在训练模型后,AutoML Translation 使用测试集中的训练项来评估新模型的质量和准确率。AutoML Translation 使用其 BLEU (Bilingual Evaluation Understudy) 得分来表示模型质量,该得分表明了候选文本与参考文本的相似程度,值越接近 1,说明两个文本越相似。
BLEU 得分为模型质量提供了总体评估。您还可以通过导出带有模型预测结果的测试集来评估特定数据项的模型输出。导出的数据包括参考文本(来自原始数据集)和模型的候选文本。
您可利用这些数据来评估您的模型的准备情况。如果您对质量水平不满意,请考虑添加更多(且更加多样化)的训练句对。 一种选择是添加更多句对。使用标题栏中的添加文件链接。添加文件后,点击训练页面上的训练新模型按钮以训练新模型。重复此过程,直到获得足以让您满意的质量水平为止。
获取模型评估结果
网页界面
打开AutoML Translation 控制台,然后点击左侧导航栏中模型旁边的灯泡图标。系统会显示可用的模型。每个模型都包含以下信息:数据集(用于训练模型)、源(语言)、目标(语言)、基本模型(用于训练模型)。
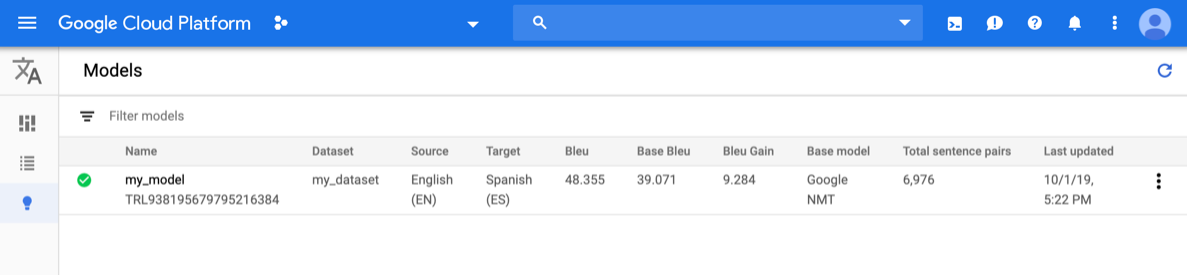
如需查看其他项目的模型,请从标题栏右上角的下拉列表中选择该项目。
点击待评估模型所在的行。
系统会打开预测标签页。
在这里,您可以测试自己的模型,并查看自定义模型以及用于训练的基本模型的结果。
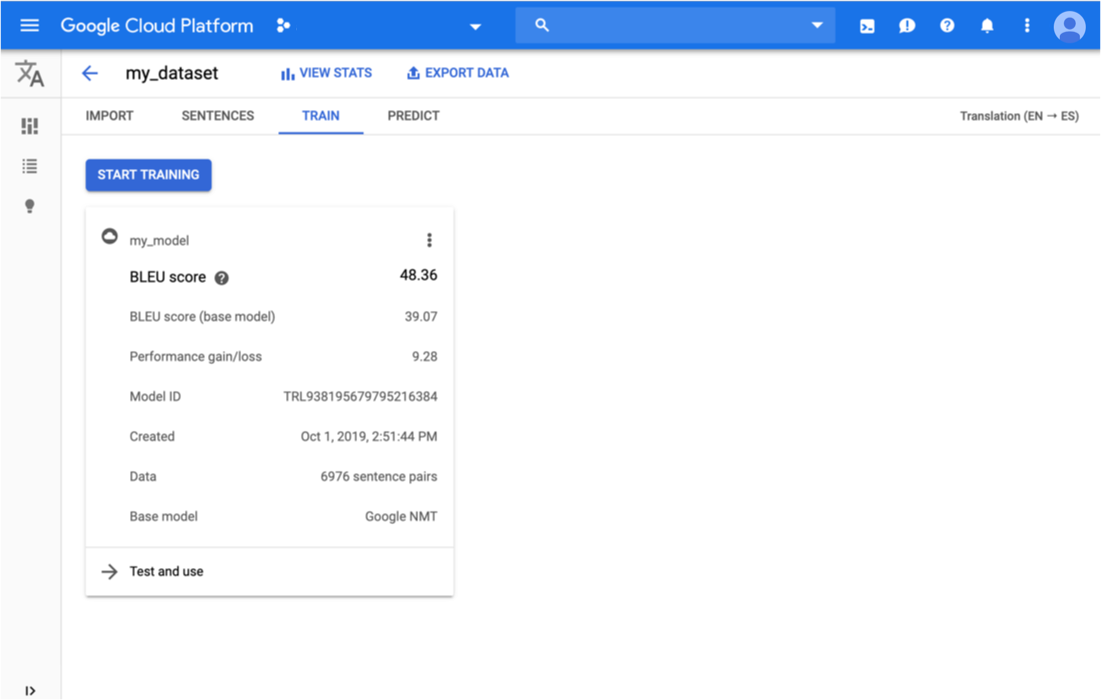
点击标题栏正下方的训练标签页。
如果该模型已完成训练,则 AutoML Translation 会显示其评估指标。
REST
在使用任何请求数据之前,请先进行以下替换:
- model-name:模型的完整名称。模型的完整名称包括您的项目名称和位置。模型名称类似于以下示例:
projects/project-id/locations/us-central1/models/model-id。 - project-id:您的 Google Cloud Platform 项目 ID
HTTP 方法和网址:
GET https://automl.googleapis.com/v1/model-name/modelEvaluations
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"modelEvaluation": [
{
"name": "projects/project-number/locations/us-central1/models/model-id/modelEvaluations/evaluation-id",
"createTime": "2019-10-02T00:20:30.972732Z",
"evaluatedExampleCount": 872,
"translationEvaluationMetrics": {
"bleuScore": 48.355409502983093,
"baseBleuScore": 39.071375131607056
}
}
]
}
Go
如需了解如何安装和使用 AutoML Translation 客户端库,请参阅 AutoML Translation 客户端库。如需了解详情,请参阅 AutoML Translation Go API 参考文档。
如需向 AutoML Translation 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
Java
如需了解如何安装和使用 AutoML Translation 客户端库,请参阅 AutoML Translation 客户端库。如需了解详情,请参阅 AutoML Translation Java API 参考文档。
如需向 AutoML Translation 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需了解如何安装和使用 AutoML Translation 客户端库,请参阅 AutoML Translation 客户端库。如需了解详情,请参阅 AutoML Translation Node.js API 参考文档。
如需向 AutoML Translation 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需了解如何安装和使用 AutoML Translation 客户端库,请参阅 AutoML Translation 客户端库。如需了解详情,请参阅 AutoML Translation Python API 参考文档。
如需向 AutoML Translation 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
其他语言
C#:请按照客户端库页面上的 C# 设置说明操作,然后访问 .NET 版 AutoML Translation 参考文档。
PHP:请按照客户端库页面上的 PHP 设置说明操作,然后访问 PHP 版 AutoML Translation 参考文档。
Ruby:请按照客户端库页面上的 Ruby 设置说明操作,然后访问 Ruby 版 AutoML Translation 参考文档。
导出带有模型预测的测试数据
在训练模型后,AutoML Translation 使用测试集中的训练项来评估新模型的质量和准确率。在 AutoML Translation 控制台中,您可以导出 TEST 集以查看模型输出与原始数据集中的参考文本的比较情况。AutoML Translation 会将 TSV 文件保存到您的 Google Cloud Storage 存储分区,其中每行都具有以下格式:
Source sentence 制表符 Reference translation 制表符 Model candidate translation
网页界面
打开 AutoML Translation 控制台,然后点击左侧导航栏中“模型”左侧的灯泡图标,以显示可用的模型。
如需查看其他项目的模型,请从标题栏右上角的下拉列表中选择该项目。
选择模型。
点击标题栏中的导出数据按钮。
输入要保存导出的 .tsv 文件的 Google Cloud Storage 存储分区的完整路径。
您必须使用与当前项目关联的存储分区。
选择要导出其测试数据的模型。
带有模型预测的测试集下拉列表列出了使用相同输入数据集训练的模型。
点击导出。
AutoML Translation 会在指定的 Google Cloud Storage 存储分区中写入名为 model-name
_evaluated.tsv的文件。
使用新的测试集对模型进行评估和比较
在 AutoML Translation 控制台中,您可以使用新的测试数据集重新评估现有模型。在单个评估中,您最多可以添加 5 个不同的模型,然后比较其结果。
将测试数据作为制表符分隔值 (.tsv) 文件或 Translation Memory eXchange (.tmx) 文件上传到 Cloud Storage。
AutoML Translation 会根据测试集评估模型,然后生成评估分数。您可以视情况将每个模型的结果以 .tsv 文件的形式保存在 Cloud Storage 存储分区中,其中每行都具有以下格式:
Source sentence tab Model candidate translation tab Reference translation
网页界面
打开 AutoML Translation 控制台,然后点击左侧导航窗格中的模型,以显示可用的模型。
如需查看其他项目的模型,请从标题栏右上角的下拉列表中选择该项目。
选择一个要评估的模型。
点击标题栏下方的评估标签页。
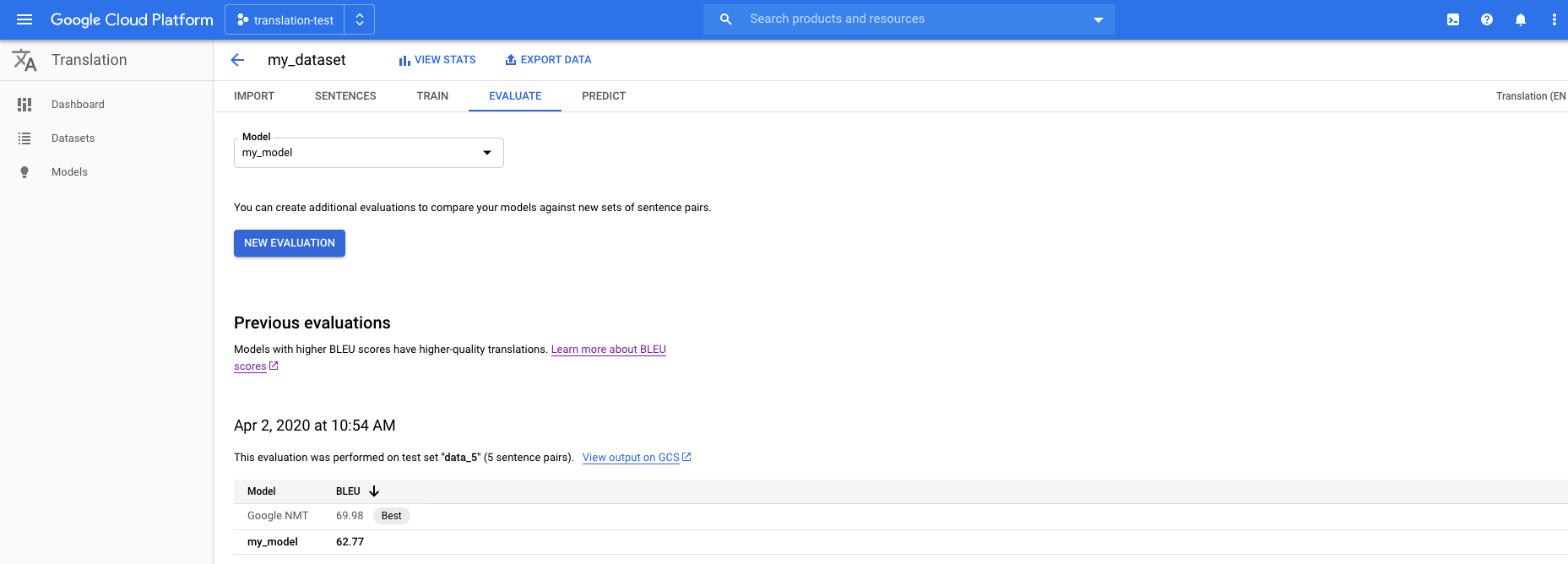
在评估标签页中,点击新建评估。
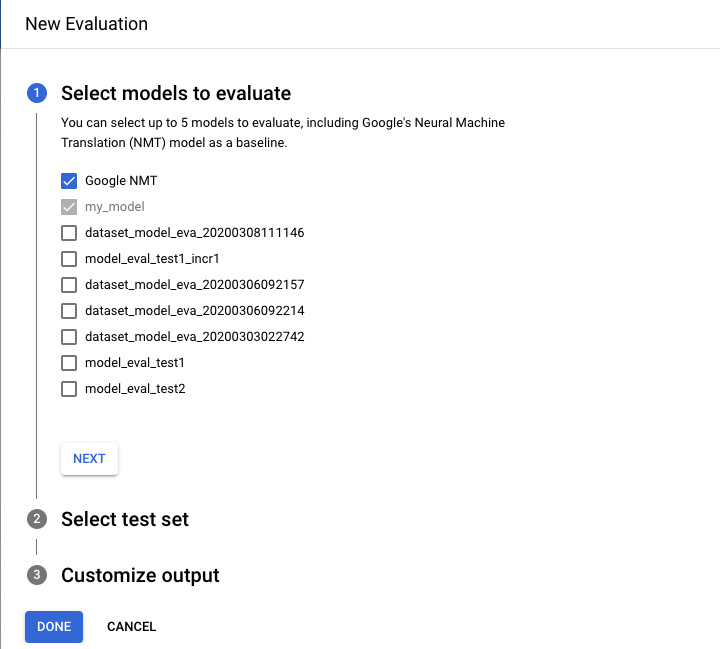
- 选择要执行评估和比较的模型。必须选择当前模型,默认选中的是 Google NMT,您可以取消选中。
- 为测试集名称指定一个名称,以帮助您将其与其他评估区分开来,然后从 Cloud Storage 中选择新的测试集。
- 如果要导出基于测试集的预测,请指定用于存储结果的 Cloud Storage 存储分区(按字符标准费率计算价格)。
点击完成。
AutoML Translation 评估完成后,会在控制台以表格格式显示评估分数。一次只能运行一个评估。如果您指定了用于存储预测结果的存储分区,则 AutoML Translation 会将名为 model-name_test-set-name
.tsv的文件写入该存储分区。
了解 BLEU 得分
BLEU (BiLingual Evaluation Understudy) 是一种自动评估机器翻译文本的指标。BLEU 得分是一个 0 到 1 之间的数字,用于衡量机器翻译文本与一组高质量参考翻译的相似度。0 表示机器翻译的输出与参考翻译没有重叠(低质量),而 1 表示其与参考翻译完全重叠(高质量)。
事实表明,BLEU 得分与人类对翻译质量的判断有很好的相关性。请注意,即使是人工翻译也无法达到 1.0 的满分。
AutoML 以百分比表示 BLEU 得分,而不是 0 到 1 之间的小数。
解释
我们强烈建议不要试图比较不同语料库和语言的 BLEU 得分。即使比较的语料库相同,但若参考译文的数量不同,其 BLEU 得分也可能具有很大的误导性。
但是,作为大致的参考,以下对 BLEU 得分的解释(以百分比而非小数表示)有一定的意义。
| BLEU 得分 | 解读 |
|---|---|
| < 10 | 几乎没用 |
| 10 - 19 | 很难理解要点 |
| 20 - 29 | 要点很清晰,但有明显的语法错误 |
| 30 - 40 | 从可以理解到质量良好的翻译 |
| 40 - 50 | 高质量的翻译 |
| 50 - 60 | 质量极高、理解充分、语言流畅的翻译 |
| > 60 | 质量经常高于人工翻译 |
以下颜色渐变可用作 BLEU 分数解释的一般量表:

数学细节
在数学上,BLEU 得分的定义为:
以及
\[ precision_i = \dfrac{\sum_{\text{snt}\in\text{Cand-Corpus}}\sum_{i\in\text{snt}}\min(m^i_{cand}, m^i_{ref})} {w_t^i = \sum_{\text{snt'}\in\text{Cand-Corpus}}\sum_{i'\in\text{snt'}} m^{i'}_{cand}} \]
其中:
- \(m_{cand}^i\hphantom{xi}\) 是匹配参考翻译的候选翻译中 i-gram 的数量
- \(m_{ref}^i\hphantom{xxx}\) 是参考翻译中 i-gram 的数量
- \(w_t^i\hphantom{m_{max}}\) 是候选翻译中 i-gram 的总数
该公式由两部分组成:简短惩罚因子和 n-gram 重叠度。
简短惩罚因子
简短惩罚因子惩罚与最接近的参考长度相比过短的生成翻译,且呈指数衰减。简短惩罚因子弥补了 BLEU 得分没有召回率项的缺陷。N 元语法重叠度
n 元语法重叠度计算有多少一元语法、二元语法、三元语法和四元语法 (i=1,...,4) 与参考翻译中 n 元语法对应内容匹配。该项充当精确率指标。1-gram 反映充分性,而较长的 n-gram 反映翻译的流畅性。为避免过度计数,n-gram 数量限制为参考翻译中出现的最大 n-gram 数 (\(m_{ref}^n\))。
示例
计算 \(precision_1\)
假设有以下参考翻译和候选翻译:
参考翻译:the cat is on the mat
候选翻译:the the the cat mat
第一步是计算参考翻译和候选翻译中每个 1-gram 的出现次数。请注意,BLEU 指标区分大小写。
| 1-gram | \(m_{cand}^i\hphantom{xi}\) | \(m_{ref}^i\hphantom{xxx}\) | \(\min(m^i_{cand}, m^i_{ref})\) |
|---|---|---|---|
the |
3 | 2 | 2 |
cat |
1 | 1 | 1 |
is |
0 | 1 | 0 |
on |
0 | 1 | 0 |
mat |
1 | 1 | 1 |
候选翻译中的 1-gram 的总数 (\(w_t^1\)) 为 5,因此 \(precision_1\) = (2 + 1 + 1)/5 = 0.8。
计算 BLEU 得分
参考翻译:The NASA Opportunity rover is battling a massive dust storm on Mars .
候选翻译 1:The Opportunity rover is combating a big sandstorm on Mars .
候选翻译 2:A NASA rover is fighting a massive storm on Mars .
以上示例包含一个参考翻译和两个候选翻译。 如上所述,在计算 BLEU 得分之前,系统会对句子进行词法单元化处理;例如,末尾的句号被计为一个单独的词法单元。
为了计算每个翻译的 BLEU 得分,我们需要计算以下统计信息。
- N 元语法精确率
下表包含两个候选翻译的 n 元语法精确率。 - 简短惩罚因子
候选翻译 1 和候选翻译 2 的简短惩罚因子是相同的,因为这两个句子都包含 11 个词法单元。 - BLEU 得分
请注意,若要使 BLEU 得分 > 0,至少需要有一个匹配的四元语法。 由于候选翻译 1 没有匹配的四元语法,因此它的 BLEU 得分为 0。
| 指标 | 候选翻译 1 | 候选翻译 2 |
|---|---|---|
| \(precision_1\) (1gram) | 8/11 | 9/11 |
| \(precision_2\) (2gram) | 4/10 | 5/10 |
| \(precision_3\) (3gram) | 2/9 | 2/9 |
| \(precision_4\) (4gram) | 0/8 | 1/8 |
| 简短惩罚因子 | 0.83 | 0.83 |
| BLEU 得分 | 0.0 | 0.27 |
属性
BLEU 是一个基于语料库的指标
当用于评估单个句子时,BLEU 指标表现不佳。例如,即使两个例句都翻出了大部分含义,但其 BLEU 得分仍可能很低。因为单个句子的 n-gram 统计信息意义不大,所以 BLEU 的设计是一个基于语料库的指标;也就是说,在计算得分时,统计信息在整个语料库中进行累积。请注意,上面定义的 BLEU 指标不能针对单个句子进行分解。实词和功能词之间没有区别
BLEU 指标不区分实词和功能词,也就是说,漏掉像“a”这样的功能词与“NASA”被错误替换为“ESA”一样会得到同样的惩罚。善于捕捉句子的含义和语法
漏掉“not”这样的单词会改变句子的极性。 此外,仅考虑 n≤4 的 n 元语法忽略了长程依赖性,因此 BLEU 通常只会为不符合语法的句子应用一个较小的惩罚因子。归一化和词法单元化
在计算 BLEU 得分之前,参考翻译和候选翻译都会进行归一化和词法单元化处理。归一化和词法单元化步骤的选择对最终 BLEU 得分有显著的影响。