Introduction
Imaginez que vous gérez un service de rapports financiers qui a l'opportunité de s'étendre à de nouveaux pays. Ces marchés nécessitent que les documents financiers urgents soient traduits en temps réel. Au lieu de recruter un employé bilingue ou de faire appel à un traducteur spécialisé, tous deux très onéreux du fait de leur expertise du domaine et des délais d'exécution courts, pensez à automatiser vos tâches de traduction de manière évolutive et à vous développer rapidement sur de nouveaux marchés en adoptant AutoML Translation.
Faites l'essai
Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de Cloud Translation en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
Profiter d'un essai gratuit de Cloud TranslationEn quoi un système de machine learning (ML) constitue-t-il un outil adapté pour résoudre ce problème ?
![]() Généralement, un programme suppose que le programmeur spécifie des instructions détaillées que l'ordinateur doit suivre. Dans le domaine de la traduction, cette approche devient rapidement impossible. Le langage naturel est complexe, et sa traduction l'est également : cela fait des décennies que la traduction basée sur des règles n'est plus la meilleure approche. Désormais, la traduction automatique est presque entièrement réalisée selon une approche statistique, grâce à de grands corpus parallèles qui remplacent les experts en linguistique. Ceux-ci peaufinent manuellement des ensembles de règles de plus en plus spécialisés.
Généralement, un programme suppose que le programmeur spécifie des instructions détaillées que l'ordinateur doit suivre. Dans le domaine de la traduction, cette approche devient rapidement impossible. Le langage naturel est complexe, et sa traduction l'est également : cela fait des décennies que la traduction basée sur des règles n'est plus la meilleure approche. Désormais, la traduction automatique est presque entièrement réalisée selon une approche statistique, grâce à de grands corpus parallèles qui remplacent les experts en linguistique. Ceux-ci peaufinent manuellement des ensembles de règles de plus en plus spécialisés.
Il vous faut un système capable de généraliser un modèle à une grande diversité de scénarios de traduction, mais qui s'adapte particulièrement à votre cas d'utilisation et au domaine linguistique de vos tâches, dans les combinaisons linguistiques qui vous intéressent. Nous avons ici affaire à un cas de figure où l'adoption d'une séquence de règles spécifiques vous mènera forcément à une impasse, car elle est condamnée à se développer de manière exponentielle. Vous devez plutôt opter pour un système capable d'apprendre à partir d'exemples. Heureusement, les systèmes de machine learning constituent des outils idéaux pour résoudre ce problème.
De l'API Translation ou d'AutoML Translation, quel est l'outil adapté à mon cas ?
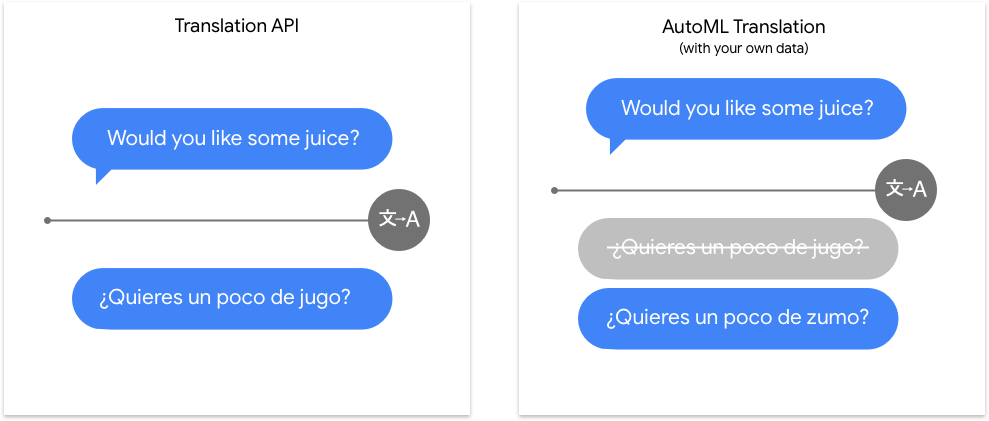
L'API Translation couvre un grand nombre de combinaisons linguistiques et est très efficace avec du texte polyvalent. AutoML Translation se démarque vraiment pour la dernière étape qui distingue les tâches de traduction génériques de celles impliquant un vocabulaire de niche spécifique. Nos modèles personnalisés appliquent d'abord le modèle générique de l'API Translation, puis ajoutent une couche qui aide spécifiquement le modèle à obtenir la traduction appropriée au contenu dans le domaine concerné.
| Essayer l'API Translation | Premiers pas avec AutoML |
Qu'implique le machine learning dans AutoML Translation ?
![]() Le machine learning implique l'utilisation de données pour entraîner des algorithmes afin d'obtenir le résultat souhaité. Les spécificités de l'algorithme et les méthodes d'entraînement varient selon le cas d'utilisation. Il existe de nombreuses sous-catégories de machine learning, qui résolvent toutes des problèmes différents et fonctionnent avec des contraintes variées.
AutoML Translation vous permet d'effectuer un apprentissage supervisé. Cela consiste à apprendre à un ordinateur à reconnaître des schémas à partir de paires de phrases traduites,
permettant ainsi d'entraîner un modèle personnalisé à traduire du contenu dans le domaine qui vous intéresse.
Le machine learning implique l'utilisation de données pour entraîner des algorithmes afin d'obtenir le résultat souhaité. Les spécificités de l'algorithme et les méthodes d'entraînement varient selon le cas d'utilisation. Il existe de nombreuses sous-catégories de machine learning, qui résolvent toutes des problèmes différents et fonctionnent avec des contraintes variées.
AutoML Translation vous permet d'effectuer un apprentissage supervisé. Cela consiste à apprendre à un ordinateur à reconnaître des schémas à partir de paires de phrases traduites,
permettant ainsi d'entraîner un modèle personnalisé à traduire du contenu dans le domaine qui vous intéresse.
Préparation des données
Pour entraîner un modèle personnalisé avec AutoML Translation, fournissez des paires de phrases correspondantes dans les langues source et cible (c'est-à-dire des paires de phrases qui signifient la même chose dans la langue à partir de laquelle vous voulez traduire et dans celle vers laquelle vous voulez traduire). Bien entendu, la traduction n'est pas une science exacte, mais plus la signification des deux phrases d'une paire est proche, plus votre modèle est performant.
Évaluer le cas d'utilisation
Lorsque vous constituez un ensemble de données, commencez toujours par définir son cas d'utilisation. Dans un premier temps, posez-vous les questions suivantes :
- Quel résultat souhaitez-vous obtenir ?
- Quels types de phrases devez-vous traduire pour atteindre ce résultat ? Est-ce une tâche que l'API Translation peut effectuer immédiatement ?
- L'être humain est-il en mesure de traduire ces phrases de manière satisfaisante ? Si la tâche de traduction est intrinsèquement ambiguë, au point où une personne parlant couramment les deux langues aurait des difficultés à faire un travail satisfaisant, vous constaterez peut-être qu'AutoML Translation présente des performances similaires.
- Quels types d'exemples refléteraient le mieux le type et la plage de données que votre système devra traduire ?
Les produits de ML de Google reposent sur un principe fondamental : le machine learning centré sur l'humain, une approche qui met en avant les pratiques d'IA responsables, y compris l'équité. L'objectif de l'équité en matière de ML est de comprendre et d'éviter le traitement injuste ou préjudiciable des individus en fonction de leur origine ethnique, leurs revenus, leur orientation sexuelle, leur religion, leur sexe ou d'autres caractéristiques qui sont associées, historiquement, à des faits de discrimination et de marginalisation, lorsque ces phénomènes se manifestent dans les systèmes algorithmiques ou les processus décisionnels assistés par un algorithme. Pour en savoir plus, parcourez notre guide et consultez les remarques sur l'équité✽ incluses dans les consignes suivantes. Lors de la lecture des consignes permettant la mise en place de votre ensemble de données, nous vous incitons à appliquer ce principe d'équité dans le machine learning lorsque cela est pertinent pour votre cas d'utilisation.
Collecter des données
![]() Une fois que vous avez défini les données dont vous avez besoin, vous devez trouver un moyen de les collecter. Vous pouvez commencer par prendre en compte toutes les données que votre organisation recueille. Vous allez peut-être constater que vous collectez déjà les données dont vous avez besoin pour entraîner un modèle de traduction. Dans le cas contraire, vous pouvez les obtenir manuellement ou confier cette étape à un fournisseur tiers.
Une fois que vous avez défini les données dont vous avez besoin, vous devez trouver un moyen de les collecter. Vous pouvez commencer par prendre en compte toutes les données que votre organisation recueille. Vous allez peut-être constater que vous collectez déjà les données dont vous avez besoin pour entraîner un modèle de traduction. Dans le cas contraire, vous pouvez les obtenir manuellement ou confier cette étape à un fournisseur tiers.
Trouver des données correspondant à la complexité du domaine
![]() Vous entraînez un modèle de traduction personnalisé, car vous avez besoin d'un modèle adapté à un domaine linguistique particulier. Assurez-vous que les paires de phrases couvrent l'ensemble du vocabulaire, de la syntaxe et des particularités grammaticales de votre secteur ou domaine d'activité. Trouvez des documents qui regroupent les syntaxes types qui pourraient apparaître dans les tâches de traduction que vous souhaitez accomplir. Assurez-vous que la signification des phrases sources et cibles est la plus proche possible. Bien sûr, il arrive que le vocabulaire ou la syntaxe ne correspondent pas parfaitement dans les deux langues. Cependant, essayez de capturer toute la diversité de la sémantique que vous vous attendez à utiliser, si possible. Vous vous appuyez sur un modèle qui fonctionne déjà assez bien pour de la traduction polyvalente. L'entraînement à partir de vos exemples constitue la dernière étape permettant à AutoML Translation d'être performant pour votre cas d'utilisation en particulier. Par conséquent, assurez-vous que ces exemples sont pertinents et représentatifs de ce que vous attendez.
Vous entraînez un modèle de traduction personnalisé, car vous avez besoin d'un modèle adapté à un domaine linguistique particulier. Assurez-vous que les paires de phrases couvrent l'ensemble du vocabulaire, de la syntaxe et des particularités grammaticales de votre secteur ou domaine d'activité. Trouvez des documents qui regroupent les syntaxes types qui pourraient apparaître dans les tâches de traduction que vous souhaitez accomplir. Assurez-vous que la signification des phrases sources et cibles est la plus proche possible. Bien sûr, il arrive que le vocabulaire ou la syntaxe ne correspondent pas parfaitement dans les deux langues. Cependant, essayez de capturer toute la diversité de la sémantique que vous vous attendez à utiliser, si possible. Vous vous appuyez sur un modèle qui fonctionne déjà assez bien pour de la traduction polyvalente. L'entraînement à partir de vos exemples constitue la dernière étape permettant à AutoML Translation d'être performant pour votre cas d'utilisation en particulier. Par conséquent, assurez-vous que ces exemples sont pertinents et représentatifs de ce que vous attendez.
Capturer la diversité de l'espace linguistique
![]() On pourrait supposer que la façon dont les gens écrivent sur un sujet spécifique est suffisamment uniforme pour qu'un petit nombre d'échantillons de texte traduits par un petit nombre de traducteurs suffise à entraîner un modèle qui fonctionne bien pour tous les écrits sur ce sujet. Or, nous sommes tous différents, et nous apportons chacun notre propre personnalité aux mots que nous écrivons. Un ensemble de données d'entraînement comprenant des paires de phrases provenant d'un grand nombre d'auteurs et de traducteurs est plus susceptible de vous fournir un modèle utile pour la traduction des écrits d'une autre organisation.
En outre, en tenant compte de la diversité des phrases en termes de longueur et de structure, un ensemble de données dont toutes les phrases ont la même taille ou partagent une structure grammaticale similaire ne donnera pas suffisamment d'informations à AutoML Translation pour créer un modèle convenable qui capture toutes les possibilités.
On pourrait supposer que la façon dont les gens écrivent sur un sujet spécifique est suffisamment uniforme pour qu'un petit nombre d'échantillons de texte traduits par un petit nombre de traducteurs suffise à entraîner un modèle qui fonctionne bien pour tous les écrits sur ce sujet. Or, nous sommes tous différents, et nous apportons chacun notre propre personnalité aux mots que nous écrivons. Un ensemble de données d'entraînement comprenant des paires de phrases provenant d'un grand nombre d'auteurs et de traducteurs est plus susceptible de vous fournir un modèle utile pour la traduction des écrits d'une autre organisation.
En outre, en tenant compte de la diversité des phrases en termes de longueur et de structure, un ensemble de données dont toutes les phrases ont la même taille ou partagent une structure grammaticale similaire ne donnera pas suffisamment d'informations à AutoML Translation pour créer un modèle convenable qui capture toutes les possibilités.
Maintenir une intervention humaine
![]() Dans la mesure du possible, assurez-vous qu'une personne bilingue valide la correspondance des paires de phrases, ainsi que la compréhension et la justesse des traductions. Une erreur aussi simple qu'un mauvais alignement des lignes de la feuille de calcul des données d'entraînement peut générer des traductions qui ne veulent rien dire.
Des données de haute qualité constituent l'élément le plus important que vous puissiez fournir à AutoML Translation pour obtenir un modèle utilisable par votre entreprise.
Dans la mesure du possible, assurez-vous qu'une personne bilingue valide la correspondance des paires de phrases, ainsi que la compréhension et la justesse des traductions. Une erreur aussi simple qu'un mauvais alignement des lignes de la feuille de calcul des données d'entraînement peut générer des traductions qui ne veulent rien dire.
Des données de haute qualité constituent l'élément le plus important que vous puissiez fournir à AutoML Translation pour obtenir un modèle utilisable par votre entreprise.
Nettoyer les données désordonnées
![]() Il est facile de faire des erreurs lors du prétraitement des données. Certaines de ces erreurs peuvent vraiment dérouter un modèle AutoML Translation. Recherchez en particulier les problèmes de données suivants que vous pouvez résoudre :
Il est facile de faire des erreurs lors du prétraitement des données. Certaines de ces erreurs peuvent vraiment dérouter un modèle AutoML Translation. Recherchez en particulier les problèmes de données suivants que vous pouvez résoudre :
- Supprimez les phrases sources en double, en particulier si elles ont des traductions cibles différentes. AutoML Translation n'utilise que le premier exemple vu et supprime toutes les autres paires au moment de l'importation. En supprimant les doublons, vous vous assurez qu'AutoML Translation utilise votre traduction préférée.
- Alignez les phrases sources sur les phrases cibles correctes.
- Faites correspondre les phrases à la langue spécifiée. Par exemple, n'incluez que des phrases en chinois dans un ensemble de données chinois.
- Pour les phrases cibles incluant plusieurs langues, vérifiez que les mots non traduits sont intentionnellement non traduits, tels que les noms de produits ou d'organisations. Les phrases cibles qui incluent par erreur des mots non traduits ajoutent du bruit à vos données d'entraînement, ce qui peut être à l'origine d'un modèle de qualité inférieure.
- Corrigez les phrases comportant des erreurs typographiques ou grammaticales afin que votre modèle n'apprenne pas ces erreurs.
- Supprimez le contenu intraduisible, tel que les tags d'espace réservé et les balises HTML. Le contenu intraduisible peut entraîner des erreurs de ponctuation.
- Supprimez les contenus spécifiques aux paramètres régionaux. Les informations destinées à différents utilisateurs locaux ne sont pas nécessairement des traductions directes, telles que des numéros de téléphone pour des paramètres régionaux particuliers.
- N'incluez pas de traductions qui remplacent les entités générales par des noms spécifiques. Par exemple, vous pouvez avoir un exemple qui remplace "président" par le nom d'un président spécifique tel que "JFK" ou "John F Kennedy". Le modèle peut apprendre à remplacer toutes les occurrences de "président" par "JFK". Supprimez plutôt ces traductions ou remplacez les noms spécifiques par un nom commun.
- Supprimez les phrases en double dans les ensembles d'entraînement et de test (en savoir plus sur ces ensembles).
- Divisez les phrases multiples en différentes paires de phrases. L'entraînement sur un ensemble de données où de nombreux éléments contiennent plus de 50 jetons (mots) produit des modèles de qualité inférieure. Dans la mesure du possible, scindez les éléments en phrases individuelles.
- Utilisez une casse cohérente. La casse affecte la façon dont un modèle apprend, par exemple à distinguer un titre d'un corps de texte.
- Supprimez les balises TMX lors de l'importation de données à partir d'un fichier TSV. Dans certains cas, vous pouvez exporter votre mémoire de traduction existante vers un fichier TSV, qui peut inclure des balises TMX. Toutefois, AutoML Translation ne nettoie les balises d'unité de traduction que lorsque vous importez un fichier TMX (et non pour les fichiers TSV).
Prétraitement des données par AutoML
AutoML Translation arrête d'analyser votre fichier d'entrée de données lorsque :
- le format n'est pas valide ;
- une paire de phrases est excessivement longue (10 Mo) ;
- le fichier utilise un encodage autre que UTF-8.
AutoML Translation ignore certaines erreurs pour les problèmes qu'il peut détecter. Par exemple :
- Un élément <tu> d'un fichier TMX n'a pas de langue source ou de langue cible.
- Une des paires de phrases en entrée est vide.
En mode AutoSplit, AutoML Translation effectue un traitement supplémentaire :
- Une fois l'ensemble de données chargé, il supprime les paires de phrases ayant des phrases sources identiques.
- Il répartit de manière aléatoire les données en trois ensembles, avec un rapport de fractionnement de 8:1:1 avant l'entraînement.
Comprendre comment AutoML Translation utilise les ensembles de données lors de la création de modèles personnalisés
![]() Votre ensemble de données contient des ensembles d'entraînement, de validation et de test. Si vous ne spécifiez pas la répartition (consultez la page Préparer les données d'entraînement) et que votre ensemble de données contient moins de 100 000 paires de phrases, AutoML Translation utilise automatiquement 80 % de vos documents texte à des fins d'entraînement, 10 % à des fins de validation et 10 % à des fins de test. Si votre ensemble de données est plus volumineux, vous devrez effectuer votre propre répartition des données.
Votre ensemble de données contient des ensembles d'entraînement, de validation et de test. Si vous ne spécifiez pas la répartition (consultez la page Préparer les données d'entraînement) et que votre ensemble de données contient moins de 100 000 paires de phrases, AutoML Translation utilise automatiquement 80 % de vos documents texte à des fins d'entraînement, 10 % à des fins de validation et 10 % à des fins de test. Si votre ensemble de données est plus volumineux, vous devrez effectuer votre propre répartition des données.
Ensemble d'entraînement
![]() La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement : elles sont utilisées pour apprendre les paramètres du modèle, à savoir la pondération des connexions entre les nœuds du réseau de neurones.
La grande majorité de vos données doit figurer dans l'ensemble d'entraînement. Il s'agit des données auxquelles votre modèle accède pendant l'entraînement : elles sont utilisées pour apprendre les paramètres du modèle, à savoir la pondération des connexions entre les nœuds du réseau de neurones.
Ensemble de validation
![]() L'ensemble de validation, parfois nommé ensemble "dev", est également utilisé lors du processus d'entraînement. Lors de l'entraînement d'un modèle, le framework utilise l'ensemble d'entraînement pour entraîner une série de modèles candidats. Il utilise ensuite les performances des modèles sur l'ensemble de validation pour choisir le meilleur modèle généré, puis pour ajuster les hyperparamètres de ce modèle, qui sont des variables spécifiant sa structure. Si vous utilisiez l'ensemble d'entraînement pour ajuster les hyperparamètres, le modèle pourrait finir par trop se focaliser sur les données d'entraînement. L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
L'ensemble de validation, parfois nommé ensemble "dev", est également utilisé lors du processus d'entraînement. Lors de l'entraînement d'un modèle, le framework utilise l'ensemble d'entraînement pour entraîner une série de modèles candidats. Il utilise ensuite les performances des modèles sur l'ensemble de validation pour choisir le meilleur modèle généré, puis pour ajuster les hyperparamètres de ce modèle, qui sont des variables spécifiant sa structure. Si vous utilisiez l'ensemble d'entraînement pour ajuster les hyperparamètres, le modèle pourrait finir par trop se focaliser sur les données d'entraînement. L'utilisation d'un ensemble de données relativement nouveau pour affiner la structure du modèle permet une meilleure généralisation du modèle à d'autres données.
Ensemble de test
![]() L'ensemble de test n'est pas du tout impliqué dans le processus d'entraînement. Une fois celui-ci terminé, l'utilisation de l'ensemble de test représente un défi complètement nouveau pour le modèle. Ses performances sur l'ensemble de test sont supposées vous fournir une idée plutôt fidèle de son comportement sur des données réelles.
L'ensemble de test n'est pas du tout impliqué dans le processus d'entraînement. Une fois celui-ci terminé, l'utilisation de l'ensemble de test représente un défi complètement nouveau pour le modèle. Ses performances sur l'ensemble de test sont supposées vous fournir une idée plutôt fidèle de son comportement sur des données réelles.
Répartition manuelle
![]() AutoML peut scinder automatiquement vos données en ensembles d'entraînement, de validation et de test. Vous pouvez également le faire vous-même si vous souhaitez avoir davantage de contrôle sur le processus, si vous préférez une autre répartition ou si vous tenez absolument à inclure des exemples spécifiques dans une certaine partie du cycle de vie de l'entraînement du modèle.
AutoML peut scinder automatiquement vos données en ensembles d'entraînement, de validation et de test. Vous pouvez également le faire vous-même si vous souhaitez avoir davantage de contrôle sur le processus, si vous préférez une autre répartition ou si vous tenez absolument à inclure des exemples spécifiques dans une certaine partie du cycle de vie de l'entraînement du modèle.
Préparer les données pour l'importation
Lorsque vous avez fait votre choix entre la répartition manuelle ou automatique de vos données, vous êtes prêt à les ajouter dans AutoML Translation, ce qui peut se faire de deux manières :
- Vous pouvez importer les données sous forme d'un fichier TSV (valeurs séparées par des tabulations) contenant des phrases sources et cibles (une paire de phrases par ligne).
- Vous pouvez importer les données sous forme d'un fichier TMX. Il s'agit d'un format standard permettant de fournir des paires de phrases aux outils de modélisation de traduction automatique (en savoir plus sur le format TMX accepté). Si le fichier TMX contient des balises XML non valides, AutoML Translation les ignore. Si le fichier TMX n'est pas conforme aux formats XML et TMX appropriés (par exemple, s'il manque une balise de fin ou un élément <tmx>), AutoML Translation ne le traitera pas. AutoML Translation interrompt également le traitement et renvoie une erreur s'il ignore plus de 1 024 éléments <tu> non valides.
Évaluer
Une fois le modèle entraîné, vous recevrez un résumé de ses performances. Cliquez sur l'onglet Entraînement après la fin de l'entraînement du modèle pour afficher une analyse détaillée.
Que dois-je garder à l'esprit avant d'évaluer un modèle ?
![]() Le débogage d'un modèle consiste davantage à déboguer les données que le modèle proprement dit. Si votre modèle commence à agir de manière inattendue alors que vous évaluez ses performances avant et après le passage en production, vous devez de nouveau vérifier vos données afin d'identifier des axes d'amélioration de vos exemples.
Le débogage d'un modèle consiste davantage à déboguer les données que le modèle proprement dit. Si votre modèle commence à agir de manière inattendue alors que vous évaluez ses performances avant et après le passage en production, vous devez de nouveau vérifier vos données afin d'identifier des axes d'amélioration de vos exemples.
Score BLEU
Le score BLEU est une méthode standard pour mesurer la qualité d'un système de traduction automatique. AutoML Translation utilise un score BLEU calculé sur les données de test que vous avez fournies comme métrique d'évaluation principale. (En savoir plus sur les scores BLEU)
Le modèle NMT de Google, qui alimente l'API Translation, est destiné à un usage général. Il ne s'agit probablement pas de la meilleure solution pour vous si vous avez besoin d'une traduction spécialisée dans vos domaines. Le modèle personnalisé entraîné fonctionne généralement mieux que le modèle NMT dans les domaines auxquels votre ensemble d'entraînement est associé.
Une fois que vous avez entraîné le modèle personnalisé avec votre ensemble de données, les scores BLEU du modèle personnalisé et du modèle NMT de Google s'affichent dans l'onglet Entraînement. Le gain de performance sur le score BLEU du modèle personnalisé est également indiqué. Plus le score BLEU est élevé, plus les traductions que votre modèle peut fournir pour des phrases semblables à vos données d'entraînement sont de qualité. Si le score BLEU se situe entre 30 et 40, le modèle est considéré comme capable de fournir de bonnes traductions.
Tester le modèle
![]() Même si le score BLEU semble correct, il est judicieux de vérifier par vous-même le modèle afin de vous assurer que ses performances correspondent à vos attentes. Si les données d'entraînement et de test proviennent d'un même ensemble qui est incorrect, le score peut être excellent alors que la traduction ne veut rien dire. Quelques exemples d'évaluation de l'intégrité à saisir dans l'onglet Prédiction d'AutoML Translation vous permettront d'effectuer une comparaison avec les résultats du modèle de base NMT de Google. Vous pouvez également appliquer les instructions de cet onglet pour appeler l'API AutoML afin d'utiliser votre modèle dans des tests automatisés. Il se peut que votre modèle présente les mêmes prédictions que le modèle de base, en particulier pour les phrases courtes ou si votre ensemble d'entraînement est petit. Ce n'est pas surprenant, car le modèle de base est déjà assez bon pour une grande diversité de cas d'utilisation. Essayez avec des phrases plus longues ou plus complexes. Cependant, si toutes vos phrases présentent des prédictions identiques au modèle de base, cela peut indiquer un problème au niveau des données.
Même si le score BLEU semble correct, il est judicieux de vérifier par vous-même le modèle afin de vous assurer que ses performances correspondent à vos attentes. Si les données d'entraînement et de test proviennent d'un même ensemble qui est incorrect, le score peut être excellent alors que la traduction ne veut rien dire. Quelques exemples d'évaluation de l'intégrité à saisir dans l'onglet Prédiction d'AutoML Translation vous permettront d'effectuer une comparaison avec les résultats du modèle de base NMT de Google. Vous pouvez également appliquer les instructions de cet onglet pour appeler l'API AutoML afin d'utiliser votre modèle dans des tests automatisés. Il se peut que votre modèle présente les mêmes prédictions que le modèle de base, en particulier pour les phrases courtes ou si votre ensemble d'entraînement est petit. Ce n'est pas surprenant, car le modèle de base est déjà assez bon pour une grande diversité de cas d'utilisation. Essayez avec des phrases plus longues ou plus complexes. Cependant, si toutes vos phrases présentent des prédictions identiques au modèle de base, cela peut indiquer un problème au niveau des données.
Si une erreur vous inquiète particulièrement lors de la création du modèle (par exemple, une caractéristique déroutante de votre combinaison linguistique qui amène souvent les traducteurs humains à se tromper, ou une erreur de traduction qui pourrait être particulièrement coûteuse en argent ou en réputation), assurez-vous que l'ensemble de test ou la procédure couvre ce cas de manière adéquate. Ainsi, vous n'aurez rien à craindre lorsque vous utiliserez votre modèle pour des tâches de traduction quotidiennes.