Use o Console do Google Cloud para verificar o desempenho do modelo. Analise erros de teste para melhorar a qualidade do modelo de forma iterativa corrigindo problemas de dados.
Este tutorial tem várias páginas:
Criar um conjunto de dados de classificação de imagens e importar as imagens.
Avaliar e analisar o desempenho do modelo.
Cada página pressupõe que você já tenha realizado as instruções das páginas anteriores do tutorial.
1. Entenda os resultados da avaliação do modelo do AutoML
Após a conclusão do treinamento, o modelo é avaliado automaticamente em relação à divisão de dados de teste. Os resultados da avaliação correspondentes são apresentados clicando no nome do modelo na página Model Registry ou na página Dataset.
A partir daí, é possível encontrar as métricas para medir o desempenho do modelo.
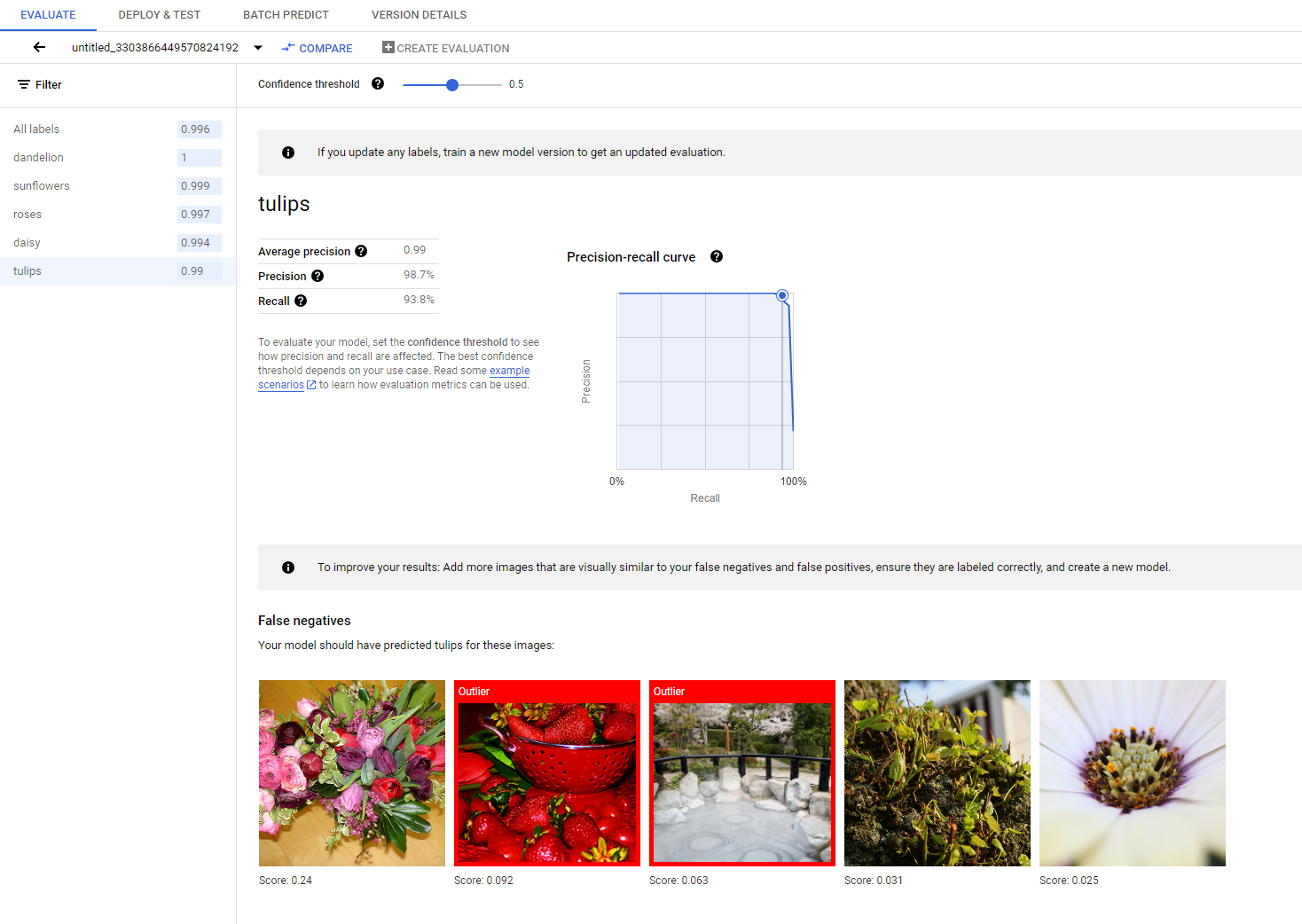
Veja uma introdução mais detalhada a diferentes métricas de avaliação na seção Avaliar, testar e implantar o modelo.
2. Analisar os resultados do teste
Se você quiser continuar melhorando o desempenho do modelo, a primeira etapa geralmente será examinar os casos de erro e investigar as potenciais causas. A página de avaliação de cada classe apresenta imagens de teste detalhadas da classe especificada, categorizadas como falsos negativos, falsos positivos e verdadeiros positivos. A definição de cada categoria pode ser encontrada na seção Avaliar, testar e implantar o modelo.
Para cada imagem em cada categoria, é possível verificar melhor os detalhes da previsão clicando na imagem e acessando os resultados detalhados da análise. Você verá o painel Revisar imagens semelhantes no lado direito da página, onde as amostras mais próximas do conjunto de treinamento são apresentadas com distâncias medidas no espaço do recurso.
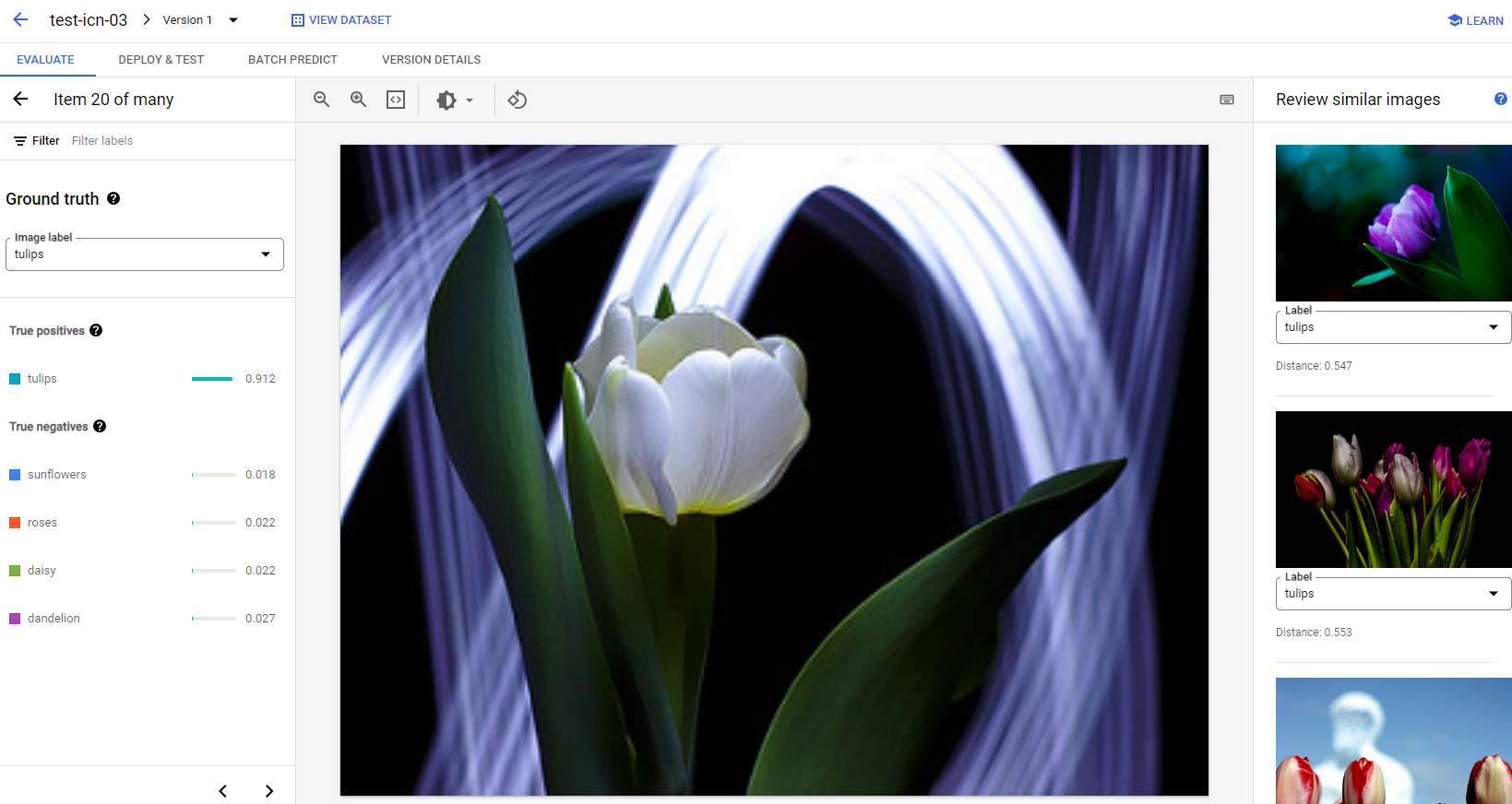
Há dois tipos de problemas de dados que merecem atenção:
Inconsistência do rótulo. Se uma amostra visualmente semelhante do conjunto de treinamento tiver rótulos diferentes da amostra de teste, é possível que uma delas esteja incorreta ou que a diferença sutil exija mais dados para o modelo aprender. ou que os rótulos de classe atuais não sejam precisos o suficiente para descrever a amostra especificada. A análise de imagens semelhantes pode ajudar você a corrigir as informações do rótulo. Basta corrigir os casos de erro ou excluir a amostra problemática do conjunto de teste. Você pode alterar convenientemente o rótulo da imagem de teste ou de imagens de treinamento no painel Revisar imagens semelhantes na mesma página.
Outliers. Se uma amostra de teste estiver marcada como outlier, é possível que não haja amostras visualmente semelhantes no conjunto de treinamento para ajudar a treinar o modelo. A análise de imagens semelhantes do conjunto de treinamento pode ajudar a identificar essas amostras e adicionar imagens semelhantes ao conjunto de treinamento para melhorar ainda mais o desempenho do modelo nesses casos.
A seguir
Se você estiver contente com o desempenho do modelo, siga a próxima página deste tutorial para implantar seu modelo treinado do AutoML em um endpoint e enviar uma imagem para o modelo para previsão. Caso contrário, se você fizer correções nos dados, treine um novo modelo usando o tutorial Como treinar um modelo de classificação de imagens do AutoML.