トレーニング データの品質は作成するモデルの有効性を大きく左右し、ひいてはそのモデルから返される予測の品質にも大きく影響します。高品質のトレーニング データを得るためには、予測の対象となるドメインを正確に表すトレーニング アイテムを用意し、トレーニング アイテムに正確なラベルを付けることが重要です。
トレーニング データ項目にラベルを割り当てる方法は 3 つあります。
- 市販のデータセットなどを使用して、ラベルが割り当てられたデータセットにデータ項目を追加する
- Google Cloud コンソールを使用してデータ項目にラベルを割り当てる
- ラベル付け担当者にデータ項目へのラベル付けを依頼する
Vertex AI データラベル付けタスクを使用すると、ラベル付け担当者と協力して、機械学習モデルのトレーニングに使用できるデータのコレクションに対して高精度のラベルを生成できます。
データラベル付けの料金については、データのラベル付けをご覧ください。
ラベル付け担当者にデータのラベル付けを依頼するには、データラベル付けジョブを作成し、ラベル付け担当者に次のデータを提供します。
- ラベル付けの対象となる代表的なデータ項目が含まれたデータセット
- データ項目に適用可能なすべてのラベルのリスト
- ラベル付け担当者によるラベル付けに関する指示が記載された PDF ファイル
ラベル付け担当者は、これらのリソースを使用し、手順に沿ってデータセットの項目に対してアノテーションを付けます。完了したら、アノテーション セットを使用して Vertex AI モデルをトレーニングすることも、ラベル付きデータ項目をエクスポートして別の機械学習環境で使用することもできます。
データセットを作成する
データセットを作成し、そこにデータ項目をインポートして、ラベル付け担当者にデータ項目を提供します。データ項目はラベル付けされていなくても構いません。ラベル付け担当者がデータ項目に適用するアノテーションの種類は、データ型(画像、動画、テキスト)と目的(分類やオブジェクト トラッキングなど)によって決まります。
ラベルを指定する
データラベル付けタスクを作成する際には、ラベル付け担当者に画像のラベル付けに使用してもらいたいラベルセットの一覧を作成します。たとえば、イヌまたはネコが含まれているかどうかで画像を分類する場合は、「Dog」と「Cat」の 2 つのラベルを含むラベルセットを作成します。また、次のリストに示すとおり、「Neither」と「Both」のラベルを使用することもできます。
質の高いラベルセットを作成するためのガイドラインを以下に示します。
- 各ラベルの表示名は、「dog」、「cat」、「building」などの意味のある言葉にします。「label1」や「label2」のような抽象的な名前や一般的でない頭字語は使用しないでください。ラベル名の意味が明確であれば、ラベル付け担当者がそのラベルを正確かつ一貫して適用しやすくなります。
- ラベル同士を簡単に区別できるようにします。各データ項目に単一のラベルを適用する分類タスクでは、意味が重複するラベルを使用しないでください。たとえば、「Sports」や「Baseball」といったラベルは使用しないでください。
- 分類タスクの場合は、他のどのラベルとも一致しないデータ用に、「other」または「none」といった名前のラベルを用意することをおすすめします。たとえば、適用可能なラベルが「dog」と「cat」しかない場合は、すべての画像に必ずどちらかのラベルを付けなければなりません。多くの場合、イヌやネコ以外の画像をトレーニング データに含めると、カスタムモデルはより堅牢になります。
- ラベル付け担当者が最も効率的かつ正確にラベル付けできるのは、ラベルセットで定義されているラベルの数が 20 個以下の場合であることに留意してください。最大 100 個のラベルを含めることができます。
指示を作成する
ここでいう「指示」とは、データにラベルを適用する方法についての情報をラベル付け担当者に与えるものを指します。指示には、ラベルが付けられたサンプルデータやその他の明示的な説明を含める必要があります。
指示は PDF ファイルとして作成します。PDF 指示では、ポジティブ サンプルとネガティブ サンプルやそれぞれのケースの説明など、詳細な説明を提供できます。画像の境界ボックスや動画のオブジェクト トラッキングなどの複雑な作業の指示を行う場合にも、PDF は役立ちます。
指示を記述し、PDF ファイルを作成して、その PDF ファイルを Cloud Storage バケットに保存します。
適切な指示を与える
適切な指示を与えることは、ヒューマン ラベリングで良好な結果を得るために最も重要な要素です。ユースケースを最もよく知っているのはサービス利用者自身であり、サービス利用者がラベル付け担当者にどうしてほしいかを知らせる必要があります。適切な指示を作成するためのガイドラインを以下に示します。
ラベル付け担当者はドメインに関する知識を持っていません。サービス利用者のユースケースに精通していない人でも、どのような区別が求められているかを容易に理解できる必要があります。
指示が長くなりすぎないように注意してください。ラベル付け担当者が 20 分以内に指示を確認して理解できるようにすることをおすすめします。
指示にはタスクのコンセプトを記述し、データのラベル付け方法の詳細を追加する必要があります。たとえば、境界ボックスのタスクを依頼する場合は、境界ボックスをどのように描画するかを説明します。対象だけを厳密に囲むか、または大まかに囲むか。対象が複数ある場合は、それらすべてを 1 つの境界ボックスで囲むか、複数の境界ボックスで囲むか。
作成する指示に対応するラベルセットがある場合は、そのセットに含まれるすべてのラベルについて指示を記載します。指示に記載したラベルの名前は、ラベルセットに含まれる名前と一致している必要があります。
一般に、適切な指示を作成するには何度か繰り返すことが必要です。まず、ラベル付け担当者に小さなデータセットで作業してもらい、その後で作業量と期待値に応じて指示を調整することをおすすめします。
適切な指示ファイルには次のセクションが含まれています。
- ラベルのリストと説明: 使用するすべてのラベルのリストと、各ラベルの意味。
- サンプル: ラベルごとに少なくとも 3 つのポジティブ サンプルと 1 つのネガティブ サンプルを含めます。これらのサンプルでさまざまなケースをカバーします。
- エッジケースをカバーします。ラベル付け担当者がラベルを解釈する必要性を減らすには、できるだけ多くのエッジケースを明確なものにします。たとえば、人を境界ボックスで囲むよう求める場合は、次のことを明確にすることをおすすめします。
- 複数の人がいる場合、1 人ずつボックスで囲む必要があるか。
- 人混みに遮られた人を囲む必要はあるか。
- 画像に一部だけ写っている人を囲む必要はあるか。
- 写真や絵の中の人を囲む必要はあるか。
- アノテーションを追加する方法を説明します。例:
- 境界ボックスの場合、対象だけを厳密に囲むか、または大まかに囲むか。
- テキスト エンティティ抽出の場合、対象エンティティの開始位置と終了位置はどのように判断するか。
- ラベルの説明。2 つのラベルが似ている場合や混同しやすい場合は例を挙げて違いを明確にします。
以下の例では、PDF 指示の内容を説明します。ラベル付け担当者は作業を開始する前にこの指示を読みます。

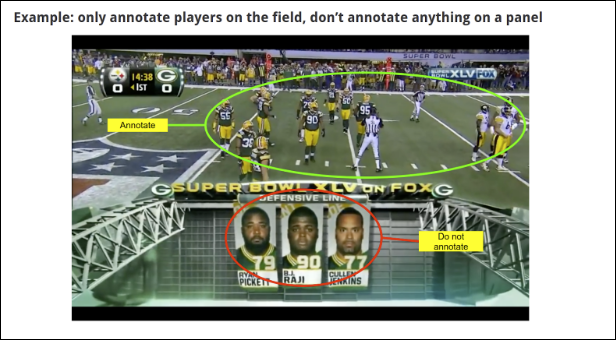
データのラベル付けタスクを作成する
ウェブ UI
Google Cloud Console からデータのラベル付けをリクエストできます。
Google Cloud Console で、[タスクのラベル付け] ページに移動します。
[作成] をクリックします。
[新しいラベル付けタスク] ペインが表示されます。
ラベル付けタスクの名前を入力します。
ラベルを付ける項目を含むデータセットを選択します。
データセットの詳細画面から [新しいラベル付けタスク] ペインを開いた場合、別のデータセットは選択できません。
目的が正しいことを確認します。
[目的] ボックスには、デフォルトのアノテーション セットによって決定されたデータセットの目的が表示されます。目的を変更するには、別のアノテーション セットを選択します。
ラベル付きデータに使用するアノテーション セットを選択します。
ラベル付け担当者によって適用されたラベルは、選択したアノテーション セットに保存されます。既存のアノテーション セットを選択することも、新しいアノテーション セットを作成することもできます。新しく作成する場合は、その名前を指定する必要があります。
能動的学習を使用するかどうかを指定します。
能動的学習では、ラベル付け担当者がデータを部分的にラベル付けして、残りのデータには機械学習を適用して自動的にラベル付けを行うことにより、ラベル付けプロセスを促進します。
[続行] をクリックします。
ラベル付け担当者が適用するラベルを入力します。高品質のラベルセットを作成する方法については、ラベルセットの設計をご覧ください。
[続行] をクリックします。
ラベル付け担当者向けの指示のパスを入力します。指示は、Cloud Storage バケットに保存されている PDF ファイルである必要があります。質の高い指示を作成する方法については、ラベル付け担当者に向けた指示の設計をご覧ください。
[続行] をクリックします。
Google マネージド ラベラーを使用するか、独自のラベラーを使用するかを選択します。
Google マネージド ラベラーを使用する場合は、チェックボックスをオンにして、料金ガイドを読んでラベルの費用を理解したことを確認します。
独自のラベル付けを設定するには、DataCompute Console を使用してラベラー グループを作成し、そのアクティビティを管理します。それ以外の場合は、このラベル付けタスクに使用するラベラー グループを選択します。
プルダウン リストから既存のラベラー グループを選択するか、[新しいラベラー グループ] を選択してから、プルダウン リストの下にあるテキスト ボックスに、グループ名と、グループのマネージャーのメールアドレスのリストをカンマ区切りで入力します。チェックボックスをオンにして、指定した管理者にデータラベル付け情報へのアクセスを許可します。
項目ごとにレビューの対象となるラベル付け担当者の人数を指定します。
デフォルトでは、データ項目ごとに 1 人のラベル付け担当者がアノテーションを付けます。ただし、各データ項目に対して、複数のラベル付け担当者がアノテーションを付け、レビューするよう依頼することもできます。[Specialist per data item] ボックスでラベル付け担当者の人数を選択します。
[タスクの開始] をクリックします。
[タスクの開始] が使用できない場合は、[新しいラベル付けタスク] ペインのページを調べて、すべての必要な情報が入力されていることを確認してください。
Google Cloud Console の [ラベル付けタスク] ページで、データのラベル付けタスクの進行状況を確認できます。
このページには、リクエストされた各ラベル付けタスクのステータスが表示されます。[進行状況] 列に 100% と表示されている場合、対応するデータセットにラベルが付けられていて、モデルのトレーニングの準備ができていることを表します。
REST
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: 実際のプロジェクト ID
- DISPLAY_NAME: データラベル付けジョブの名前
- DATASET_ID: ラベルを付けるアイテムを含むデータセットの ID
- LABELERS: 各データ項目をレビューしてもらうラベル付け担当者の人数。有効な値は 1、3、5 です。
- INSTRUCTIONS: 手動のラベル付けに関する説明を含む PDF ファイルのパス。このファイルは、プロジェクトからアクセス可能な Cloud Storage バケットに存在する必要があります。
- INPUT_SCHEMA_URI: データ項目タイプのスキーマ ファイルのパス:
- 画像分類(単一ラベル):
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_classification_single_label_io_format_1.0.0.yaml - 画像分類(マルチラベル):
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_classification_multi_label_io_format_1.0.0.yaml - 画像オブジェクト検出:
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml - テキスト分類(単一ラベル):
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_classification_single_label_io_format_1.0.0.yaml - テキスト分類(マルチラベル):
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_classification_multi_label_io_format_1.0.0.yaml - テキスト エンティティの抽出:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_extraction_io_format_1.0.0.yaml - テキスト感情分析:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_sentiment_io_format_1.0.0.yaml - 動画分類:
gs://google-cloud-aiplatform/schema/dataset/ioformat/video_classification_io_format_1.0.0.yaml - 動画オブジェクト トラッキング:
gs://google-cloud-aiplatform/schema/dataset/ioformat/video_object_tracking_io_format_1.0.0.yaml
- 画像分類(単一ラベル):
- LABEL_LIST: データ項目に適用できるラベルを列挙した、文字列のカンマ区切りリスト。
- ANNOTATION_SET: ラベル付きデータのアノテーション セットの名前
HTTP メソッドと URL:
POST https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/dataLabelingJobs
リクエストの本文(JSON):
{
"displayName":"DISPLAY_NAME",
"datasets":"DATASET_ID",
"labelerCount":LABELERS,
"instructionUri":"INSTRUCTIONS",
"inputsSchemaUri":"INPUT_SCHEMA_URI",
"inputs": {
"annotation_specs": [LABEL_LIST]
},
"annotationLabels": {
"aiplatform.googleapis.com/annotation_set_name": "ANNOTATION_SET"
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/locations/us-central1/dataLabelingJobs/JOB_ID",
"displayName": "DISPLAY_NAME",
"datasets": [
"DATASET_ID"
],
"labelerCount": LABELERS,
"instructionUri": "INSTRUCTIONS",
"inputsSchemaUri": "INPUT_SCHEMA_URI",
"inputs": {
"annotationSpecs": [
LABEL_LIST
]
},
"state": "JOB_STATE_PENDING",
"labelingProgress": "0",
"createTime": "2020-05-30T23:13:49.121133Z",
"updateTime": "2020-05-30T23:13:49.121133Z",
"savedQuery": {
"name": "projects/PROJECT_ID/locations/us-central1/datasets/DATASET_ID/savedQueries/ANNOTATION_SET_ID"
},
"annotationSpecCount": 2
}
DataLabelingJob になります。"labelingProgress" 要素をモニタリングすることで、ジョブの進行状況を確認できます。この値は、完了した割合を示します。Java
その他のコードサンプル:アクティブ ラーニングの使用
Python
その他のコードサンプル:アクティブ ラーニングの使用