Preparazione dei dati di addestramento
Questa pagina descrive come preparare i dati per l'addestramento di un modello AutoML Video Object Tracking.
Preparazione dei video in corso...
Questa pagina descrive come preparare i dati di addestramento e di test in modo che AutoML Video Intelligence Object Tracking possa creare un modello di annotazione video per te.
Il monitoraggio degli oggetti AutoML Video Intelligence supporta i seguenti formati video per l'addestramento del modello o per la richiesta di previsione.
- .MOV
- .MPEG4
- MP4
- File AVI
La dimensione massima dei file per i video di formazione è 50 GB e può durare fino a 3 ore. Non sono supportati singoli file video con errori di formattazione o offset di tempo vuoti nel container.
I dati di addestramento dovrebbero essere il più possibile simili a quelli sui quali vuoi effettuare previsioni. Ad esempio, se il tuo caso d'uso prevede video sfocati e a bassa risoluzione (come quelli di una videocamera di sicurezza), i dati di addestramento devono essere composti da video sfocati e a bassa risoluzione. In generale, dovresti anche valutare la possibilità di fornire più angolazioni, risoluzioni e sfondi per i tuoi video di formazione.
In genere, i modelli di monitoraggio degli oggetti video AutoML non sono in grado di prevedere etichette che gli utenti non possono assegnare. Ad esempio, se non è possibile addestrare un essere umano ad assegnare etichette guardando il video per 1-2 secondi, è probabile che anche il modello non possa essere addestrato a farlo.
La dimensione minima del riquadro di delimitazione è 10 x 10 px.
Per una risoluzione del fotogramma video molto superiore a 1024 x 1024 pixel, è possibile che una parte della qualità dell'immagine vada persa durante il processo di normalizzazione dei fotogrammi utilizzato da AutoML Video Object Tracking.
I modelli funzionano meglio quando ci sono al massimo 100 volte più frame per l'etichetta più comune rispetto all'etichetta meno comune. Potresti rimuovere le etichette di frequenza molto bassa dai tuoi set di dati.
Ogni etichetta univoca deve essere presente in almeno tre fotogrammi video distinti. Inoltre, ogni etichetta deve avere almeno 10 annotazioni.
Il numero massimo di frame video etichettati in ogni set di dati è attualmente limitato a 150.000.
Il numero massimo di riquadri di delimitazione annotati in ogni set di dati è attualmente limitato a 1.000.000.
Il numero massimo di etichette univoche in ogni set di dati è attualmente limitato a 1000.
I dati di addestramento devono avere almeno un'etichetta.
Devi fornire almeno 100 frame video di addestramento per etichetta e in ogni frame tutti gli oggetti di interesse siano etichettati. Non è necessario etichettare tutti i frame in cui vengono visualizzati gli oggetti, ma più frame vengono etichettati, migliore sarà il modello. Ti consigliamo di scegliere fotogrammi non adiacenti tra loro in modo che possano coprire dimensioni, angolazione, sfondo, condizioni di illuminazione differenti e così via.
Set di dati per addestramento, convalida e test
Durante l'addestramento di un modello, i dati di un set di dati vengono suddivisi in tre set di dati: un set di dati di addestramento, un set di dati di convalida (facoltativo) e un set di dati di test.
- Per creare un modello viene utilizzato un set di dati di addestramento. Durante la ricerca di pattern nei dati di addestramento, vengono tentati più algoritmi e parametri.
- Man mano che i pattern vengono identificati, il set di dati di convalida viene utilizzato per testare gli algoritmi e i pattern. Gli algoritmi e i pattern con le prestazioni migliori vengono scelti tra quelli identificati durante la fase di addestramento.
- Una volta identificati, gli algoritmi e i pattern con le migliori prestazioni, vengono testati per il tasso di errore, la qualità e l'accuratezza utilizzando il set di dati di test.
Vengono utilizzati sia un set di dati di convalida che un set di dati di test per evitare bias nel modello. Durante la fase di convalida, vengono utilizzati parametri del modello ottimali, che possono generare metriche distorte. L'utilizzo del set di dati di test per valutare la qualità del modello dopo la fase di convalida fornisce una valutazione imparziale della qualità del modello.
Per identificare il set di dati di addestramento e test, utilizza i file CSV.
Creare file CSV con URI ed etichette dei video
Una volta caricati i file in Cloud Storage, puoi creare file CSV che elencano tutti i dati di addestramento e le etichette delle categorie per tali dati. I file CSV possono avere qualsiasi nome, avere la codifica UTF-8 e terminare con l'estensione .csv.
Esistono tre file che puoi utilizzare per l'addestramento e la verifica del modello:
| File | Descrizione |
|---|---|
| Elenco dei file di addestramento del modello | Contiene i percorsi dei file CSV di addestramento e test. Questo file viene utilizzato per identificare le posizioni dei file CSV separati che descrivono i dati di addestramento e test. Di seguito sono riportati alcuni esempi dei contenuti del file CSV con l'elenco dei file: Esempio 1: TRAIN,gs://automl-video-demo-data/traffic_videos/traffic_videos_train.csv TEST,gs://automl-video-demo-data/traffic_videos/traffic_videos_test.csv Esempio 2: UNASSIGNED,gs://automl-video-demo-data/traffic_videos/traffic_videos_labels.csv |
| Dati di addestramento | Utilizzato per addestrare il modello. Contiene gli URI dei file video, l'etichetta che identifica la categoria dell'oggetto, l'ID istanza che identifica l'istanza dell'oggetto nei frame video di un video (facoltativo), lo offset temporale del frame video etichettato e le coordinate del riquadro di delimitazione degli oggetti. Se specifichi un file CSV dei dati di addestramento, devi specificare anche un file CSV dei dati di test o non assegnato. |
| Dati di test | Utilizzato per testare il modello durante la fase di addestramento. Contiene gli stessi campi dei dati di addestramento. Se specifichi un file CSV dei dati di test, devi specificare anche un file CSV di addestramento o di dati non assegnati. |
| Dati non assegnati | Utilizzato sia per l'addestramento del modello sia per il test. Contiene gli stessi campi dei dati di addestramento. Le righe nel file non assegnato vengono suddivise automaticamente in dati di addestramento e test, in genere l'80% per l'addestramento e il 20% per i test. Puoi specificare solo un file CSV con i dati non assegnati senza file CSV dei dati di addestramento e test. Puoi anche specificare solo i file CSV dei dati di addestramento e test senza un file CSV dei dati non assegnato. |
I file di addestramento, test e non assegnati devono avere una riga di un riquadro di delimitazione degli oggetti nel set che stai caricando, con le seguenti colonne in ogni riga:
I contenuti da classificare o annotare. Questo campo contiene un URI Cloud Storage del video. Gli URI Cloud Storage sono sensibili alle maiuscole.
Un'etichetta che identifica il modo in cui viene classificato l'oggetto. Le etichette devono iniziare con una lettera e contenere solo lettere, numeri e trattini bassi. AutoML Video Object Tracking consente inoltre di usare etichette con spazi bianchi.
(Facoltativo) Un ID istanza che identifica l'istanza dell'oggetto nei vari frame video di un video. L'ID istanza è un numero intero. Se disponibile, AutoML Video Object Tracking utilizza l'ID per l'ottimizzazione, l'addestramento e la valutazione del monitoraggio degli oggetti. I riquadri di delimitazione della stessa istanza di oggetto presente in frame video diversi sono etichettati con lo stesso ID istanza. L'ID istanza è univoco solo in ogni video, ma non nel set di dati. Ad esempio, se due oggetti di due video diversi hanno lo stesso ID istanza, non significa che si tratti della stessa istanza di oggetto.
Lo offset temporale del fotogramma video che indica lo scarto della durata dall'inizio del video. Lo offset temporale è un numero mobile e le unità sono in secondi.
Un riquadro di delimitazione per un oggetto nel frame video Il riquadro di delimitazione per un oggetto può essere specificato in due modi:
Utilizzando 2 vertici costituiti da un insieme di coordinate x,y se sono punti diagonalmente opposti del rettangolo, come mostrato in questo esempio:
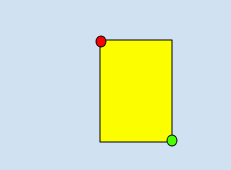
x_relative_min, y_relative_min,,,x_relative_max,y_relative_max,,
- Utilizza tutti e quattro i vertici:
x_relative_min,y_relative_min,x_relative_max,y_relative_min,x_relative_max,y_relative_max,x_relative_min,y_relative_max
Ogni
vertexè specificato da valori delle coordinate x e y. Queste coordinate devono essere un numero in virgola mobile compreso tra 0 e 1, dove 0 rappresenta il valore x o y minimo e 1 rappresenta il valore x o y massimo.Ad esempio, (0,0) rappresenta l'angolo in alto a sinistra e (1,1) rappresenta l'angolo in basso a destra; un riquadro di delimitazione per l'intera immagine è espresso come (0,0,,,1,1,) o (0,0,1,0,1,1,0,1).
L'API AutoML Video Object Tracking non richiede un ordinamento del vertice specifico. Inoltre, se quattro vertici specificati non formano un rettangolo parallelo ai bordi dell'immagine, l'API AutoML Video Object Tracking specifica i vertici che formano un rettangolo di questo tipo.
Esempi di file di set di dati CSV
Le seguenti righe mostrano come specificare i dati in un set di dati. L'esempio include un percorso di un video su Cloud Storage, un'etichetta per l'oggetto, un offset temporale per iniziare il monitoraggio e due vertici diagonali.
video_uri,label,instance_id,time_offset,x_relative_min,y_relative_min, x_relative_max,y_relative_min,x_relative_max,y_relative_max,x_relative_min,y_relative_max
gs://folder/video1.avi,car,,12.90,0.8,0.2,,,0.9,0.3,,
gs://folder/video1.avi,bike,,12.50,0.45,0.45,,,0.55,0.55,,
dove nella prima riga
- VIDEO_URI è
gs://folder/video1.avi, - LABEL è
car, - INSTANCE_ID non specificato,
- TIME_OFFSET è
12.90, - X_RELATIVE_MIN,Y_RELATIVE_MIN sono
0.8,0.2, - X_RELATIVE_MAX,Y_RELATIVE_MIN non specificato,
- X_RELATIVE_MAX,Y_RELATIVE_MAX sono
0.9,0.3, - X_RELATIVE_MIN,Y_RELATIVE_MAX non è specificato
Come indicato in precedenza, puoi anche specificare i riquadri di delimitazione fornendo tutti e quattro i vertici, come mostrato nei seguenti esempi.
gs://folder/video1.avi,car,,12.10,0.8,0.8,0.9,0.8,0.9,0.9,0.8,0.9
gs://folder/video1.avi,car,,12.90,0.4,0.8,0.5,0.8,0.5,0.9,0.4,0.9
gs://folder/video1.avi,car,,12.10,0.4,0.2,0.5,0.2,0.5,0.3,0.4,0.3
Non è necessario specificare dati di convalida per verificare i risultati del modello addestrato. AutoML Video Object Tracking suddivide automaticamente le righe identificate per l'addestramento nei dati di addestramento e convalida, dove l'80% viene utilizzato per l'addestramento e il 20% per la convalida.
Risoluzione dei problemi relativi ai set di dati CSV
Se hai problemi a specificare il set di dati utilizzando un file CSV, controlla se nel file CSV è presente il seguente elenco di errori comuni:
- Utilizzo di caratteri Unicode nelle etichette. Ad esempio, i caratteri giapponesi non sono supportati.
- Uso di spazi e caratteri non alfanumerici nelle etichette
- Righe vuote
- Colonne vuote (righe con due virgole successive)
- Uso errato delle lettere maiuscole nei percorsi video di Cloud Storage
- Controllo dell'accesso non corretto configurato per i tuoi file video. L'account di servizio deve avere un accesso in lettura o superiore oppure i file devono essere leggibili pubblicamente.
- Riferimenti a file non video (ad esempio file PDF o PSD). Analogamente, i file che non sono file video, ma che sono stati rinominati con un'estensione video, causeranno un errore.
- L'URI del video rimanda a un bucket diverso da quello del progetto corrente. È possibile accedere solo ai video nel bucket del progetto.
- File non in formato CSV.