はじめに
新しい国々に展開する可能性のある財務報告サービスを運営していると想像してみてください。こうした市場では、時間的制約のある財務文書をリアルタイムで翻訳する必要があります。金融に関する専門知識や短納期での翻訳が必要なため、バイリンガルの金融スタッフを雇い、金融専門の翻訳者と契約すると費用がかさみます。代わりに、AutoML Translation を導入すれば、翻訳業務をスケーラブルに自動化でき、新しい市場に迅速に参入できます。
使ってみる
Google Cloud を初めて使用する場合は、アカウントを作成し、実際のシナリオで Cloud Translation のパフォーマンスを評価してみてください。新規のお客様には、ワークロードの実行、テスト、デプロイを行う際に使用できる無料クレジット $300 分を差し上げます。
Cloud Translation の無料トライアル機械学習(ML)がこの問題に適したツールである理由
![]() 従来のプログラミングでは、プログラマーが段階的な指示を与える必要があります。しかし、このアプローチを翻訳に適用するのは不可能です。自然言語は複雑であるため、翻訳もまた複雑です。ルールベースの翻訳は、数十年も前に最良のアプローチとは言えなくなりました。現在、機械翻訳のほとんどは統計的手法で行われています。言語の専門家が専門分野別のルールセットを手作業で細かく調整する代わりに、大規模な並列コーパスが使用されています。
従来のプログラミングでは、プログラマーが段階的な指示を与える必要があります。しかし、このアプローチを翻訳に適用するのは不可能です。自然言語は複雑であるため、翻訳もまた複雑です。ルールベースの翻訳は、数十年も前に最良のアプローチとは言えなくなりました。現在、機械翻訳のほとんどは統計的手法で行われています。言語の専門家が専門分野別のルールセットを手作業で細かく調整する代わりに、大規模な並列コーパスが使用されています。
求められているのは、幅広い翻訳シナリオに対して汎用化されているものの、対象となる言語ペアのユースケースやタスク固有の言語分野にもピンポイントで対応できるシステムです。一連の特定のルールが指数関数的に拡大することが想定される状況では、サンプルから学習できるシステムも必要です。こうした問題の解決に最適なのが機械学習システムです。
Translation API と AutoML Translation のどちらのツールが適切か
Translation API は膨大な数の言語ペアに対応しており、汎用テキストでその能力を発揮します。AutoML Translation の真価が発揮されるのは、汎用的な翻訳タスクと専門的でニッチな語彙をつなぐ「最後の工程」においてです。Google のカスタムモデルでは、汎用的な Translation API モデルから始まり、対象とする分野固有のコンテンツをモデルに正しく翻訳させるためのレイヤが追加されます。
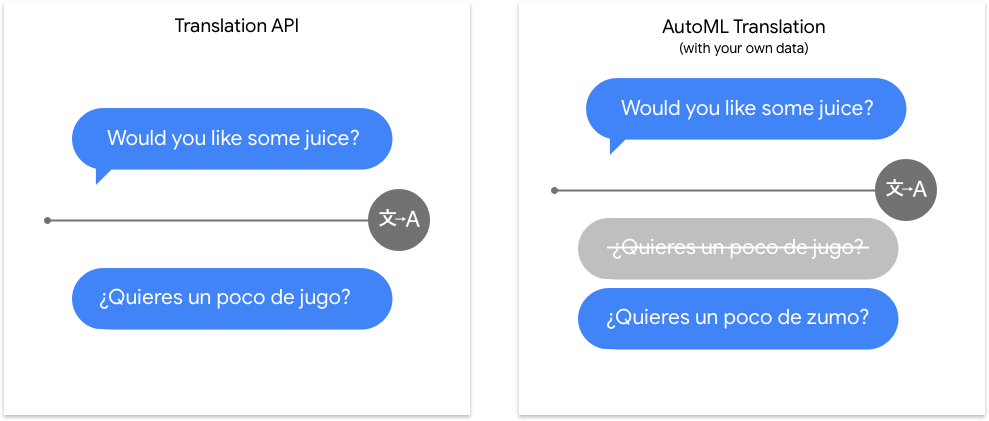
| Translation API を使ってみる | AutoML を使ってみる |
AutoML Translation の機械学習に含まれるもの
![]() 機械学習で望ましい結果を得るには、データを使用してアルゴリズムをトレーニングする必要があります。アルゴリズムの詳細やトレーニング方法は、問題空間に応じて変わります。機械学習にはさまざまなサブカテゴリがあり、それらはすべて異なる問題を解決し、異なる制約の中で動作します。AutoML Translation を使用すると、翻訳されたセンテンスのペアからパターンを認識するようにトレーニングする、教師付きの学習を実施できます。教師付きの学習を使用することで、対象となる分野固有のコンテンツを翻訳するようにカスタムモデルをトレーニングできます。
機械学習で望ましい結果を得るには、データを使用してアルゴリズムをトレーニングする必要があります。アルゴリズムの詳細やトレーニング方法は、問題空間に応じて変わります。機械学習にはさまざまなサブカテゴリがあり、それらはすべて異なる問題を解決し、異なる制約の中で動作します。AutoML Translation を使用すると、翻訳されたセンテンスのペアからパターンを認識するようにトレーニングする、教師付きの学習を実施できます。教師付きの学習を使用することで、対象となる分野固有のコンテンツを翻訳するようにカスタムモデルをトレーニングできます。
データ準備
AutoML Translation を使用してカスタムモデルをトレーニングするには、ソース言語とターゲット言語で対応するセンテンスのペア、つまり翻訳元の言語と翻訳先の言語で同じ内容を意味するセンテンスのペアを用意します。もちろん、翻訳が原文と完全に対応するとは限りませんが、センテンスのペアの意味が近いほど、モデルがうまく機能します。
ユースケースを検討する
データセットを用意するときは、常にユースケースの検討から始めます。まずは以下の点を考慮します。
- どのような結果を得ようとしているのか。
- その結果を得るために、どのようなセンテンスを翻訳する必要があるか。この作業には Translation API をそのまま使えるか。
- 人間が十分な品質でそのセンテンスを翻訳できるか。両方の言語に堪能な人でも十分な仕上がりを見込めないほど、その翻訳タスクが本質的に曖昧である場合、AutoML Translation の翻訳結果も同様の品質になると考えられます。
- システムに翻訳させる必要があるデータの種類と範囲を最もよく表すのは、どのようなサンプルか。
Google の ML プロダクトを支える基本原則は、人間を中心とした機械学習です。これは責任ある AI への取り組みを重視したアプローチであり、公平性への取り組みなどが含まれます。ML における公平性の目的とは、過去に差別や過小評価の対象になった人種、収入、性的志向、宗教、性別などの特性を理解し、そのような特性がアルゴリズム システムやアルゴリズムによる意思決定に現れる場合に、不公平で偏見的な扱いを防止することです。詳細についてはガイドをお読みいただくか、ガイドラインの「公平性の認識」の注記 ✽ でご確認いただけます。データセットを用意するためのガイドラインを読み進めながら、ご自身のユースケースに関係するところで機械学習における公平性について検討してみてください。
データを調達する
![]() 必要なデータが決まったら、データの調達方法を見つける必要があります。まず、組織で現在収集しているあらゆるデータを考慮に入れるところから始めます。モデルのトレーニングに必要なデータがすでに収集されている場合もあります。必要なデータがない場合、自力で収集することも、サードパーティ プロバイダにデータの収集を委託することもできます。
必要なデータが決まったら、データの調達方法を見つける必要があります。まず、組織で現在収集しているあらゆるデータを考慮に入れるところから始めます。モデルのトレーニングに必要なデータがすでに収集されている場合もあります。必要なデータがない場合、自力で収集することも、サードパーティ プロバイダにデータの収集を委託することもできます。
データを問題の分野に合わせる
![]() 特定の言語分野に適合するモデルが必要なため、カスタム翻訳モデルをトレーニングしているとします。このとき、センテンスのペアが、対象の業界や分野の語彙、用例、文法上の特徴をできる限り網羅するようにしてください。対象となる翻訳タスクで典型的な用法を含むドキュメントを探し、対応するフレーズの意味ができる限り近いことを確認してください。もちろん、言語間で語彙や構文が完全に対応しない場合もありますが、できれば、使用されている多様な語義をとらえるように努めてください。AutoML Translation は、汎用的な翻訳ですでに高い成果を達成しているモデルを土台にして構築されます。AutoML Translation をユースケースに特化して機能させるための特別な最終ステップとしてサンプルを提供してください。また、想定した使用方法に関連する典型的なサンプルであることを確認してください。
特定の言語分野に適合するモデルが必要なため、カスタム翻訳モデルをトレーニングしているとします。このとき、センテンスのペアが、対象の業界や分野の語彙、用例、文法上の特徴をできる限り網羅するようにしてください。対象となる翻訳タスクで典型的な用法を含むドキュメントを探し、対応するフレーズの意味ができる限り近いことを確認してください。もちろん、言語間で語彙や構文が完全に対応しない場合もありますが、できれば、使用されている多様な語義をとらえるように努めてください。AutoML Translation は、汎用的な翻訳ですでに高い成果を達成しているモデルを土台にして構築されます。AutoML Translation をユースケースに特化して機能させるための特別な最終ステップとしてサンプルを提供してください。また、想定した使用方法に関連する典型的なサンプルであることを確認してください。
言語空間の多様性を考慮する
![]() 特定の分野に関して人が文章を書く方法はほぼ統一されており、少数の翻訳者によって翻訳された少量のテキスト サンプルがあれば、その分野について誰が書いた文章でも通用するモデルをトレーニングするのに十分であると考えたくなりますが、人には個性があり、それが書き方に現れます。幅広い著者や翻訳者によるセンテンスペアが含まれているトレーニング データセットを用意することで、多様な組織の文章の翻訳に役立つモデルを構築できる可能性が高くなります。また、センテンスの長さや構造の多様性も考慮してください。データセット内のすべてのセンテンスが同じサイズの場合や、文法構造が似ている場合、AutoML Translation に十分な情報が与えられず、あらゆる可能性に対応できる優れたモデルを構築できません。
特定の分野に関して人が文章を書く方法はほぼ統一されており、少数の翻訳者によって翻訳された少量のテキスト サンプルがあれば、その分野について誰が書いた文章でも通用するモデルをトレーニングするのに十分であると考えたくなりますが、人には個性があり、それが書き方に現れます。幅広い著者や翻訳者によるセンテンスペアが含まれているトレーニング データセットを用意することで、多様な組織の文章の翻訳に役立つモデルを構築できる可能性が高くなります。また、センテンスの長さや構造の多様性も考慮してください。データセット内のすべてのセンテンスが同じサイズの場合や、文法構造が似ている場合、AutoML Translation に十分な情報が与えられず、あらゆる可能性に対応できる優れたモデルを構築できません。
担当者が必ず確認を行う
![]() 可能であれば、両言語をよく理解する人が、センテンスペアが正確に一致し、わかりやすく正確な翻訳になっていることを確認してください。トレーニング データのスプレッドシートの行がずれるなどの単純なミスで、まったく意味不明な翻訳になる場合があります。ビジネスに役立つモデルを実現するには、AutoML Translation に高品質のデータを提供することが非常に重要です。
可能であれば、両言語をよく理解する人が、センテンスペアが正確に一致し、わかりやすく正確な翻訳になっていることを確認してください。トレーニング データのスプレッドシートの行がずれるなどの単純なミスで、まったく意味不明な翻訳になる場合があります。ビジネスに役立つモデルを実現するには、AutoML Translation に高品質のデータを提供することが非常に重要です。
データをクリーンアップする
![]() データの前処理ではミスが起きやすく、それが AutoML Translation モデルをひどく混乱させる場合があります。特に、データに関する修正可能な次の問題を見つけてください。
データの前処理ではミスが起きやすく、それが AutoML Translation モデルをひどく混乱させる場合があります。特に、データに関する修正可能な次の問題を見つけてください。
- 重複するソースの文を削除します(特に、ターゲットの翻訳言語が異なる場合)。AutoML Translation は最初に検出されたサンプルのみを使用し、インポート時に他のすべてのペアを削除します。重複を削除すると、AutoML Translation が優先の翻訳言語を使用するようになります。
- ソースの文を正しいターゲットの文に合わせます。
- 指定された言語に対して文を照合します。たとえば、中国語のデータセットには中国語の文のみを含めます。
- 複数の言語が混在する訳文の場合は、未翻訳の単語がプロダクトや組織の名前など、意図して翻訳しない状態を保持されている単語であることを確認します。翻訳されていない単語を誤って含んだターゲット センテンスにより、トレーニング データにノイズが発生し、モデルの品質が低下する可能性があります。
- モデルがこれらのエラーを学習しないように、入力ミスや文法的な誤りのある文を修正します。
- プレースホルダ タグや HTML タグなど、翻訳できないコンテンツは削除します。翻訳できないコンテンツは句読点エラーとなる可能性があります。
- ロケール固有のコンテンツを削除します。異なる地域を対象とした情報(特定のロケールの電話番号など)は、直訳にならない場合があります。
- 一般的なエンティティを固有名詞に置き換える翻訳は含めないでください。たとえば、「大統領」を「JFK」や「ジョン F ケネディ」のような特定の大統領の名前に変更するような例があります。このモデルは、「大統領」をすべて「JFK」に変更するように学習する可能性があります。代わりに、そのような翻訳を削除するか、固有名詞を普通名詞に変更してください。
- トレーニング セットとテストセットで重複するセンテンスを削除します(トレーニング セットとテストセットの詳細をご覧ください)。
- 複数の文を異なる文のペアに分割します。多数のアイテムに 50 以上のトークン(単語)が含まれているデータセットをトレーニングすると、モデルの品質が低くなります。可能な場合は、アイテムを個々のセンテンスに分割してください。
- 大文字と小文字に一貫性を持たせます。大文字と小文字の区別は、たとえば、見出しと本文の識別など、モデルがどのように学習するかに影響を与えます。
- TSV ファイルからデータをインポートする際は、TMX タグを削除します。場合によっては、既存の翻訳メモリを TSV ファイルにエクスポートすることもあります。このファイルには TMX タグが含まれる場合があります。ただし、AutoML Translation では、TMX ファイルのインポート時にのみ、翻訳単位タグがクリーンアップされます(TSV ファイルの場合はクリーンアップされません)。
AutoML によるデータの前処理方法
AutoML Translation では、以下の場合にデータ入力ファイルの解析を停止します。
- 無効な書式が含まれている
- 異常に長いセンテンスペア(10 MB)がある
- ファイルに UTF-8 以外のエンコーディングが使用されている
AutoML Translation では、以下のような検出可能な問題に関するエラーが無視されます。
- TMX ファイルの <tu> 要素に、ソース言語またはターゲット言語がない。
- 入力センテンスペアの一方が空である。
AutoSplit モードでは、以下の追加処理が行われます。
- データセットがアップロードされた後、同じソース センテンスがあるセンテンスペアを削除する。
- トレーニングの前に、データを分割比 8:1:1 でランダムに 3 つのセットに分割する。
カスタムモデルの作成時に AutoML Translation がどのようにデータセットを使用するかを考慮する
![]() データセットには、トレーニング セット、検証セット、テストセットが含まれます。データセットの分割を指定せず(トレーニング データの準備を参照)、データセットに含まれるセンテンスペアが 100,000 個未満の場合、AutoML Translation では、コンテンツ ドキュメントの 80% がトレーニングに、10% が検証に、10% がテストに自動的に使用されます。これより大規模なデータの場合は、ご自身でデータを分割する必要があります。
データセットには、トレーニング セット、検証セット、テストセットが含まれます。データセットの分割を指定せず(トレーニング データの準備を参照)、データセットに含まれるセンテンスペアが 100,000 個未満の場合、AutoML Translation では、コンテンツ ドキュメントの 80% がトレーニングに、10% が検証に、10% がテストに自動的に使用されます。これより大規模なデータの場合は、ご自身でデータを分割する必要があります。
トレーニング セット
![]() データの大部分をトレーニング セットに含めるようにします。これはトレーニング中にモデルが「見る」データであり、モデルのパラメータ、つまりニューラル ネットワークのノード間の接続の重みを学習するために使用されます。
データの大部分をトレーニング セットに含めるようにします。これはトレーニング中にモデルが「見る」データであり、モデルのパラメータ、つまりニューラル ネットワークのノード間の接続の重みを学習するために使用されます。
検証セット
![]() 検証セット(「dev」セットとも呼ばれる)はトレーニング プロセス中にも使用されます。モデルの学習中、フレームワークではトレーニング セットを使用して一連の候補モデルがトレーニングされ、検証セットに対するモデルのパフォーマンスを考慮して、生成されたモデルの中から最適なものが選択されます。また、検証セットに対するモデルのパフォーマンスを考慮することで、モデルのハイパーパラメータ(モデルの構造を指定する変数)の調整も可能になります。ハイパーパラメータの調整にトレーニング セットを使用すると、モデルがトレーニング データに過度に適合してしまいます。多少違ったデータセットを使ってモデル構造を細かく調整することで、モデルがより適切に一般化されます。
検証セット(「dev」セットとも呼ばれる)はトレーニング プロセス中にも使用されます。モデルの学習中、フレームワークではトレーニング セットを使用して一連の候補モデルがトレーニングされ、検証セットに対するモデルのパフォーマンスを考慮して、生成されたモデルの中から最適なものが選択されます。また、検証セットに対するモデルのパフォーマンスを考慮することで、モデルのハイパーパラメータ(モデルの構造を指定する変数)の調整も可能になります。ハイパーパラメータの調整にトレーニング セットを使用すると、モデルがトレーニング データに過度に適合してしまいます。多少違ったデータセットを使ってモデル構造を細かく調整することで、モデルがより適切に一般化されます。
テストセット
![]() テストセットはトレーニング プロセスにはまったく使用されません。モデルのトレーニングが完了したら、モデル向けのまったく新しい課題としてテストセットを使用します。テストセットに対するモデルのパフォーマンスから、実世界のデータに対するモデルのパフォーマンスをおおよそ推測できます。
テストセットはトレーニング プロセスにはまったく使用されません。モデルのトレーニングが完了したら、モデル向けのまったく新しい課題としてテストセットを使用します。テストセットに対するモデルのパフォーマンスから、実世界のデータに対するモデルのパフォーマンスをおおよそ推測できます。
手動分割
![]() AutoML では、データをトレーニング セット、検証セット、テストセットに分割できます。より詳細にプロセスを制御する場合や、異なる比率でデータを分割する場合、モデルのトレーニング ライフサイクルの特定の部分に特定のサンプルを確実に含める場合は、手動でデータを分割することもできます。
AutoML では、データをトレーニング セット、検証セット、テストセットに分割できます。より詳細にプロセスを制御する場合や、異なる比率でデータを分割する場合、モデルのトレーニング ライフサイクルの特定の部分に特定のサンプルを確実に含める場合は、手動でデータを分割することもできます。
インポートするデータを準備する
データの手動分割と自動分割のどちらが適切かを判断したら、2 つの方法で AutoML Translation にデータを追加できます。
- 1 行あたり 1 つのセンテンスペアが配置された、ソースとターゲットのセンテンスからなるタブ区切り値(TSV)ファイルとしてデータをインポートできます。
- 自動翻訳モデルツールにセンテンスペアを提供する際の標準形式である TMX ファイルでデータをインポートできます(サポートされる TMX 形式の詳細については、ごちらをご覧ください)。TMX ファイルに無効な XML タグが含まれている場合、AutoML Translation では無視されます。ファイルが XML と TMX の正しい形式に従っていない場合(たとえば、終了タグや <tmx> 要素がない場合)、AutoML Translation はそのファイルを処理しません。AutoML Translation は、1,024 個を超える無効な <tu> 要素をスキップした場合も処理を終了してエラーを返します。
評価
モデルのトレーニングが終了すると、モデルのパフォーマンスの要約が届きます。詳細な分析を表示するには、モデルでのトレーニングが完了した後に [トレーニング] タブをクリックします。
モデルを評価する前の留意点
![]() モデルのデバッグは、モデル自体よりもデータを対象とするものです。本番環境への移行前後でモデルのパフォーマンスを評価しているときに、モデルが予期しない動作をするようになった場合は、いったん戻ってデータをチェックし、改善が必要な箇所を見つける必要があります。
モデルのデバッグは、モデル自体よりもデータを対象とするものです。本番環境への移行前後でモデルのパフォーマンスを評価しているときに、モデルが予期しない動作をするようになった場合は、いったん戻ってデータをチェックし、改善が必要な箇所を見つける必要があります。
BLEU スコア
BLEU スコアは、機械翻訳システムの品質を測定するための標準的な方法です。AutoML Translation では、提供したテストデータに対して計算された BLEU スコアを主な評価指標として使用します(BLEU スコアの詳細については、こちらをご覧ください)。
Translation API で使用されている Google NMT モデルは、一般的な使用方法を想定して構築されています。独自の分野に特化した翻訳をお求めの場合には最良の方法ではないかもしれません。トレーニングされたカスタムモデルは、一般的にトレーニング セットに関連する分野の NMT モデルよりも優れています。
独自のデータセットを使用してカスタムモデルをトレーニングすると、カスタムモデルと Google NMT モデルの BLEU スコアが [トレーニング] タブに表示されます。また、[トレーニング] タブには、カスタムモデルで得た BLEU スコアのパフォーマンスも表示されています。BLEU スコアが高いほど、トレーニング データに類似した文章のモデルでの翻訳が向上します。BLEU スコアが 30~40 の範囲内にある場合、モデルは良質な翻訳を提供できると考えられます。
モデルをテストする
![]() BLEU スコアに問題がない場合でも、パフォーマンスが予想どおりであることを確かめるためにモデルの正常性チェックを実施することをおすすめします。トレーニング データとテストデータが、誤りが含まれる同一のサンプルセットから抽出されている場合、翻訳が意味不明であっても、高スコアが発生する可能性があります。正常性チェックに使うサンプルを用意して AutoML Translation の [予測] タブに入力します。Google NMT ベースモデルの結果と比較するか、このタブの指示に従って AutoML API を呼び出して、ご自身のモデルで自動テストを行います。特にセンテンスが短い場合やトレーニング セットのサイズが小さい場合は、モデルがベースモデルと同じ予測をするかもしれません。これは予想外の結果ではありません。ベースモデルはすでに幅広いユースケースに適しているからです。長く複雑なセンテンスで試してみてください。ただし、すべてのセンテンスがベースモデルでの予測と同じになった場合、データに問題があることを示している可能性があります。
BLEU スコアに問題がない場合でも、パフォーマンスが予想どおりであることを確かめるためにモデルの正常性チェックを実施することをおすすめします。トレーニング データとテストデータが、誤りが含まれる同一のサンプルセットから抽出されている場合、翻訳が意味不明であっても、高スコアが発生する可能性があります。正常性チェックに使うサンプルを用意して AutoML Translation の [予測] タブに入力します。Google NMT ベースモデルの結果と比較するか、このタブの指示に従って AutoML API を呼び出して、ご自身のモデルで自動テストを行います。特にセンテンスが短い場合やトレーニング セットのサイズが小さい場合は、モデルがベースモデルと同じ予測をするかもしれません。これは予想外の結果ではありません。ベースモデルはすでに幅広いユースケースに適しているからです。長く複雑なセンテンスで試してみてください。ただし、すべてのセンテンスがベースモデルでの予測と同じになった場合、データに問題があることを示している可能性があります。
モデル作成について特に心配しているミスがある場合(たとえば、言語ペアに関する翻訳者が陥りやすい文法上の落とし穴や、金銭的にも評判にも大きな損失を招く翻訳ミスなど)、日々の業務でモデルを安心して使用できるように、テストセットや手順がそのミスに適切に対応していることを確認してください。