Introducción
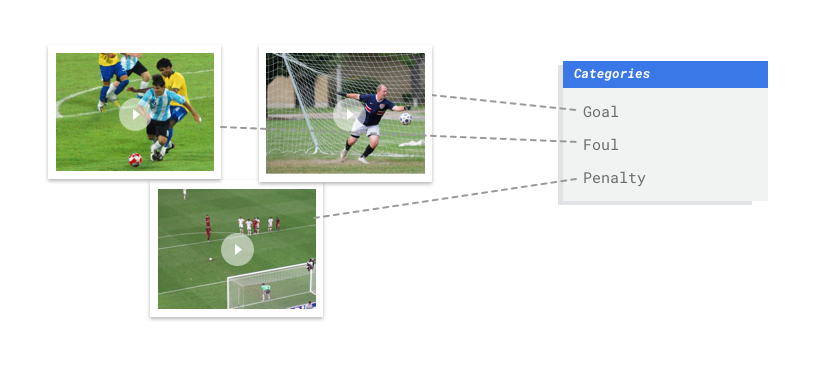
Imagina que eres el entrenador de un equipo de fútbol. Tienes una gran biblioteca de videos de juegos que te gustaría usar para estudiar las fortalezas y debilidades de tu equipo. Sería increíblemente útil compilar en un solo video acciones como goles, faltas y penales de muchos partidos. Pero hay cientos de horas de video para revisar y muchas acciones a las que hacer un seguimiento. El trabajo de mirar cada video y marcar los segmentos de forma manual para destacar cada acción es tedioso y lleva mucho tiempo. Y deberás hacer este trabajo para cada temporada. ¿No sería más fácil enseñarle a una computadora a identificar y marcar estas acciones automáticamente cada vez que aparecen en un video?
¿Por qué el aprendizaje automático (AA) es la herramienta correcta para este problema?
 La programación clásica requiere que un programador especifique las instrucciones paso por paso para que una computadora las siga. Sin embargo, considera el caso de uso para identificar acciones específicas en los partidos de fútbol. Hay tanta variación en el color, el ángulo, la resolución y la iluminación que requeriría codificar demasiadas reglas para indicarle a una máquina cómo tomar la decisión correcta. Es difícil imaginar dónde empezarías.
Por suerte, el aprendizaje automático está bien posicionado para resolver este problema.
La programación clásica requiere que un programador especifique las instrucciones paso por paso para que una computadora las siga. Sin embargo, considera el caso de uso para identificar acciones específicas en los partidos de fútbol. Hay tanta variación en el color, el ángulo, la resolución y la iluminación que requeriría codificar demasiadas reglas para indicarle a una máquina cómo tomar la decisión correcta. Es difícil imaginar dónde empezarías.
Por suerte, el aprendizaje automático está bien posicionado para resolver este problema.
En esta guía, se explica cómo AutoML Video Intelligence Classification puede resolver este problema, su flujo de trabajo y los demás tipos de problemas que diseñó.
¿Cómo funciona AutoML Video Intelligence Classification?
 La clasificación de AutoML Video Intelligence es una tarea de aprendizaje supervisado. Esto significa que debes entrenar, probar y validar el modelo de aprendizaje automático con videos de ejemplo que ya están etiquetados. Con un modelo entrenado, puedes ingresar videos nuevos y
el modelo generará segmentos de video con etiquetas. Una etiqueta es una “respuesta”
predicha del modelo. Por ejemplo, un modelo entrenado para el caso de uso del fútbol te permitiría ingresar nuevos videos de fútbol y generar segmentos de video con etiquetas que describan tomas de acción como "gol", "falta personal", etcétera.
La clasificación de AutoML Video Intelligence es una tarea de aprendizaje supervisado. Esto significa que debes entrenar, probar y validar el modelo de aprendizaje automático con videos de ejemplo que ya están etiquetados. Con un modelo entrenado, puedes ingresar videos nuevos y
el modelo generará segmentos de video con etiquetas. Una etiqueta es una “respuesta”
predicha del modelo. Por ejemplo, un modelo entrenado para el caso de uso del fútbol te permitiría ingresar nuevos videos de fútbol y generar segmentos de video con etiquetas que describan tomas de acción como "gol", "falta personal", etcétera.
Flujo de trabajo de AutoML Video Intelligence Classification
AutoML Video Intelligence Classification usa un flujo de trabajo de aprendizaje automático estándar:
- Reúne tus datos: Determina los datos que necesitas para entrenar y probar tu modelo en función del resultado que quieres lograr.
- Prepara tus datos: Asegúrate de que los datos tengan el formato y las etiquetas correctas.
- Entrena: Configura los parámetros y crea tu modelo.
- Evalúa: Revisa las métricas del modelo.
- Implementa y predice: Haz que tu modelo esté disponible para su uso.
Sin embargo, antes de comenzar a recopilar datos, debes pensar en el problema que está tratando de resolver, lo que definirá los requisitos de datos.
Considera tu caso práctico

Comienza con tu problema: ¿cuál es el resultado que quieres obtener? ¿Cuántas clases necesitas predecir? Una clase es algo que quieres que tu modelo aprenda a identificar y se represente en su resultado como una etiqueta (por ejemplo, un modelo de detección de bolas tendrá dos clases: “bola” y “sin pelota”).
Según tus respuestas, AutoML Video Intelligence Classification creará el modelo necesario para resolver tu caso de uso:
Los modelos de clasificación binaria predicen un resultado binario (una de dos clases). Úsalo para preguntas de sí o no; por ejemplo, para identificar solo goles en un partido de fútbol ("¿Es un gol o no un gol?"). En general, un problema de clasificación binaria requiere menos datos de video para entrenarse que otros problemas.
Un modelo de clasificación de clases múltiples predice una clase de dos o más clases discretas. Úsalo para categorizar segmentos de video. Por ejemplo, puedes clasificar segmentos de una biblioteca de videos de los Juegos Olímpicos para descubrir qué deporte se muestra en un momento determinado. El resultado proporciona segmentos de video a los que se les asignó una sola etiqueta, como natación o gimnasia.
Un modelo de clasificación de varias etiquetas predice una o más clases de muchas clases posibles. Usa este modelo para etiquetar varias clases en un solo segmento de video. Este tipo de problema suele requerir más datos de entrenamiento, ya que la distinción entre muchas clases es más compleja.
El ejemplo de fútbol anterior requeriría un modo de clasificación con varias etiquetas, ya que las clases (acciones como goles, faltas personales, etc.) pueden ocurrir simultáneamente, lo que significa que un solo segmento de video puede requerir varias etiquetas.
Una aclaración sobre la equidad
La equidad es una de las prácticas responsables de la IA de Google. Su objetivo es comprender y evitar un tratamiento injusto o prejuicioso de las personas en relación con sus ingresos, su origen étnico, orientación sexual, religión, género y otras características asociadas históricamente con la discriminación y la exclusión en el lugar y momento en el que se manifiesten en los sistemas algorítmicos o en la toma de decisiones basada en algoritmos. A medida que leas esta guía, verás notas sobre “Imparcialidad” que tratan sobre cómo crear un modelo de aprendizaje automático más justo. Más información
Recopila tus datos
 Después de establecer tu caso de uso, deberás recopilar los datos de video que
te permitirán crear el modelo que deseas. Los datos que recopilas para el entrenamiento indican el tipo de problemas que puedes resolver. ¿Cuántos videos puedes usar? ¿Contienen los videos suficientes ejemplos de las clases que quieres que prediga tu modelo? Cuando recopiles los datos de tus videos, ten en cuenta las siguientes consideraciones.
Después de establecer tu caso de uso, deberás recopilar los datos de video que
te permitirán crear el modelo que deseas. Los datos que recopilas para el entrenamiento indican el tipo de problemas que puedes resolver. ¿Cuántos videos puedes usar? ¿Contienen los videos suficientes ejemplos de las clases que quieres que prediga tu modelo? Cuando recopiles los datos de tus videos, ten en cuenta las siguientes consideraciones.
Incluye suficientes videos
 Por lo general, cuantos más videos de entrenamiento haya en tu conjunto de datos, mejor será el resultado. La cantidad de videos recomendados también aumenta debido a la complejidad del problema que intentas resolver. Por ejemplo, necesitarás menos datos de video para un problema de clasificación binaria (predecir una clase de dos) que un problema con varias etiquetas (predecir una o más clases a partir de varias).
Por lo general, cuantos más videos de entrenamiento haya en tu conjunto de datos, mejor será el resultado. La cantidad de videos recomendados también aumenta debido a la complejidad del problema que intentas resolver. Por ejemplo, necesitarás menos datos de video para un problema de clasificación binaria (predecir una clase de dos) que un problema con varias etiquetas (predecir una o más clases a partir de varias).
La complejidad de lo que intentas clasificar también puede determinar la cantidad de datos de video que necesitas. Considera el caso de uso del fútbol, que consiste en crear un modelo para distinguir tomas de acción. Compara eso con un modelo que distingue las especies de colibrí. Ten en cuenta los matices y las similitudes de color, tamaño y forma: se necesitarían más datos de entrenamiento para que el modelo aprenda a identificar con precisión cada especie.
Usa estas reglas como referencia para comprender tus necesidades mínimas de datos de video:
- 200 ejemplos de video por clase si tienes pocas clases y se distinguen
- Más de 1,000 ejemplos de videos por clase si tienes más de 50 clases o si son similares entre sí
Es posible que la cantidad de datos de video requeridos sea superior a la que tienes actualmente. Considera obtener más videos a través de un proveedor externo. Por ejemplo, puedes comprar, o bien obtener más videos de fútbol, si no tienes suficientes para tu modelo de identificador de acciones del juego.
Distribuye videos de forma equitativa en todas las clases
Intenta proporcionar una cantidad similar de ejemplos de entrenamiento a cada clase. Este es el motivo: Imagina que el 80% de tu conjunto de datos de entrenamiento son videos de fútbol con tiros de goles, pero solo el 20% de los videos muestran faltas personales o penales. Con una distribución de clases tan desigual, es más probable que el modelo prediga que una acción determinada es un objetivo. Es similar a escribir una prueba de opción múltiple en la que el 80% de las respuestas correctas son “C”: el modelo inteligente sabrá rápidamente que “C” es una buena suposición la mayor parte del tiempo.

Es posible que no puedas obtener la misma cantidad de videos para cada clase. Los ejemplos imparciales y de alta calidad también pueden ser difíciles para algunas clases. Intenta mantener una proporción de 1:10: si la clase más grande tiene 10,000 videos, la clase más pequeña debe tener al menos 1,000 videos.
Abarca la variedad
Los datos de tus videos deben capturar la diversidad del espacio del problema. Cuanto más diversos sean los ejemplos que ve un modelo durante el entrenamiento, con mayor facilidad podrá generalizar ejemplos nuevos o no tan comunes. Piensa en el modelo de clasificación de acciones de fútbol: Se recomienda que incluyas videos con una variedad de ángulos de cámara y horarios de día y noche, y distintos movimientos de los jugadores. Exponer el modelo a una variedad de datos mejorará la capacidad de su modelo para distinguir una acción de otra.
Hace coincidir los datos con el resultado deseado

Encuentra videos de entrenamiento que sean visualmente similares a los videos que planeas ingresar en el modelo para la predicción. Por ejemplo, si todos tus videos de entrenamiento se graban en invierno o en la noche, los patrones de iluminación y color de esos entornos afectarán a tu modelo. Si luego usas ese modelo para probar videos grabados en verano o de día, es posible que no recibas predicciones precisas.
Considera estos factores adicionales: * Resolución de video * Fotogramas por video * Ángulo de la cámara * Fondo
Prepara los datos

Después de recopilar los videos que deseas incluir en tu conjunto de datos, debes asegurarte de que contengan cuadros de límite con etiquetas para que el modelo sepa qué buscar.
¿Por qué mis videos necesitan cuadros de límite y etiquetas?
¿Cómo aprende un modelo de clasificación de AutoML Video Intelligence a identificar patrones? Eso es lo que hacen los cuadros de límite y las etiquetas durante el entrenamiento. Tomemos el ejemplo del fútbol: cada ejemplo de video deberá contener cuadros delimitadores alrededor de los golpes de acción. Esos cuadros también necesitan etiquetas como "objetivo", "falta personal" y "patada penal" que se les asigne. De lo contrario, el modelo no sabrá qué debe buscar. Dibujar cuadros y asignar etiquetas a tus videos de ejemplo puede llevar tiempo. Si es necesario, considera usar un servicio de etiquetado para subcontratar el trabajo a otras personas.
Entrene su modelo
Después de preparar los datos del video de entrenamiento, está todo listo para crear un modelo de aprendizaje automático. Ten en cuenta que puedes usar el mismo conjunto de datos para crear diferentes modelos de aprendizaje automático, incluso si tienen diferentes tipos de problemas.
Uno de los beneficios de AutoML Video Intelligence Classification es que los parámetros predeterminados te guiarán a un modelo de aprendizaje automático confiable. Sin embargo, es posible que debas ajustar los parámetros según la calidad de tus datos y el resultado que buscas. Por ejemplo:
- Tipo de predicción (el nivel de detalle con el que se procesan tus videos)
- Velocidad de fotogramas
- Solución
Evalúa tu modelo
 Después del entrenamiento del modelo, recibirás un resumen sobre el rendimiento. Las métricas de evaluación del modelo se basan en cómo se desempeñó ante una porción de tu conjunto de datos (el conjunto de datos de prueba). Hay algunas métricas y conceptos clave que debes tener en cuenta a fin de determinar si tu modelo está listo para usarse con datos reales.
Después del entrenamiento del modelo, recibirás un resumen sobre el rendimiento. Las métricas de evaluación del modelo se basan en cómo se desempeñó ante una porción de tu conjunto de datos (el conjunto de datos de prueba). Hay algunas métricas y conceptos clave que debes tener en cuenta a fin de determinar si tu modelo está listo para usarse con datos reales.
Umbral de puntuación
¿Cómo sabe un modelo de aprendizaje automático cuando un gol de fútbol es realmente un gol? A cada predicción se le asigna una puntuación de confianza, es decir, una evaluación numérica de la certeza del modelo de que un segmento de video determinado contenga una clase. El umbral de puntuación es el número que determina cuándo una puntuación determinada se convierte en una decisión de sí o no; es decir, el valor en el que tu modelo dice “sí, este número de confianza es lo suficientemente alto como para concluir que este segmento del video contiene un objetivo”.

Si tu umbral de puntuación es bajo, tu modelo correrá el riesgo de etiquetar de forma incorrecta los segmentos de video. Por ese motivo, el umbral de puntuación debe basarse en un caso práctico determinado. Imagina un caso de uso médico, como la detección de cáncer, en el que las consecuencias de un etiquetado incorrecto son más altas que las de un etiquetado incorrecto de videos de deportes. En la detección del cáncer, es apropiado tener un umbral de puntuación más alto.
Resultados de la predicción
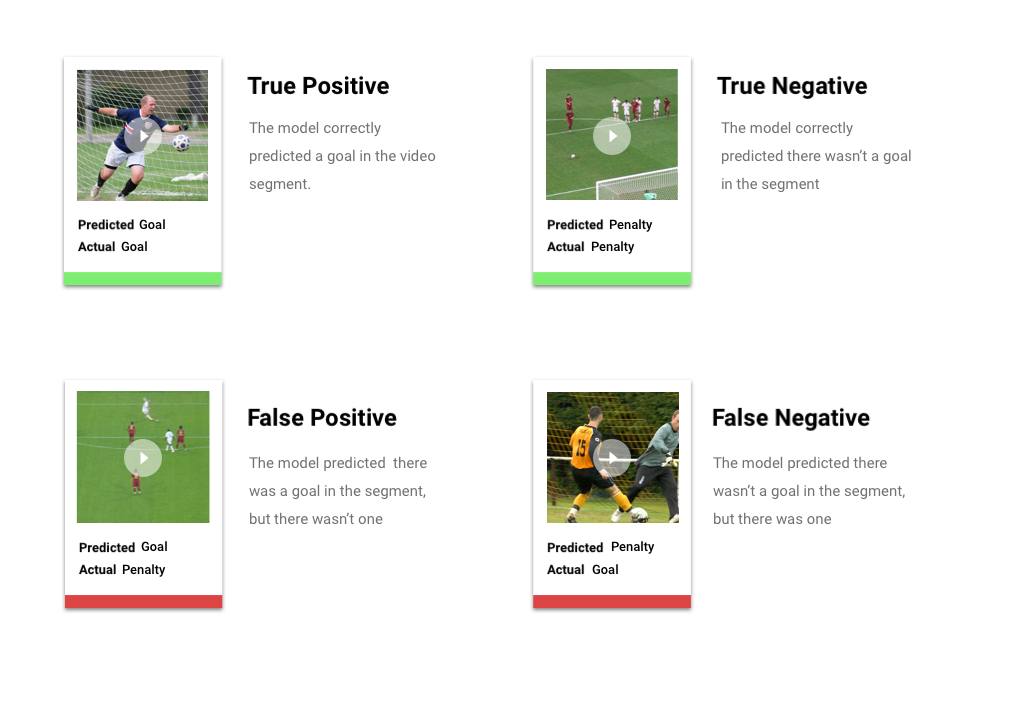
Después de aplicar el umbral de puntuación, las predicciones que realice tu modelo se clasificarán en una de cuatro categorías. Para comprender estas categorías, imaginemos que compilaste un modelo que detecta si un segmento determinado contiene (o no) un gol de fútbol. En este ejemplo, un objetivo es la clase positiva (lo que el modelo intenta predecir).
- Verdadero positivo: El modelo predice la clase positiva de forma correcta. El modelo predijo correctamente un objetivo en el segmento del video.
- Falso positivo: El modelo predice la clase positiva de forma incorrecta. El modelo predijo que un objetivo estaba en el segmento, pero no había uno.
- Verdadero negativo: El modelo predice la clase negativa de forma correcta. El modelo predijo correctamente que no había un objetivo en el segmento.
- Falso negativo: El modelo predice una clase negativa de forma incorrecta. El modelo predijo que no había un objetivo en el segmento, pero había uno.
Precisión y recuperación
Las métricas de precisión y recuperación te ayudan a comprender qué tan bien tu modelo capta información y qué omite. Obtén más información sobre precisión y recuperación
- La precisión es la fracción correcta de las predicciones positivas. De todas las predicciones etiquetadas como “objetivo”, ¿qué fracción contenía realmente un objetivo?
- La recuperación es la fracción de todas las predicciones positivas que se identificaron realmente. De todos los goles de fútbol que se pudieron haber identificado, ¿qué fracción se hizo?
Según el caso práctico, es posible que debas optimizar la precisión o la recuperación. Considera los siguientes casos prácticos.
Caso de uso: Información privada en los videos
Imagina que estás compilando un software que detecta automáticamente información sensible en un video y la desenfoca. Las ramificaciones de los resultados falsos pueden incluir lo siguiente:
- Un falso positivo identifica algo que no debe censurarse, pero que sí se censura de todos modos. Esto puede ser molesto, pero no perjudicial.

- Un falso negativo no identifica la información que se debe censurar, como el número de una tarjeta de crédito. Esto liberaría información privada y es el peor de los casos.
En este caso de uso, es fundamental optimizar la recuperación para garantizar que el modelo encuentre todos los casos relevantes. Es más probable que un modelo optimizado para la recuperación etiquete ejemplos marginalmente relevantes, pero también que etiquete los incorrectos (desenfoque más de lo necesario).
Caso de uso: Búsqueda de videos en stock
Supongamos que quieres crear un software que permita a los usuarios buscar en una biblioteca de videos a partir de una palabra clave. Consideremos los resultados incorrectos:
- Un falso positivo muestra un video irrelevante. Como el sistema intenta proporcionar solo videos relevantes, el software no realiza las tareas necesarias.

- Un falso negativo falla en mostrar un video relevante. Debido a que muchas palabras clave tienen cientos de videos, este problema no es negativo como mostrar un video irrelevante.

En este ejemplo, deberás optimizar la precisión para asegurarte de que tu modelo entregue resultados correctos y muy relevantes. Es probable que un modelo de alta precisión etiquete solo los ejemplos más relevantes, pero puede omitir algunos. Obtén más información sobre las métricas de evaluación del modelo.
Implementa tu modelo
 Cuando estés conforme con el rendimiento de tu modelo, será hora de usarlo.
AutoML Video Intelligence Classification usa la predicción por lotes, que te permite subir un archivo CSV con rutas de acceso a archivos de videos alojados en Cloud Storage. Tu modelo procesará cada video y generará predicciones en otro archivo CSV. La predicción por lotes es asíncrona, lo que significa que el modelo procesará todas las solicitudes de predicción primero antes de generar los resultados.
Cuando estés conforme con el rendimiento de tu modelo, será hora de usarlo.
AutoML Video Intelligence Classification usa la predicción por lotes, que te permite subir un archivo CSV con rutas de acceso a archivos de videos alojados en Cloud Storage. Tu modelo procesará cada video y generará predicciones en otro archivo CSV. La predicción por lotes es asíncrona, lo que significa que el modelo procesará todas las solicitudes de predicción primero antes de generar los resultados.