简介
假设您正在与建筑保护委员会合作,尝试发现您所在城市里建筑风格一致的街区。有数十万张的房屋快照需要仔细筛查;如果您试图手动分类所有这些图片,这将是一项单调乏味且容易出错的工作。 几个月前,一名实习生为其中的几百张图片添加了标签,但从那以后就没有人碰过这些照片了。如果您可以教计算机来代您完成这项工作,那么一定会收到很好的效果!

为什么说机器学习 (ML) 是最适合解决这类问题的工具?
 传统编程要求程序员必须指定计算机要逐步完成的一组指令。虽然这种方法可以解决各种各样的问题,但它不能按照您希望的方式对房屋进行分类。这些照片在构图、色彩、角度和风格细节方面差异很大;您无法想象该如何确定一套分步规则,让机器能够判断一张单户式住宅照片是属于工匠风格还是现代风格。甚至难以想象应该从哪里开始入手。幸运的是,机器学习系统可以很好地解决这个问题。
传统编程要求程序员必须指定计算机要逐步完成的一组指令。虽然这种方法可以解决各种各样的问题,但它不能按照您希望的方式对房屋进行分类。这些照片在构图、色彩、角度和风格细节方面差异很大;您无法想象该如何确定一套分步规则,让机器能够判断一张单户式住宅照片是属于工匠风格还是现代风格。甚至难以想象应该从哪里开始入手。幸运的是,机器学习系统可以很好地解决这个问题。
Vision API 或 AutoML 哪一款工具更适合我?
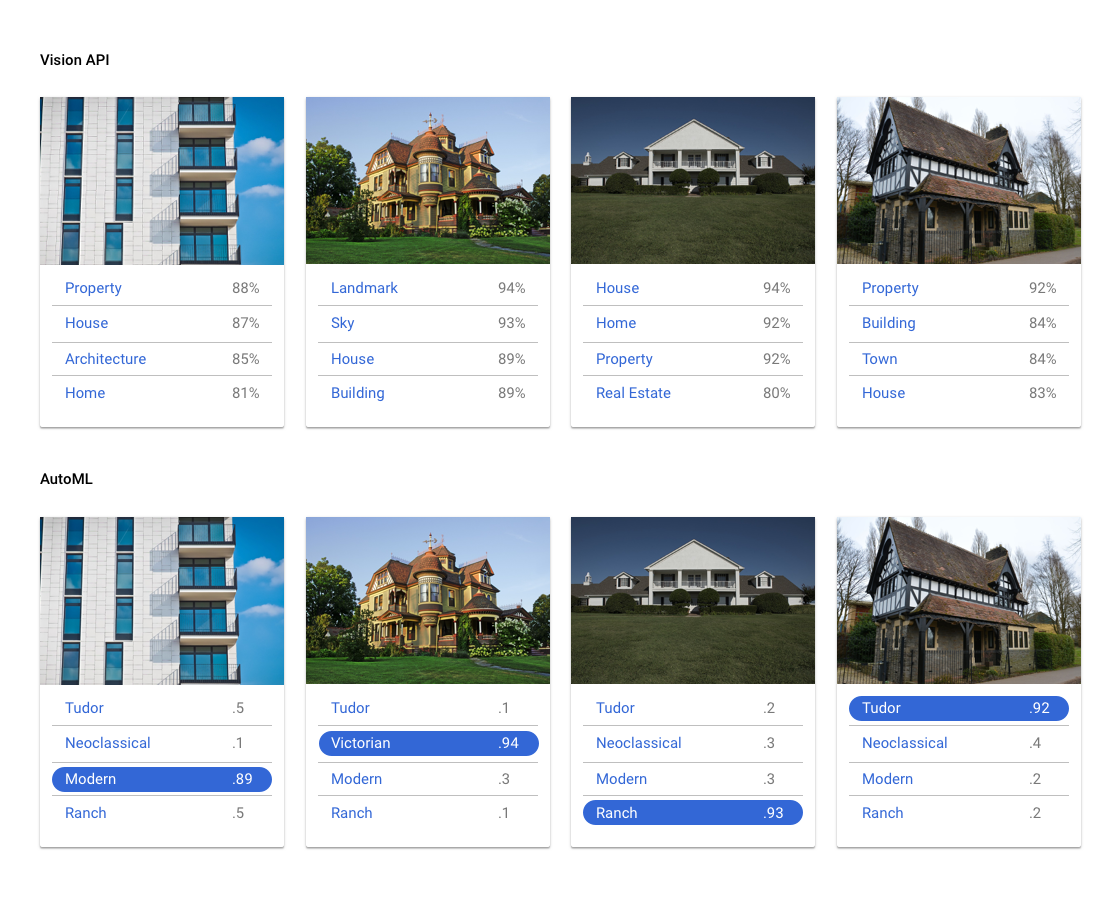
Vision API 可将图片归入数千种预定义类别,检测图片中的各个对象和人脸,以及查找和读取图片中包含的印刷文字。如果您想要检测数据集中的各个对象、人脸和文本,或者您需要对图片进行非常常规的分类,请试用 Vision API,看看它是否适合您。但是,如果您的使用场景需要使用您自己的标签来对图片进行分类,那么可以尝试使用自定义分类模型来看看是否能满足您的需求。
| 试用 Vision API | 开始使用 AutoML |
AutoML 中的机器学习涉及哪些内容?
 为了实现期望的结果,机器学习需要使用数据来训练算法。算法和训练方法的具体细节因使用场景而异。机器学习有许多不同的子类别,所有子类别均用于解决不同的问题,并具有不同的限制条件。借助 AutoML Vision,您可以执行监督式学习,这需要训练机器根据已加标签的数据来识别模式。通过监督式学习,我们可以训练模型来识别图片中我们需要关注的模式和内容。
为了实现期望的结果,机器学习需要使用数据来训练算法。算法和训练方法的具体细节因使用场景而异。机器学习有许多不同的子类别,所有子类别均用于解决不同的问题,并具有不同的限制条件。借助 AutoML Vision,您可以执行监督式学习,这需要训练机器根据已加标签的数据来识别模式。通过监督式学习,我们可以训练模型来识别图片中我们需要关注的模式和内容。
数据准备
如需使用 AutoML Vision 训练自定义模型,您需要提供各种待分类图片的有标签样本(输入),以及您希望机器学习系统预测的类别或标签(输出)。
评估您的使用场景

在整合数据集时,应始终以使用场景为基础。您可以从以下问题入手:
- 您想要实现什么样的结果?
- 为了实现这个结果,您需要识别哪些种类的类别?
- 人类能否识别这些类别?尽管 AutoML Vision 每次处理的类别数量都远多于人类可以记住和分配的数量,但如果人类无法识别某一具体类别,那么 AutoML Vision 也很难识别出来。
- 哪些种类的样本最能反映您的系统要分类的数据类型和范围?
支持 Google 机器学习产品的核心原则是以人为本的机器学习,这种方法强调负责任的 AI 做法(包括公平性)。机器学习中的公平性目标旨在了解和防止以不公正或有偏见的方式对待不同种族、收入、性取向、宗教、性别以及带有历史上与歧视和边缘化相关的其他特征的人群的倾向(当其无论何时何地表现在算法系统或算法辅助决策中时)。如需了解详情,请参阅我们的指南;如需查看有关“公平意识”的说明 ✽,请参阅下述准则。在您阅读有关整理数据集的准则时,我们建议您了解与您的用例相关的机器学习公平性。
寻找数据
 确定了所需的数据后,您需要找到一种方法来获取数据。首先,您可以考虑使用组织收集的所有数据。此时您可能会发现,自己已经在收集训练模型所需的数据了。如果没有收集到所需的数据,您可以手动获取或将这项任务外包给第三方提供商。
确定了所需的数据后,您需要找到一种方法来获取数据。首先,您可以考虑使用组织收集的所有数据。此时您可能会发现,自己已经在收集训练模型所需的数据了。如果没有收集到所需的数据,您可以手动获取或将这项任务外包给第三方提供商。
在每个类别中添加足够的加标签样本
 若要进行 AutoML Vision 训练,每个类别/标签必须至少有 100 个图片样本。每个标签的高质量样本数量越多,成功识别标签的可能性就越大;一般而言,您为训练过程提供的加标签数据越多,模型的表现就会越出众。目标是每个标签至少 1000 个样本。
若要进行 AutoML Vision 训练,每个类别/标签必须至少有 100 个图片样本。每个标签的高质量样本数量越多,成功识别标签的可能性就越大;一般而言,您为训练过程提供的加标签数据越多,模型的表现就会越出众。目标是每个标签至少 1000 个样本。
在所有类别中平均分配样本
每个类别获取数量大致相同的训练样本非常重要。即使某一个标签有很多数据,也最好针对每个标签进行平等分配。为了说明原因,我们假设您用于构建模型的图片中有 80% 都是现代风格的单户式住宅照片。由于标签的分配如此不均衡,您的模型很可能会发现,总是将照片预测为现代风格的单户式住宅非常安全,而尝试预测它是一个不那么常见的标签则会有风险。这就像是编写一份单选题试卷,其中几乎所有正确答案都是“C”;在这种情况下,聪明的应试者很快就会发现,每次都可以回答“C”,甚至都不需要看题。

我们理解,并不总是可以为每个标签找到数量大致相同的样本。某些类别的高质量、无偏见样本可能更难获取。在这些情况下,您可以遵循一个经验法则,即样本数量最少的标签所具有的样本数应至少达到样本数最多的标签的 10%,因此,如果最大的标签有 10000 个样本,则最小的标签应至少有 1000 个样本。
捕获问题空间中的各种变化
出于类似的原因,请尝试确保您的数据能够捕获问题空间的变化和多样性。模型在训练过程中看到的选择项越广泛,就越容易泛化新的样本。例如,如果您尝试将消费类电子产品的照片进行分类,则模型在训练中接触到的各种消费类电子产品越多,它就越有可能区分出新型平板电脑、手机或笔记本电脑,即使之前从未见过这种特定型号也是如此。
将数据与模型的预期输出相匹配

您所搜集的图片在视觉上应与您计划进行预测的图片类似。如果您正在尝试对在冬季多雪天气条件下拍摄的房屋图片进行分类,而您的模型仅使用了在阳光明媚天气条件下拍摄的房屋图片进行训练,那么您可能无法从中获得出色的结果,即使您已经使用自己所需的类别标记了这些图片也是如此,因为光线和背景的差异可能足以影响模型的表现。理想情况下,您的训练样本是从您计划使用模型进行分类的数据集中提取的真实数据。
考虑 AutoML Vision 在创建自定义模型时如何使用您的数据集
数据集包含训练集、验证集和测试集。如果您未指定分组(请参阅准备数据),那么 AutoML Vision 会自动将 80% 图片用于训练,10% 图片用于验证,另外 10% 图片用于测试。
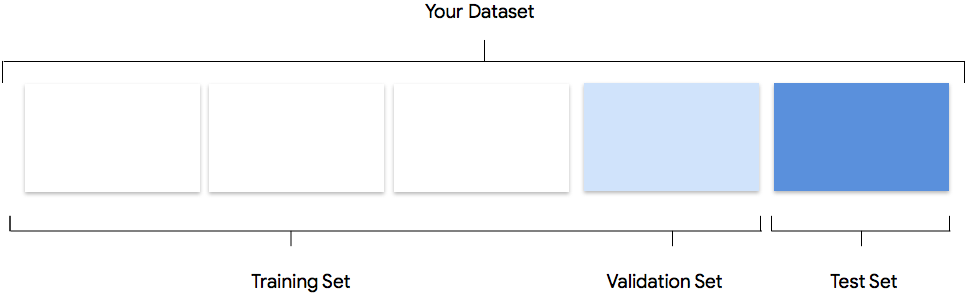
训练集
 您的绝大部分数据都应该划分到训练集中。训练集包含您的模型在训练期间“看到”的数据:它用于学习模型的参数,即神经网络节点之间连接的权重。
您的绝大部分数据都应该划分到训练集中。训练集包含您的模型在训练期间“看到”的数据:它用于学习模型的参数,即神经网络节点之间连接的权重。
验证集
 验证集(有时也称为“开发集”)也用于训练过程。模型学习框架在训练过程的每次迭代期间吸纳了训练数据之后,会根据模型在验证集上的表现来调整模型的超参数,这些超参数是指定模型结构的变量。如果您尝试使用训练集来调整超参数,则很可能会导致模型过度关注训练数据,因而很难泛化到并非精确匹配的样本。使用在一定程度上的新数据集微调模型结构,意味着您的模型将会有更好的泛化效果。
验证集(有时也称为“开发集”)也用于训练过程。模型学习框架在训练过程的每次迭代期间吸纳了训练数据之后,会根据模型在验证集上的表现来调整模型的超参数,这些超参数是指定模型结构的变量。如果您尝试使用训练集来调整超参数,则很可能会导致模型过度关注训练数据,因而很难泛化到并非精确匹配的样本。使用在一定程度上的新数据集微调模型结构,意味着您的模型将会有更好的泛化效果。
测试集
 测试集完全不参与训练过程。当模型完成全部训练后,我们会利用测试集来对模型提出全新的挑战。通过模型在测试集上的表现,您可以充分了解模型在使用真实数据时的表现。
测试集完全不参与训练过程。当模型完成全部训练后,我们会利用测试集来对模型提出全新的挑战。通过模型在测试集上的表现,您可以充分了解模型在使用真实数据时的表现。
手动拆分
 您也可以自行拆分数据集。如果您想要对流程施加更多控制,或者您确定要在模型训练生命周期的某个阶段添加特定的样本,则手动拆分数据是个不错的选择。
您也可以自行拆分数据集。如果您想要对流程施加更多控制,或者您确定要在模型训练生命周期的某个阶段添加特定的样本,则手动拆分数据是个不错的选择。
准备要导入的数据

决定好手动拆分或自动拆分数据后,您可以选择以下三种方法之一在 AutoML Vision 中添加数据:
- 您可以通过与标签对应的文件夹中存储并排序的图片导入数据。
- 您可以通过内嵌的标签以 CSV 格式从 Google Cloud Storage 中导入数据。如需了解详情,请参阅我们的文档。
- 如果您的数据尚未添加标签,您还可以上传未加标签的图片样本,并使用 AutoML Vision 界面将标签应用于各个样本。
评估
模型训练完成后,您将收到模型性能总结。 点击“评估”或“查看完整评估”可以查看详细分析。
在评估模型前,需要注意哪些事项?
 调试模型主要是调试数据,而非模型本身。如果在推送到生产环境前后,模型在您评估其性能时有出乎意料的表现,则您应返回并检查数据,以查找能够改进的地方。
调试模型主要是调试数据,而非模型本身。如果在推送到生产环境前后,模型在您评估其性能时有出乎意料的表现,则您应返回并检查数据,以查找能够改进的地方。
我可以在 AutoML Vision 中执行哪些种类的分析?
在 AutoML Vision 的评估部分,您可以根据自定义模型基于测试样本的输出以及常见的机器学习指标来评估其性能。在本部分中,我们将介绍下面每个概念的含义。
- 模型输出
- 分数阈值
- 真正例、真负例、假正例和假负例
- 精确率和召回率
- 精确率/召回率曲线。
- 平均精确率
如何解读模型的输出?
AutoML Vision 会从您的测试数据中提取样本,对模型提出全新的挑战。模型会针对每个样本输出一系列数字,用于表示每个标签与该样本相关的程度。如果该数字较大,表示关于该标签应该应用于该文档的模型置信度较高。

什么是分数阈值?
我们可以通过设置分数阈值将这些概率转换为二进制的“开”/“关”值。分数阈值是指若要将某一类别分配给某一测试项,模型必须具有的置信度水平。界面中的分数阈值滑块是一种直观的工具,用于测试不同阈值对数据集中的所有类别和个别类别的影响。如果分数阈值较低,那么您的模型需要分类的图片会较多,但在该过程中,它对一些图片的分类可能会出错。如果分数阈值较高,那么您的模型需要分类的图片会较少,但出现图片分类错误的风险较低。您可以在界面中调整每个类别的阈值以进行实验。但是,在生产环境中使用模型时,您必须实施您认为最佳的阈值。
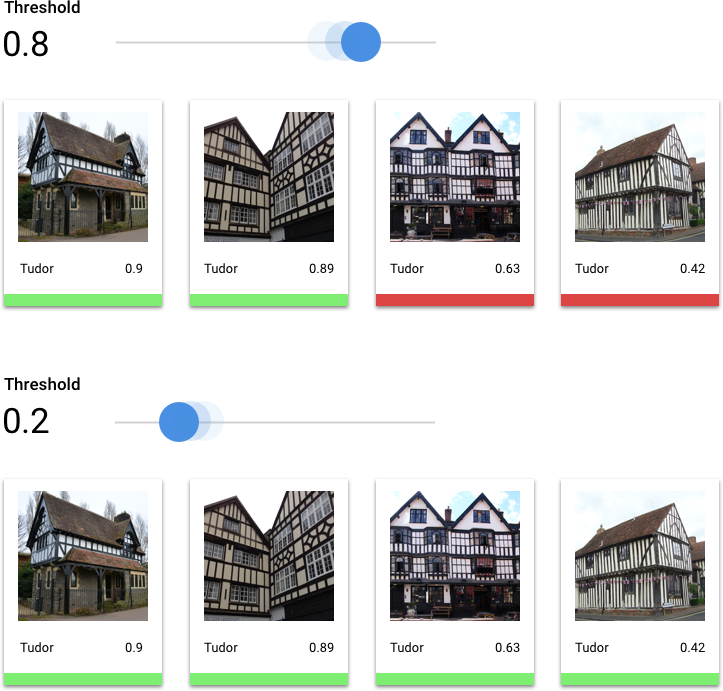
什么是真正例、真负例、假正例和假负例?
应用分数阈值后,模型所做的预测可分为以下四类。

我们可以使用这些类别来计算精确率和召回率,这两个指标可帮助我们衡量模型的效果。
什么是精确率和召回率?
精确率和召回率有助于我们了解模型捕获信息的精准度以及遗漏的信息量。通过精确率指标我们可以了解到,在分配了某标签的所有测试样本中,实际有多少样本应该分类到该标签中。通过召回率指标可以了解到,在本应分配该标签的所有测试样本中,有多少样本实际分配了该标签。


我应该针对精确率还是召回率进行优化?
根据您的使用场景,您可能需要针对精确率或召回率进行优化。让我们通过以下两个使用场景来看看如何做出这个决定。
使用场景:图片含有隐私信息
假设您要创建一个自动检测敏感信息并对该信息进行模糊处理的系统。

在此使用场景中,那些本不需要模糊处理、却被如此处理的内容属于假正例,它们可能会让您感到有些烦恼,但并不会带来负面影响。
在此使用场景中,那些需要模糊处理、却未能进行此项处理的内容(如信用卡)属于假负例,它们可能会导致身份盗用。
在这种情况下,您需要针对召回率进行优化。该指标衡量所有的预测中遗漏了多少信息。高召回率的模型可能会为略微相关的样本添加标签,这对于类别缺少训练数据的情况非常有用。
使用场景:搜索图库照片
假设您想要创建一个用于查找与给定关键字最为匹配的图库照片的系统。

此使用场景中的假正例返回不相关的图片。由于您的产品是以仅返回最佳匹配图片为目标,因此这是一个完全失败的响应。

此使用场景中的假负例无法返回与搜索关键字相关的图片。由于许多搜索字词都会有数以千计的最佳匹配照片,因此这没什么问题。
在这种情况下,您需要针对精确率进行优化。该指标衡量所进行的所有预测的正确程度。高精确率的模型可能只会为最相关的样本添加标签,这对于类别在训练数据中很常见的情况非常有用。
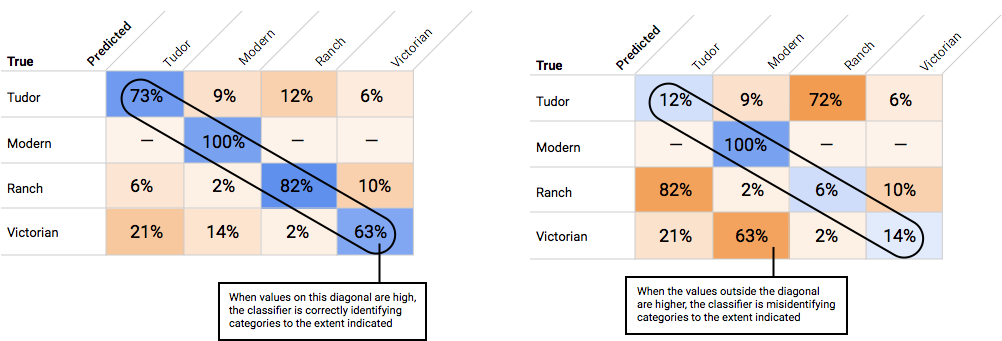
如何使用混淆矩阵?
我们可以使用混淆矩阵比较模型在每个标签上的表现。在理想模型中,对角线上的所有值都将较高,而其他所有值都将较低。这表明目标类别都得到了正确识别。如果有其他任何值较高,我们可以由此了解模型如何对测试图片进行了错误分类。
如何解读精确率/召回率曲线?
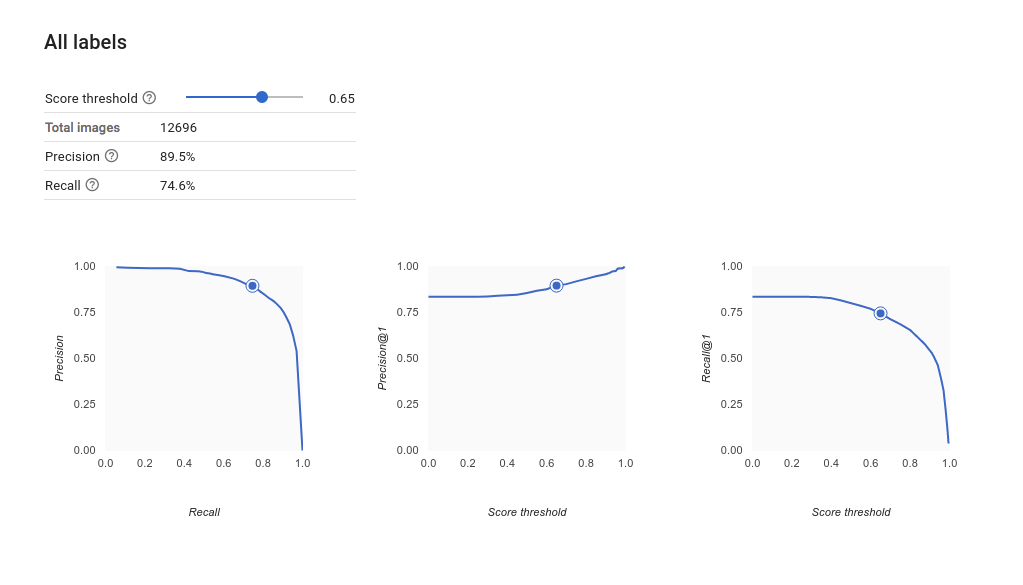
通过分数阈值工具,您可以研究所选分数阈值会如何影响您的精确率和召回率。当您拖动分数阈值栏上的滑块时,您可以看到该阈值在精确率与召回率权衡曲线上的对应位置,以及该阈值对您的精确率和召回率分别有何影响(对于多类别模型,这些图表上的精确率和召回率意味着用于计算精确率和召回率指标的唯一标签是我们返回的标签集中得分最高的标签)。这可以帮助您在假正例和假负例之间取得较好的平衡。
在选择了对于整个模型而言似乎可接受的阈值后,您就可以点击各个标签,并查看该阈值在各个标签的精确率与召回率曲线上处于什么位置。在某些情况下,这可能意味着针对一些标签进行的很多预测都不正确,这可能有助于您决定为每个类别选择针对这些标签定制的阈值。例如,假设您查看了房屋数据集,并注意到如果阈值设为 0.5,“都铎风格”以外的其他所有图片类型都会有合理的精确度和召回率,这可能是因为“都铎风格”类别过于普通。就该类别而言,您会看到大量的假正例。在这种情况下,当您调用分类模型进行预测时,您可能决定仅为"都铎风格"使用阈值 0.8。
什么是平均精确率?
精确率/召回率曲线下的面积是衡量模型准确率的有用指标。 它可以衡量模型在所有分数阈值上的表现。在 AutoML Vision 中,该指标称为“平均精确率”。此分数越接近 1.0,您的模型在测试集上的表现就越好;如果是随机猜测使用哪个标签的模型,平均精确率约为 0.5。
测试模型
 AutoML Vision 自动使用 10% 的数据(如果您选择自行拆分数据,则为您选择使用的任何百分比)来测试模型,通过“评估”页面,您可以了解模型在该测试数据上的表现。
但是,如果您想对模型进行置信度检查,有几种方法可以使用。最简单的方法是在“预测”页面中上传几个图片,然后查看模型为样本选择的标签。希望这符合您的期望。请针对您希望收到的每种图片尝试一些样本。
AutoML Vision 自动使用 10% 的数据(如果您选择自行拆分数据,则为您选择使用的任何百分比)来测试模型,通过“评估”页面,您可以了解模型在该测试数据上的表现。
但是,如果您想对模型进行置信度检查,有几种方法可以使用。最简单的方法是在“预测”页面中上传几个图片,然后查看模型为样本选择的标签。希望这符合您的期望。请针对您希望收到的每种图片尝试一些样本。
如果您想在自己的自动化测试中使用模型,“预测”页面还会告诉您如何以编程方式调用模型。