Bilder mithilfe eines AutoML Vision Edge-Modells mit Labels versehen
In dieser Kurzanleitung werden folgende Verfahren erläutert:
- Bilder in Google Cloud Storage kopieren
- CSV-Datei zum Auflisten von Bildern und zugehörigen Labels erstellen
- Mithilfe der AutoML Vision-Objekterkennung ein Dataset erstellen, ein benutzerdefiniertes AutoML Vision Edge-Modell trainieren (Bildklassifizierung oder Objekterkennung) und eine Vorhersage treffen
- Exportieren und Bereitstellen Ihres AutoML Vision Edge-Modells für einen von mehreren Edge-Gerätetypen, z. B. Mobiltelefone, ARM-basierte Geräte und Coral Edge TPU.
Hinweis
Projekt einrichten
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
- Installieren Sie die Google Cloud CLI.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init
-
Google Cloud-Projekt erstellen oder auswählen.
-
Erstellen Sie ein Google Cloud-Projekt:
gcloud projects create PROJECT_ID
Ersetzen Sie
PROJECT_IDdurch einen Namen für das Google Cloud-Projekt, das Sie erstellen. -
Wählen Sie das von Ihnen erstellte Google Cloud-Projekt aus:
gcloud config set project PROJECT_ID
Ersetzen Sie
PROJECT_IDdurch den Namen Ihres Google Cloud-Projekts.
-
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Aktivieren Sie die AutoML and Cloud Storage APIs:
gcloud services enable storage-component.googleapis.com
automl.googleapis.com storage-api.googleapis.com - Installieren Sie die Google Cloud CLI.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init
-
Google Cloud-Projekt erstellen oder auswählen.
-
Erstellen Sie ein Google Cloud-Projekt:
gcloud projects create PROJECT_ID
Ersetzen Sie
PROJECT_IDdurch einen Namen für das Google Cloud-Projekt, das Sie erstellen. -
Wählen Sie das von Ihnen erstellte Google Cloud-Projekt aus:
gcloud config set project PROJECT_ID
Ersetzen Sie
PROJECT_IDdurch den Namen Ihres Google Cloud-Projekts.
-
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Aktivieren Sie die AutoML and Cloud Storage APIs:
gcloud services enable storage-component.googleapis.com
automl.googleapis.com storage-api.googleapis.com - Legen Sie für die Umgebungsvariable
PROJECT_IDIhre Projekt-ID fest.export PROJECT_ID=PROJECT_ID
Die AutoML API-Aufrufe und Ressourcennamen enthalten Ihre Projekt-ID. Die UmgebungsvariablePROJECT_IDbietet eine bequeme Möglichkeit, die ID anzugeben.
Cloud Storage-Bucket erstellen
Verwenden Sie Cloud Shell, eine browserbasierte Linux-Befehlszeile, die mit Ihrem Google Cloud Console-Projekt verbunden ist, um Ihren Cloud Storage-Bucket zu erstellen:
Erstellen Sie einen Google Cloud Storage-Bucket. Der Bucket-Name muss das Format
project-id-vcmhaben. Mit dem folgenden Befehl wird ein Storage-Bucket in der Regionus-central1mit dem Namenproject-id-vcmerstellt. Eine vollständige Liste der verfügbaren Regionen finden Sie auf der Seite Bucket-Standorte.gsutil mb -p ${PROJECT_ID} -c regional -l us-central1 gs://${PROJECT_ID}-vcm/Legen Sie die Variable BUCKET fest.
export BUCKET=${PROJECT_ID}-vcm
Beispielbilder in den Bucket kopieren
Kopieren Sie als Nächstes das in diesem Tensorflow-Blogpost verwendete Blumen-Dataset. Die Bilder sind in einem öffentlichen Cloud Storage-Bucket gespeichert, sodass Sie sie direkt von dort in Ihren eigenen Bucket kopieren können.
Geben Sie in der Cloud Shell-Sitzung Folgendes ein:
gsutil -m cp -R gs://cloud-samples-data/ai-platform/flowers/ gs://${BUCKET}/img/Das Kopieren der Datei dauert ungefähr 20 Minuten.
CSV-Datei erstellen
Das Beispiel-Dataset enthält eine CSV-Datei mit allen Bildspeicherorten und -labels. Damit lässt sich eine eigene CSV-Datei erstellen:
Aktualisieren Sie die CSV-Datei so, dass sie auf die Dateien in Ihrem Bucket verweist:
gsutil cat gs://${BUCKET}/img/flowers/all_data.csv | sed "s:cloud-ml-data/img/flower_photos/:${BUCKET}/img/flowers/:" > all_data.csvKopieren Sie die CSV-Datei in Ihren Bucket:
gsutil cp all_data.csv gs://${BUCKET}/csv/
Dataset erstellen
Besuchen Sie die AutoML Vision-UI, um mit dem Erstellen Ihres Datasets und dem Trainieren Ihres Modells zu beginnen.
Wählen Sie bei Aufforderung das Projekt aus, das Sie für Ihren Cloud Storage-Bucket verwendet haben.
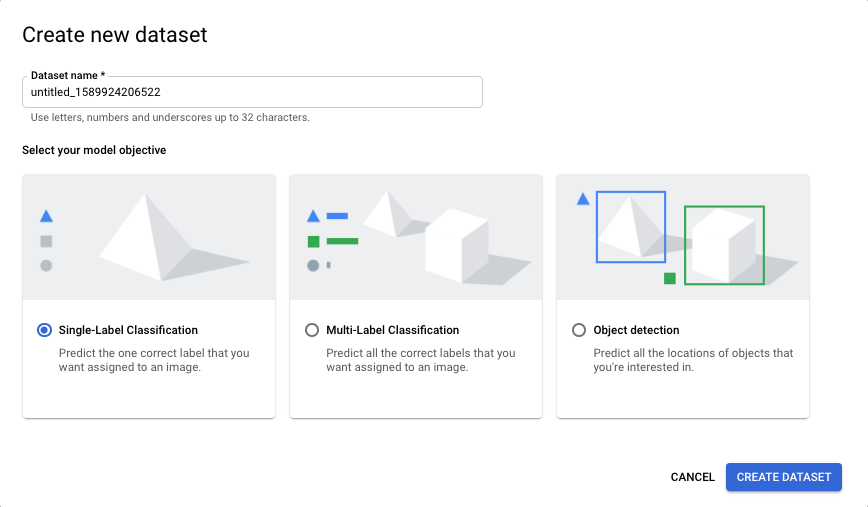
Klicken Sie auf der AutoML Vision-Seite auf New Dataset:

Geben Sie einen Namen für dieses Dataset an (optional), wählen Sie das Modellziel aus und klicken Sie dann auf Dataset erstellen, um den Dataset-Erstellungsprozess fortzusetzen.
Wählen Sie im Bildschirm Select files to import das Optionsfeld Select a CSV file on Cloud Storage aus. Geben Sie den Cloud Storage-URI Ihrer CSV-Datei an. In dieser Kurzanleitung befindet sich die CSV-Datei unter:
gs://${PROJECT_ID}-vcm/csv/all_data.csv
Ersetzen Sie
PROJECT_IDdurch Ihre spezifische Projekt-ID.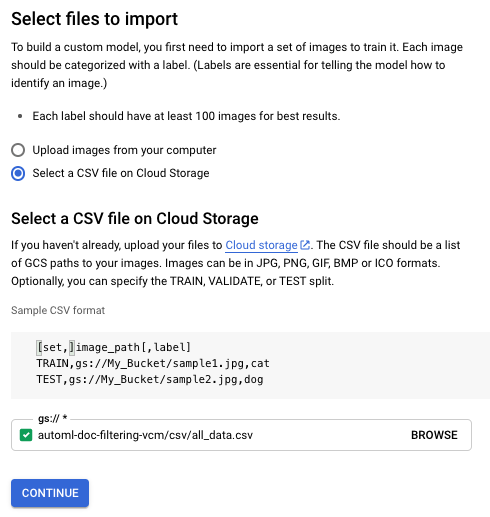
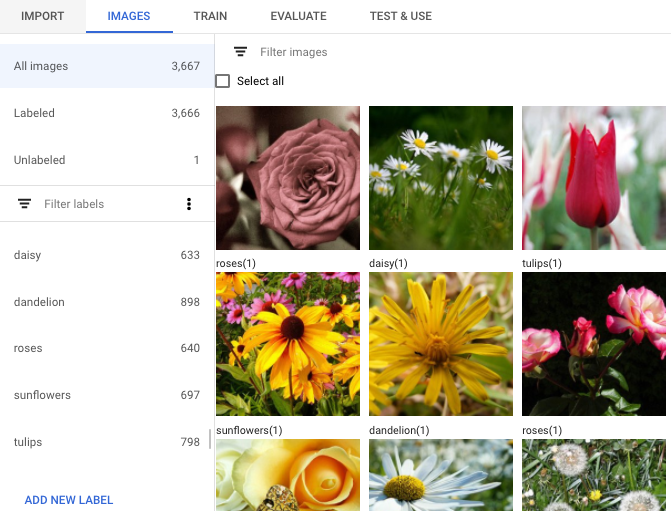
Klicken Sie auf Continue, um den Bildimport zu starten. Der Importvorgang dauert einige Minuten. Sobald der Vorgang abgeschlossen ist, werden Sie zur nächsten Seite weitergeleitet. Dort finden Sie Details zu allen Bildern (mit und ohne Label), die für Ihr Dataset ermittelt wurden.
Modell trainieren
Sobald Ihr Dataset erstellt und verarbeitet wurde, wählen Sie den Tab Train (Trainieren) aus, um mit dem Modelltraining zu beginnen.
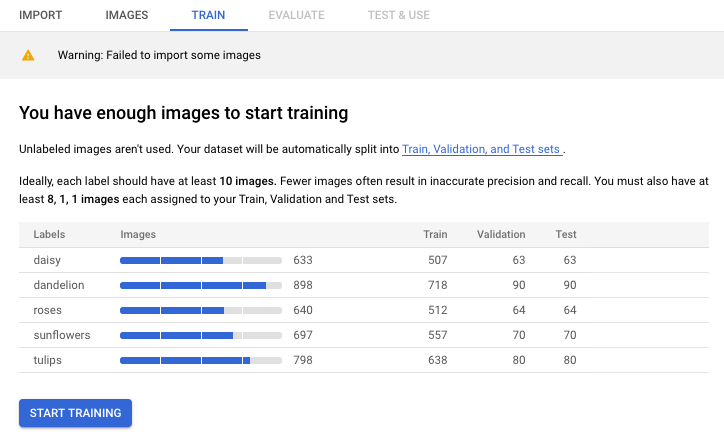
Wählen Sie Start trainingaus, um fortzufahren. Dadurch wird das Fenster Train new model mit Trainingsoptionen geöffnet.
Ändern Sie im Abschnitt Define your model des neuen Modelltrainingsfensters den Modellnamen (optional) und wählen Sie die Option Edge-Modell aus. Wählen Sie Continue aus, um zum nächsten Abschnitt zu gelangen.
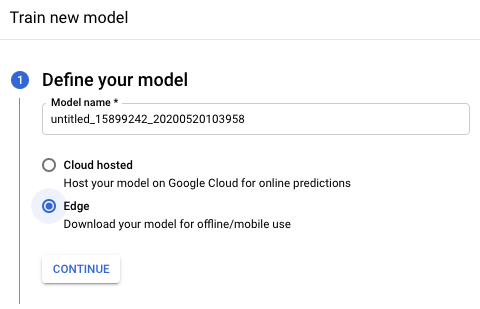
Übernehmen Sie im Abschnitt Optimize model for die Option Best trade-off (Optimal) und wählen Sie Continue aus.
Übernehmen Sie im Abschnitt Set a node hour budget das vorgeschlagene Knotenbudget (4 Knotenstunden).
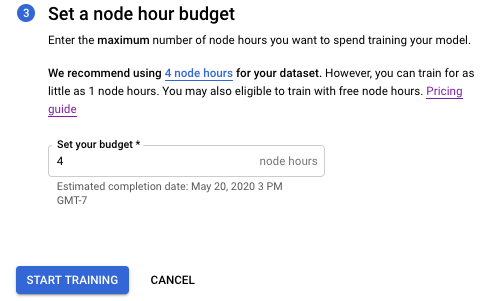
Wählen Sie Start training (Training starten), um mit dem Modelltraining zu beginnen.
Das Training des Modells wird gestartet und sollte etwa eine Stunde dauern. Das Training endet möglicherweise vor der ausgewählten Knotenstunde. Wenn das Training abgeschlossen ist oder ein Fehler auftritt, werden Sie per E-Mail benachrichtigt.
Modell bereitstellen
Bevor Sie Ihr Modell exportieren können, müssen Sie es zum Verwenden bereitstellen.
Wählen Sie zum Bereitstellen des Modells den Tab Test & use aus. Klicken Sie auf dem Tab neben dem Modellnamen auf die Option Deploy model.
Geben Sie dann im Fenster einen Knoten für die Bereitstellung an und wählen Sie Deploy aus, um den Modellbereitstellungsprozess zu starten.
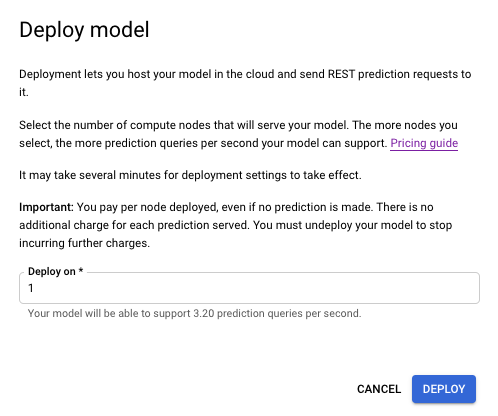
Sie erhalten eine Benachrichtigung, sobald die Modellbereitstellung abgeschlossen ist.
Modell exportieren
Im letzten Schritt bei der Verwendung eines AutoML Vision Edge-Modells wird das Modell exportiert (optimiert und heruntergeladen) und bereitgestellt (verwendet).
Es gibt verschiedene Möglichkeiten, Ihre Modelle für die Vorhersage auf Edge-Geräten zu exportieren und bereitzustellen.
In dieser Kurzanleitung verwenden Sie Tensorflow Lite (TF Lite) als Beispiel. TF Lite-Modelle sind einfach zu bedienen und bieten eine Vielzahl von Anwendungsfällen.
Wählen Sie auf dem Tab Test und Nutzung im Abschnitt Modell verwenden die Option TF Lite aus.
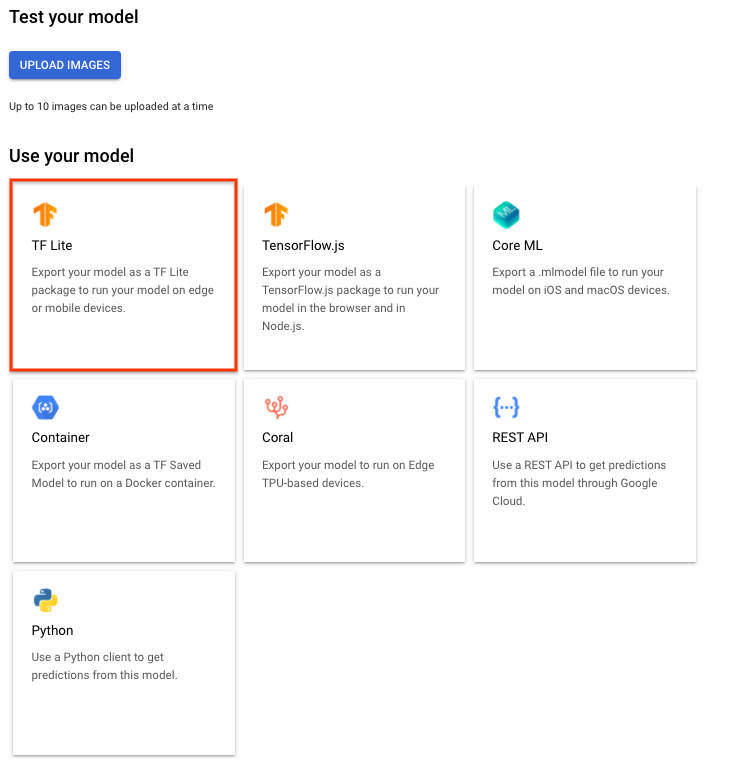
Geben Sie im angezeigten Fenster TF Lite-Paket exportieren einen Cloud Storage-Bucket-Speicherort an, in den ein TF Lite-Paket exportiert werden soll, und wählen Sie dann Exportieren aus. Der Exportvorgang dauert in der Regel einige Minuten.
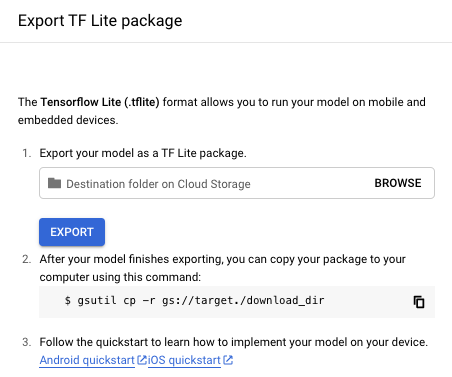
Am Google Cloud Storage-Zielort befindet sich ein Ordner mit dem Namen für den Zeitstempel und das Modellformat, unter dem Sie die folgenden Dateien finden:
- eine tflite-Datei (
model.tflite) - eine Wörterbuchdatei (
dict.txt) - eine Metadatendatei (
tflite_metadata.json)
Bereinigen
Löschen Sie das Google Cloud-Projekt mit den Ressourcen, damit Ihrem Google Cloud-Konto die auf dieser Seite verwendeten Ressourcen nicht in Rechnung gestellt werden.
Nächste Schritte
Mithilfe dieser Dateien können Sie die Anleitungen für folgende Bereitstellungen durcharbeiten: Bereitstellung auf Android-Geräten, iOS-Geräten, Raspberry Pi 3 und im Web.
Andere Nutzungsoptionen für Modelle
- Sie können das Modell als von CoreML unterstütztes Modell (iOS/macOS) exportieren. Nach dem Training können Sie das Modell exportieren. Wählen Sie dazu auf dem Tab Test und Nutzung die Option CoreML aus und folgen Sie der CoreML-Anleitung
- Sie können das Modell zur Ausführung auf der Coral Edge-TPU exportieren. Exportieren Sie nach dem Training das Modell. Wählen Sie dazu auf dem Tab Test und Nutzung die Option Coral aus. Aufgrund der derzeitigen Inkompatibilität mit unserem Objekterkennungsmodell empfehlen wir jedoch, nur Bildklassifizierungsmodelle für die Edge TPU zu exportieren (um ein Objekterkennungsmodell für die Edge TPU zu trainieren, folgen Sie stattdessen einem dieser Google Colab-Tutorials). Nachdem Sie das Modell exportiert haben, folgen Sie der offiziellen Dokumentation von Coral, um eine Inferenz auf die Edge-TPU auszuführen.
- Sie können das Modell als TensorFlow SavedModel exportieren und mit einem Docker-Container verwenden. Nach dem Training können Sie das Modell exportieren. Wählen Sie dazu im dem Tab Testen & Verwenden die Option Container aus und befolgen Sie die Anleitung für Edge-Container für den Export in einen Container.
- Sie können das Modell zur Verwendung in einem Browser oder in Node.js als ein TensorFlow.js-Modell exportieren. Nach dem Training können Sie das Modell exportieren. Wählen Sie dazu auf dem Tab Test und Nutzung die Option TensorFlow.js aus und folgen Sie der Anleitung für Edge TensorFlow.js.
Clean-up
Wenn Sie das benutzerdefinierte Modell oder das Dataset nicht mehr benötigen, können Sie es löschen.
Löschen Sie Ihr Projekt mit der GCP Console, wenn Sie es nicht mehr benötigen, um unnötige Google Cloud Platform-Gebühren zu vermeiden.
Bereitstellung eines Modells entfernen
Während der Bereitstellung fallen für das Modell Gebühren an.
- Wählen Sie den Tab Test und Nutzung direkt unter der Titelleiste aus.
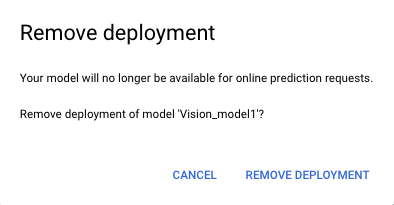
- Wählen Sie aus dem Banner unterhalb des Modellnamens Deployment entfernen aus, um das Fenster zum Aufheben der Bereitstellung zu öffnen.
- Wählen Sie Remove deployment (Deployment entfernen) aus, um die Bereitstellung des Modells zu entfernen.
- Sie erhalten eine E-Mail, wenn die Bereitstellung vollständig entfernt wurde.
Projekt löschen (optional)
Löschen Sie das Projekt mit der Google Cloud Console, wenn Sie es nicht benötigen. Damit vermeiden Sie unnötige Kosten für die Google Cloud Platform.