイを行う場合、いくつかの方法があります。
このクイックスタートでは、Tensorflow Lite(TF Lite)を例に説明します。TF Lite モデルは使いやすく、幅広いユースケースを対象にしています。
[テストと使用] タブの [モデルを使用する] セクションで、[TF Lite] オプションを選択します。

表示された [TF Lite パッケージのエクスポート] ウィンドウで、TF Lite パッケージをエクスポートする Cloud Storage バケットのロケーションを指定し、[エクスポート] を選択します。通常、エクスポート処理には数分かかります。
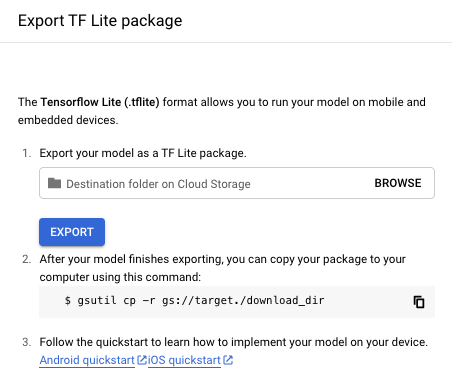
Google Cloud Storage のインストール先には、タイムスタンプとモデル形式で名前が付けられたフォルダがあり、その中に以下のファイルがあります。
- tflite ファイル(
model.tflite) - 辞書ファイル(
dict.txt) - メタデータ ファイル(
tflite_metadata.json)
クリーンアップ
このページで使用したリソースに対して Google Cloud アカウントで課金されないようにするには、Google Cloud プロジェクトとそのリソースを削除します。
次のステップ
これらのファイルを使用すると、チュートリアルに沿って Android デバイス、iOS デバイス、Raspberry Pi 3 またはウェブにデプロイできるようになります。
その他のモデル使用オプション
- CoreML(iOS / macOS)対応モデルとしてモデルをエクスポートできます。トレーニング後に、[テストと使用] タブで [CoreML] オプションを選択してモデルをエクスポートし、CoreML チュートリアルの手順を行います。
- Coral Edge TPU で実行するモデルをエクスポートできます。トレーニング後に、[テストと使用] タブで [Coral] オプションを選択してモデルをエクスポートします。ただし、現在のオブジェクト検出モデルと互換性がないため、Edge TPU の画像分類モデルのみをエクスポートすることをおすすめします(Edge TPU のオブジェクト検出モデルをトレーニングするには、こちらの Google Colab チュートリアルをご覧ください)。モデルをエクスポートした後は、Edge TPU での推論の実行に関する Coral の公式ドキュメントの手順を行います。
- モデルは、TensorFlow SavedModel としてエクスポートし、Docker コンテナで使用できます。トレーニング後に、[テストと使用] タブで [コンテナ] オプションを選択してモデルをエクスポートします。コンテナへのエクスポート方法については、Edge コンテナのチュートリアルをご覧ください。
- ブラウザまたは Node.js で使用するモデルは Tensorflow.js モデルとしてエクスポートできます。トレーニング後に [テストと使用] タブで [TensorFlow.js] オプションを選択してモデルをエクスポートし、Edge TensorFlow.js チュートリアルの手順を行います。
クリーンアップ
不要になったカスタムモデルやデータセットは削除できます。
Google Cloud Platform の不必要な課金を避けるため、GCP Console を使用して、不要になったプロジェクトを削除します。
モデルのデプロイ解除
モデルがデプロイされている間は料金がかかります。
- タイトルバーのすぐ下にある [テストと使用] タブを選択します。
- モデル名の下にあるバナーから [デプロイメントを削除] を選択します。デプロイ解除オプションのウィンドウが開きます。
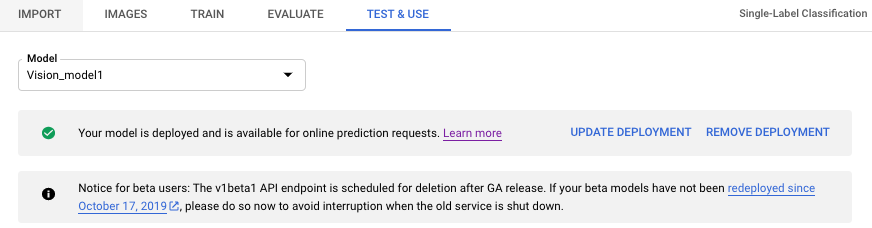
- [デプロイメントを削除] を選択して、モデルのデプロイを解除します。

- モデルのデプロイ解除が完了すると、メールが届きます。
プロジェクトを削除する(任意)
Google Cloud Platform で不必要な課金を避けるため、Google Cloud コンソールを使用して、不要になったプロジェクトを削除します。