En las siguientes secciones, se proporciona información sobre los requisitos de datos, los archivos de esquema y el formato de los archivos de importación de datos (JSON y CSV) que define el esquema.
Como alternativa, puedes importar videos que no se anotaron y anotarlos más tarde con la consola de Google Cloud (consulta Etiqueta con la consola de Google Cloud).
Requisitos de los datos
Los siguientes requisitos se aplican a los conjuntos de datos usados para entrenar modelos de AutoML o modelos personalizados.
Vertex AI admite los siguientes formatos de video para entrenar tu modelo o solicitar una predicción (anotar un video).
- MOV
- .MPEG4
- .MP4
- .AVI
Para ver el contenido del video en la consola web o anotar un video, el video debe estar en un formato compatible con tu navegador de forma nativa. Debido a que no todos los navegadores administran contenido .MOV o .AVI de forma nativa, la recomendación es usar el formato de video .MPEG4 o .MP4.
El tamaño máximo del archivo es de 50 GB (hasta 3 horas de duración). No se admiten archivos de video individuales con marcas de tiempo incorrectas o con formato incorrecto en el contenedor.
La cantidad máxima de etiquetas en cada conjunto de datos está limitada a 1,000.
Puedes asignar etiquetas “ML_USE” a los videos en los archivos de importación. En el entrenamiento, puedes usar esas etiquetas para dividir los videos y sus anotaciones correspondientes en conjuntos de “entrenamiento” o “prueba”. Para el seguimiento de objetos de video, ten en cuenta lo siguiente:
- La cantidad máxima de marcos de video etiquetados en cada conjunto de datos está limitada a 150,000.
- La cantidad máxima de cuadros delimitadores anotados en cada conjunto de datos está limitada a 1,000,000.
- La cantidad máxima de etiquetas en cada conjunto de anotaciones está limitada a 1,000.
Prácticas recomendadas para los datos de video que se usan a fin de entrenar los modelos de AutoML
Los siguientes requisitos se aplican a los conjuntos de datos que se usan para entrenar modelos de AutoML.
Los datos de entrenamiento deben ser lo más parecidos posible a los datos sobre los que se harán las predicciones. Por ejemplo, si tu caso práctico incluye videos borrosos y de baja resolución (como los de una cámara de seguridad), los datos de entrenamiento deben estar compuestos por videos borrosos y de baja resolución. En general, también deberías tratar de proporcionar videos de entrenamiento con múltiples ángulos, resoluciones y fondos.
Por lo general, los modelos de Vertex AI no pueden predecir las etiquetas que las personas no pueden asignar. Por lo tanto, si no se puede entrenar a una persona para que asigne etiquetas con tan solo mirar el video durante 1 o 2 segundos, es probable que tampoco se pueda entrenar al modelo para que lo haga.
El modelo funciona mejor cuando hay como máximo 100 veces más videos para la etiqueta más común que para la etiqueta menos común. Recomendamos quitar etiquetas de baja frecuencia. Para el seguimiento de objetos, haz lo siguiente:
- El tamaño mínimo del cuadro de límite es de 10 x 10 píxeles.
- Para una resolución de fotogramas de video mucho mayor que 1024 píxeles por 1024 píxeles, puede perderse parte de la calidad de imagen durante el proceso de normalización de fotogramas que usa la detección de objetos de AutoML.
- Cada etiqueta única debe estar presente en, al menos, tres marcos de video distintos. Además, cada etiqueta también debe tener un mínimo de diez anotaciones.
Archivos de esquema
Usa el siguiente archivo de esquema de acceso público cuando crees el archivo de jsonl para importar anotaciones. Este archivo de esquema dicta el formato de los archivos de entrada de datos. La estructura del archivo sigue la prueba de esquema de OpenAPI.
Archivo del esquema de seguimiento de objetos:
gs://google-cloud-aiplatform/schema/dataset/ioformat/object_tracking_io_format_1.0.0.yaml
Archivo del esquema completo
title: VideoObjectTracking version: 1.0.0 description: > Import and export format for importing/exporting videos together with temporal bounding box annotations. type: object required: - videoGcsUri properties: videoGcsUri: type: string description: > A Cloud Storage URI pointing to a video. Up to 50 GB in size and up to 3 hours in duration. Supported file mime types: `video/mp4`, `video/avi`, `video/quicktime`. TemporalBoundingBoxAnnotations: type: array description: Multiple temporal bounding box annotations. Each on a frame of the video. items: type: object description: > Temporal bounding box anntoation on video. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the video frame size, and the point 0,0 is in the top left of the frame. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e., the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double timeOffset: type: string description: > A time offset of a video in which the object has been detected. Expressed as a number of seconds as measured from the start of the video, with fractions up to a microsecond precision, and with "s" appended at the end. instanceId: type: number format: integer description: > The instance of the object, expressed as a positive integer. Used to tell apart objects of the same type when multiple are present on a single video. annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
Archivos de entrada
El formato de los datos de entrenamiento para el seguimiento de objetos de video es el siguiente.
Para importar tus datos, crea un archivo JSONL o CSV.
JSONL
JSON en cada línea:
Consulta el archivo yaml de seguimiento de objetos para obtener más detalles.
{
"videoGcsUri": "gs://bucket/filename.ext",
"TemporalBoundingBoxAnnotations": [{
"displayName": "LABEL",
"xMin": "leftmost_coordinate_of_the_bounding box",
"xMax": "rightmost_coordinate_of_the_bounding box",
"yMin": "topmost_coordinate_of_the_bounding box",
"yMax": "bottommost_coordinate_of_the_bounding box",
"timeOffset": "timeframe_object-detected"
"instanceId": "instance_of_object
"annotationResourceLabels": "resource_labels"
}],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "train|test"
}
}JSONL de ejemplo - Seguimiento de objeto de video:
{'videoGcsUri': 'gs://demo-data/video1.mp4', 'temporal_bounding_box_annotations': [{'displayName': 'horse', 'instance_id': '-1', 'time_offset': '4.000000s', 'xMin': '0.668912', 'yMin': '0.560642', 'xMax': '1.000000', 'yMax': '1.000000'}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{'videoGcsUri': 'gs://demo-data/video2.mp4', 'temporal_bounding_box_annotations': [{'displayName': 'horse', 'instance_id': '-1', 'time_offset': '71.000000s', 'xMin': '0.679056', 'yMin': '0.070957', 'xMax': '0.801716', 'yMax': '0.290358'}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
...CSV
Formato de una fila en el archivo CSV:
[ML_USE,]VIDEO_URI,LABEL,[INSTANCE_ID],TIME_OFFSET,BOUNDING_BOX
Lista de columnas
ML_USE(opcional). Para la división de datos con el entrenamiento de un modelo. Usa TRAINING o TEST.VIDEO_URI. Este campo contiene un URI de Cloud Storage para el video. Los URI de Cloud Storage distinguen entre mayúsculas y minúsculas.LABEL. Las etiquetas deben comenzar con una letra y solo deben contener letras, números y guiones bajos. Si quieres especificar múltiples etiquetas para un video, agrega múltiples filas en el archivo CSV que identifiquen el mismo segmento de video con una etiqueta diferente para cada fila.INSTANCE_ID(opcional). Un ID de instancia que identifica la instancia de objeto entre los fotogramas de video en un video. Si se proporciona, el seguimiento de objetos de AutoML los usa para ajustar, entrenar y evaluar el seguimiento de objetos. Los cuadros de límite de la misma instancia de objeto presente en diferentes fotogramas de video están etiquetados como el mismo ID de instancia. El ID de instancia es único en cada video, pero no en el conjunto de datos. Por ejemplo, si dos objetos de dos videos diferentes tienen el mismo ID de instancia, no significa que sean la misma instancia de objeto.TIME_OFFSET. El marco del video que indica el desplazamiento de duración desde el principio del video. La compensación de tiempo es un número de punto flotante y las unidades están en segundos.BOUNDING_BOXUn cuadro de límite de un objeto en el marco de video. La especificación de un cuadro de límite involucra más de una columna.
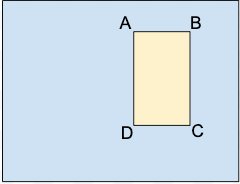
A.x_relative_min,y_relative_min
B.x_relative_max,y_relative_min
C.x_relative_max,y_relative_max
D.x_relative_min,y_relative_max
Cada vértice se especifica mediante valores de coordenadas x, y. Los valores de coordenadas deben ser un número de punto flotante en el rango del 0 al 1, en el que 0 representa el valor mínimo de x o y, y 1 el máximo.
Por ejemplo, (0,0) representa la esquina superior izquierda, y (1,1) representa la esquina inferior derecha; un cuadro de límite para toda la imagen se expresa como (0,0,,,1,1,,) o (0,0,1,0,1,1,0,1).
El seguimiento de objetos de AutoML no requiere un orden específico de vértices. Además, si cuatro vértices especificados no forman un rectángulo paralelo a los vértices de la imagen, Vertex AI especifica los vértices que forman ese rectángulo.
El cuadro de límite de un objeto se puede especificar de las siguientes dos maneras:- Dos vértices especificados que consisten en un conjunto de coordenadas x,y si son puntos diagonalmente opuestos del rectángulo:
A.x_relative_min,y_relative_min
C.x_relative_max,y_relative_max
como se muestra en este ejemplo:
x_relative_min, y_relative_min,,,x_relative_max,y_relative_max,, - Los cuatro vértices especificados como se muestra en:
x_relative_min,y_relative_min, x_relative_max,y_relative_min, x_relative_max,y_relative_max, x_relative_min,y_relative_max,
Si los cuatro vértices especificados no forman un rectángulo paralelo a las aristas de la imagen, Vertex AI especifica los vértices que forman ese rectángulo.
- Dos vértices especificados que consisten en un conjunto de coordenadas x,y si son puntos diagonalmente opuestos del rectángulo:
Ejemplos de filas en archivos del conjunto de datos
En las siguientes filas, se muestra cómo especificar datos en un conjunto de datos. El ejemplo incluye una ruta de acceso a un video en Cloud Storage, una etiqueta para el objeto, una compensación de tiempo para iniciar el seguimiento y dos vértices diagonales.
VIDEO_URI.,LABEL,INSTANCE_ID,TIME_OFFSET,x_relative_min,y_relative_min,x_relative_max,y_relative_min,x_relative_max,y_relative_max,x_relative_min,y_relative_max
gs://folder/video1.avi,car,,12.90,0.8,0.2,,,0.9,0.3,,
gs://folder/video1.avi,bike,,12.50,0.45,0.45,,,0.55,0.55,,
donde,
- VIDEO_URI es
gs://folder/video1.avi, - LABEL es
car, - INSTANCE_ID, (no especificado)
- TIME_OFFSET es
12.90, - x_relative_min,y_relative_min son
0.8,0.2, - x_relative_max,y_relative_min no especificado,
- x_relative_max,y_relative_max son
0.9,0.3, - x_relative_min,y_relative_max no se especificaron
Como se mencionó antes, también puedes especificar los cuadros de límite proporcionando los cuatro vértices, como se muestra en los siguientes ejemplos.
gs://folder/video1.avi,car,,12.10,0.8,0.8,0.9,0.8,0.9,0.9,0.8,0.9
gs://folder/video1.avi,car,,12.90,0.4,0.8,0.5,0.8,0.5,0.9,0.4,0.9
gs://folder/video1.avi,car,,12.10,0.4,0.2,0.5,0.2,0.5,0.3,0.4,0.3
Ejemplo de CSV - Sin etiquetas:
También puedes proporcionar videos en el archivo de datos CSV sin especificar ninguna etiqueta. Luego, debes usar la consola de Google Cloud para aplicar etiquetas a tus datos antes de entrenar el modelo. Si quieres hacerlo, solo debes proporcionar el URI de Cloud Storage para el video seguido de once comas, como se muestra en el siguiente ejemplo.
Ejemplo sin asignar ml_use:
gs://folder/video1.avi ...
Ejemplo con ml_use asignado:
TRAINING,gs://folder/video1.avi TEST,gs://folder/video2.avi ...