Usa la consola de Google Cloud para verificar el rendimiento del modelo. Analiza los errores de prueba para mejorar de forma iterativa la calidad del modelo mediante la corrección de problemas de datos
En este instructivo, se incluyen las siguientes páginas:
Crea un conjunto de datos de clasificación de imágenes y, luego, importar imágenes.
Evalúa y analiza el rendimiento del modelo.
En cada página, se supone que ya realizaste las instrucciones de las páginas anteriores del instructivo.
1. Comprende los resultados de la evaluación del modelo de AutoML
Una vez finalizado el entrenamiento, tu modelo se evalúa de forma automática en función de la división de datos de prueba. Los resultados de la evaluación correspondiente se presentan si haces clic en el nombre del modelo desde la página Model Registry o desde la página Dataset.
Allí, puedes encontrar las métricas para medir el rendimiento del modelo.
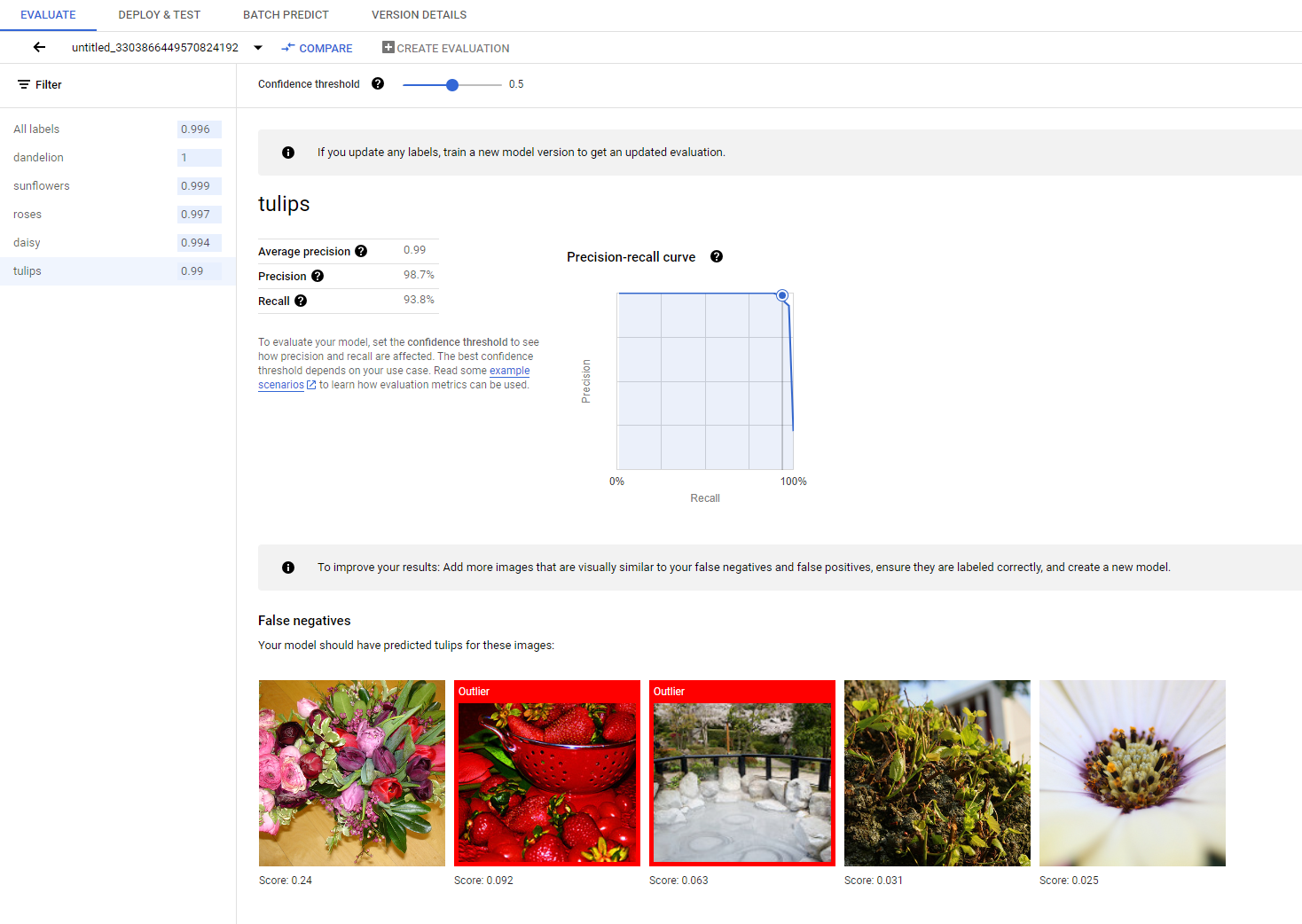
Puedes encontrar una introducción más detallada a las diferentes métricas de evaluación en la sección Evalúa, implementa y prueba tu modelo.
2. Analiza los resultados de la prueba
Si deseas seguir mejorando el rendimiento del modelo, el primer paso a menudo es examinar los casos de error y, además, investigar las posibles causas. En la página de evaluación de cada clase, se presentan imágenes de prueba detalladas de la clase determinada categorizadas como falsos negativos, falsos positivos y verdaderos positivos. Puedes encontrar la definición de cada categoría en la sección Evalúa, implementa y prueba tu modelo.
Para cada imagen en cada categoría, puedes verificar aún más los detalles de la predicción si haces clic en la imagen y accedes a los resultados detallados del análisis. Verás el panel Review similar images en el lado derecho de la página, en el que las muestras más cercanas del conjunto de entrenamiento se presentan con distancias que se miden en el espacio de atributos.
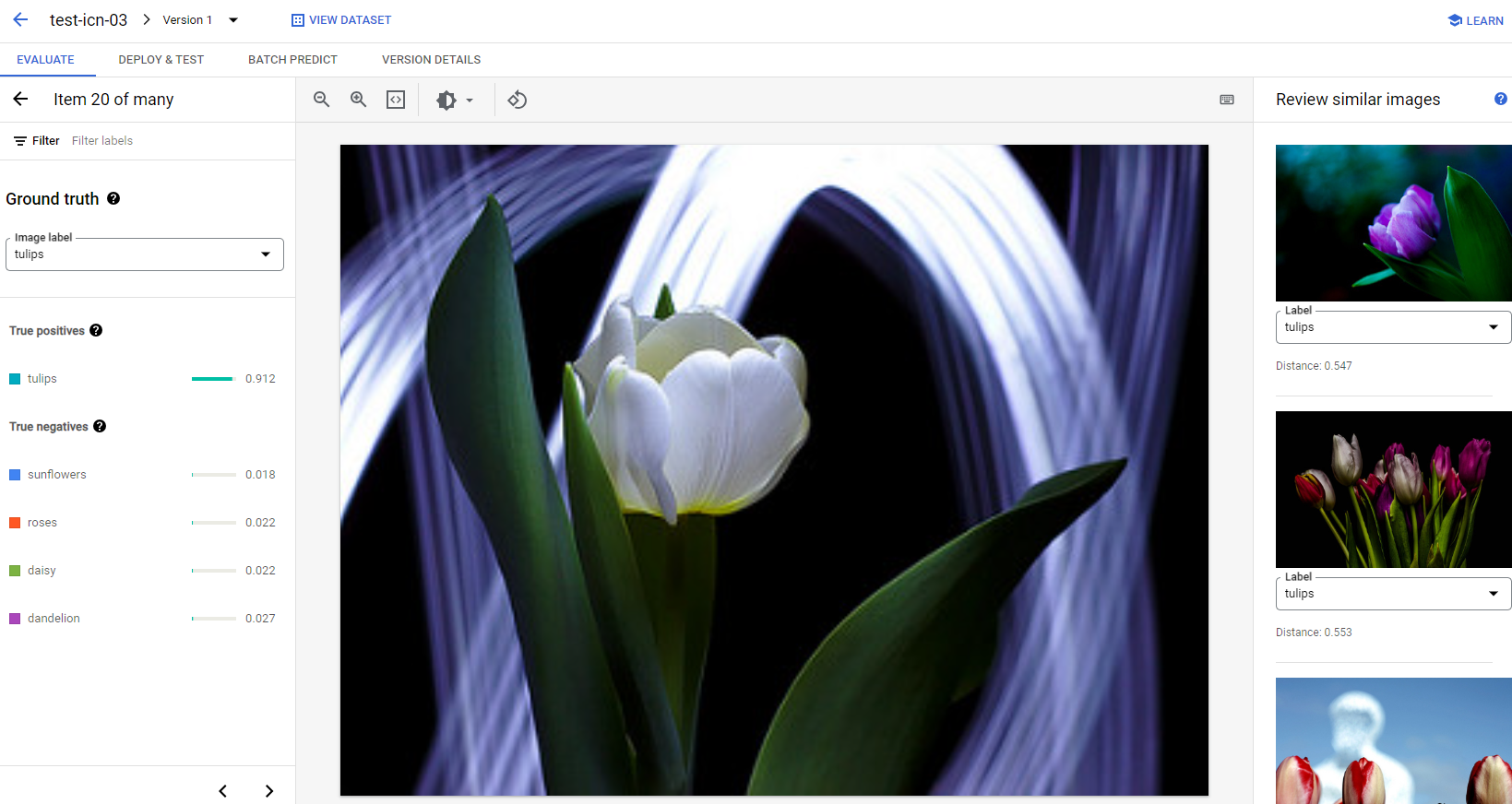
Hay dos tipos de problemas de datos a los que tal vez quieras prestar atención:
Inconsistencia de la etiqueta. Si una muestra visualmente similar al conjunto de entrenamiento tiene etiquetas diferentes a las de la muestra de prueba, es posible que una de ellas sea incorrecta o que la sutil diferencia requiera más datos para que el modelo aprenda, o que las etiquetas de clase actuales no sean lo suficientemente precisas para describir la muestra determinada. Revisar imágenes similares puede ayudarte a obtener la información de la etiqueta precisa, ya que corrige los casos de error o excluye la muestra problemática del conjunto de prueba. De forma conveniente, puedes cambiar la etiqueta de la imagen de prueba o de las imágenes de entrenamiento en el panel Review similar images en la misma página.
Valores atípicos. Si una muestra de prueba se marca como un valor atípico, es posible que no haya muestras visualmente similares en el conjunto de entrenamiento para ayudar a entrenar el modelo. Revisar imágenes similares del conjunto de entrenamiento puede ayudarte a identificar estas muestras y agregar imágenes similares al conjunto de entrenamiento para mejorar aún más el rendimiento del modelo en estos casos.
¿Qué sigue?
Si estás satisfecho con el rendimiento del modelo, pasa a la página siguiente de este instructivo para implementar tu modelo entrenado de AutoML en un extremo y enviar una imagen al modelo para su predicción. De lo contrario, si haces correcciones en los datos, entrena un modelo nuevo con el instructivo Entrena un modelo de clasificación de imágenes de AutoML.