Introducción
Imagina que ejecutas un servicio de informes financieros y existe la oportunidad de expandirlo a nuevos países. En esos mercados, es necesario que tus documentos financieros urgentes se traduzcan en tiempo real. En lugar de contratar a personal financiero bilingüe o a un traductor especializado, que en ambos casos tienen un precio alto debido a la experiencia necesaria en el sector y a tu necesidad de una respuesta rápida, AutoML Translation te puede ayudar a automatizar el trabajo de traducción de manera escalable y a acceder a nuevos mercados con rapidez.
Pruébalo tú mismo
Si es la primera vez que usas Google Cloud, crea una cuenta para evaluar el rendimiento de Cloud Translation en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
Probar Cloud Translation gratis¿Por qué el aprendizaje automático (AA) es la herramienta correcta para este problema?
![]() La programación clásica requiere que el programador especifique paso a paso las instrucciones que la computadora debe seguir
Sin embargo, este enfoque rápidamente se vuelve inviable para la traducción. El lenguaje natural es complejo, y traducirlo también lo es: La traducción basada en reglas dejó de ser el mejor enfoque hace décadas. Ahora la traducción automática se realiza con un enfoque estadístico casi en su totalidad, con corpus masivos en paralelo que reemplazan a los expertos lingüistas que perfeccionan a mano los conjuntos de reglas cada vez más especializados.
La programación clásica requiere que el programador especifique paso a paso las instrucciones que la computadora debe seguir
Sin embargo, este enfoque rápidamente se vuelve inviable para la traducción. El lenguaje natural es complejo, y traducirlo también lo es: La traducción basada en reglas dejó de ser el mejor enfoque hace décadas. Ahora la traducción automática se realiza con un enfoque estadístico casi en su totalidad, con corpus masivos en paralelo que reemplazan a los expertos lingüistas que perfeccionan a mano los conjuntos de reglas cada vez más especializados.
Necesitas un sistema que puedas aplicar de forma general a una amplia variedad de situaciones de traducción, pero que se centre con precisión en tu caso práctico y en el dominio lingüístico específico de la tarea en los pares de idiomas que te interesan. En una situación en la que una secuencia de reglas específicas está destinada a expandirse de manera exponencial, necesitas un sistema que pueda aprender de los ejemplos. Por fortuna, los sistemas de aprendizaje automático tienen lo necesario para resolver este problema.
¿La API de Translation o AutoML Translation son herramientas adecuadas para mí?
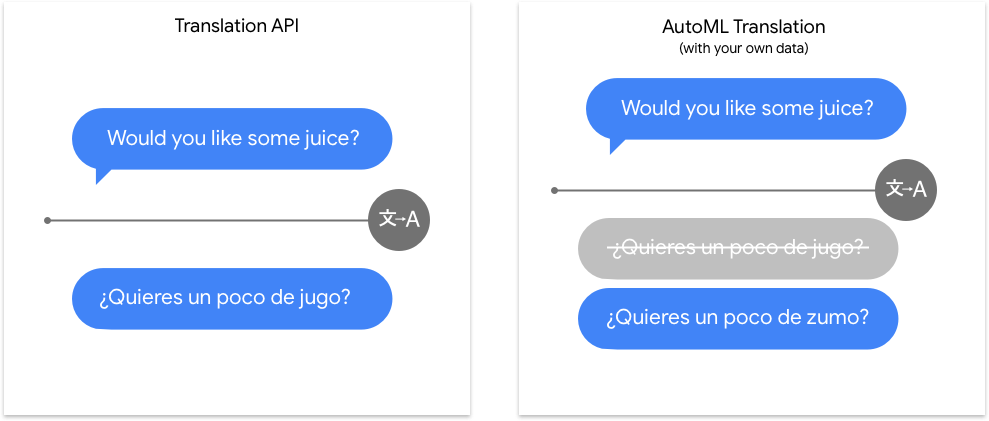
La API de Translation abarca una cantidad colosal de pares de idiomas y realiza un gran trabajo con textos de uso general. AutoML Translation se destaca sobre todo en el “trecho final” entre las tareas de traducción genéricas y los vocabularios específicos y especializados. Nuestros modelos personalizados parten del modelo genérico de API de Translation, pero agregan una capa que ayuda de forma específica a que el modelo genere la traducción correcta para el contenido específico del dominio que te interesa.
| Probar la API de Translation | Comenzar a usar AutoML |
¿Qué implica el aprendizaje automático en AutoML Translation?
![]() El aprendizaje automático implica el uso de datos para entrenar algoritmos a fin de lograr un resultado deseado. Los detalles de los métodos de entrenamiento y cambian en función del ámbito del problema. Existen muchas subcategorías diferentes de aprendizaje automático; todas ellas resuelven distintos problemas y funcionan con diferentes restricciones.
AutoML Translate te permite realizar un aprendizaje supervisado, que conlleva el entrenamiento de una computadora para que reconozca patrones de pares de oraciones traducidas.
Mediante el uso del aprendizaje supervisado, podemos entrenar un modelo personalizado para traducir contenido específico del dominio que te interesa.
El aprendizaje automático implica el uso de datos para entrenar algoritmos a fin de lograr un resultado deseado. Los detalles de los métodos de entrenamiento y cambian en función del ámbito del problema. Existen muchas subcategorías diferentes de aprendizaje automático; todas ellas resuelven distintos problemas y funcionan con diferentes restricciones.
AutoML Translate te permite realizar un aprendizaje supervisado, que conlleva el entrenamiento de una computadora para que reconozca patrones de pares de oraciones traducidas.
Mediante el uso del aprendizaje supervisado, podemos entrenar un modelo personalizado para traducir contenido específico del dominio que te interesa.
Preparación de datos
Para entrenar un modelo personalizado con AutoML Translation, debes proporcionar pares de oraciones coincidentes en los idiomas fuente y objetivo, es decir, pares de oraciones que tengan el mismo significado en el idioma desde y hacia el que deseas traducir. Por supuesto, la traducción no es una ciencia exacta, pero mientras más se parezca el significado de los pares de oraciones, mejor funcionará el modelo.
Evalúa tu caso práctico
Para crear el conjunto de datos, comienza siempre con el caso práctico. Puedes empezar con las siguientes preguntas:
- ¿Cuál es el resultado que buscas?
- ¿Qué tipos de oraciones necesitas traducir para lograr este resultado? ¿Es esta una tarea que la API de Translation puede hacer de manera predeterminada?
- ¿Podrían los traductores humanos traducir estas oraciones de una manera satisfactoria? Si la traducción es inherentemente ambigua hasta el punto de que una persona que domine ambos idiomas tendría dificultades para realizar un trabajo satisfactorio, es posible que el rendimiento de AutoML Translation sea similar.
- ¿Qué tipos de ejemplos reflejarían mejor el tipo y rango de datos que tendrá que traducir tu sistema?
Un principio fundamental en el que se basan los productos del AA de Google es el aprendizaje automático centrado en las personas, un enfoque que destaca las prácticas de IA responsables, incluida la equidad. El objetivo de la equidad en el AA es comprender y evitar un trato injusto o discriminatorio de las personas en relación con su origen étnico, orientación sexual, religión, género, ingresos y otras características asociadas históricamente con la discriminación y la exclusión, en el lugar y el momento en el que se manifiesten en los sistemas algorítmicos o en la toma de decisiones basada en algoritmos. Puedes leer más en nuestra guía y encontrar notas sobre “imparcialidad” ✽ en los lineamientos a continuación. A medida que avanzas a través de los lineamientos para armar tu conjunto de datos, te recomendamos que consideres la equidad en el aprendizaje automático cuando sea relevante para tu caso práctico.
Consigue tus datos
![]() Una vez establecidos los datos que necesitas, debes buscar una manera de obtenerlos. Puedes empezar por tener en cuenta todos los datos que recopila tu organización. Es posible que descubras que ya estás recopilando los datos que necesitarás para entrenar un modelo de traducción. Si no tienes los datos que necesitas, puedes obtenerlos de forma manual o encargar el proceso a un proveedor externo.
Una vez establecidos los datos que necesitas, debes buscar una manera de obtenerlos. Puedes empezar por tener en cuenta todos los datos que recopila tu organización. Es posible que descubras que ya estás recopilando los datos que necesitarás para entrenar un modelo de traducción. Si no tienes los datos que necesitas, puedes obtenerlos de forma manual o encargar el proceso a un proveedor externo.
Haz corresponder tus datos con el dominio del problema
![]() Estás entrenando un modelo de traducción personalizado porque necesitas que se ajuste a un dominio lingüístico particular. Asegúrate de que tus pares de oraciones abarquen de la mejor manera posible el vocabulario, el uso y las peculiaridades gramaticales de tu industria o área de enfoque. Busca documentos que contengan usos típicos que puedes encontrar en las tareas de traducción que desees realizar y asegúrate de que tus frases paralelas tengan un significado lo más similar posible. Sin duda, a veces el vocabulario y la sintaxis de los idiomas no se corresponden del todo, pero debes intentar capturar toda la diversidad de la semántica que esperas encontrar en uso, si es posible. Estás usando un modelo que ya realiza un gran trabajo con la traducción de uso general. Tus ejemplos son el último paso especial que hace que AutoML Translation funcione para tu caso práctico específico, así que asegúrate de que sean relevantes y representativos del uso que esperas ver.
Estás entrenando un modelo de traducción personalizado porque necesitas que se ajuste a un dominio lingüístico particular. Asegúrate de que tus pares de oraciones abarquen de la mejor manera posible el vocabulario, el uso y las peculiaridades gramaticales de tu industria o área de enfoque. Busca documentos que contengan usos típicos que puedes encontrar en las tareas de traducción que desees realizar y asegúrate de que tus frases paralelas tengan un significado lo más similar posible. Sin duda, a veces el vocabulario y la sintaxis de los idiomas no se corresponden del todo, pero debes intentar capturar toda la diversidad de la semántica que esperas encontrar en uso, si es posible. Estás usando un modelo que ya realiza un gran trabajo con la traducción de uso general. Tus ejemplos son el último paso especial que hace que AutoML Translation funcione para tu caso práctico específico, así que asegúrate de que sean relevantes y representativos del uso que esperas ver.
Captura la diversidad de tu espacio lingüístico
![]() Es tentador suponer que la manera en la que las personas escriben sobre un dominio específico es lo suficientemente uniforme como para que una cantidad limitada de muestras de textos a cargo de un número reducido de traductores sea suficiente a fin de entrenar un modelo que funcione bien para cualquier persona que escriba sobre ese dominio. Pero todos somos distintos e incluimos nuestra propia personalidad en las palabras que escribimos. Es más probable que un conjunto de datos de entrenamiento con pares de oraciones de una amplia selección de autores y traductores te proporcione un modelo útil para traducir los escritos de una organización diversa.
Además, considera la variedad de estructuras y longitudes de las oraciones, ya que un conjunto de datos en el que todas las oraciones tienen la misma longitud o comparten una estructura gramatical similar no le proporcionará a AutoML Translation la información suficiente para crear un buen modelo que capture todas las posibilidades.
Es tentador suponer que la manera en la que las personas escriben sobre un dominio específico es lo suficientemente uniforme como para que una cantidad limitada de muestras de textos a cargo de un número reducido de traductores sea suficiente a fin de entrenar un modelo que funcione bien para cualquier persona que escriba sobre ese dominio. Pero todos somos distintos e incluimos nuestra propia personalidad en las palabras que escribimos. Es más probable que un conjunto de datos de entrenamiento con pares de oraciones de una amplia selección de autores y traductores te proporcione un modelo útil para traducir los escritos de una organización diversa.
Además, considera la variedad de estructuras y longitudes de las oraciones, ya que un conjunto de datos en el que todas las oraciones tienen la misma longitud o comparten una estructura gramatical similar no le proporcionará a AutoML Translation la información suficiente para crear un buen modelo que capture todas las posibilidades.
Usa revisores manuales
![]() Si es posible, asegúrate de que una persona que entienda bien los dos idiomas valide que los pares de oraciones coincidan correctamente y representen traducciones comprensibles y precisas. Un error tan simple como alinear las filas de tu hoja de cálculo para los datos de entrenamiento de forma incorrecta puede dar como resultado traducciones sin sentido.
Lo más importante que le puedes brindar a AutoML Translation son datos de buena calidad a fin de obtener un modelo que tu empresa pueda utilizar.
Si es posible, asegúrate de que una persona que entienda bien los dos idiomas valide que los pares de oraciones coincidan correctamente y representen traducciones comprensibles y precisas. Un error tan simple como alinear las filas de tu hoja de cálculo para los datos de entrenamiento de forma incorrecta puede dar como resultado traducciones sin sentido.
Lo más importante que le puedes brindar a AutoML Translation son datos de buena calidad a fin de obtener un modelo que tu empresa pueda utilizar.
Limpia los datos desordenados
![]() Es fácil cometer errores al realizar el procesamiento previo de los datos, y algunos de estos errores pueden confundir a un modelo de AutoML Translation. En particular, busca los siguientes problemas de datos que puedes corregir:
Es fácil cometer errores al realizar el procesamiento previo de los datos, y algunos de estos errores pueden confundir a un modelo de AutoML Translation. En particular, busca los siguientes problemas de datos que puedes corregir:
- Quita las oraciones fuente duplicadas, en especial si tienen traducciones objetivo diferentes. AutoML Translation usa solo el primer ejemplo visto y descarta todos los otros pares al momento de la importación. Cuando quitas duplicados, te aseguras de que AutoML Translation use tu traducción preferida.
- Alinea las oraciones fuente con las oraciones objetivo correctas.
- Haz coincidir las oraciones con el idioma especificado; por ejemplo, incluye solo oraciones en chino en un conjunto de datos en ese idioma.
- En el caso de las oraciones objetivo que incluyen idiomas mixtos, verifica que las palabras no traducidas estén sin traducir de manera intencional, como los nombres de organizaciones o productos. Las oraciones objetivo que incluyen palabras no traducidas agregan ruido a tus datos de entrenamiento, lo que puede generar un modelo de baja calidad.
- Corrige las oraciones con errores tipográficos o gramaticales para que el modelo no aprenda estos errores.
- Quita el contenido que no se puede traducir, como las etiquetas de marcador de posición y HTML. El contenido que no se puede traducir puede generar errores de puntuación.
- Quita el contenido específico de la configuración regional. Es posible que la información que está destinada a diferentes lugares no sean traducciones directas, como números de teléfono de una configuración regional en particular.
- No incluyas traducciones que reemplacen entidades generales por sustantivos específicos. Por ejemplo, puedes tener un ejemplo que cambie “presidente” a un nombre de presidente específico, como “JFK” o “John F. Kennedy”. El modelo puede aprender a cambiar todas las instancias de “presidente” a “JFK”. En su lugar, quita estas traducciones o cambia los sustantivos específicos a uno común.
- Quita las oraciones duplicadas en los conjuntos de entrenamiento y prueba (más información sobre los conjuntos de entrenamiento y prueba)
- Divide varias oraciones en diferentes pares de oraciones. Los entrenamientos con conjuntos de datos cuyos elementos tienen alrededor de 50 tokens (palabras) o más dan como resultado modelos de baja calidad. Divide los elementos en oraciones individuales cuando sea posible.
- Usa mayúsculas y minúsculas coherentes. El uso de mayúsculas y minúsculas afecta la forma en la que un modelo aprende, por ejemplo, a distinguir un título frente al texto del cuerpo.
- Quita las etiquetas TMX cuando importes datos a un archivo TSV. En algunos casos, puedes exportar tu memoria de traducción existente a un archivo TSV, que puede incluir etiquetas TMX. Sin embargo, AutoML Translation limpia las etiquetas de unidades de traducción solo cuando importas el archivo TMX (no en los archivos TSV).
Cómo procesa AutoML tus datos
AutoML Translation dejará de analizar tu archivo de entrada de datos cuando:
- Haya un formato no válido
- Exista un par de oraciones excesivamente largo (10 MB)
- El archivo use una codificación que no sea UTF-8
AutoML Translation ignora los errores de problemas que puede detectar, como:
- Un elemento <tu> en un archivo TMX no tiene el idioma objetivo o fuente
- Uno de los pares de oraciones de entrada está vacío
En el modo de Distribución automática, AutoML Translation realiza un procesamiento adicional:
- Luego de que se suba el conjunto de datos, quita los pares de oraciones cuyas oraciones fuente sean idénticas.
- Divide aleatoriamente tus datos en tres conjuntos con una proporción de distribución de 8:1:1 antes del entrenamiento.
Considera cómo AutoML Translation usa tu conjunto de datos para crear un modelo personalizado
![]() Tu conjunto de datos contiene conjuntos de entrenamiento, validación y prueba. Si no especificas las divisiones (consulta Cómo preparar los datos de entrenamiento) y el conjunto de datos contiene menos de 100,000 pares de oraciones, AutoML Translation usa automáticamente el 80% de tus documentos de contenido para el entrenamiento, el 10% para la validación y el 10% para las pruebas. Si tus datos son más grandes, necesitarás realizar tu propia división de los datos.
Tu conjunto de datos contiene conjuntos de entrenamiento, validación y prueba. Si no especificas las divisiones (consulta Cómo preparar los datos de entrenamiento) y el conjunto de datos contiene menos de 100,000 pares de oraciones, AutoML Translation usa automáticamente el 80% de tus documentos de contenido para el entrenamiento, el 10% para la validación y el 10% para las pruebas. Si tus datos son más grandes, necesitarás realizar tu propia división de los datos.
Conjunto de entrenamiento
![]() La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento, y se usan para aprender los parámetros del modelo, en concreto, el peso de las conexiones entre los nodos de la red neuronal.
La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento, y se usan para aprender los parámetros del modelo, en concreto, el peso de las conexiones entre los nodos de la red neuronal.
Conjunto de validación
![]() El conjunto de validación, a veces llamado conjunto “dev”, también se usa durante el proceso de entrenamiento. Durante el aprendizaje del modelo, el marco de trabajo utiliza el conjunto de entrenamiento para entrenar un conjunto de modelos candidatos. Luego, usa el rendimiento del modelo en el conjunto de validación para seleccionar el mejor modelo generado. El marco usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican su estructura. Si usas el conjunto de entrenamiento para ajustar los hiperparámetros, el modelo podría terminar demasiado enfocado en tus datos de entrenamiento. El uso de un conjunto de datos original para ajustar la estructura del modelo permitirá que este realice mejores generalizaciones.
El conjunto de validación, a veces llamado conjunto “dev”, también se usa durante el proceso de entrenamiento. Durante el aprendizaje del modelo, el marco de trabajo utiliza el conjunto de entrenamiento para entrenar un conjunto de modelos candidatos. Luego, usa el rendimiento del modelo en el conjunto de validación para seleccionar el mejor modelo generado. El marco usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican su estructura. Si usas el conjunto de entrenamiento para ajustar los hiperparámetros, el modelo podría terminar demasiado enfocado en tus datos de entrenamiento. El uso de un conjunto de datos original para ajustar la estructura del modelo permitirá que este realice mejores generalizaciones.
Conjunto de prueba
![]() El conjunto de prueba no interviene para nada en el proceso de entrenamiento. Una vez que el modelo completa todo su entrenamiento, usamos el conjunto de prueba como un desafío nuevo para tu modelo. El rendimiento de tu modelo en el conjunto de prueba sirve para darte una idea bastante clara de cómo será su rendimiento en datos del mundo real.
El conjunto de prueba no interviene para nada en el proceso de entrenamiento. Una vez que el modelo completa todo su entrenamiento, usamos el conjunto de prueba como un desafío nuevo para tu modelo. El rendimiento de tu modelo en el conjunto de prueba sirve para darte una idea bastante clara de cómo será su rendimiento en datos del mundo real.
División manual
![]() AutoML puede dividir tus datos en conjuntos de entrenamiento, validación y prueba, o puedes hacerlo tú mismo si deseas tener un mayor control sobre el proceso, si prefieres una división del porcentaje diferente o si hay ejemplos específicos que deseas incluir con seguridad en alguna parte del ciclo de vida del entrenamiento del modelo.
AutoML puede dividir tus datos en conjuntos de entrenamiento, validación y prueba, o puedes hacerlo tú mismo si deseas tener un mayor control sobre el proceso, si prefieres una división del porcentaje diferente o si hay ejemplos específicos que deseas incluir con seguridad en alguna parte del ciclo de vida del entrenamiento del modelo.
Prepara tus datos para importarlos
Una vez que elijas entre la división manual o automática, tienes dos formas de agregar datos en AutoML Translation:
- Puedes importar datos como un archivo de valores separados por tabulaciones (TSV) que contiene oraciones fuente y objetivo, con un par de oraciones por línea.
- Puedes importar datos como un archivo TMX, un formato estándar para proporcionar pares de oraciones a herramientas de modelos de traducción automática (obtén más información sobre el formato TMX compatible). Si el archivo TMX contiene etiquetas XML no válidas, AutoML Translation las ignora. Si el archivo TMX no se ajusta a los formatos XML y TMX adecuados, por ejemplo, si falta una etiqueta final o un elemento <tmx>, AutoML Translation no lo procesará. AutoML Translation también finaliza el procesamiento y muestra un error si omite más de 1,024 elementos <tu> no válidos.
Evaluar
Una vez que tu modelo esté entrenado, recibirás un resumen de su rendimiento. Haz clic en la pestaña Entrenar luego de que el modelo haya completado el entrenamiento para ver un análisis detallado.
¿Qué debo tener en cuenta antes de evaluar mi modelo?
![]() La depuración de un modelo consiste más en depurar los datos que el modelo en sí. Si tu modelo comienza a actuar de manera inesperada mientras evalúas su rendimiento antes y después de pasar a producción, debes regresar y verificar tus datos para ver dónde podrían realizarse mejoras.
La depuración de un modelo consiste más en depurar los datos que el modelo en sí. Si tu modelo comienza a actuar de manera inesperada mientras evalúas su rendimiento antes y después de pasar a producción, debes regresar y verificar tus datos para ver dónde podrían realizarse mejoras.
Puntuación BLEU
La puntuación BLEU es una manera estándar de medir la calidad de un sistema de traducción automática. AutoML Translation usa una puntuación BLEU calculada a partir de los datos de prueba que proporcionaste como su métrica de evaluación primaria (obtén más información sobre las puntuaciones BLEU).
El modelo de NMT de Google, en el que se basa la API de Translation, se creó para uso general. Puede que no sea la mejor solución para ti si buscas una traducción especializada en tus propios campos. El modelo personalizado entrenado generalmente funciona mejor que el modelo de NMT en los campos con los que está relacionado tu conjunto de entrenamiento.
Luego de entrenar el modelo personalizado con tu propio conjunto de datos, la puntuación BLEU del modelo personalizado y del modelo de NMT de Google se mostrará en la pestaña Entrenar. También se obtiene un aumento en el rendimiento de la puntuación BLEU del modelo personalizado en la pestaña Entrenar. Cuánto más alta sea la puntuación BLEU, mejores traducciones te ofrecerá tu modelo para las oraciones que sean similares a tus datos de entrenamiento. Si la puntuación BLEU se encuentra entre 30 y 40, se considera que el modelo puede proporcionar buenas traducciones.
Probar tu modelo
![]() Incluso si la puntuación BLEU es buena, conviene que verifiques tú mismo el modelo para asegurarte de que el rendimiento coincide con tus expectativas. Si tus datos de entrenamiento y prueba se extraen del mismo conjunto de pruebas incorrecto, las puntuaciones podrían ser excelentes incluso si la traducción no tiene sentido. Imagina algunos ejemplos de verificación para ingresar en la pestaña Predecir de AutoML Translation y compáralos con los resultados del modelo base de NMT de Google, o bien usa las instrucciones en esa pestaña para llamar a la API de AutoML a fin de usar tu modelo en pruebas automatizadas. Puedes notar que tu modelo presenta las mismas predicciones que el modelo base, especialmente en oraciones cortas o si tienes un conjunto de entrenamiento más pequeño. Esto es normal porque el modelo base ya es bastante bueno para una amplia variedad de casos prácticos. Inténtalo con algunas oraciones más largas o complejas. Sin embargo, si todas tus oraciones resultan idénticas a las predicciones del modelo base, podría ser una indicación de un problema con los datos.
Incluso si la puntuación BLEU es buena, conviene que verifiques tú mismo el modelo para asegurarte de que el rendimiento coincide con tus expectativas. Si tus datos de entrenamiento y prueba se extraen del mismo conjunto de pruebas incorrecto, las puntuaciones podrían ser excelentes incluso si la traducción no tiene sentido. Imagina algunos ejemplos de verificación para ingresar en la pestaña Predecir de AutoML Translation y compáralos con los resultados del modelo base de NMT de Google, o bien usa las instrucciones en esa pestaña para llamar a la API de AutoML a fin de usar tu modelo en pruebas automatizadas. Puedes notar que tu modelo presenta las mismas predicciones que el modelo base, especialmente en oraciones cortas o si tienes un conjunto de entrenamiento más pequeño. Esto es normal porque el modelo base ya es bastante bueno para una amplia variedad de casos prácticos. Inténtalo con algunas oraciones más largas o complejas. Sin embargo, si todas tus oraciones resultan idénticas a las predicciones del modelo base, podría ser una indicación de un problema con los datos.
Si estás particularmente preocupado por un error que puede generar tu modelo (por ejemplo, una característica confusa de tu par de idiomas con la que generalmente tropiezan los traductores humanos, o un error de traducción que puede ser especialmente costoso en términos económicos o de reputación), asegúrate de que tu procedimiento o conjunto de prueba abarque ese caso de manera adecuada para que te sientas seguro cuando uses tu modelo en tareas diarias.