Como preparar dados de treinamento
Nesta página, você aprende a preparar seus dados para treinar um modelo de rastreamento de objetos de AutoML Video.
Como preparar os vídeos
Nesta página, descrevemos como preparar os dados de treinamento e teste para que o rastreamento de objetos do AutoML Video Intelligence crie um modelo de anotação de vídeos para você.
O rastreamento de objetos do AutoML Video Intelligence aceita os formatos de vídeo a seguir para treinar seu modelo ou solicitar uma predição.
- .MOV
- .MPEG4
- .MP4
- .AVI
O tamanho máximo do arquivo de vídeos de treinamento é de 50 GB e até 3 horas de duração. Arquivos de vídeo individuais com ajustes de horário incorretos ou vazios no contêiner não são compatíveis.
Os dados de treinamento precisam estar o mais próximo possível dos dados para predições. Por exemplo, se o caso de uso incluir vídeos desfocados e de baixa resolução (como de uma câmera de segurança), seus dados de treinamento precisarão ser compostos por vídeos desfocados e de baixa resolução. Em geral, pense também em fornecer vários ângulos, resoluções e planos de fundo nos vídeos de treinamento.
Em geral, os modelos de rastreamento de objetos de vídeo do AutoML não podem prever rótulos que humanos não são capazes de atribuir. Por exemplo, se um humano não puder ser treinado para atribuir rótulos olhando o vídeo por 1 ou 2 segundos, o modelo provavelmente não poderá ser treinado para fazer isso também.
O tamanho mínimo da caixa delimitadora é 10 px por 10 px.
Para uma resolução de frame de vídeo muito maior do que 1024 pixels por 1024 pixels, talvez haja uma perda na qualidade da imagem durante o processo de normalização do frame usado pelo rastreamento de objetos do AutoML Video.
Os modelos funcionam melhor quando há no máximo 100 vezes mais frames para o rótulo mais comum do que para o menos comum. Considere remover rótulos de frequência muito baixa dos conjuntos de dados.
Cada rótulo exclusivo deve estar presente em pelo menos três frames de vídeo distintos. Além disso, cada rótulo também precisa ter no mínimo 10 anotações.
O número máximo de frames de vídeo rotulados em cada conjunto de dados é atualmente limitado a 150.000.
O número máximo de caixas delimitadoras anotadas totais em cada conjunto de dados está atualmente limitado a 1.000.000.
O número máximo de rótulos exclusivos em cada conjunto de dados está atualmente limitado a 1.000.
Seus dados de treinamento precisam ter pelo menos um rótulo.
Forneça pelo menos 100 frames de vídeo de treinamento por rótulo. Em cada um deles, todos os objetos de interesse são rotulados. Não é necessário rotular todos os frames em que os objetos aparecem, mas quanto mais frames forem rotulados, melhor o modelo. É recomendável escolher frames não adjacentes para que eles possam cobrir tamanhos, ângulos, plano de fundo, condição de iluminação diferentes etc.
Conjuntos de dados de treinamento, validação e teste
Os dados em um conjunto de dados são divididos em três conjuntos de dados ao treinar um modelo: um conjunto de dados de treinamento, um de validação (opcional) e um de teste.
- O conjunto de dados de treinamento é usado para criar um modelo, Ao pesquisar por padrões nos dados de treinamento, vários algoritmos e parâmetros são tentados.
- Os padrões são identificados, e o conjunto de dados de validação é usado para testar os algoritmos e padrões. Aqueles que tiverem melhor desempenho são escolhidos entre os identificados durante o estágio de treinamento.
- Depois que os algoritmos e padrões de melhor desempenho forem identificados, eles serão testados quanto à taxa de erros, qualidade e acurácia usando o conjunto de dados de teste.
Tanto um conjunto de dados de validação quanto um de teste são usados para evitar vieses no modelo. Durante o estágio de validação, são usados os parâmetros ideais do modelo, o que pode resultar em métricas tendenciosas. Usar o conjunto de dados de teste para avaliar a qualidade do modelo após o estágio de validação fornece uma avaliação imparcial da qualidade.
Para identificar o conjunto de dados de treinamento e de teste, use arquivos CSV.
Criar arquivos CSV com URIs e rótulos de vídeo
Depois que seus arquivos forem enviados ao Cloud Storage, você poderá criar arquivos
CSV que listem todos os seus dados de treinamento e os rótulos de
categoria para esses dados. Os arquivos CSV podem ter qualquer nome de arquivo, precisam ser codificados em
UTF-8 e terminar com a extensão .csv.
Há três arquivos que podem ser usados para treinar e verificar seu modelo:
| File | Descrição |
|---|---|
| Lista de arquivos de treinamento de modelo | Contém caminhos para os arquivos CSV de treinamento e teste. Esse arquivo é usado para identificar os locais de arquivos CSV separados que descrevem os dados de treinamento e teste. Aqui estão alguns exemplos do conteúdo do arquivo CSV da lista de arquivos: Exemplo 1: TRAIN,gs://automl-video-demo-data/traffic_videos/traffic_videos_train.csv TEST,gs://automl-video-demo-data/traffic_videos/traffic_videos_test.csv Exemplo 2: UNASSIGNED,gs://automl-video-demo-data/traffic_videos/traffic_videos_labels.csv |
| Dados de treinamento | Usado para treinar o modelo. Contém URIs para arquivos de vídeo, o rótulo que identifica a categoria do objeto, o código da instância que identifica a instância do objeto em frames de vídeo em um vídeo (opcional), o ajuste de horário do frame de vídeo rotulado e as coordenadas da caixa delimitadora do objeto. Se você especificar um arquivo CSV de dados de treinamento, especifique também um arquivo CSV de dados de teste ou não atribuído. |
| Dados de teste | Usado para testar o modelo durante a fase de treinamento. Contém os mesmos campos dos dados de treinamento. Se você especificar um arquivo CSV de dados de teste, especifique também um arquivo CSV de dados de treinamento ou não atribuído. |
| Dados não atribuídos | Usado para treinar e testar o modelo. Contém os mesmos campos dos dados de treinamento. As linhas no arquivo não atribuído são automaticamente divididas em dados de treinamento e de teste, normalmente 80% para treinamento e 20% para testes. Você pode especificar apenas um arquivo CSV de dados não atribuído sem treinar e testar arquivos CSV de dados. Você também pode especificar apenas os arquivos CSV de dados de treinamento e teste sem um arquivo CSV de dados não atribuído. |
Os arquivos de treinamento, teste e não atribuídos precisam ter uma linha de uma caixa delimitadora do objeto que você está fazendo upload, com estas colunas em cada linha:
O conteúdo a ser categorizado ou anotado. Esse campo contém um URI do Cloud Storage para o vídeo. Esses URIs diferenciam maiúsculas de minúsculas.
Um rótulo que identifica como o objeto é categorizado. Os rótulos precisam começar com uma letra e conter apenas letras, números e sublinhado. O rastreamento de objetos do AutoML Video também permite usar rótulos com espaços em branco.
Um ID que identifica a instância do objeto em frames de um vídeo (opcional).. O ID da instância é um número inteiro. Se fornecido, ele será utilizado pelo rastreamento de objetos do AutoML Video Intelligence para ajuste, treinamento e avaliação de rastreamento de objetos. As caixas delimitadoras da mesma instância de objeto presente em frames de vídeo diferentes são rotuladas como o mesmo ID de instância. O ID da instância é único em cada vídeo, mas não no conjunto de dados. Por exemplo, se dois objetos de dois vídeos diferentes tiverem o mesmo ID de instância, isso não significa que eles são a mesma instância de objeto.
O ajuste de horário do frame de vídeo que indica o ajuste de duração desde o início do vídeo. O ajuste de horário é um número flutuante e as unidades estão em segundos.
Uma caixa delimitadora de um objeto no frame de vídeo. A caixa delimitadora de um objeto pode ser especificada de duas maneiras:
O uso de dois vértices que consistem em um conjunto de coordenadas x,y, se eles forem pontos diagonalmente opostos do retângulo, como mostrado neste exemplo:
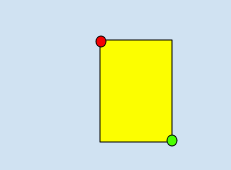
x_relative_min, y_relative_min,,,x_relative_max,y_relative_max,,
- Usando os quatro vértices:
x_relative_min,y_relative_min,x_relative_max,y_relative_min,x_relative_max,y_relative_max,x_relative_min,y_relative_max
Cada
vertexé especificado por valores de coordenadas x, y. Essas coordenadas precisam ser um float no intervalo de 0 a 1, em que 0 representa o valor mínimo de x ou y e 1 representa o maior valor de x ou y.Por exemplo, (0,0) representa o canto superior esquerdo e (1,1) representa o canto inferior direito. Uma caixa delimitadora da imagem inteira é expressa como (0,0,,,1,1,,) ou (0,0,1,0,1,1,0,1).
A API AutoML Video Object Tracking não requer uma ordem específica de vértices. Além disso, se quatro vértices especificados não formarem um retângulo paralelo às bordas da imagem, a API de rastreamento de objetos do AutoML Video especificará vértices que formam esse retângulo.
Exemplos de arquivos de conjunto de dados CSV
As linhas a seguir demonstram como especificar dados em um conjunto de dados. O exemplo inclui um caminho para um vídeo no Cloud Storage, um rótulo para o objeto, um ajuste de horário para começar o rastreamento e dois vértices diagonal.
video_uri,label,instance_id,time_offset,x_relative_min,y_relative_min, x_relative_max,y_relative_min,x_relative_max,y_relative_max,x_relative_min,y_relative_max
gs://folder/video1.avi,car,,12.90,0.8,0.2,,,0.9,0.3,,
gs://folder/video1.avi,bike,,12.50,0.45,0.45,,,0.55,0.55,,
onde, na primeira linha,
- VIDEO_URI é
gs://folder/video1.avi, - LABEL é
car, - INSTANCE_ID não especificado,
- TIME_OFFSET é
12.90, - X_RELATIVE_MIN,Y_RELATIVE_MIN são
0.8,0.2, - X_RELATIVE_MAX,Y_RELATIVE_MIN não especificado,
- X_RELATIVE_MAX,Y_RELATIVE_MAX são
0.9,0.3, - X_RELATIVE_MIN,Y_RELATIVE_MAX não são especificados
Conforme mencionado anteriormente, também é possível especificar as caixas delimitadoras fornecendo todos os quatro vértices, conforme mostrado nos exemplos a seguir.
gs://folder/video1.avi,car,,12.10,0.8,0.8,0.9,0.8,0.9,0.9,0.8,0.9
gs://folder/video1.avi,car,,12.90,0.4,0.8,0.5,0.8,0.5,0.9,0.4,0.9
gs://folder/video1.avi,car,,12.10,0.4,0.2,0.5,0.2,0.5,0.3,0.4,0.3
Não é necessário especificar os dados de validação para verificar os resultados do seu modelo de treinamento. O rastreamento de objetos do AutoML Video divide automaticamente as linhas identificadas para treinamento em dados de treinamento e validação, em que 80% é usado para treinamento e 20% para validação.
Como solucionar problemas de conjunto de dados CSV
Se você tiver problemas ao especificar o conjunto de dados usando um arquivo CSV, verifique a seguinte lista de erros comuns no arquivo CSV:
- Uso de caracteres unicode em rótulos. Por exemplo, caracteres japoneses não são compatíveis.
- Uso de espaços e caracteres não alfanuméricos em rótulos.
- Linhas vazias.
- Colunas vazias (linhas com duas vírgulas sucessivas).
- Uso incorreto de maiúsculas e minúsculas dos caminhos de vídeo do Cloud Storage.
- Controle de acesso incorreto configurado para os arquivos de vídeo. Sua conta de serviço precisa ter acesso de leitura ou maior ou os arquivos precisam ser legíveis publicamente.
- Referências a arquivos sem vídeo (como arquivos PDF ou PSD). Da mesma forma, arquivos que não são de vídeo, mas que forem renomeados com uma extensão de vídeo, causarão um erro.
- URI de pontos de vídeo para um bucket diferente do projeto atual. Somente vídeos no bucket do projeto podem ser acessados.
- Arquivos não formatados em CSV.