Un conjunto de datos contiene muestras representativas del tipo de contenido que deseas traducir, como pares de oraciones equivalentes en los idiomas de origen y objetivo. El conjunto de datos sirve como entrada para entrenar un modelo.
Los pasos principales para compilar un conjunto de datos son:
- Crear un conjunto de datos y luego identificar los idiomas fuente y objetivo.
- Importar pares de oraciones al conjunto de datos.
Un proyecto puede tener varios conjuntos de datos, y cada uno se usa para entrenar un modelo diferente. Puedes obtener una lista de los conjuntos de datos disponibles y, también, borrar los conjuntos de datos que ya no necesites.
Crea un conjunto de datos
El primer paso cuando se crea un modelo personalizado es crear un conjunto de datos vacío que finalmente tendrá los datos de entrenamiento para el modelo. Cuando creas un conjunto de datos, identificas los idiomas fuente y objetivo para el modelo. Para obtener más información sobre los idiomas y las variantes admitidos, consulta Idiomas admitidos para modelos personalizados.
IU web
La IU de AutoML Translation te permite crear un conjunto de datos nuevo e importar elementos desde la misma página.
Visita la IU de AutoML Translation.
Selecciona el proyecto para el que habilitaste AutoML Translation de la lista desplegable en la parte superior derecha de la barra de título.
En la pestaña Conjuntos de datos (Datasets), haz clic en Crear conjunto de datos (Create Dataset).
En el diálogo Crear conjunto de datos, haz lo siguiente:
- Ingresa un nombre para el conjunto de datos.
Selecciona el idioma de origen y el idioma objetivo en las listas desplegables. Cuando seleccionas un idioma en Traducir del, aparecen los idiomas disponibles en Traducir al.
Haz clic en Crear. Se abrirá la pestaña Importar.
REST
Envía la solicitud de creación de conjunto de datos
A continuación, se muestra cómo enviar una solicitud POST al método project.locations.datasets/create.
En el ejemplo, se usa el token de acceso correspondiente a la configuración de una cuenta de servicio para el proyecto con Google Cloud CLI.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: el ID de tu proyecto de Google Cloud Platform
- dataset-name: el nombre de tu conjunto de datos nuevo
- source-language-code: el idioma desde el que deseas traducir, como un código ISO 639-1, como “en”
- target-language-code: el idioma al que deseas traducir, como un código ISO 639-1, como "es"
Método HTTP y URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/us-central1/datasets
Cuerpo JSON de la solicitud:
{
"displayName": "dataset-name",
"translationDatasetMetadata": {
"sourceLanguageCode": "source-language-code",
"targetLanguageCode": "target-language-code"
}
}
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"name": "projects/project-number/locations/us-central1/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-10-01T22:13:48.155710Z",
"updateTime": "2019-10-01T22:13:48.155710Z",
"createDatasetDetails": {}
}
}
Obtén los resultados
Para obtener los resultados de tu solicitud, debes enviar una solicitud GET al recurso operations. A continuación, se muestra cómo enviar una solicitud de este tipo.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- operation-name: el nombre de la operación como se muestra en la respuesta a la llamada original a la API
- project-id: el ID de tu proyecto de Google Cloud Platform
Método HTTP y URL:
GET https://automl.googleapis.com/v1/operation-name
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-10-01T22:13:48.155710Z",
"updateTime": "2019-10-01T22:13:52.321072Z",
...
},
"done": true,
"response": {
"@type": "resource-type",
"name": "resource-name"
}
}
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Go.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Java.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.

Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Node.js.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Python.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Lenguajes adicionales
C#: Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para PHP.
Ruby: Sigue lasInstrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para Ruby.
Importar elementos a un conjunto de datos
Luego de que hayas creado un conjunto de datos, puedes importar pares de oraciones de entrenamiento. Para obtener detalles sobre cómo preparar datos de entrenamiento, consulta Cómo preparar los datos de entrenamiento.
IU web
La IU de AutoML Translation te permite crear un conjunto de datos nuevo y, también, importar elementos a él desde la misma página (consulta Crea un conjunto de datos). Los pasos siguientes sirven para importar elementos a un conjunto de datos existente.
Después de crear la carpeta del conjunto de datos, debes subir tus datos.Sube los pares de oraciones que se usarán para entrenar el modelo.
En la pestaña Importar (Import), puedes subir archivos TSV o TMX desde tu computadora local o desde Cloud Storage. Para los archivos importados de forma local, después de seleccionar el archivo, haz clic en Examinar (Browse). Aparecerá una lista de carpetas. Selecciona la carpeta en la que deseas que se suba el archivo. Se requiere este directorio alojado en Cloud Storage para garantizar la residencia de los datos.
Selecciona la casilla de verificación de Usar archivos distintos para el entrenamiento, la validación y las pruebas (avanzado) (Use separate files for training, validation, and testing [advanced]), si deseas subir archivos distintos que contengan los pares de oraciones. Esta opción se recomienda si tu conjunto de datos tiene más de 100,000 pares de oraciones. Debes asignar 10,000 pares de oraciones como máximo para los conjuntos de validación y de prueba. De lo contrario, AutoML Translation muestra un error.
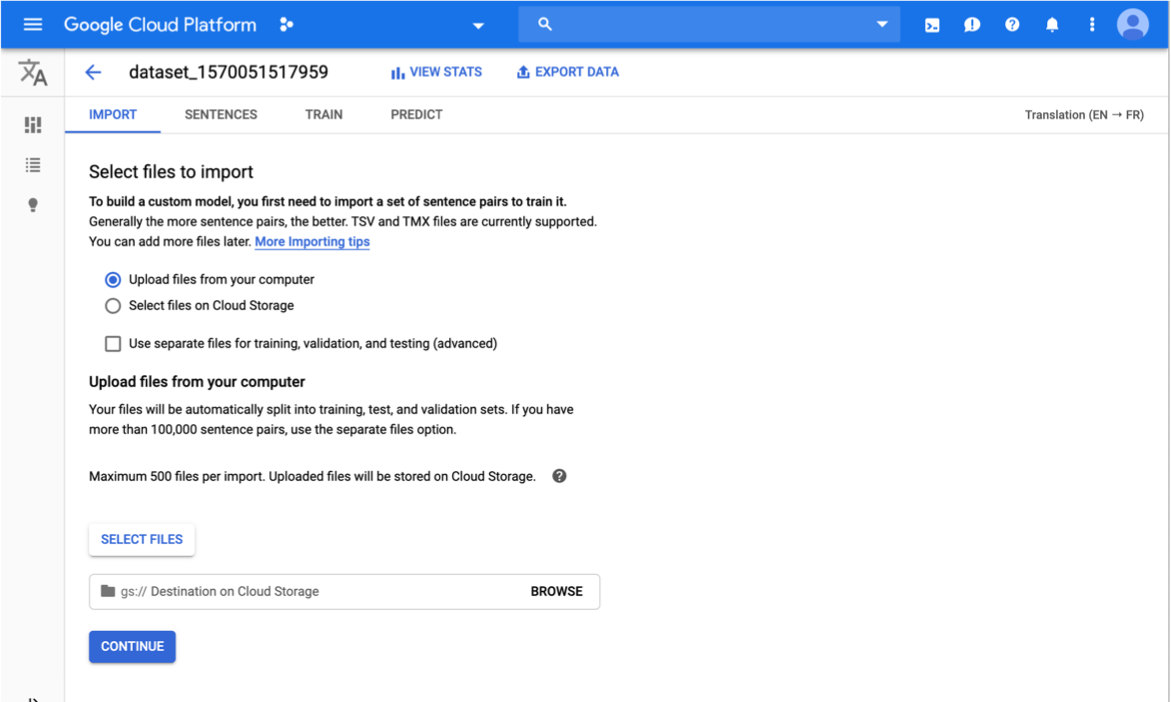
Haz clic en Continuar (Continue).
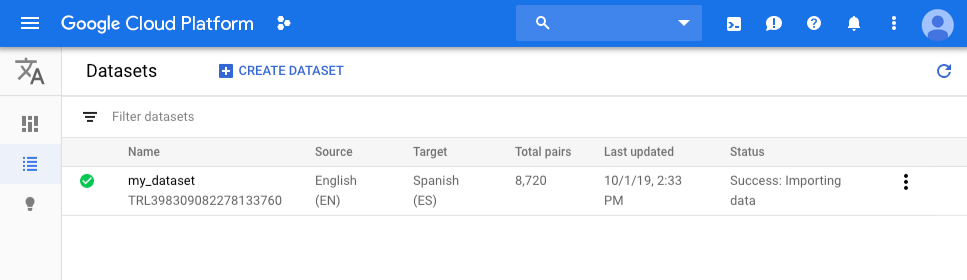
Volverás a la página Conjuntos de datos. El conjunto de datos muestra una animación en curso mientras se importan tus documentos. Cuando tu conjunto de datos se suba con éxito, recibirás un mensaje en la dirección de correo electrónico que usaste para registrarte en el programa.
Revisa el conjunto de datos.
Una vez que los datos se hayan importado con éxito, selecciona el conjunto de datos de la pestaña Conjuntos de datos para ver los detalles del conjunto de datos. La pestaña Oración está habilitada y muestra el nombre del conjunto de datos. Se crea una lista de los pares de oraciones. A cada par se le asigna “entrenamiento”, “validación” o “prueba”, a fin de indicar en qué etapa del procesamiento se usará.
REST
Usa el método projects.locations.datasets.importData para importar elementos a un conjunto de datos.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- dataset-name: es el nombre de tu conjunto de datos, como lo mostró la API cuando creaste el conjunto de datos.
- bucket-name: el depósito de Cloud Storage que contiene el archivo CSV de entrada que describe el conjunto de datos
- csv-file-name: el nombre del archivo CSV de entrada que describe el conjunto de datos.
- project-id: el ID de tu proyecto de Google Cloud Platform
Método HTTP y URL:
POST https://automl.googleapis.com/v1/dataset-name:importData
Cuerpo JSON de la solicitud:
{
"inputConfig": {
"gcsSource": {
"inputUris": "gs://bucket-name/csv-file-name"
}
}
}
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"name": "projects/project-number/locations/us-central1/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2018-04-27T01:28:36.128120Z",
"updateTime": "2018-04-27T01:28:36.128150Z",
"cancellable": true
}
}
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Go.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Java.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Node.js.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Python.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Lenguajes adicionales
C#: Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para PHP.
Ruby: Sigue lasInstrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para Ruby.
Una vez que hayas creado y propagado el conjunto de datos, estarás listo para entrenar el modelo (consulta: Administrar modelos).
Administra conjuntos de datos
Enumera conjuntos de datos
Un proyecto puede incluir numerosos conjuntos de datos. En esta sección, se describe cómo recuperar una lista de los conjuntos de datos disponibles para un proyecto.
IU web
Para ver una lista de los conjuntos de datos disponibles que usan la IU de AutoML Translation, haz clic en el vínculo Conjuntos de datos (Datasets) en la parte superior del menú de navegación de la izquierda.
Para ver los conjuntos de datos de otro proyecto, selecciónalo de la lista desplegable en la parte superior derecha de la barra de título.
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- project-id: el ID de tu proyecto de Google Cloud Platform
Método HTTP y URL:
GET https://automl.googleapis.com/v1/projects/project-id/locations/us-central1/datasets
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"datasets": [
{
"name": "projects/project-number/locations/us-central1/datasets/dataset-id",
"displayName": "dataset-display-name",
"createTime": "2019-10-01T22:47:38.347689Z",
"etag": "AB3BwFpPWn6klFqJ867nz98aXr_JHcfYFQBMYTf7rcO-JMi8Ez4iDSNrRW4Vv501i488",
"translationDatasetMetadata": {
"sourceLanguageCode": "source-language",
"targetLanguageCode": "target-language"
}
},
...
]
}
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Go.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Java.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Node.js.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Python.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Lenguajes adicionales
C#: Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para PHP.
Ruby: Sigue lasInstrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para Ruby.
Borrar un conjunto de datos
IU web
En la IU de AutoML Translation, haz clic en el vínculo Conjuntos de datos (Datasets) situado en la parte superior del menú de navegación de la izquierda para ver la lista de conjuntos de datos disponibles.
Haz clic en el menú de tres puntos en el extremo derecho de la fila que deseas borrar y selecciona Borrar.
Haz clic en Confirmar en el cuadro de diálogo de confirmación.
REST
- Reemplaza dataset-name con el nombre completo del conjunto de datos, de la respuesta cuando lo creaste. El nombre completo tiene el siguiente formato:
projects/{project-id}/locations/us-central1/datasets/{dataset-id}
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- dataset-name: el nombre del conjunto de datos que deseas borrar, en el formato
project/project-id/locations/us-central1/datasets/dataset-id
Método HTTP y URL:
DELETE https://automl.googleapis.com/v1/dataset-name
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"name": "projects/project-number/locations/us-central1/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1.OperationMetadata",
"createTime": "2019-10-02T16:43:03.923442Z",
"updateTime": "2019-10-02T16:43:03.923442Z",
"deleteDetails": {}
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Go.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Java.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Node.js.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Python.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Lenguajes adicionales
C#: Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para PHP.
Ruby: Sigue lasInstrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para Ruby.
Problemas de importación
Cuando creas un conjunto de datos, AutoML Translation puede descartar pares de oraciones si son demasiado largos o si los pares son exactamente los mismos en los idiomas de origen y destino.
En el caso de los pares de oraciones demasiado largos, te recomendamos que dividas las oraciones de aproximadamente 200 palabras o menos y, luego, vuelvas a crear el conjunto de datos para incluir los pares descartados. Mientras se procesan tus datos, AutoML Translation usa un proceso interno para asignar tokens a los datos de entrada, lo que puede aumentar el tamaño de las oraciones. Estos datos con tokens asignados son los que AutoML Translation usa para medir el tamaño de los datos. Por lo tanto, el límite de 200 palabras es una estimación para la longitud máxima.
En el caso de los pares de oraciones que son iguales en los idiomas de origen y objetivo, puedes quitarlos de tu conjunto de datos. Si quieres mantener estas oraciones sin traducir, usa un recurso de glosario para crear un diccionario personalizado que defina cómo AutoML Translation maneja términos específicos.