Les modèles de machine learning sont souvent considérés comme des "boîtes noires", où même ses concepteurs ne peuvent expliquer comment ou pourquoi un modèle a généré une prédiction spécifique. Vertex Explainable AI fournit des explications basées sur les caractéristiques et basées sur des exemples pour mieux comprendre la prise de décision concernant un modèle.
Si vous connaissez le comportement d'un modèle et comment celui-ci est influencé par son ensemble de données d'entraînement, vous permettez à toute personne qui crée ou utilise de nouvelles capacités de ML d'améliorer les modèles, de renforcer la confiance dans ses prédictions et de comprendre quand et pourquoi les problèmes surviennent.
Explications basées sur des exemples
Avec les explications basées sur des exemples, Vertex AI utilise la recherche des plus proches voisins pour renvoyer une liste d'exemples (généralement à partir de l'ensemble d'entraînement) les plus similaires à l'entrée. Comme nous attendons généralement des entrées similaires pour générer des prédictions similaires, nous pouvons utiliser ces explications pour explorer et expliquer le comportement de notre modèle.
Les explications basées sur des exemples peuvent être utiles dans plusieurs scénarios :
Améliorer vos données ou votre modèle : l'un des principaux cas d'utilisation des explications basées sur des exemples vous aide à comprendre pourquoi votre modèle a commis certaines erreurs dans ses prédictions, et à exploiter ces insights pour améliorer vos données ou votre modèle. Pour ce faire, sélectionnez d'abord les données de test qui vous intéressent. Cela peut être dû aux besoins de l'entreprise ou à des heuristiques telles que les données pour lesquelles le modèle a commis les erreurs les plus évidentes.
Par exemple, supposons que nous ayons un modèle qui classe des images en tant qu'oiseau ou en tant qu'avion, et qu'il classe à tort l'oiseau suivant en tant qu'avion avec un haut niveau de confiance. Vous pouvez utiliser des explications basées sur des exemples pour extraire des images similaires de l'ensemble d'entraînement afin de comprendre ce qu'il se passe.

Étant donné que toutes ses explications sont des silhouettes sombres de la classe "avion", c'est un signe qu'il faut obtenir davantage de silhouettes d'oiseaux.
Toutefois, si les explications proviennent principalement de la classe "oiseau", cela signifie que notre modèle est incapable d'apprendre les relations même lorsque les données sont riches, ,et que nous devons envisager d'augmenter la complexité du modèle (par exemple, en ajoutant plus de couches).
Interpréter des données nouvelles : supposons que votre modèle a été entraîné pour classer des oiseaux et des avions, mais qu'en conditions réelles, il rencontre également des images de cerfs-volants, de drones et d'hélicoptères. Si votre ensemble de données des plus proches voisins contient des images étiquetées de cerfs-volants, de drones et d'hélicoptères, vous pouvez utiliser des explications basées sur des exemples pour classer de nouvelles images en appliquant l'étiquette la plus fréquente de ses voisins les plus proches. Cela est possible, car nous nous attendons à ce que les représentations latentes des cerfs-volants diffèrent de celles des oiseaux et des avions, mais soient plus semblables aux cerfs-volants étiquetés dans l'ensemble de données des voisins les plus proches.
Détecter les anomalies : intuitivement, si une instance est éloignée de toutes les données de l'ensemble d'entraînement, il s'agit probablement d'une anomalie. Les réseaux de neurones sont connus pour avoir trop confiance en leurs erreurs, ce qui masque leurs erreurs. Surveiller vos modèles à l'aide d'explications basées sur des exemples permet d'identifier les anomalies les plus sérieuses.
Apprentissage actif : les explications basées sur des exemples peuvent vous aider à identifier les instances qui pourraient bénéficier de l'ajout manuel d'étiquettes. Cela se révèle particulièrement utile si l'étiquetage est lent ou coûteux, car elles permettent d'obtenir l'ensemble de données le plus riche possible à partir de ressources d'étiquetage limitées.
Par exemple, supposons que nous ayons un modèle qui classe un patient médical comme ayant un rhume ou une grippe. Si un patient est classifié comme ayant la grippe, et que toutes ses explications basées sur des exemples proviennent de la classe "grippe", le médecin peut être plus sûr de la prédiction du modèle sans avoir à y regarder de plus près. Toutefois, si certaines des explications proviennent de la classe "grippe" et d'autres de la classe "rhume", il peut s'avérer utile d'obtenir l'avis d'un médecin. Vous obtiendrez ainsi un ensemble de données dans lequel les instances difficiles ont plus d'étiquettes, ce qui permet aux modèles en aval d'apprendre plus facilement des relations complexes.
Pour créer un modèle compatible avec les explications basées sur des exemples, consultez la page Configurer des explications basées sur des exemples.
Types de modèles compatibles
Les modèles TensorFlow capables de fournir une représentation vectorielle continue (représentation latente) pour les entrées sont compatibles. Les modèles basés sur des arbres, tels que les arbres de décision, ne sont pas compatibles. Les modèles d'autres frameworks, tels que PyTorch ou XGBoost, ne sont pas encore compatibles.
Pour les réseaux de neurones profonds, nous supposons généralement que les couches supérieures (les plus proches de la couche de sortie) ont appris quelque chose de "significatif". C'est pourquoi l'on choisit souvent l'avant-dernière couche pour les représentations vectorielles continues. Vous pouvez tester différentes couches, examiner les exemples obtenus et en choisir une en fonction de mesures quantitatives (correspondances de classe) ou qualitatives (sensibles).
Pour obtenir une démonstration sur l'extraction de représentations vectorielles continues à partir d'un modèle TensorFlow et de la recherche des plus proches voisins, consultez le notebook d'explications basées sur des exemples.
Explications basées sur les caractéristiques
Vertex Explainable AI intègre les attributions de caractéristiques dans Vertex AI. Cette page offre un bref aperçu des concepts et méthodes d'attribution de caractéristiques disponibles avec Vertex AI.
Les attributions de caractéristiques indiquent dans quelle mesure chaque caractéristique de votre modèle a contribué aux prédictions pour chaque instance donnée. Lorsque vous demandez des prédictions, vous obtenez des valeurs prédites correspondant à votre modèle. Lorsque vous demandez des explications, vous obtenez les prédictions ainsi que les informations d'attribution des caractéristiques.
Les attributions de caractéristiques fonctionnent sur des données tabulaires et incluent des fonctionnalités de visualisation intégrées pour les données d'image. Prenons les exemples suivants :
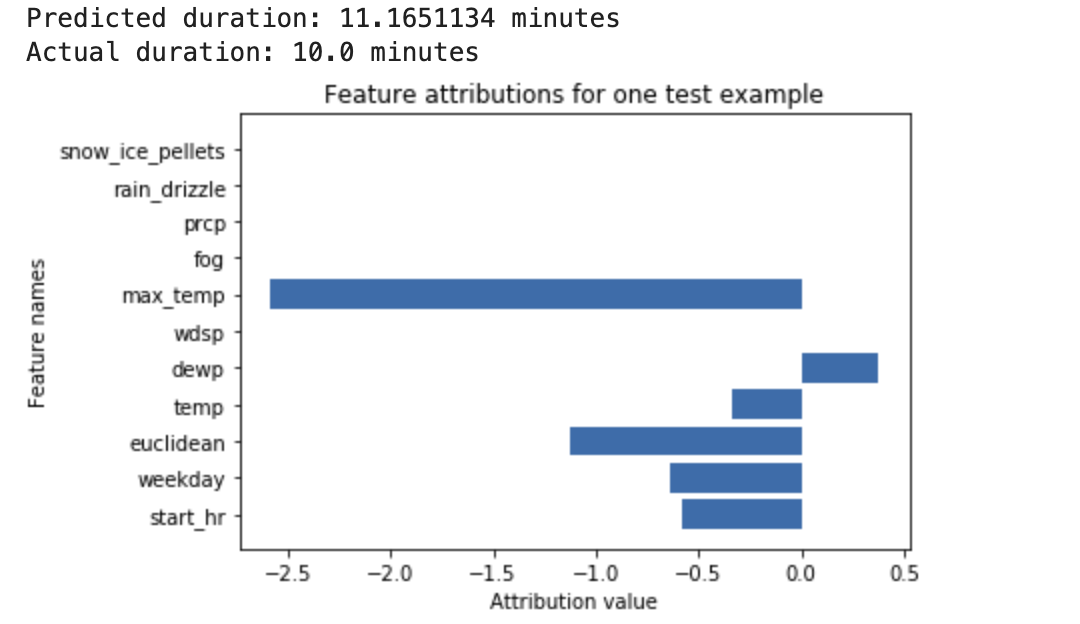
Un réseau de neurones profond est entraîné pour prédire la durée d'un trajet à vélo, en fonction des données météorologiques et des données de trajets précédents fournies par les stations de vélos en libre-service. Si vous ne demandez que des prédictions à partir de ce modèle, vous obtenez la durée prévue des trajets à vélo en minutes. Si vous demandez des explications, vous obtenez la durée prévue des trajets à vélo, ainsi qu'un score d'attribution pour chaque caractéristique dans votre requête d'explication. Les scores d'attribution indiquent dans quelle mesure chaque caractéristique a affecté la variation de la valeur de prédiction par rapport à la valeur de référence que vous avez spécifiée. Choisissez une valeur de référence cohérente et adaptée à votre modèle, en l'occurrence la durée moyenne d'un trajet à vélo. Vous pouvez tracer les scores d'attribution des caractéristiques pour identifier celles qui ont le plus contribué à la prédiction obtenue :
Un modèle de classification d'images est entraîné pour prédire si une image donnée contient un chien ou un chat. Si vous demandez des prédictions à partir de ce modèle sur un nouvel ensemble d'images, vous obtenez une prédiction pour chaque image ("chien" ou "chat"). Si vous demandez des explications, vous obtenez la classe prédite avec, en superposition sur l'image, l'affichage des pixels qui ont le plus contribué à la prédiction obtenue :

Photo de chat avec attribution de caractéristiques en superposition 
Photo de chien avec attribution de caractéristiques en superposition Un modèle de classification d'images est entraîné à prédire des espèces de fleurs dans l'image. Si vous demandez des prédictions à partir de ce modèle sur un nouvel ensemble d'images, vous obtenez une prédiction pour chaque image ("marguerite" ou "pissenlit"). Si vous demandez des explications, vous obtenez la classe prédite avec, en superposition sur l'image, l'affichage des zones qui ont le plus contribué à la prédiction obtenue :

Photo d'une marguerite avec attribution de caractéristiques en superposition
Types de modèles compatibles
L'attribution de caractéristiques est compatible avec tous les types de modèles (AutoML et personnalisé), les frameworks (TensorFlow, scikit, XGBoost), les modèles BigQuery ML et les modalités (images, texte, tabulaires, vidéo).
Pour utiliser l'attribution de caractéristiques, configurez votre modèle pour l'attribution de caractéristiques lorsque vous l'importez ou l'enregistrez dans Vertex AI Model Registry.
En outre, pour les types de modèles AutoML suivants, l'attribution de caractéristiques est intégrée à la console Google Cloud :
- Modèles d'images AutoML (modèles de classification uniquement)
- Modèles tabulaires AutoML (modèles de classification et de régression seulement)
Pour les types de modèles AutoML intégrés, vous pouvez activer l'attribution de caractéristiques dans la console Google Cloud pendant l'entraînement, puis afficher l'importance des caractéristiques du modèle pour l'ensemble du modèle, et l'importance des caractéristiques locales pour les prédictions en ligne et par lot.
Pour les types de modèles AutoML qui ne sont pas intégrés, vous pouvez toujours activer l'attribution de caractéristiques en exportant les artefacts de modèle et en configurant l'attribution de caractéristiques lorsque vous importez les artefacts de modèle dans Vertex AI Model Registry.
Avantages
Si vous inspectez des instances spécifiques et regroupez les attributions de caractéristiques dans votre ensemble de données d'entraînement, vous pouvez obtenir des insights plus complets sur le fonctionnement de votre modèle. Tenez compte des avantages suivants :
Déboguer les modèles : les attributions de caractéristiques peuvent aider à détecter les problèmes liés aux données que les techniques d'évaluation standards des modèles ne parviennent généralement pas à résoudre.
Par exemple, un modèle d'images pathologiques a obtenu des résultats suspects sur un ensemble de données de test d'images de radiographie thoracique. Les attributions de caractéristiques ont révélé que la précision élevée du modèle dépendait des marquages au stylo effectués par le radiologue dans l'image. Pour plus de détails sur cet exemple, consultez le livre blanc sur AI Explanations.
Optimiser les modèles : vous pouvez identifier et supprimer les caractéristiques moins importantes, ce qui permet d'obtenir des modèles plus efficaces.
Méthodes d'attribution des caractéristiques
Chaque méthode d'attribution de caractéristiques est basée sur les valeurs de Shapley, un algorithme collaboratif de la théorie des jeux qui attribue un crédit à chaque joueur pour un résultat particulier. Appliqué aux modèles de machine learning, cela signifie que chaque caractéristique de modèle est traitée comme un "joueur" dans le jeu. Vertex Explainable AI attribue un crédit proportionnel à chaque caractéristique pour le résultat d'une prédiction spécifique.
Méthode de l'échantillonnage des valeurs de Shapley
La méthode de l'échantillonnage des valeurs de Shapley fournit une approximation d'échantillonnage de valeurs de Shapley exactes. Les modèles tabulaires AutoML utilisent la méthode d'échantillonnage des valeurs de Shapley pour l'importance des caractéristiques. L'échantillonnage des valeurs de Shapley convient parfaitement à ces modèles, qui sont des méta-objets d'arbres et de réseaux de neurones.
Pour des informations détaillées sur le fonctionnement de la méthode d'échantillonnage des valeurs de Shapley, consultez l'article Bounding the Estimation Error of Sampling-based Shapley Value Approximation (Limiter l'erreur d'estimation de l'approximation d'échantillonnage basée sur les valeurs de Shapley).
Méthode des gradients intégrés
Avec la méthode des gradients intégrés, le gradient de sortie de la prédiction est calculé par rapport aux caractéristiques d'entrée, le long d'un chemin intégral.
- Les gradients sont calculés à différents intervalles selon un paramètre de mise à l'échelle. La taille de chaque intervalle est déterminée à l'aide de la règle de la quadrature de Gauss. (Pour les données d'image, imaginez ce paramètre de mise à l'échelle comme un "curseur" qui redimensionne tous les pixels de l'image en noir.)
- Les gradients sont intégrés comme suit :
- L'intégrale est approximée à l'aide d'une moyenne pondérée.
- Le produit par éléments de la moyenne des gradients et de l'entrée d'origine est calculé.
Pour obtenir une explication intuitive de ce processus appliqué aux images, consultez l'article de blog Attributing a deep network's prediction to its input features (Attribuer une prédiction de réseau profond à ses caractéristiques d'entrée). Les auteurs de l'article original sur les gradients intégrés, Axiomatic Attribution for Deep Networks (Attribution axiomatique pour les réseaux profonds) montrent dans l'article de blog précédent à quoi ressemblent les images à chaque étape du processus.
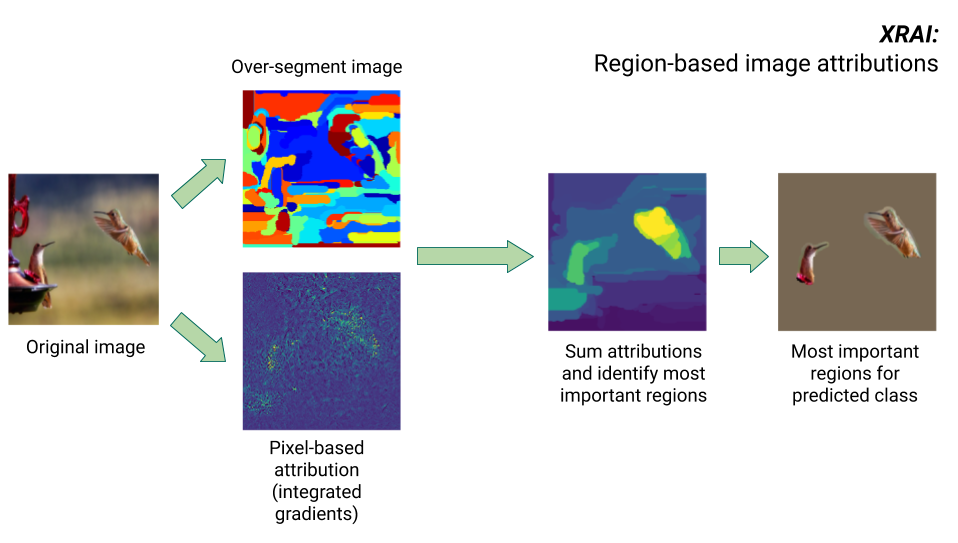
Méthode XRAI
La méthode XRAI combine la méthode des gradients intégrés et des étapes supplémentaires pour déterminer quelles régions de l'image contribuent le plus à une prédiction de classe donnée.
- Attribution au niveau du pixel : XRAI effectue l'attribution au niveau du pixel pour l'image d'entrée. Lors de cette étape, XRAI utilise la méthode des gradients intégrés avec une référence noire et une référence blanche.
- Segmentation excessive : indépendamment de l'attribution au niveau du pixel, XRAI segmente l'image de manière excessive pour créer un patchwork de petites régions. XRAI utilise la méthode basée sur le graphique de Felzenswalb pour créer les segments de l'image.
- Sélection de la région : XRAI agrège l'attribution au niveau du pixel dans chaque segment pour déterminer sa densité d'attribution. En utilisant ces valeurs, XRAI classe chaque segment, du plus positif au moins positif. Cela permet de déterminer quelles zones de l'image sont les plus saillantes ou contribuent le plus à une prédiction de classe donnée.
Comparer les méthodes d'attribution des caractéristiques
Vertex Explainable AI propose trois méthodes d'attribution de caractéristiques : échantillonnage des valeurs de Shapley, gradients intégrés et XRAI.
| Méthode | Explication de base | Types de modèles recommandés | Exemples de cas d'utilisation | Ressources Model Vertex AI compatibles |
|---|---|---|---|---|
| Échantillonnage des valeurs de Shapley | Attribue un crédit de contribution au résultat pour chaque caractéristique en tenant compte des diverses permutations de caractéristiques. Cette méthode fournit une approximation d'échantillonnage de valeurs de Shapley exactes. | Modèles non différenciables, tels que les ensembles d'arbres et de réseaux de neurones |
|
|
| Gradients intégrés | Méthode basée sur les gradients permettant de calculer efficacement les attributions de caractéristiques avec les mêmes propriétés axiomatiques que les valeurs de Shapley. | Modèles différenciables, tels que les réseaux de neurones. Particulièrement recommandé pour les modèles comportant de grands espaces de caractéristiques. Recommandé pour les images à faible contraste, comme les images par rayons X. |
|
|
| XRAI (eXplanation with Ranked Area Integrals) | En fonction de la méthode des gradients intégrés, XRAI évalue les régions en chevauchement pour créer une carte de saillance, qui met en évidence les régions pertinentes de l'image plutôt que les pixels. | Modèles acceptant les images d'entrée. Particulièrement recommandé pour les images naturelles, qui sont des scènes réelles contenant plusieurs objets. |
|
|
Pour une comparaison plus détaillée des méthodes d'attribution, consultez le livre blanc sur AI Explanations.
Modèles différenciables et non différenciables
Dans les modèles différenciables, vous pouvez calculer le dérivé de toutes les opérations de votre graphe TensorFlow. Cette propriété contribue à rendre la rétropropagation possible dans de tels modèles. Par exemple, les réseaux de neurones sont différenciables. Pour obtenir des attributions de caractéristiques pour des modèles différenciables, utilisez la méthode des gradients intégrés.
La méthode des gradients intégrés ne fonctionne pas pour les modèles non différenciables. Apprenez-en plus sur l'encodage des entrées non différenciables afin de permettre l'utilisation de la méthode des gradients intégrés.
Les modèles non différenciables incluent des opérations non différenciables dans le graphe TensorFlow, comme celles qui effectuent les tâches de décodage et d'arrondi. Par exemple, un modèle construit comme un ensemble d'arbres et de réseaux de neurones est non différenciable. Pour obtenir des attributions de caractéristiques pour des modèles non différenciables, utilisez la méthode de l'échantillonnage des valeurs de Shapley. Cette méthode fonctionne également sur les modèles différenciables, mais les opérations de calcul nécessaires sont plus importantes.
Limites conceptuelles
Les attributions de caractéristiques comportent les limites suivantes dont vous devez tenir compte :
Les attributions de caractéristiques, y compris l'importance des caractéristiques locales pour AutoML, sont spécifiques aux prédictions individuelles. Si inspecter les attributions de caractéristiques pour une prédiction individuelle permet d'obtenir des informations utiles, elles ne sont pas forcément généralisables à l'ensemble de la classe ou du modèle.
Pour obtenir des informations plus générales sur les modèles AutoML, reportez-vous à l'importance des caractéristiques du modèle. Pour obtenir des insights plus généralisables à d'autres modèles, vous pouvez agréger les attributions dans des sous-ensembles de votre ensemble de données, ou pour l'ensemble de données complet.
Bien que les attributions de caractéristiques puissent faciliter le débogage du modèle, elles n'indiquent pas toujours clairement si un problème provient du modèle lui-même ou des données sur lesquelles il est entraîné. Faites appel à votre bon sens et analysez les problèmes de données courants afin de réduire le champ des causes potentielles.
Dans les modèles complexes, les attributions de caractéristiques sont soumises à des attaques contradictoires semblables à celles rencontrées dans les prédictions.
Pour en savoir plus sur les limites, reportez-vous à la liste détaillée des limites et au livre blanc sur AI Explanations.
Références
Pour l'attribution de caractéristiques, les implémentations de l'échantillonnage des valeurs de Shapley, des gradients intégrés et de XRAI sont respectivement basées sur les documents de référence suivants :
- Bounding the Estimation Error of Sampling-based Shapley Value Approximation (Limiter l'erreur d'estimation de l'approximation d'échantillonnage basée sur les valeurs de Shapley)
- Axiomatic Attribution for Deep Networks (Attribution axiomatique pour les réseaux profonds)
- XRAI : Better Attributions Through Regions (Améliorer les attributions dans les régions)
Pour en savoir plus sur la mise en œuvre de Vertex Explainable AI, consultez le livre blanc sur AI Explanations.
Notebooks
Pour commencer à utiliser Vertex Explainable AI, utilisez ces notebooks :
| Notebook | Méthode d'explicabilité | ML framework | Modalité | Tâche |
|---|---|---|---|---|
| Lien GitHub | explications basées sur des exemples | TensorFlow | Image | Entraîner un modèle de classification qui prédit la classe de l'image d'entrée fournie et obtient des explications en ligne |
| Lien GitHub | basée sur les caractéristiques | AutoML | tabulaire | Entraîner un modèle de classification binaire pour prédire si une banque personnalisée a acheté un dépôt à terme et obtenez des explications par lots |
| Lien GitHub | basée sur les caractéristiques | AutoML | tabulaire | Entraîner un modèle de classification qui prédit le type d'espèce de fleurs Iris et obtenir des explications en ligne |
| Lien GitHub | basée sur les caractéristiques (échantillonnage des valeurs de Shapley) | scikit-learn | tabulaire | Entraîner un modèle de régression linéaire qui prédit le prix d'une course en taxi et obtient des explications en ligne |
| Lien GitHub | basé sur les caractéristiques (gradients intégrés) | TensorFlow | Image | Entraîner un modèle de classification qui prédit la classe de l'image d'entrée fournie et obtient des explications par lots |
| Lien GitHub | basé sur les caractéristiques (gradients intégrés) | TensorFlow | Image | Entraîner un modèle de classification qui prédit la classe de l'image d'entrée fournie et obtient des explications en ligne |
| Lien GitHub | basé sur les caractéristiques (gradients intégrés) | TensorFlow | tabulaire | Entraîner un modèle de régression qui prédit le prix médian d'une maison et obtenir des explications par lots |
| Lien GitHub | basé sur les caractéristiques (gradients intégrés) | TensorFlow | tabulaire | Entraîner un modèle de régression qui prédit le prix médian d'une maison et obtenir des explications en ligne |
| Lien GitHub | basé sur les caractéristiques (gradients intégrés) | TensorFlow | Image | Utiliser Inception_v3, un modèle de classification pré-entraîné pour obtenir des explications par lot et en ligne |
| Lien GitHub | basée sur les caractéristiques (échantillonnage des valeurs de Shapley) | TensorFlow | text | Entraîner un modèle LSTM qui classe les avis de films comme étant positifs ou négatifs à l'aide du texte de l'avis et obtenir des explications en ligne |
Ressources pédagogiques
Les ressources pédagogiques suivantes vous seront également utiles :
- Explainable AI pour les professionnels
- Interpretable Machine Learning: Shapley values (Modèles de machine learning interprétables : les valeurs de Shapley)
- Dépôt GitHub des gradients intégrés par Ankur Taly.
- Présentation des valeurs de Shapley
Étapes suivantes
- Configurez votre modèle pour obtenir des explications basées sur les caractéristiques.
- Configurez votre modèle pour obtenir des explications basées sur des exemples.
- Découvrez l'importance des caractéristiques pour les modèles tabulaires AutoML.