Criar perfil do modelo nos nós da Cloud TPU
Com a criação de perfil do seu modelo, é possível otimizar o desempenho do treinamento nos Cloud TPUs. Para criar o perfil do modelo, use o TensorBoard e o plug-in do TensorBoard do Cloud TPU. Consulte as instruções de instalação do TensorBoard.
Para mais informações sobre como usar o TensorBoard com um dos frameworks compatíveis, consulte os seguintes documentos:
Pré-requisitos
O TensorBoard é instalado como parte do TensorFlow. O TensorFlow é instalado por padrão nos nós do Cloud TPU. Também é possível instalar o TensorFlow manualmente. De qualquer forma, talvez sejam necessárias outras dependências. Para instalar esses recursos, execute:
(vm)$ pip3 install --user -r /usr/share/models/official/requirements.txt
Instalar o plug-in do TensorBoard do Cloud TPU
Use SSH para se conectar ao nó da TPU:
$ gcloud compute ssh your-vm --zone=your-zone
Execute os comandos a seguir:
pip3 install --upgrade "cloud-tpu-profiler>=2.3.0" pip3 install --user --upgrade -U "tensorboard>=2.3" pip3 install --user --upgrade -U "tensorflow>=2.3"
Como capturar um perfil
É possível capturar um perfil usando a IU do TensorBoard ou de maneira programática.
Capturar um perfil usando o TensorBoard
Quando você inicia o TensorBoard, ele inicia um servidor da Web. Quando você aponta seu navegador para o URL do TensorBoard, ele exibe uma página da Web. Na página da Web, é possível capturar manualmente um perfil e ver os dados dele.
Inicie o servidor do TensorFlow Profiler
tf.profiler.experimental.server.start(6000)
Isso inicia o servidor do TensorFlow Profiler na sua VM da TPU.
Iniciar seu script de treinamento
Execute o script de treinamento e aguarde até ver a saída indicando que o modelo está
em treinamento. A aparência disso depende do seu código e modelo. Procure
uma saída como Epoch 1/100. Como alternativa, é possível navegar até a página do Cloud TPU no Console do Google Cloud, selecionar a TPU e ver o gráfico de uso da CPU. Embora isso não mostre a utilização da TPU, é uma boa indicação de que ela está treinando o modelo.
Iniciar o servidor do TensorBoard
Abra uma nova janela do terminal e conecte-se via SSH à VM da TPU com o encaminhamento de portas. Isso permite que o navegador local se comunique com o servidor do TensorBoard em execução na VM da TPU.
gcloud compute tpus execution-groups ssh your-vm --zone=us-central1-a --ssh-flag="-4 -L 9001:localhost:9001"
Execute o TensorBoard na janela do terminal que você acabou de abrir e especifique o diretório em que o TensorBoard pode gravar dados de criação de perfil com a sinalização --logdir. Exemplo:
TPU_LOAD_LIBRARY=0 tensorboard --logdir your-model-dir --port 9001
O TensorBoard inicia um servidor da Web e exibe o URL dele:
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.3.0 at http://localhost:9001/ (Press CTRL+C to quit)
Abra um navegador da Web e acesse o URL exibido na saída do TensorBoard. Para verificar se o TensorBoard carregou completamente os dados de criação do perfil, clique no botão de atualização no canto superior direito da página do TensorBoard. Por padrão, a página do TensorBoard é exibida com a guia "Escalares" selecionada.
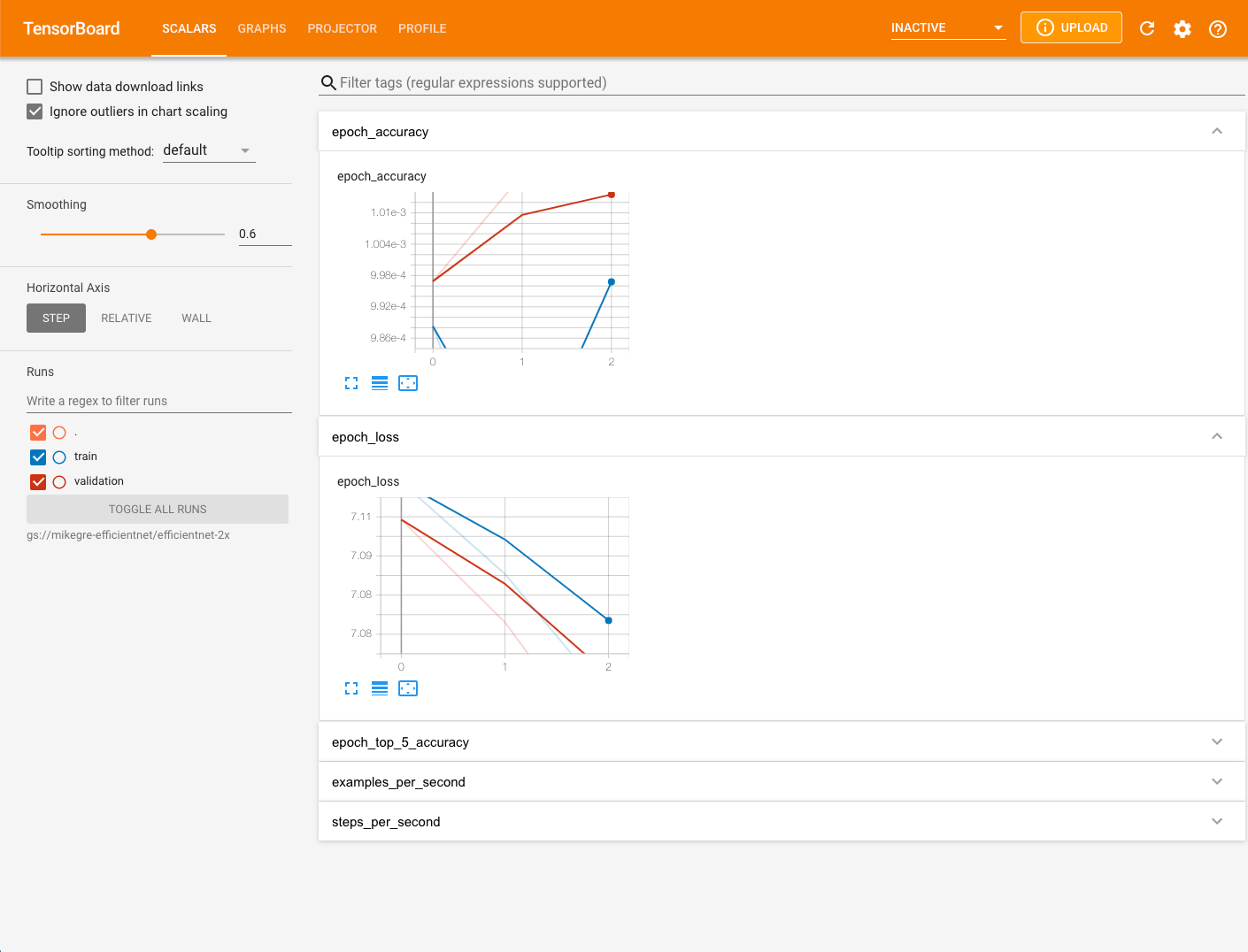
Capturar um perfil em nós de TPU
- Selecione PERFIL no menu suspenso na parte superior da tela.
- Selecione o botão CAPTURE PROFILE.
- Selecione o botão de opção Nome da TPU.
- Digite o nome da TPU
- Selecione o botão CAPTURE.
Capturar um perfil de maneira programática
A forma como você captura de maneira programática um perfil depende do framework de ML que você está usando.
Se você estiver usando o TensorFlow, inicie e interrompa o criador de perfil usando
tf.profiler.experimental.start() e tf.profiler.experimental.stop(),
respectivamente. Para mais informações, consulte o Guia de desempenho do TensorFlow (em inglês).
Se você estiver usando o JAX, use jax.profiler.start_trace() e jax.profiler.stop_trace()
para iniciar e interromper o criador de perfil, respectivamente. Para saber mais, consulte Como criar perfis de programas JAX.
Capturar problemas comuns do perfil
Às vezes, ao tentar capturar um rastro, você pode receber mensagens como estas:
No trace event is collected after xx attempt(s). Perhaps, you want to try again
(with more attempts?).Tip: increase number of attempts with --num_tracing_attempts.
Failed to capture profile: empty trace result
Isso poderá ocorrer se a TPU não estiver realizando cálculos ativamente, se uma etapa de treinamento estiver demorando muito ou outros motivos. Se você receber essa mensagem, tente fazer o seguinte:
- Tente capturar um perfil após alguns períodos.
- Tente aumentar a duração da criação de perfil na caixa de diálogo Capture Profile do TensorBoard. É possível que uma etapa de treinamento esteja demorando muito.
- Verifique se a VM e a TPU têm a mesma versão do TF.
Ver dados de perfil com o TensorBoard
A guia Perfil aparece depois que você captura alguns dados do modelo. Pode ser necessário clicar no botão de atualização no canto superior direito da página do TensorBoard. Quando os dados ficarem disponíveis, clique na guia Perfil para ver uma seleção de ferramentas que ajudam na análise de desempenho:
- Página de visão geral
- Visualizador de traces (somente navegador Chrome)
- Visualizador de traces em streaming (somente navegador Chrome)
Visualizador de traces
O visualizador de traces é uma ferramenta de análise de desempenho do Cloud TPU disponível em Perfil. Ela usa o visualizador de perfil de evento de trace do Chrome para que funcione apenas no navegador Chrome.
O visualizador de traces contém uma linha do tempo que mostra:
- as durações das operações que foram executadas pelo seu modelo do TensorFlow;
- qual parte do sistema (TPU ou máquina host) executou uma operação. A máquina host costuma executar operações de entrada, realiza o pré-processamento dos dados de treinamento e os transfere para a TPU, enquanto a TPU executa o treinamento do modelo de fato.
Com o visualizador de traces, é possível identificar problemas de desempenho do modelo e tomar providências para solucioná-los. Por exemplo, de modo geral, é possível identificar se a entrada ou o treinamento do modelo está tomando a maior parte do tempo. Em uma análise mais detalhada, é possível identificar quais operações do TensorFlow estão demorando mais para serem executadas.
O visualizador de traces é limitado a 1 milhão de eventos por Cloud TPU. Se você precisar avaliar mais eventos, use o visualizador de rastros em streaming.
Interface do visualizador de traces
Para abrir o visualizador de traces, acesse o TensorBoard, clique na guia Perfil na parte superior da tela e escolha trace_viewer no menu suspenso Ferramentas. O visualizador é exibido com a execução mais recente:
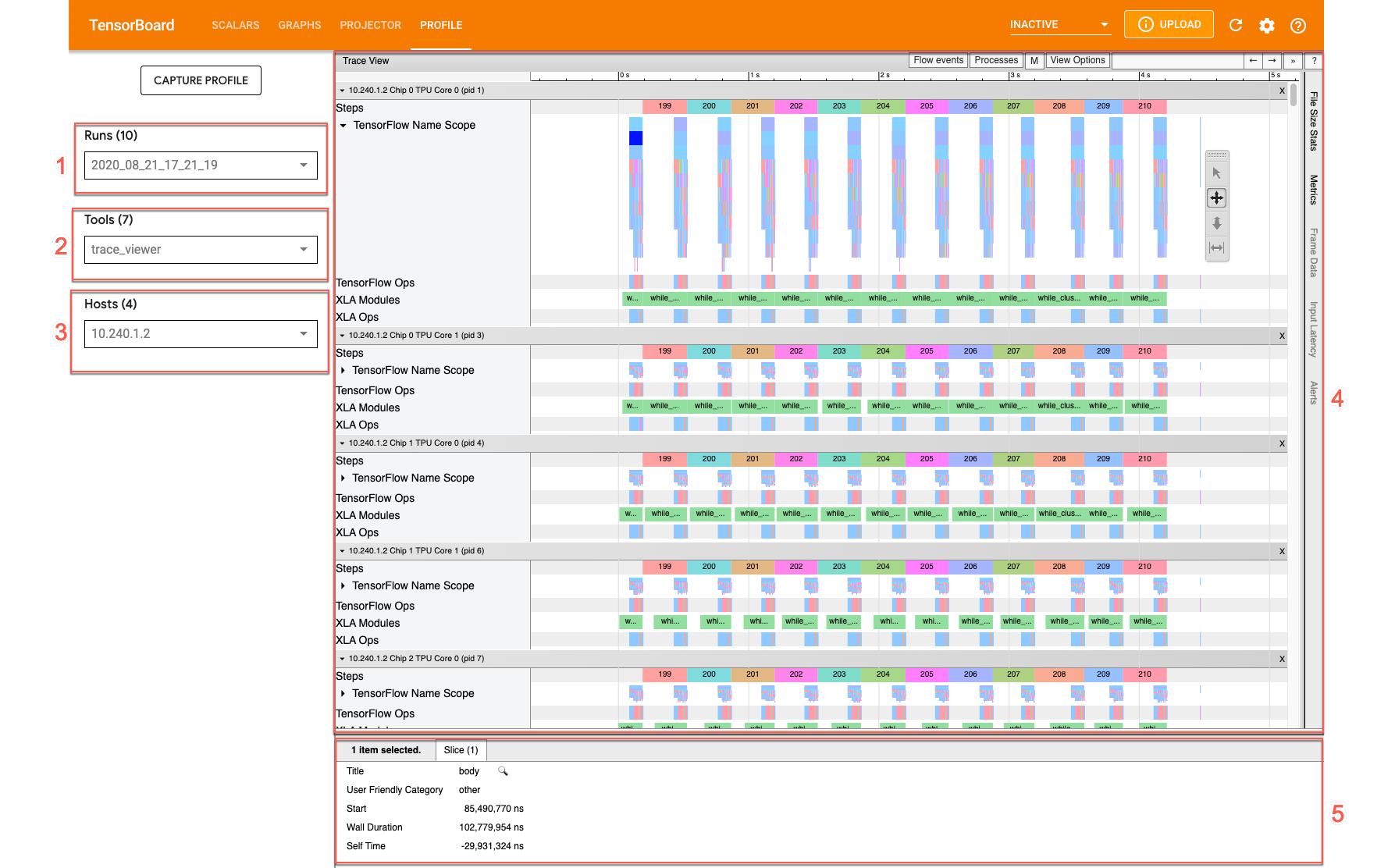
Essa tela contém os seguintes elementos principais (marcados com números):
- Lista suspensa Execuções. Contém todas as execuções de que você capturou informações de trace. A visualização padrão é a execução mais recente, mas é possível abrir a lista suspensa para selecionar outra execução.
- Lista suspensa Ferramentas. Seleciona diferentes ferramentas de criação de perfil.
- Lista suspensa de hosts. Seleciona um host que contém um conjunto de TPUs.
- Painel da linha do tempo. Mostra operações que o Cloud TPU e a máquina host executaram ao longo do tempo.
- Painel de detalhes. Mostra outras informações das operações selecionadas no painel da linha do tempo.
Esta é uma visão mais detalhada do painel da linha do tempo:
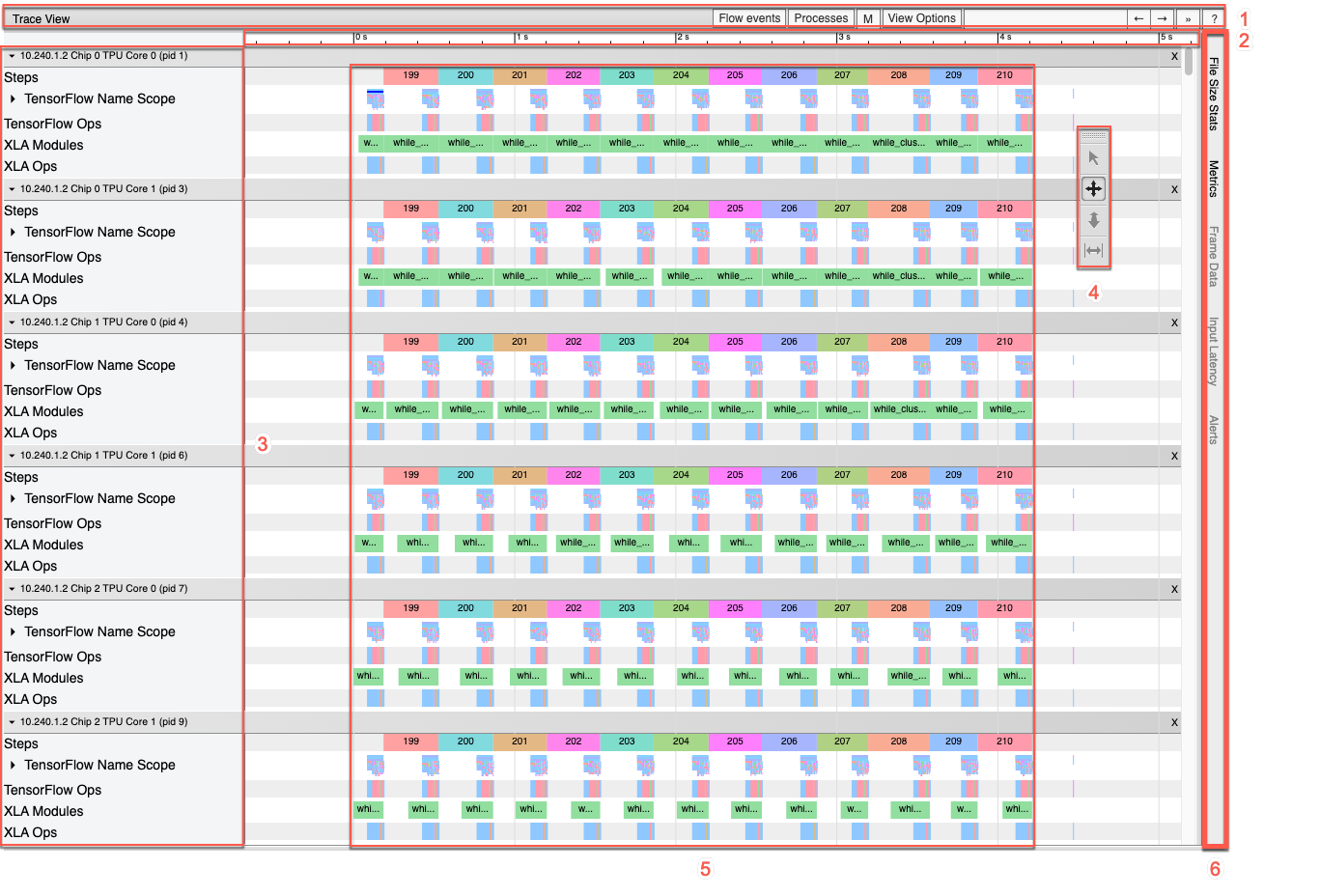
O painel da linha do tempo contém os seguintes elementos:
- Barra superior. Contém vários controles auxiliares.
- Eixo de tempo. Mostra o tempo em relação ao início do trace.
- Rótulos de seção e faixa. Cada seção contém várias faixas e um triângulo à esquerda que, quando clicado, expande e recolhe a seção. Há uma seção para cada elemento de processamento do sistema.
- Seletor de ferramentas. Contém várias ferramentas para interagir com o visualizador de traces.
- Eventos. Mostra a duração da execução de uma operação ou a duração dos metaeventos, como as etapas de treinamento.
- Barra de guias verticais. Isso não tem uma finalidade útil para o Cloud TPU. A barra faz parte da ferramenta visualizador de rastros de uso geral fornecida pelo Chrome, que é usada para várias tarefas de análise de desempenho.
Seções e linhas
O visualizador de traces contém as seguintes seções:
- Uma seção para cada nó da TPU, rotulada com o número do chip da TPU e o nó da TPU dentro do chip (por exemplo, "Chip 2: núcleo da TPU 1"). Cada seção de nó da TPU contém as seguintes faixas:
- Etapa. Mostra a duração das etapas de treinamento que foram executadas na TPU.
- Operações do TensorFlow. Mostra as operações do TensorFlow executadas na TPU.
- Operações do XLA. Mostra as operações do XLA que foram executadas na TPU. Cada operação é convertida em uma ou várias operações do XLA. O compilador XLA converte as operações do XLA em código que é executado na TPU.
- Uma seção de threads em execução na CPU da máquina host, denominada "Threads de host". Esta seção contém uma faixa para cada thread da CPU. Observação: é possível ignorar as informações exibidas ao lado dos rótulos da seção.
Seletor de ferramenta da linha do tempo
É possível interagir com a visualização da linha do tempo usando o seletor de ferramentas da linha do tempo no TensorBoard. Clique em uma ferramenta da linha do tempo ou usar os seguintes atalhos de teclado para ativar e destacar uma ferramenta. Para mover o seletor de ferramentas da linha do tempo, clique na área pontilhada na parte superior e arraste o seletor até o local desejado.
Use as ferramentas da linha do tempo da seguinte maneira:
|
Ferramenta de seleção Clique em um evento para selecioná-lo ou arraste para selecionar vários eventos. O painel de detalhes exibe mais informações sobre os eventos selecionados (nome, horário de início e duração). |
|
Ferramenta de panorama Arraste para movimentar a visualização da linha do tempo na horizontal e na vertical. |
|
Ferramenta de zoom Arraste para cima ou para baixo para, respectivamente, aumentar ou diminuir o zoom ao longo do eixo horizontal (tempo). A posição horizontal do cursor do mouse determina o centro da área onde o zoom será aplicado. Observação: a ferramenta Zoom tem um bug conhecido que deixa o zoom ativado se o botão do mouse for liberado enquanto o cursor estiver do lado de fora da visualização da linha do tempo. Se isso acontecer, basta clicar na visualização da linha de tempo para parar o zoom. |
|
Ferramenta de tempo Arraste horizontalmente para marcar um intervalo de tempo. A duração do intervalo aparece no eixo do tempo. Para ajustar o intervalo, arraste as extremidades. Para limpar o intervalo, clique em qualquer lugar dentro da visualização da linha do tempo. Observe que o intervalo permanece marcado se você selecionar uma das outras ferramentas. |




Gráficos
O TensorBoard fornece uma variedade de visualizações, ou gráficos, do seu modelo e o desempenho de cada. Use os gráficos junto com o visualizador de traces ou visualizador de traces em streaming para ajustar os modelos e melhorar o desempenho deles no Cloud TPU.
Grafo do modelo
A estrutura de modelagem pode gerar
um gráfico com base no modelo. Os dados do gráfico são armazenados no diretório MODEL_DIR
no bucket de armazenamento especificado com o parâmetro
--logdir. É possível visualizar esse gráfico sem executar capture_tpu_profile.
Para visualizar o gráfico de um modelo, selecione a guia Gráficos no TensorBoard.
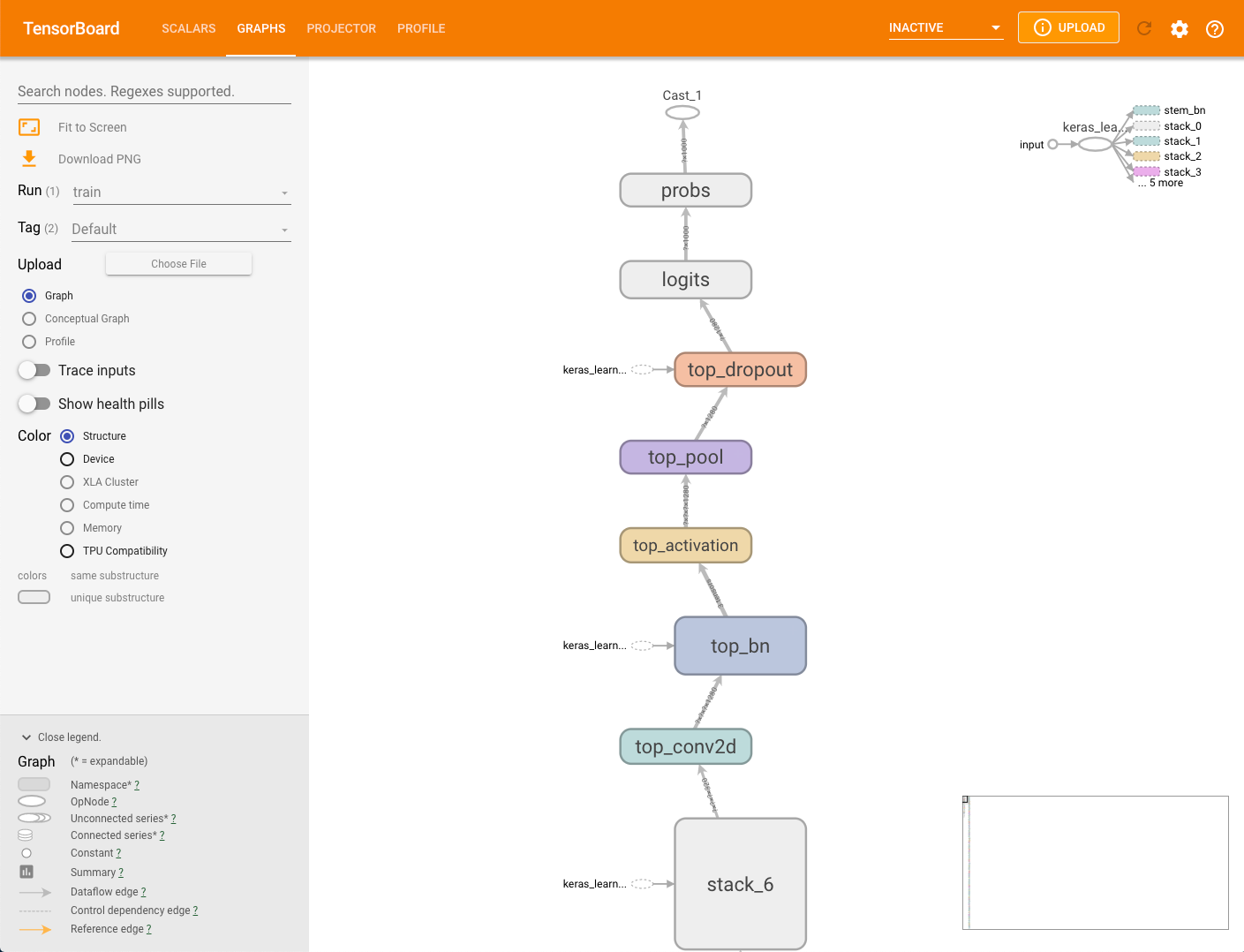
Um único nó no gráfico da estrutura representa uma única operação.
Gráfico de compatibilidade com TPU
A guia Gráficos inclui um módulo verificador de compatibilidade que verifica e exibe operações que podem causar problemas quando um modelo é executado.
Para visualizar o gráfico de compatibilidade com TPU de um modelo, selecione a guia Gráficos no TensorBoard e, em seguida, selecione a opção Compatibilidade com TPU. No gráfico, vemos as operações compatíveis (válidas) em verde e as operações incompatíveis (inválidas) em vermelho.
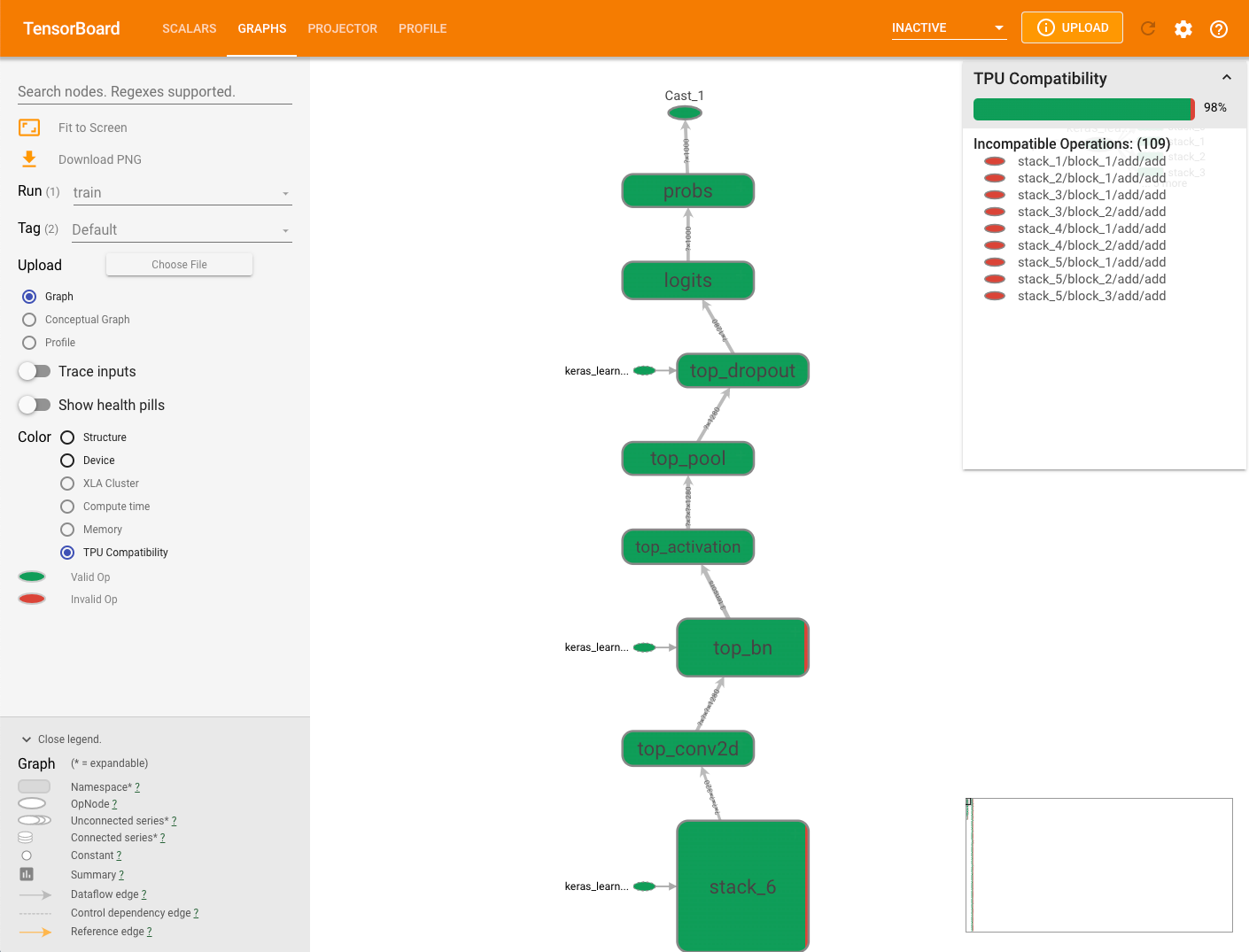
Um determinado nó pode apresentar as duas cores, indicando as porcentagens das operações de compatibilidade do Cloud TPU para esse nó. Consulte Como interpretar os resultados de compatibilidade para ver um exemplo.
O painel de resumo de compatibilidade exibido à direita do gráfico contém a porcentagem de todas as operações compatíveis com o Cloud TPU, os respectivos atributos e uma lista de operações incompatíveis com um nó selecionado.
Clique em qualquer operação no gráfico para exibir os respectivos atributos no painel de resumo.
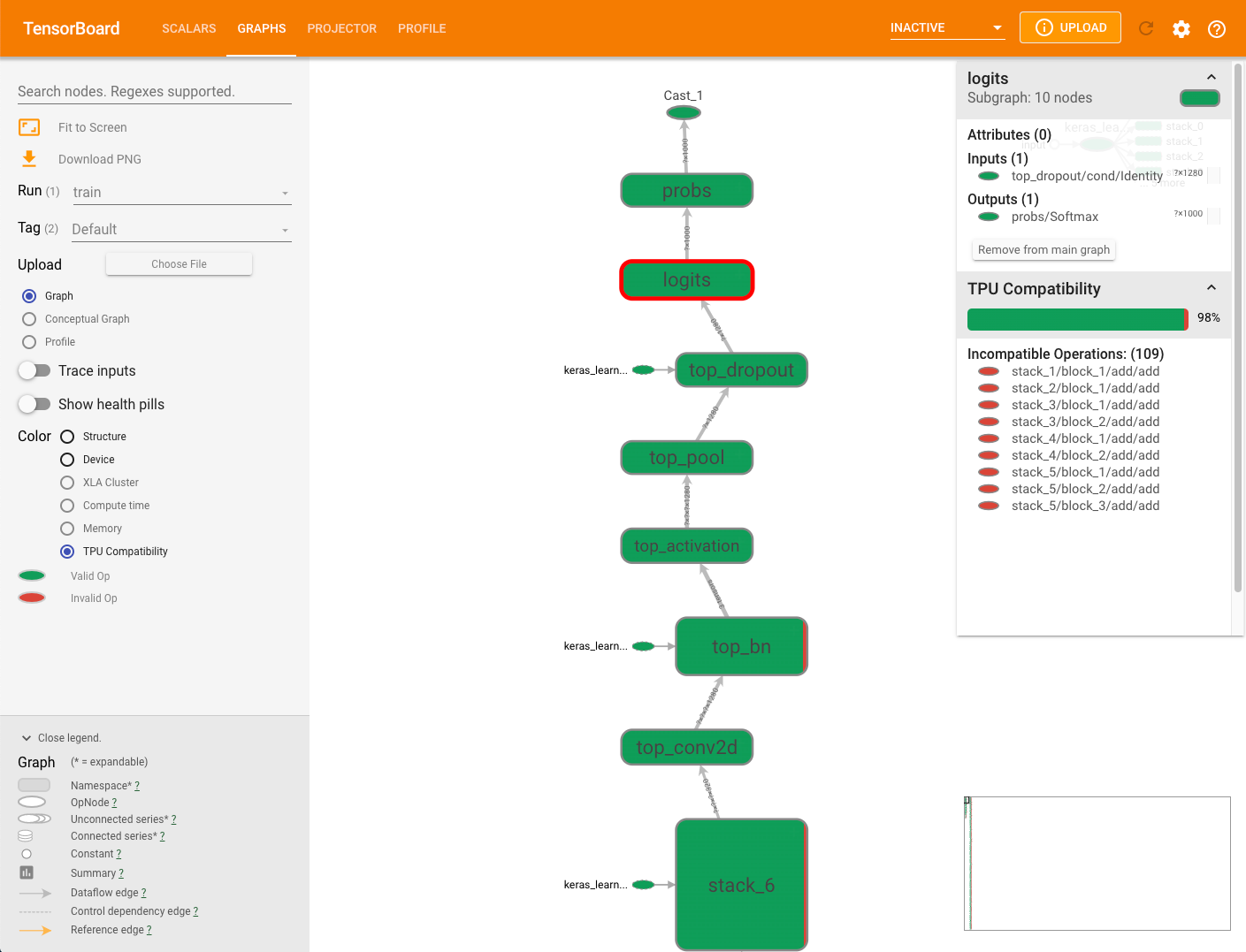
O verificador de compatibilidade não avalia nenhuma operação explicitamente atribuída a um dispositivo não TPU usando o posicionamento manual de dispositivo. Além disso, como o verificador não compila o modelo para execução, certifique-se de interpretar os resultados como uma estimativa de compatibilidade.
Como interpretar os resultados de compatibilidade
Perfil
A guia Perfil é exibida depois que você captura alguns dados de modelo. Pode ser necessário clicar no botão de atualização no canto superior direito da página do TensorBoard. Quando os dados ficarem disponíveis, clique na guia Perfil para ver uma seleção de ferramentas que ajudam na análise de desempenho:
- Página de visão geral
- Analisador do pipeline de entrada
- Perfil de operação do XLA
- Visualizador de traces (somente navegador Chrome)
- Visualizador de memória
- Visualizador de pod
- Visualizador de traces em streaming (somente navegador Chrome)
Página de visão geral do perfil
Na página de visão geral (overview_page), disponível em Perfil, você tem uma visão de nível superior de como foi o desempenho do seu modelo durante uma execução de captura. Na página, há uma página de visão geral agregada para todas as TPUs, bem como uma análise geral do pipeline de entrada. Há a opção de selecionar TPUs individuais na lista suspensa Host.
A página mostra dados nos seguintes painéis:
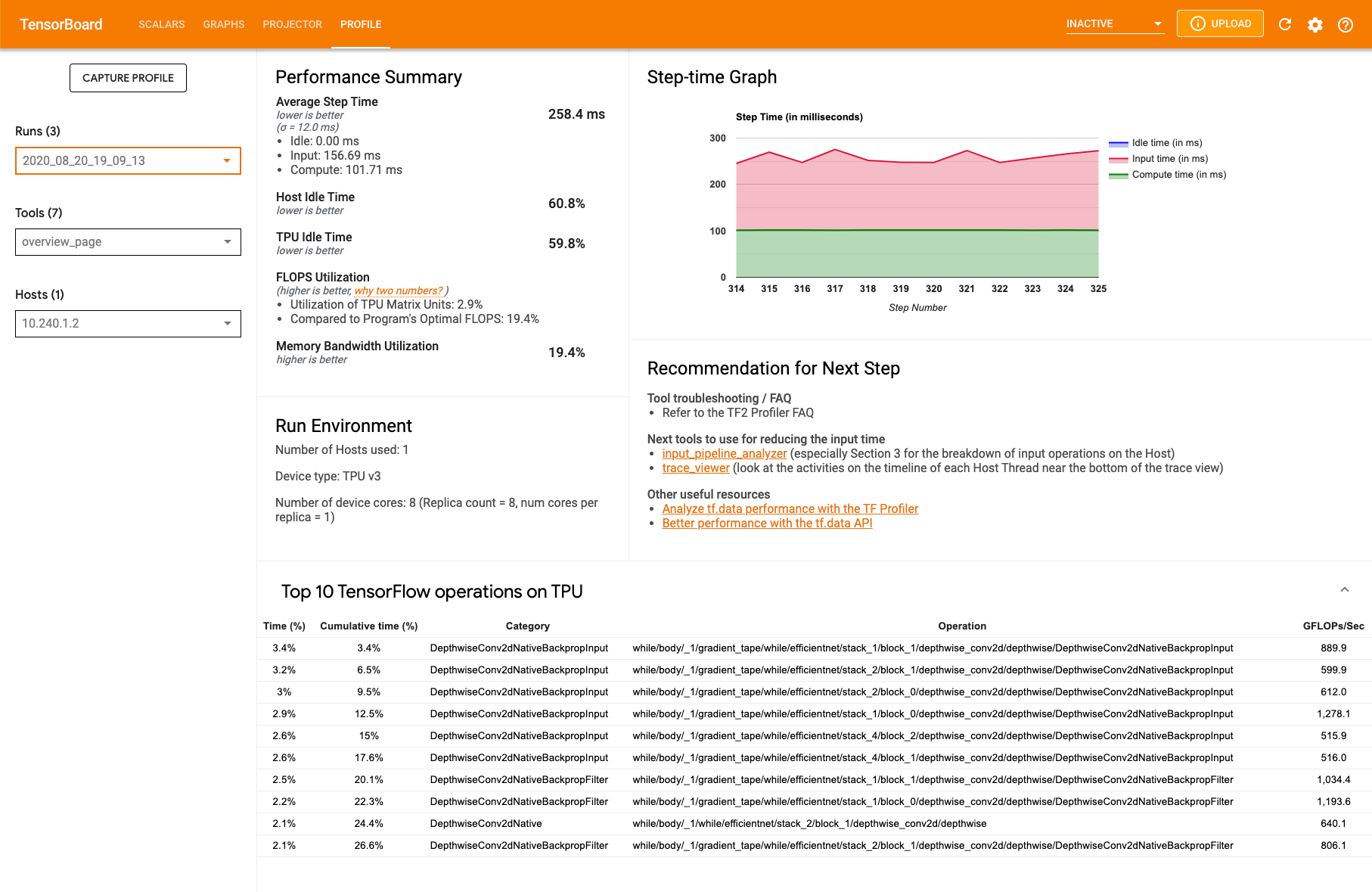
Resumo de desempenho
- Tempo médio de duração: a duração média da etapa entre todas as etapas do exemplo.
- Tempo de ociosidade do host: a porcentagem de tempo em que o host ficou ocioso.
- Tempo de ociosidade da TPU: a porcentagem de tempo que a TPU ficou ociosa.
- Utilização de FLOPS: a porcentagem de utilização das unidades de matriz da TPU.
- Utilização da largura de banda da memória: a porcentagem da largura de banda de memória usada.
Gráfico de duração da etapa. Exibe um gráfico da duração da etapa do dispositivo (em milissegundos) que abrange todas as etapas da amostra. A área azul corresponde à parte da duração em que as TPUs permaneceram ociosas aguardando os dados de entrada do host. A área vermelha mostra por quanto tempo o Cloud TPU realmente esteve em funcionamento.
10 principais operações do TensorFlow na TPU Exibe as operações do TensorFlow que consumiram mais tempo.
Cada linha exibe a duração própria de uma operação (como porcentagem do tempo gasto por todas as operações), o tempo cumulativo, a categoria, o nome e a taxa de FLOPS atingida.
Ambiente de execução
- Número de hosts usados
- Tipo de TPU usada
- Número de núcleos de TPU
- Tamanho do lote de treinamento
Recomendação para as próximas etapas. Informa quando um modelo é limitado pela entrada e sempre que ocorrem problemas com o Cloud TPU. Sugere ferramentas para localizar gargalos de desempenho.
Analisador do pipeline de entrada
O analisador de pipeline de entrada fornece insights sobre seus resultados de desempenho. A ferramenta
exibe resultados de desempenho do arquivo input_pipeline.json,
coletado pela ferramenta capture_tpu_profile.
A ferramenta informa imediatamente se o programa é limitado pela entrada. Além disso, ela pode orientar você na análise do dispositivo e do host para depurar os estágios do pipeline que estão criando gargalos.
Consulte a orientação em desempenho do pipeline de entrada para ver mais insights sobre a otimização do desempenho do pipeline.
Pipeline de entrada
Quando um programa do TensorFlow lê dados de um arquivo, ele começa na parte superior do gráfico do TensorFlow e prossegue de maneira segmentada. O processo de leitura é dividido em vários estágios de processamento de dados conectados em série, em que a saída de um estágio é a entrada do próximo. Esse sistema de leitura é chamado de pipeline de entrada.
Um pipeline típico para leitura de registros de arquivos tem os seguintes estágios:
- leitura de arquivos
- Pré-processamento de arquivos (opcional)
- Transferência de arquivos da máquina host para o dispositivo
Um canal de entrada ineficiente pode tornar o aplicativo drasticamente lento. Um aplicativo é considerado limitado pela entrada quando passa uma parte significativa do tempo no pipeline de entrada. Use o analisador de pipeline de entrada para detectar o local em que o pipeline de entrada é ineficiente.
Painel de pipeline de entrada
Para abrir o analisador de pipeline de entrada, selecione Perfil e, em seguida, selecione input_pipeline_analyzer na lista suspensa Ferramentas.
O painel contém três seções:
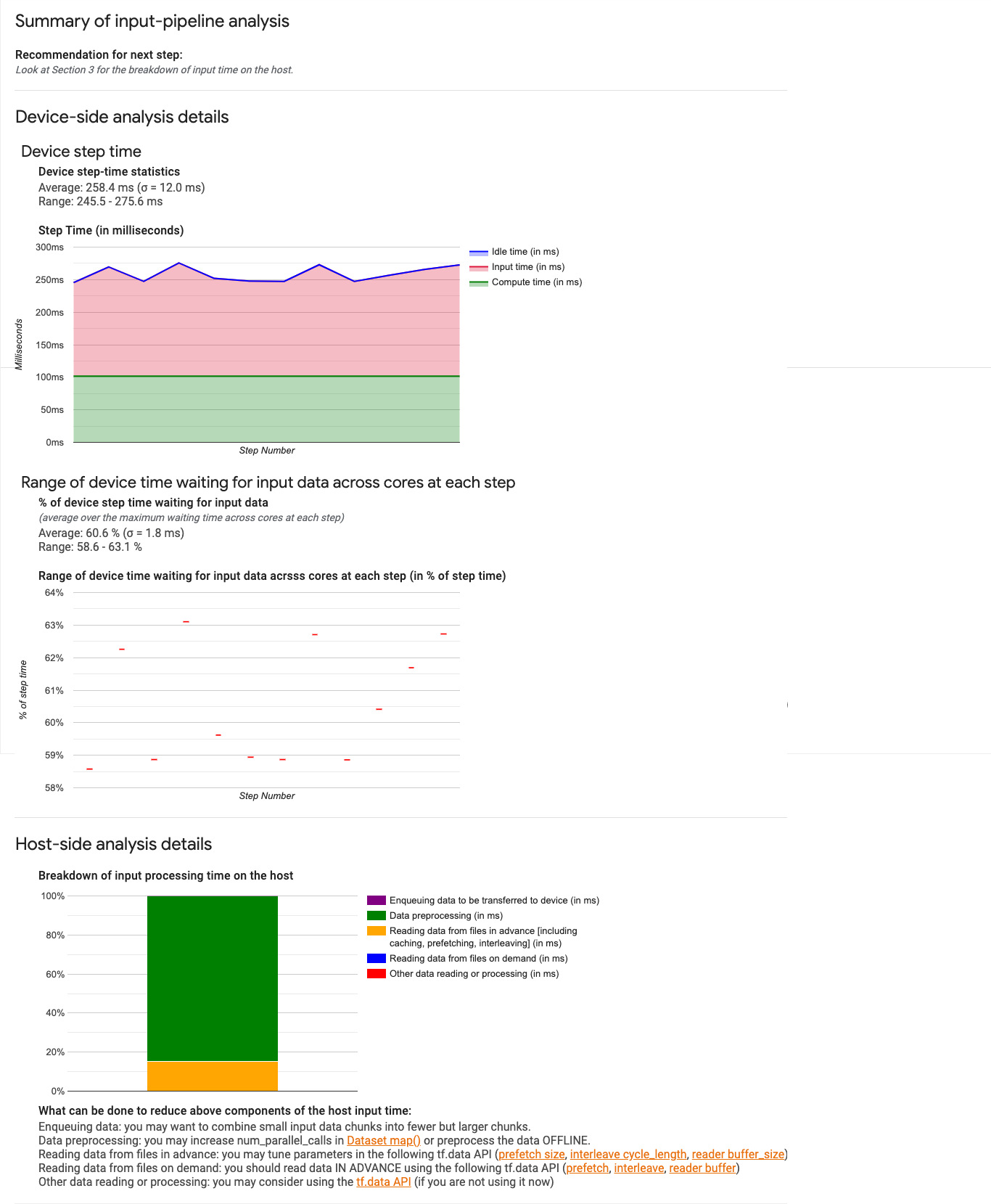
- Resumo. Resume o pipeline de entrada geral, informando se o aplicativo é limitado pela entrada e, em caso afirmativo, até que ponto.
- Análise no lado do dispositivo. Exibe os resultados detalhados da análise no lado do dispositivo, incluindo a duração de etapa do dispositivo e o tempo gasto por ele na espera pelos dados de entrada nos núcleos de cada etapa.
- Análise no lado do host. Mostra uma análise detalhada no lado do host, incluindo um detalhamento do tempo de processamento de entrada no host.
Resumo do pipeline de entrada
A primeira seção informa se o programa é limitado pela entrada, apresentando a porcentagem de tempo gasto pelo dispositivo na espera pela entrada do host. Se você estiver usando um pipeline de entrada padrão que tenha sido instrumentado, a ferramenta informará onde será gasta a maior parte do tempo de processamento de entrada. Exemplo:

Análise no lado do dispositivo
A segunda seção detalha a análise do dispositivo, com insights sobre o tempo gasto no dispositivo em relação ao host e quanto tempo de dispositivo foi gasto na espera pelos dados de entrada do host.
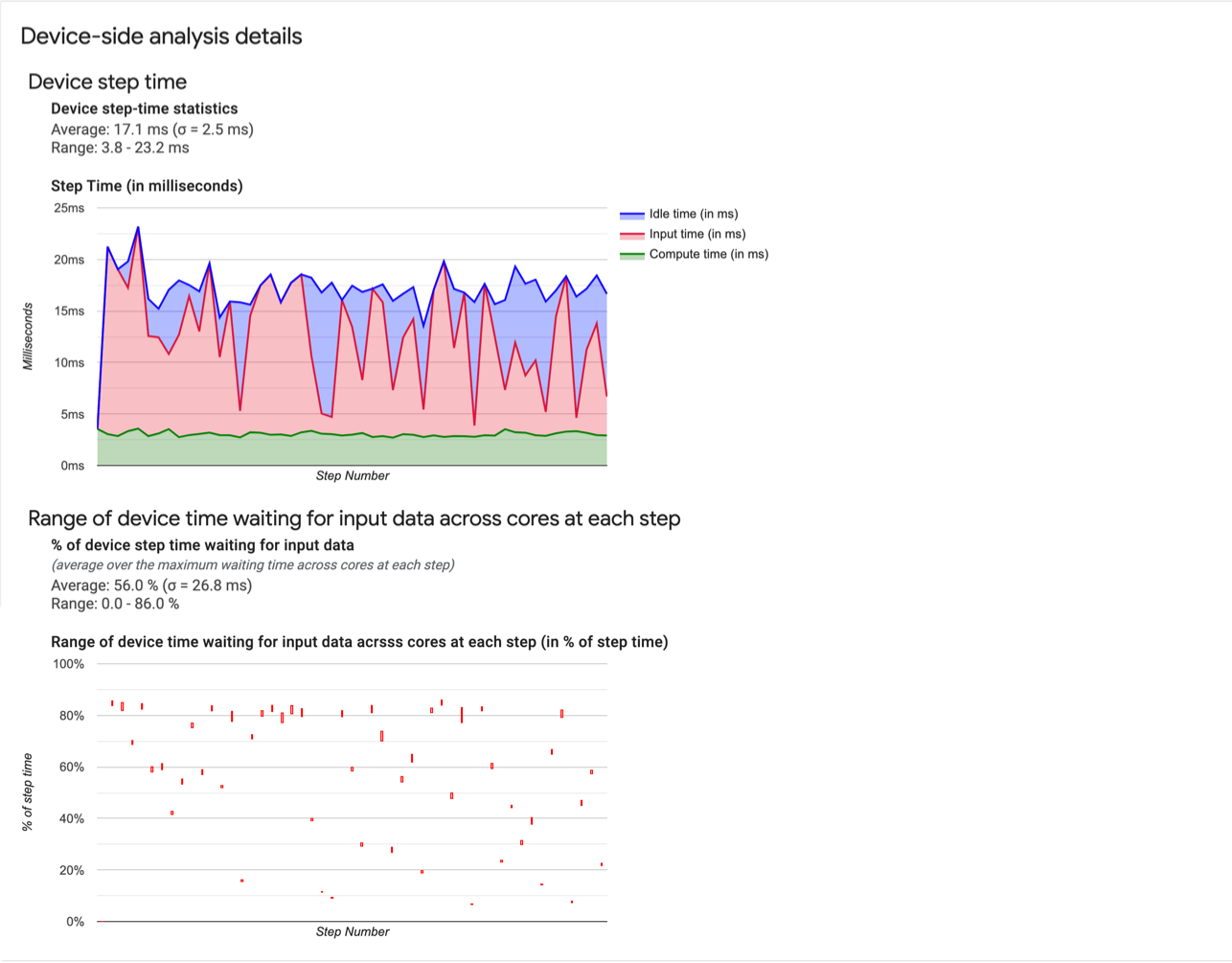
- Estatísticas de duração das etapas do dispositivo Informa a média, o desvio padrão e o intervalo (mínimo, máximo) da duração da etapa do dispositivo.
- Tempo de duração. Exibe um gráfico da duração da etapa do dispositivo (em milissegundos) que abrange todas as etapas da amostra. A área azul corresponde à parte da duração da etapa em que as TPUs permaneceram ociosas esperando os dados de entrada do host. A área vermelha mostra por quanto tempo o Cloud TPU realmente esteve em funcionamento.
- Porcentagem de tempo aguardando dados de entrada. Informa a média, o desvio padrão e o intervalo (mínimo, máximo) da fração de tempo gasto em um dispositivo aguardando os dados de entrada normalizados em relação à duração total das etapas do dispositivo.
- Intervalo de tempo do dispositivo em núcleos que foi gasto aguardando dados de entrada, por número de etapas. Exibe um gráfico de linhas com a quantidade de tempo do dispositivo (expresso como porcentagem do tempo total da etapa do dispositivo) gasto na espera pelo processamento de dados de entrada. A fração de tempo gasto varia de núcleo para núcleo, de modo que o intervalo de frações de cada núcleo também seja traçado para cada etapa. Como o tempo gasto por uma etapa é determinado pelo núcleo mais lento, convém que o intervalo seja o menor possível.
Análise no lado do host
Na seção 3, veja os detalhes da análise do host, com os relatórios do tempo de processamento de entrada (o tempo gasto nas operações da API Dataset) no host dividido em várias categorias:
- Enfileiramento de dados que serão transferidos para o dispositivo. Tempo gasto para colocar dados em uma fila de entrada antes de transferi-los para o dispositivo.
- Pré-processamento de dados. Tempo gasto em operações de pré-processamento, como descompactação de imagens.
- Leitura antecipada de dados de arquivos. Tempo gasto na leitura de arquivos, incluindo armazenamento em cache, pré-busca e intercalação.
- Leitura de dados de arquivos por demanda. Tempo gasto na leitura de dados de arquivos sem armazenamento em cache, pré-busca e intercalação.
- Outras leituras ou processamentos de dados. Tempo gasto em outras operações relacionadas à entrada
que não usam
tf.data.

Para ver as estatísticas de operações de entrada individuais e respectivas categorias divididas por tempo de execução, expanda a seção "Mostrar estatísticas das operações de entrada".
Será exibida uma tabela de dados de origem como a seguinte:
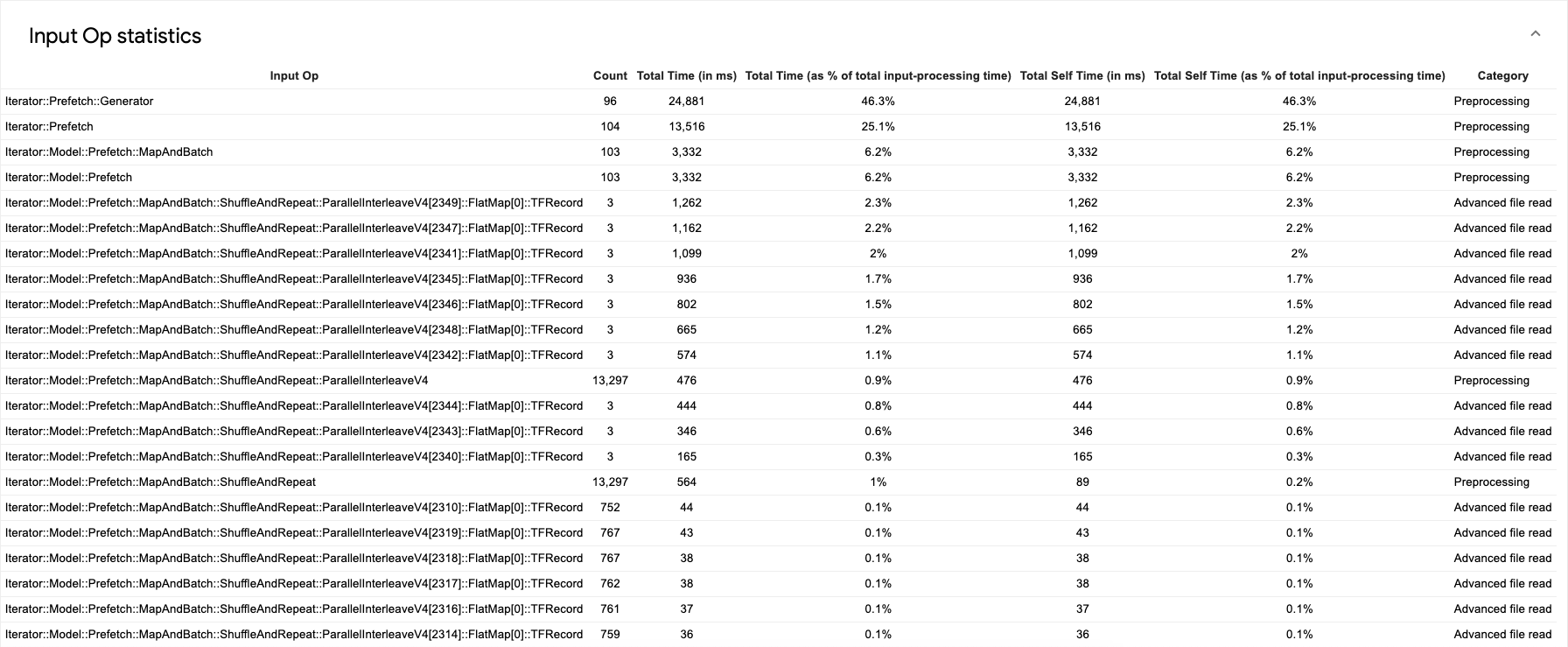
Cada entrada da tabela contém as seguintes informações:
- Operação de entrada. Mostra o nome da operação de entrada do TensorFlow.
- Contagem. Mostra o número total de instâncias da operação executadas durante o período de criação de perfil.
- Tempo total (em ms). Mostra a soma cumulativa do tempo gasto em cada uma das instâncias de operação.
- Porcentagem do tempo total. Mostra o tempo total gasto na operação como uma fração do tempo total gasto no processamento das entradas.
- Tempo próprio total (em ms). Mostra a soma cumulativa do tempo próprio
gasto em cada uma das instâncias. O tempo próprio mede o tempo gasto
no corpo da função, excluindo o tempo gasto na função chamada.
Por exemplo, se
Iterator::PaddedBatch::Filter::ForeverRepeat::Mapé chamada porIterator::PaddedBatch::Filter, o tempo próprio total da primeira será excluído do tempo próprio total da segunda. - Porcentagem de tempo próprio total: mostra o tempo próprio total como uma fração do tempo total gasto no processamento das entradas.
- Categoria. Mostra a categoria de processamento da operação de entrada.
Perfil de operações
O perfil de operações é uma ferramenta do Cloud TPU que exibe as estatísticas de desempenho das operações do XLA executadas durante um período de criação de perfil. O perfil de operações mostra:
- o uso que o aplicativo faz do Cloud TPU, com a porcentagem do tempo gasto em operações por categoria e de utilização de FLOPS de TPU;
- as operações mais demoradas, que são alvos potenciais de otimização;
- detalhes de operações individuais, incluindo forma, preenchimento e expressões que usam a operação.
É possível usar o perfil de operações para encontrar bons alvos de otimização. Por exemplo, se o modelo atingir apenas 5% de FLOPS de pico da TPU, será possível usar a ferramenta para identificar quais operações do XLA são mais demoradas na execução e quantos FLOPS de TPU elas consomem.
Como usar o perfil de operações
Durante a coleta de perfis, capture_tpu_profile também cria
um arquivo op_profile.json que contém estatísticas de desempenho das operações do XLA.
É possível visualizar os dados do op_profile no TensorBoard clicando na guia Perfil na parte superior da tela e selecionando op_profile na lista suspensa Ferramentas. Você verá uma tela como esta:
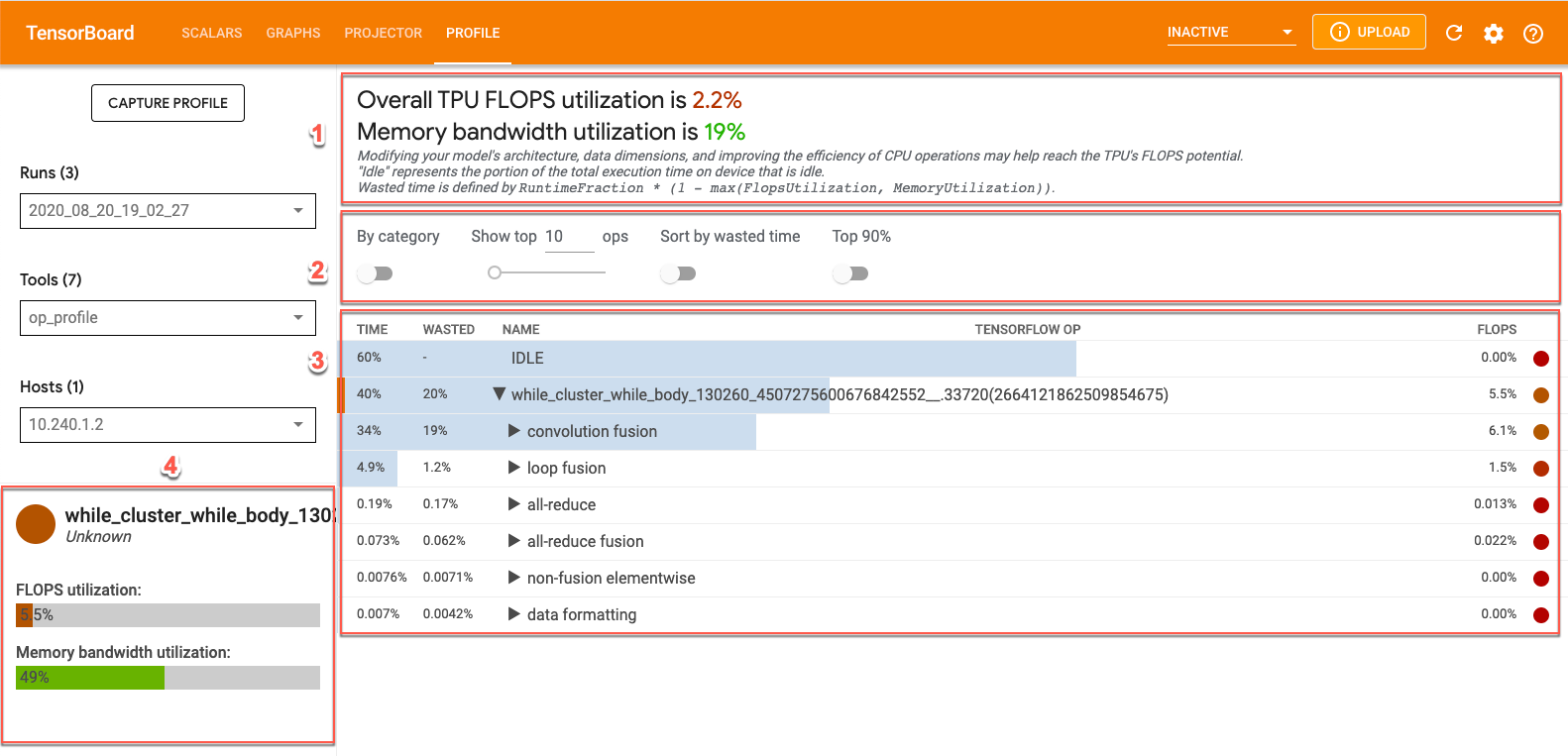
- Seção de visão geral. Mostra a utilização do Cloud TPU e fornece sugestões para otimização.
- Painel de controle. Contém controles que permitem definir o número de operações exibidas na tabela, quais operações são exibidas e como elas são classificadas.
- Tabela de operações. Uma tabela que lista as principais categorias de operações do TensorFlow associadas às operações do XLA. Essas operações são classificadas por porcentagem de uso do Cloud TPU.
- Cartões de detalhes das operações. Detalhes sobre a operação exibidos quando você passa o cursor sobre uma operação da tabela. Eles incluem a utilização de FLOPS, a expressão em que a operação é usada e o layout da operação (ajuste).
Tabela de operações do XLA
A tabela de operações lista as categorias de operações do XLA na ordem do maior uso para o menor uso do Cloud TPU, em porcentagem. Inicialmente, a tabela mostra a porcentagem de tempo gasto, o nome da categoria da operação, o nome associado da operação do TensorFlow e a porcentagem de utilização de FLOPS da categoria. Para exibir (ou ocultar) as 10 operações XLA mais demoradas de uma categoria, clique no triângulo ao lado do nome da categoria na tabela.
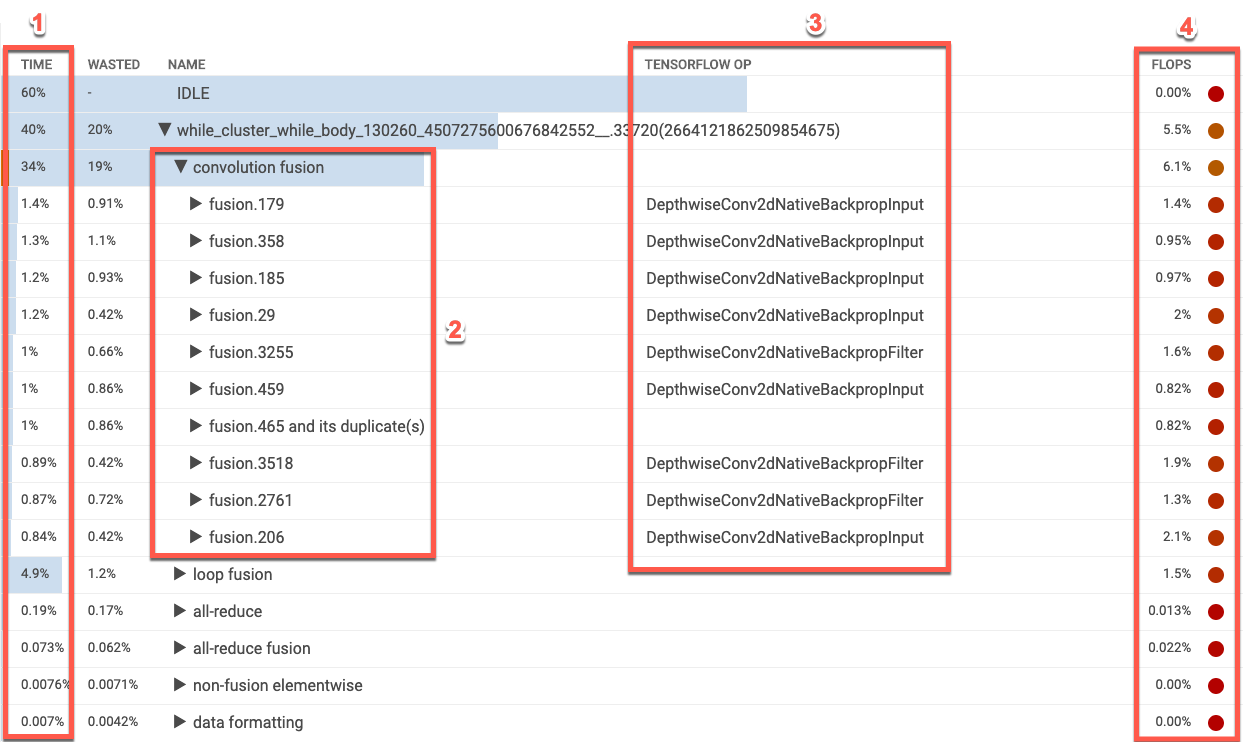
- Time. Mostra a porcentagem total de tempo gasto por todas as operações da categoria. Clique para expandir a entrada e ver o detalhamento do tempo gasto por cada operação individual.
- 10 primeiras operações. O botão de alternância ao lado do nome de uma categoria exibe/oculta as 10 operações mais demoradas da categoria. Se uma entrada de operação de fusão for exibida na lista de operações, será possível expandi-la para ver as operações elementares, que não são de fusão, que ela contém.
- Operações do TensorFlow. Mostra o nome da operação do TensorFlow associada à operação do XLA.
- FLOPS. Mostra a utilização de FLOPS, que é o número medido de FLOPS expresso como porcentagem de FLOPS de pico do Cloud TPU. Quanto maior a porcentagem de utilização de FLOPS, mais rápida a execução das operações. A célula da tabela é codificada por cores: verde para alta utilização de FLOPS (boa) e vermelho para baixa utilização de FLOPS (ruim).
Cartões de detalhes de operações
Quando você seleciona uma entrada de tabela, um card aparece à esquerda exibindo detalhes sobre a operação do XLA ou a categoria de operação. Um cartão costuma ter a seguinte aparência:
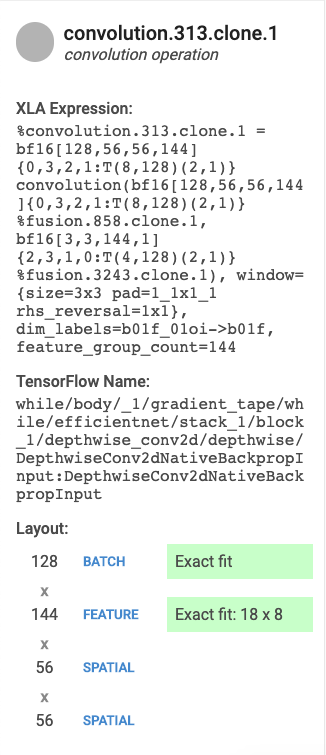
- Nome e Categoria. Mostra o nome e a categoria da operação do XLA em destaque.
- Utilização de FLOPS. Exibe a utilização de FLOPS como uma porcentagem do total de FLOPS possíveis.
- Expressão. Mostra a expressão do XLA que contém a operação.
- Uso de memória. Exibe a porcentagem de pico de uso da memória pelo programa.
- Layout (somente operações de convolução). Mostra a forma e o layout de um tensor, incluindo se a forma do tensor é um ajuste exato das unidades de matriz e como a matriz é preenchida.
Como interpretar resultados
Para operações de convolução, a utilização de FLOPS de TPU pode ser baixa devido a um ou ambos dos seguintes motivos:
- Preenchimento (as unidades da matriz são usadas parcialmente).
- A operação de convolução é limitada pela memória.
Nesta seção, veja uma interpretação de alguns números de outro modelo em que os FLOPS eram baixos. Neste exemplo, a fusão e a convolução de saída dominaram o tempo de execução e houve uma cauda longa de operações vetoriais ou escalares que tiveram FLOPS muito baixos.
Uma estratégia de otimização para esse tipo de perfil é transformar as operações vetoriais ou escalares em operações de convolução.
No exemplo a seguir, %convolution.399 tem menos FLOPS e utilização de memória do que %convolution.340, do exemplo anterior.
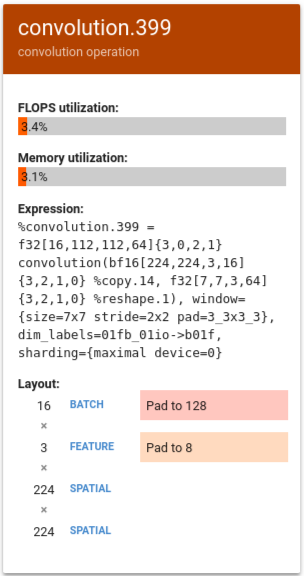
Examine o layout e observe que o tamanho do lote 16 está sendo preenchido até 128 e o tamanho do recurso 3 está sendo preenchido até 8, o que indica que apenas 5% das unidades da matriz são efetivamente usadas. O cálculo dessa instância de porcentagem de utilização é (((batch_time * num_of_features) / padding_size ) / num_of_cores). Compare os FLOPS deste exemplo com %convolution.340 do exemplo anterior, que tem um ajuste exato à matriz.
Visualizador de pod
A ferramenta visualizador de pod fornece visualizações de desempenho de cada núcleo em um pod e exibe o status dos canais de comunicação entre os núcleos de um pod. O visualizador de pod é capaz de identificar e destacar possíveis gargalos e áreas que precisam de otimização. A ferramenta funciona para pods completos e para todas as frações de pod v2 e v3.
Para exibir a ferramenta visualizador de pod, faça o seguinte:
- Selecione Perfil no botão de menu no canto superior direito da janela do TensorBoard.
- Clique no menu Ferramentas no lado esquerdo da janela e selecione pod_viewer.
A interface do usuário do visualizador de pod inclui:
- Um controle deslizante de etapa, que permite selecionar a etapa a examinar.
- Um gráfico de topologia, que visualiza interativamente seus núcleos de TPU em todo o sistema de TPU.
- Um gráfico de links de comunicação, que visualiza os canais de envio e recebimento (recv) no gráfico da topologia.
- Um gráfico de barras referente à latência de canais de envio e recebimento. Passar o cursor sobre uma barra desse gráfico ativa os links de comunicação no gráfico de links de comunicação. Um cartão de detalhes do canal aparece na barra à esquerda, fornecendo informações detalhadas do canal, como tamanho dos dados transferidos, latência e largura de banda.
- Um gráfico de detalhamento de etapas, que visualiza o detalhamento de uma etapa para todos os núcleos. Ele pode ser usado para rastrear os gargalos e verificar se um determinado núcleo está atrasando o sistema.
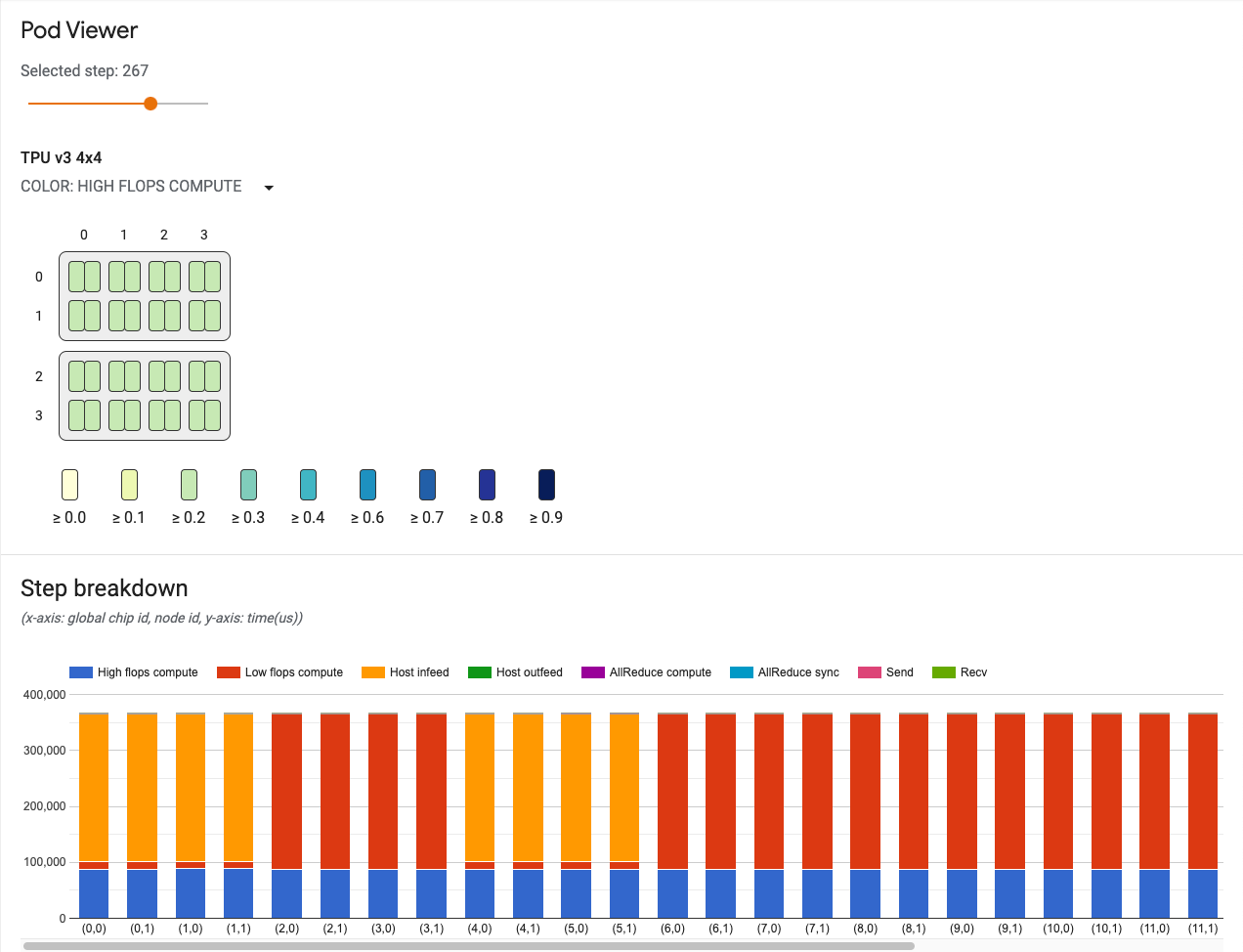
Controle deslizante de etapa
Use o controle deslizante para selecionar uma etapa. O restante da ferramenta exibe estatísticas, como detalhamento da etapa e links de comunicação, referente à etapa em questão.
Gráfico de topologia
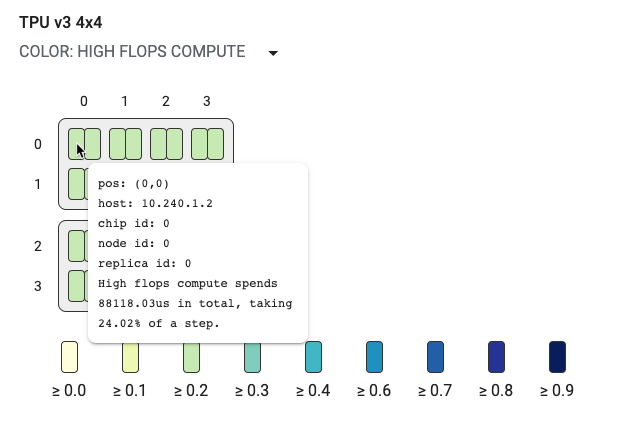
O gráfico de topologia é organizado hierarquicamente por host, chip e núcleo. Os retângulos menores são núcleos de TPU. Dois núcleos juntos representam um chip de TPU e quatro chips juntos representam um host.
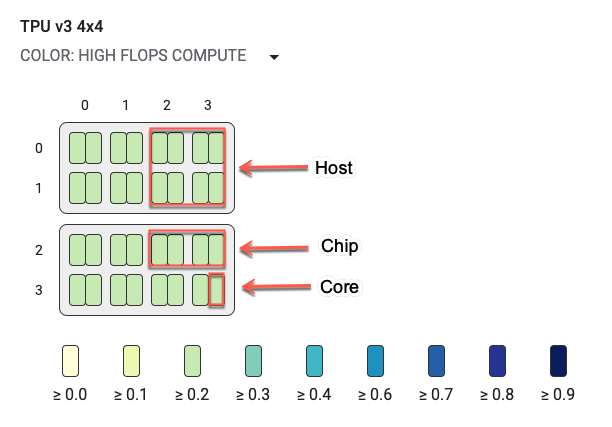
O gráfico de topologia também é um mapa de calor com cores que representam a porcentagem de duração que um segmento específico (por exemplo, cálculo de flops altos, entrada, envio etc.) leva no passo selecionado. A barra logo abaixo do gráfico de topologia (mostrada no gráfico a seguir) mostra um código de cores referente ao uso do núcleo e do chip. A cor dos núcleos mostra a utilização variando de amarelo a azul. Para cálculo de flops altos, números maiores (cor mais escura) indicam mais tempo gasto no cálculo. Para todos os outros detalhamentos, números menores (cores mais claras) indicam menores tempos de espera. Áreas com problemas potenciais, ou pontos de acesso, são indicados quando um núcleo é mais escuro que os outros.
Clique no seletor do menu suspenso ao lado do nome do sistema (destacado no diagrama) para escolher o tipo específico de detalhamento que você quer examinar.
Passe o mouse sobre qualquer um dos retângulos pequenos (núcleos simples) para exibir uma dica que mostra a posição do núcleo no sistema, o código global do chip e o nome de host. A dica também inclui a duração da categoria de detalhamento selecionada, como flops altos e a respectiva porcentagem de utilização em uma etapa.
Canais de comunicação
Essa ferramenta ajuda a visualizar os links de envio e recebimento, caso sejam usados pelo modelo na comunicação entre os núcleos. Quando seu modelo contém operações de envio e recebimento, é possível usar um seletor de ID de canal para selecionar um ID de canal. Um link do núcleo de origem (src) e do núcleo de destino (dst) representa o canal de comunicação. Para renderizá-lo no gráfico de topologia, passe o cursor do mouse sobre as barras do gráfico que mostram a latência dos canais de envio e recebimento.

Um cartão aparece na barra à esquerda, com mais detalhes sobre o canal de comunicação. Um cartão costuma ter a seguinte aparência:
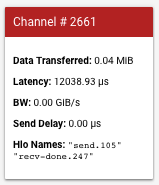
- Dados transferidos, que mostra os dados transferidos pelo canal de envio e recebimento em memibytes (MiB).
- Latência, que mostra o tempo, em microssegundos, desde o início do evento de envio até o final do evento de recebimento concluído.
- BW, que mostra a quantidade de dados transferidos, em gibibites (GiB), do núcleo de origem para o núcleo de destino durante o tempo contado.
- Atraso de envio, que é o tempo desde o início do recebimento concluído até o início do envio, em microssegundos. Se a operação de recebimento concluído começar após o início da operação de envio, o atraso é zero.
- Nomes de Hlo, que exibe os nomes de operações hlo do XLA associados a este canal. Esses nomes estão associados às estatísticas exibidas em outras ferramentas do TensorBoard, como op_profile e memory_viewer.
Gráfico de detalhamento das etapas
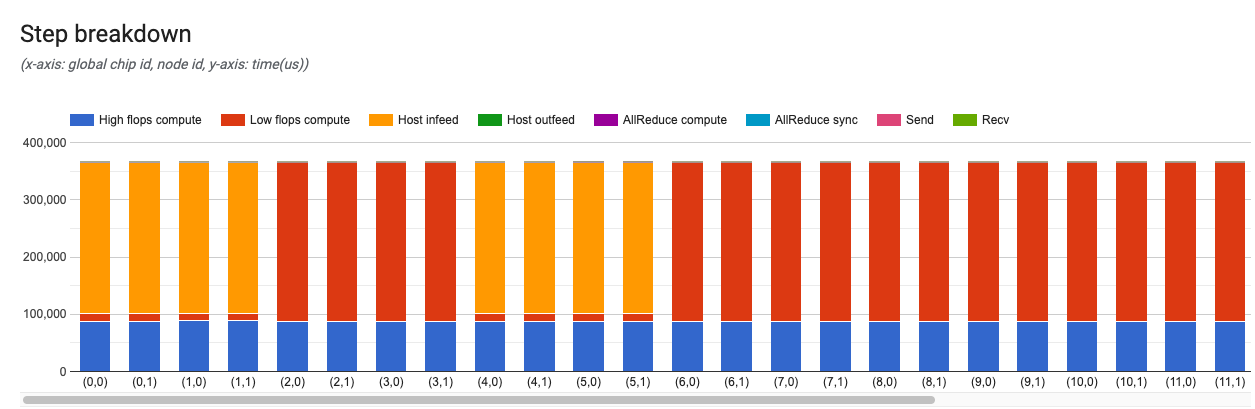
Este gráfico fornece detalhes de cada etapa de treinamento ou avaliação.
O eixo x é o código global do chip e o eixo y é o tempo em microssegundos. Neste gráfico, você pode ver onde o tempo é usado em uma determinada etapa de treinamento, onde há gargalos e se há um desequilíbrio de carga entre todos os chips.
Um card aparece na barra do lado esquerdo, com mais detalhes sobre o detalhamento da etapa. Um cartão costuma ter a seguinte aparência:
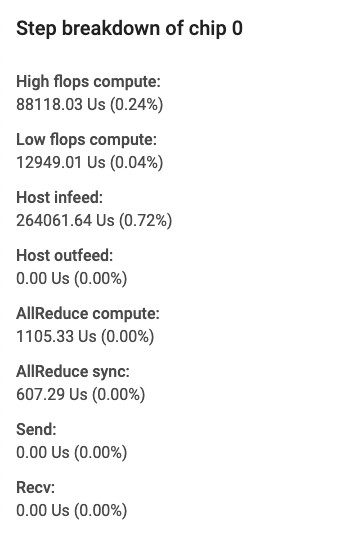
Os campos do cartão especificam o seguinte:
- Cálculo de flops altos, que é o tempo gasto em operações de convolução ou fusão de saída (ops).
- Cálculo de flops baixos, que é feito com a dedução de todos os outros detalhamentos da duração total.
- Entrada, que é o tempo que a TPU gasta à espera do host.
- Saída, que é o tempo que o host gasta à espera da saída da TPU.
- Sincronização AllReduce, que é a fração de tempo gasta em operações CrossReplicaSum aguardando para sincronizar com outros núcleos. As operações CrossReplicaSum calculam a soma entre as réplicas.
- Cálculo AllReduce, que é o tempo de cálculo real gasto em operações CrossReplicaSum.
- Operações de envio de chip para chip, que é o tempo gasto nas operações de envio.
- Operações de recebimento concluído de chip para chip, que é o tempo gasto nas operações de recebimento.
Visualizador de traces
O visualizador de traces é uma ferramenta de análise de desempenho do Cloud TPU disponível em Perfil. Ela usa o visualizador de perfil de evento de trace do Chrome para que funcione apenas no navegador Chrome.
O visualizador de traces contém uma linha do tempo que mostra:
- as durações das operações que foram executadas pelo seu modelo do TensorFlow;
- qual parte do sistema (TPU ou máquina host) executou uma operação. A máquina host costuma executar operações de entrada, realiza o pré-processamento dos dados de treinamento e os transfere para a TPU, enquanto a TPU executa o treinamento do modelo de fato.
Com o visualizador de traces, é possível identificar problemas de desempenho do modelo e tomar providências para solucioná-los. Por exemplo, de modo geral, é possível identificar se a entrada ou o treinamento do modelo está tomando a maior parte do tempo. Em uma análise mais detalhada, é possível identificar quais operações do TensorFlow estão demorando mais para serem executadas.
O visualizador de traces é limitado a 1 milhão de eventos por Cloud TPU. Se você precisar avaliar mais eventos, use o visualizador de rastros em streaming.
Interface do visualizador de traces
Para abrir o visualizador de traces, acesse o TensorBoard, clique na guia Perfil na parte superior da tela e escolha trace_viewer no menu suspenso Ferramentas. O visualizador é exibido com a execução mais recente:
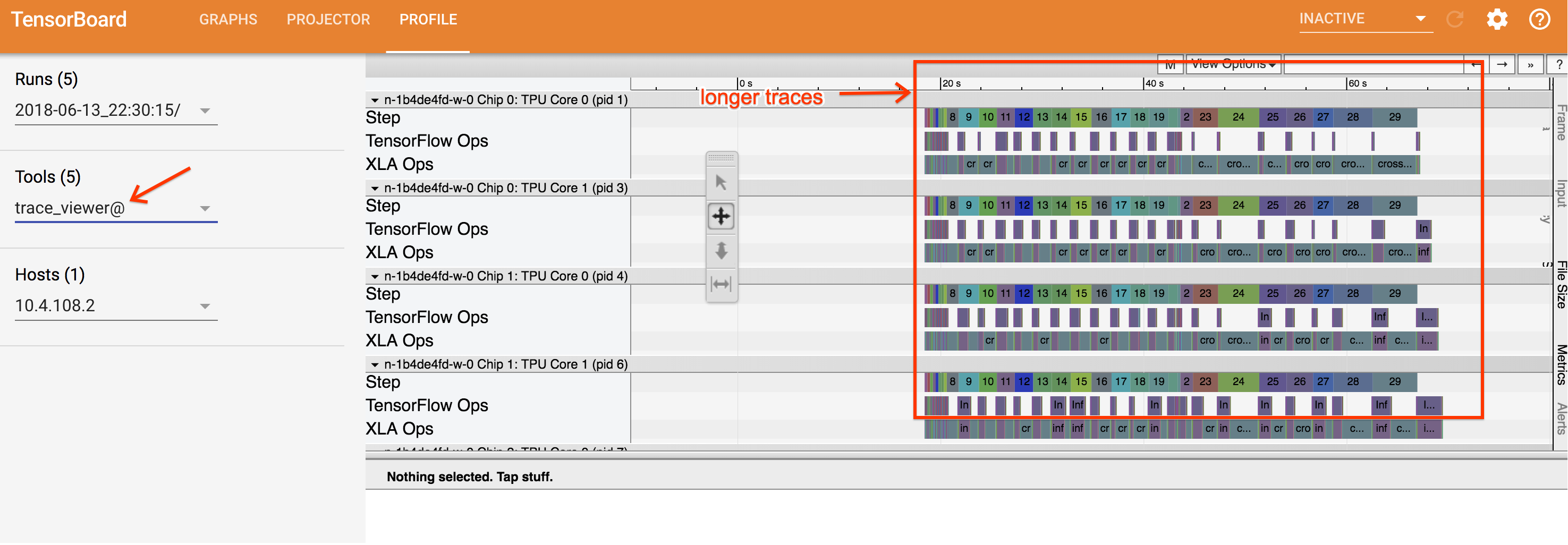
Essa tela contém os seguintes elementos principais (marcados com números):
- Lista suspensa Execuções. Contém todas as execuções de que você capturou informações de trace. A visualização padrão é a execução mais recente, mas é possível abrir a lista suspensa para selecionar outra execução.
- Lista suspensa Ferramentas. Seleciona diferentes ferramentas de criação de perfil.
- Lista suspensa de hosts. Seleciona um host que contém um conjunto de TPUs.
- Painel da linha do tempo. Mostra operações que o Cloud TPU e a máquina host executaram ao longo do tempo.
- Painel de detalhes. Mostra outras informações das operações selecionadas no painel da linha do tempo.
Esta é uma visão mais detalhada do painel da linha do tempo:
O painel da linha do tempo contém os seguintes elementos:
- Barra superior. Contém vários controles auxiliares.
- Eixo de tempo. Mostra o tempo em relação ao início do trace.
- Rótulos de seção e faixa. Cada seção contém várias faixas e um triângulo à esquerda que, quando clicado, expande e recolhe a seção. Há uma seção para cada elemento de processamento do sistema.
- Seletor de ferramentas. Contém várias ferramentas para interagir com o visualizador de traces.
- Eventos. Mostra a duração da execução de uma operação ou a duração dos metaeventos, como as etapas de treinamento.
- Barra de guias verticais. Isso não tem uma finalidade útil para o Cloud TPU. A barra faz parte da ferramenta visualizador de rastros de uso geral fornecida pelo Chrome, que é usada para várias tarefas de análise de desempenho.
Seções e linhas
O visualizador de traces contém as seguintes seções:
- Uma seção para cada nó da TPU, rotulada com o número do chip da TPU e o nó da TPU dentro do chip (por exemplo, "Chip 2: núcleo da TPU 1"). Cada seção de nó da TPU contém as seguintes faixas:
- Etapa. Mostra a duração das etapas de treinamento que foram executadas na TPU.
- Operações do TensorFlow. Mostra as operações do TensorFlow executadas na TPU.
- Operações do XLA. Mostra as operações do XLA que foram executadas na TPU. Cada operação é convertida em uma ou várias operações do XLA. O compilador XLA converte as operações do XLA em código que é executado na TPU.
- Uma seção de threads em execução na CPU da máquina host, denominada "Threads de host". Esta seção contém uma faixa para cada thread da CPU. Observação: é possível ignorar as informações exibidas ao lado dos rótulos da seção.
Seletor de ferramenta da linha do tempo
É possível interagir com a visualização da linha do tempo usando o seletor de ferramentas da linha do tempo no TensorBoard. Clique em uma ferramenta da linha do tempo ou usar os seguintes atalhos de teclado para ativar e destacar uma ferramenta. Para mover o seletor de ferramentas da linha do tempo, clique na área pontilhada na parte superior e arraste o seletor até o local desejado.
Use as ferramentas da linha do tempo da seguinte maneira:
|
Ferramenta de seleção Clique em um evento para selecioná-lo ou arraste para selecionar vários eventos. O painel de detalhes exibe mais informações sobre os eventos selecionados (nome, horário de início e duração). |
|
Ferramenta de panorama Arraste para movimentar a visualização da linha do tempo na horizontal e na vertical. |
|
Ferramenta de zoom Arraste para cima ou para baixo para, respectivamente, aumentar ou diminuir o zoom ao longo do eixo horizontal (tempo). A posição horizontal do cursor do mouse determina o centro da área onde o zoom será aplicado. Observação: a ferramenta Zoom tem um bug conhecido que deixa o zoom ativado se o botão do mouse for liberado enquanto o cursor estiver do lado de fora da visualização da linha do tempo. Se isso acontecer, basta clicar na visualização da linha de tempo para parar o zoom. |
|
Ferramenta de tempo Arraste horizontalmente para marcar um intervalo de tempo. A duração do intervalo aparece no eixo do tempo. Para ajustar o intervalo, arraste as extremidades. Para limpar o intervalo, clique em qualquer lugar dentro da visualização da linha do tempo. Observe que o intervalo permanece marcado se você selecionar uma das outras ferramentas. |
Eventos
Os eventos na linha do tempo são exibidos em cores diferentes, que não têm significado específico.
Barra superior da linha do tempo
A barra superior do painel de linha do tempo contém vários controles auxiliares:

- Exibição de metadados. Não usado para TPUs.
- Opções de visualização. Não usado para TPUs.
- Caixa de pesquisa. Insira um texto para procurar todos os eventos com esse texto no nome. Clique nos botões de seta à direita da caixa de pesquisa para avançar e recuar pelos eventos correspondentes, selecionando cada um por vez.
- Botão do console. Não usado para TPUs.
- Botão de ajuda. Clique para exibir um resumo da ajuda.
Atalhos do teclado
Veja a seguir os atalhos de teclado que podem ser usados no visualizador de traces. Clique no botão "Ajuda" (?) na barra superior para ver mais atalhos.
w Zoom in
s Zoom out
a Pan left
d Pan right
f Zoom to selected event(s)
m Mark time interval for selected event(s)
1 Activate selection tool
2 Activate pan tool
3 Activate zoom tool
4 Activate timing tool
O atalho f pode ser muito útil. Selecione uma etapa e pressione f para ampliar a etapa rapidamente.
Eventos característicos
A seguir, veja alguns tipos de eventos que podem ser muito úteis na análise de desempenho da TPU.

InfeedDequeueTuple. Essa operação do TensorFlow é executada em uma TPU e recebe dados de entrada provenientes do host. Quando a entrada demora muito, isso pode significar que as operações do TensorFlow que pré-processam os dados na máquina host não conseguem acompanhar a taxa de consumo de dados da TPU. Veja os eventos correspondentes nos traces do host denominados InfeedEnqueueTuple. Para visualizar uma análise mais detalhada do pipeline de entrada, use a ferramenta analisador do pipeline de entrada.
CrossReplicaSum. Essa operação do TensorFlow é executada em uma TPU e calcula uma soma entre as réplicas. Como cada réplica corresponde a um nó de TPU diferente, a operação precisa aguardar a conclusão de todos os nós da TPU em uma etapa. Se essa operação estiver demorando muito, talvez não seja porque a operação de soma seja lenta, mas que um nó da TPU esteja aguardando outro nó da TPU com uma entrada lenta de dados.

- Operações do conjunto de dados. O visualizador de traces visualiza as operações de conjunto de dados executadas no carregamento dos dados usando a API do conjunto de dados.
No exemplo acima,
Iterator::Filter::Batch::ForeverRepeat::Memoryé compilado e corresponde à operaçãodataset.map(). Use o visualizador de traces para examinar as operações de carregamento enquanto você faz a depuração e a mitigação dos gargalos do pipeline de entrada.
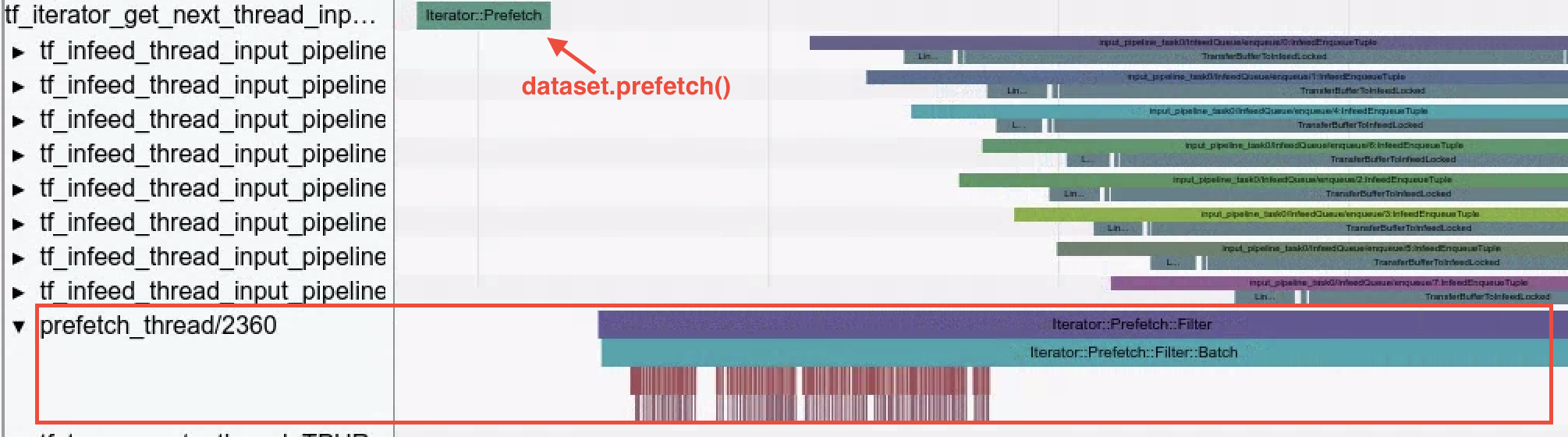
- Threads de pré-busca. O uso de
dataset.prefetch()para armazenar em buffer os dados de entrada pode evitar atrasos esporádicos no acesso a arquivos, que criam gargalos no pipeline de entrada.
O que pode dar errado
Veja alguns problemas possíveis a serem observados ao usar o visualizador de traces:
- Limite de exibição de eventos. O visualizador de traces exibe, no máximo, um milhão de eventos. Se você capturou mais eventos, apenas o primeiro milhão de eventos será exibido. Os eventos posteriores são descartados. Para capturar mais eventos da TPU, use a
sinalização
--include_dataset_ops=Falsepara exigir explicitamente quecapture_tpu_profileexclua as operações do conjunto de dados. - Eventos muito longos. Os eventos que começam antes do início de uma captura ou que terminam após a conclusão de uma captura não são visíveis no visualizador de traces. Consequentemente, eventos muito longos podem não aparecer.
Quando iniciar a captura de traces. Certifique-se de iniciar a captura de traces depois de verificar que o Cloud TPU está em execução. Se você começar antes disso, poderá ver apenas alguns eventos ou nenhum evento no visualizador de traces. É possível aumentar o tempo do perfil usando a sinalização
--duration_mse definir novas tentativas automáticas usando a sinalização--num_tracing_attempts. Exemplo:(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000 --num_tracing_attempts=10
Visualizador de memória
O visualizador de memória permite que você visualize o pico de uso de memória do programa e as tendências de uso de memória durante o ciclo de vida do programa.
A IU do visualizador de memória tem esta aparência:
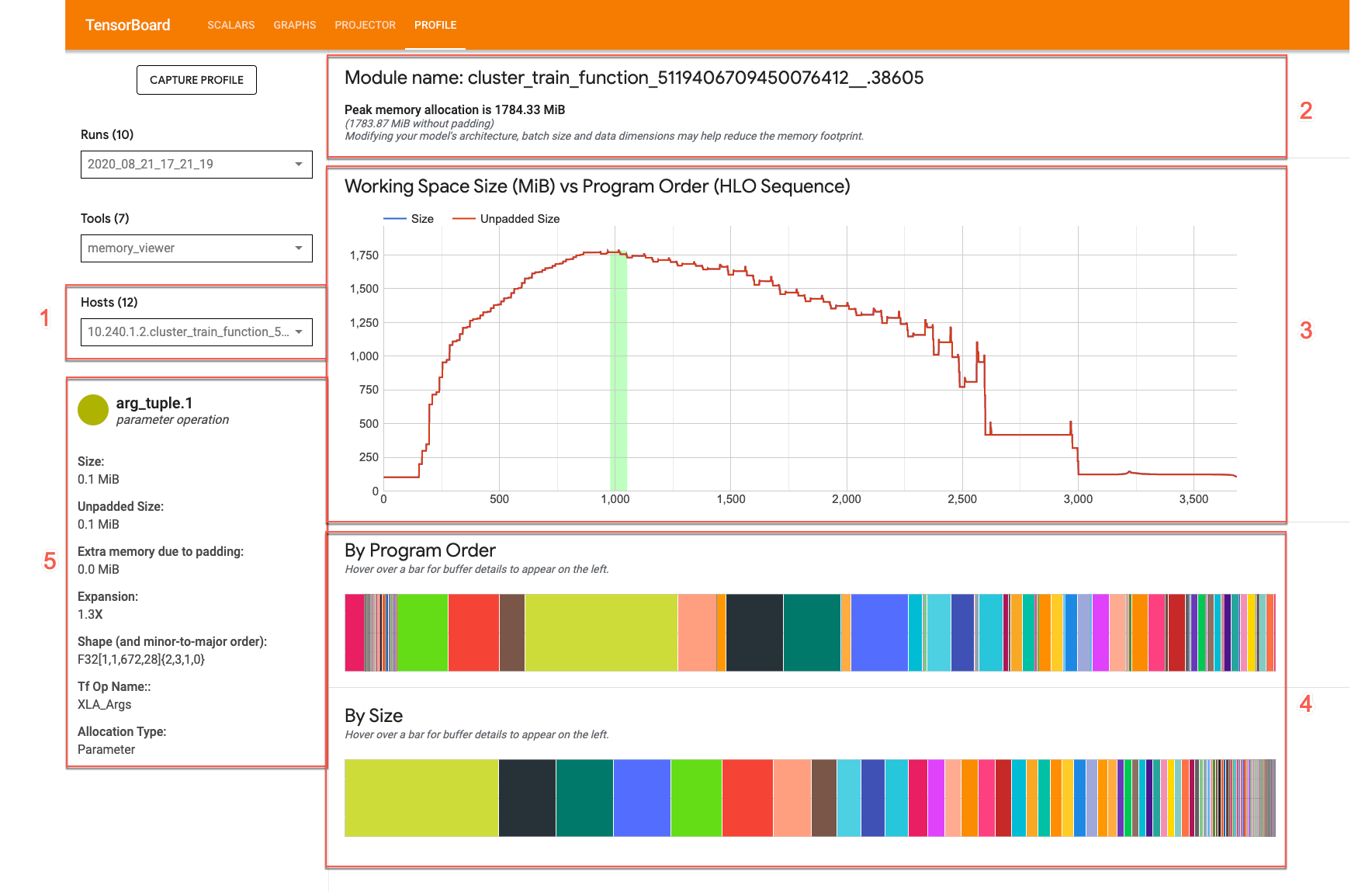
- Lista suspensa de hosts. Seleciona para um host de TPU e módulos do otimizador de alto nível (HLO, na sigla em inglês) do XLA para visualização.
- Visão geral da memória. Mostra a alocação de memória de pico e o tamanho sem padding.
- Gráfico do espaço de trabalho. Exibe o uso de memória de pico e um traçado das tendências de uso de memória durante o ciclo de vida do programa. Passar o cursor sobre um buffer em um dos gráficos de buffer adiciona uma anotação ao ciclo de vida do buffer e ao cartão de detalhes do buffer.
- Gráficos de buffer. Dois gráficos que exibem a alocação do buffer no ponto de pico de uso da memória, conforme indicado pela linha vertical no traçado do espaço de trabalho. Passar o cursor sobre um buffer em um dos gráficos de buffer exibe a barra do ciclo de vida do buffer no gráfico de espaço de trabalho e um cartão de detalhes à esquerda.
- Cartão de detalhes de alocação de buffer. Exibe detalhes de alocação de um buffer.
Painel de visão geral da memória
O painel de visão geral da memória (superior) mostra o nome do módulo e a alocação de memória de pico definida quando o tamanho total de alocação do buffer atinge o máximo. O tamanho da alocação de pico sem preenchimento também é mostrado para comparação.

Gráfico do espaço de trabalho
Esse gráfico exibe o uso de memória de pico e um traçado das tendências de uso de memória durante o ciclo de vida do programa. A barra vertical no gráfico indica a utilização da memória de pico do programa. Esse ponto determina se um programa pode ou não se ajustar ao espaço de memória global disponível.
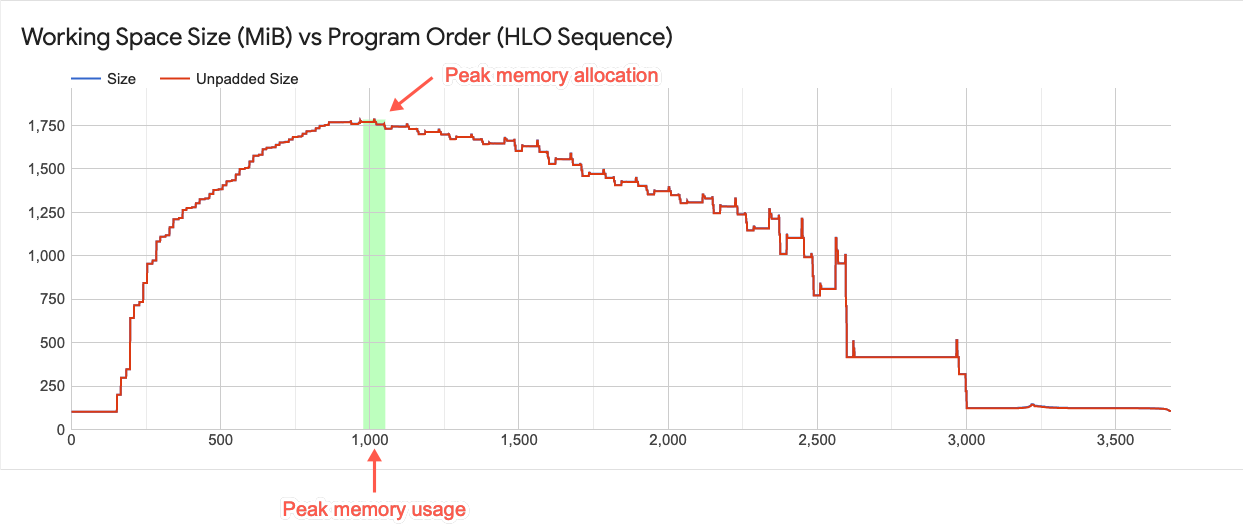
Cada ponto no traçado de linhas sobrepostas representa um "ponto do programa" HLO do XLA, conforme programado pelo compilador. A barra fornece uma noção da progressão de picos antes e depois do uso máximo.
Interação com elementos do gráfico de buffer
Quando você passa o cursor sobre um buffer exibido em um dos gráficos de buffer abaixo do gráfico do espaço de trabalho, aparece uma linha horizontal do ciclo de vida desse buffer no gráfico do espaço de trabalho. A linha horizontal tem a mesma cor do buffer destacado.
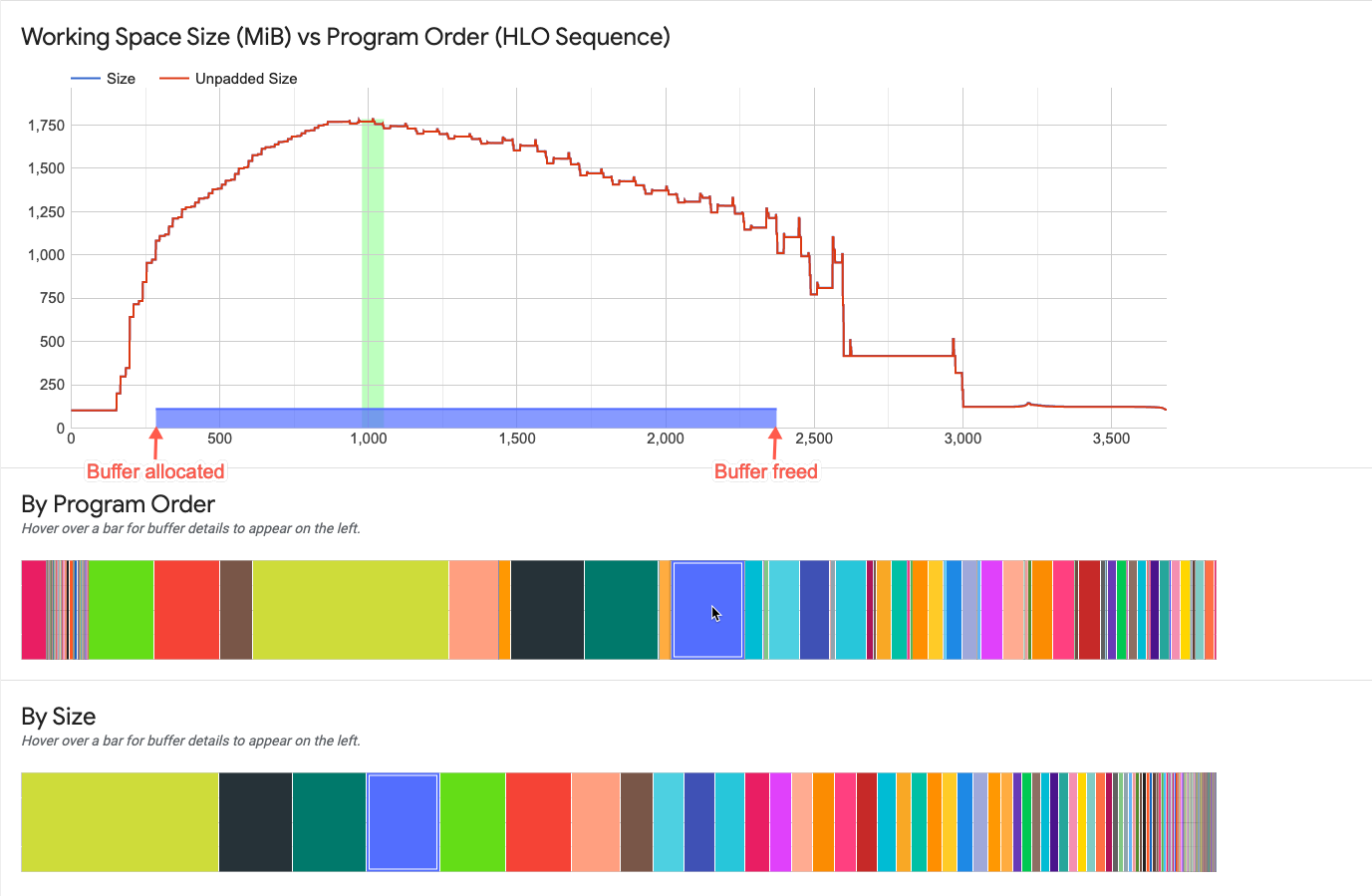
A espessura da linha horizontal indica a magnitude relativa do tamanho do buffer em relação à alocação de memória de pico. O comprimento da linha corresponde ao ciclo de vida do buffer, iniciando no ponto do programa em que o espaço do buffer foi alocado e terminando onde o espaço foi liberado.
Gráficos de buffer
Dois gráficos mostram o detalhamento do uso de memória no ponto de pico de uso (indicado pela linha vertical na área acima dos gráficos).
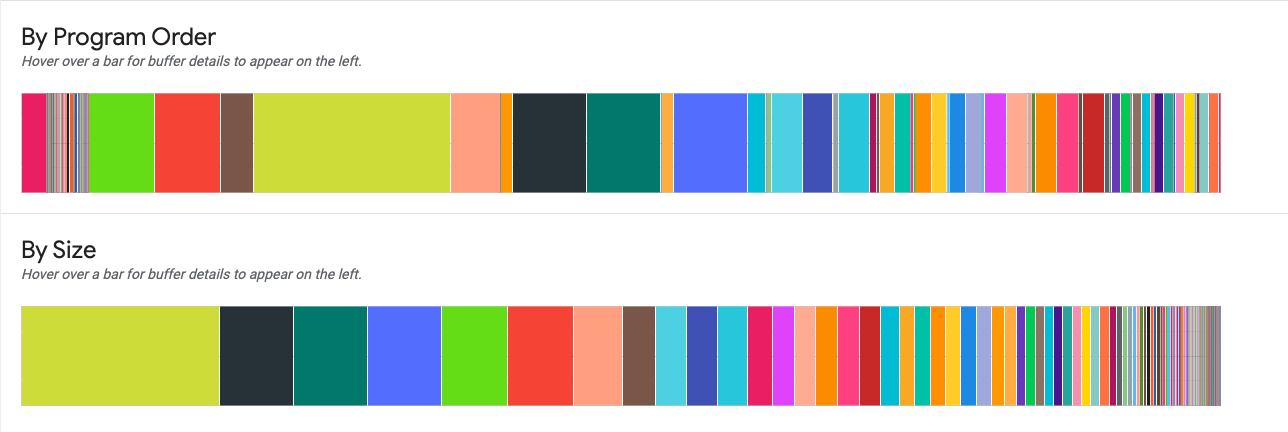
Por ordem de programa. Exibe os buffers da esquerda para a direita na ordem em que eles estavam ativos durante a execução do programa. Os buffers ativos por mais tempo estão no lado esquerdo do gráfico.
Por tamanho. Exibe os buffers que estavam ativos durante a execução do programa em ordem de tamanho decrescente. Os buffers que tiveram o maior impacto no ponto de pico de uso de memória estão à esquerda.
Cartão de detalhes de alocação de buffer
Quando você passa o cursor sobre um buffer exibido em um dos gráficos de buffer, aparece um cartão de detalhes de alocação de buffer (além da linha do ciclo de vida exibida no gráfico de trabalho). Um cartão de detalhes costuma ter a seguinte aparência:
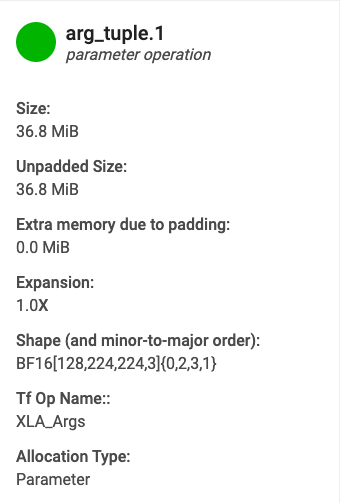
- Nome. Nome da operação do XLA.
- Categoria. Categoria da operação.
- Tamanho. Tamanho da alocação do buffer (incluindo preenchimento).
- Tamanho sem preenchimento. Tamanho da alocação do buffer sem preenchimento.
- Expansão. Magnitude relativa do tamanho do buffer preenchido em relação ao tamanho não preenchido.
- Memória extra. Indica quanta memória extra é usada para preenchimento.
- Forma. Descreve a classificação, o tamanho e o tipo de dados da matriz de N dimensões.
- Nome da operação do TensorFlow. Mostra o nome da operação do TensorFlow associada à alocação do buffer.
- Tipo de alocação. Indica a categoria de alocação do buffer. Os tipos são: parâmetro, saída, thread-local e temporário (por exemplo, alocação de buffer em uma fusão).
Erros de "memória insuficiente"
Se você executar um modelo e receber um "erro de memória insuficiente", use o seguinte comando para capturar um perfil de memória e visualizá-lo no visualizador de memória. Certifique-se de definir duration_ms adequadamente para que o período de criação de perfil se sobreponha ao tempo de compilação do programa. A saída pode ajudar você a entender o que causou o erro:
(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000
Visualizador de traces em streaming
O visualizador de traces em streaming (trace_viewer) é uma ferramenta de análise de desempenho do Cloud TPU, disponível para o TensorFlow 2.16.1 ou posterior, que fornece renderizações de trace dinâmico. Ela usa o visualizador de perfil de evento de trace do Chrome
para que funcione apenas no navegador Chrome.
Quando você usa capture_tpu_profile para
capturar um perfil, um arquivo .tracetable é salvo no bucket do
Google Cloud Storage. O arquivo contém um grande número de eventos de trace que é possível visualizar no
visualizador de traces e no visualizador de traces em streaming.
Como usar o visualizador de traces em streaming
Para usar o visualizador de traces em streaming, trace_viewer, é preciso encerrar a sessão no TensorBoard existente e depois reiniciá-lo usando o endereço IP da TPU que quer examinar. O visualizador de rastreamento de streaming exige que o TensorBoard faça uma chamada de procedimento remoto do Google (GRPC, na sigla em inglês) para um endereço IP do Cloud TPU. O canal GRPC não é criptografado.
Você encontra o endereço IP de um host do Cloud TPU na página do Cloud TPU. Encontre o Cloud TPU e procure o endereço IP na coluna IP interno.
Na sua VM, execute o TensorBoard da seguinte maneira, substituindo tpu-ip pelo endereço IP da TPU:
(vm)$ tensorboard --logdir=${MODEL_DIR} \
--master_tpu_unsecure_channel=tpu-ip
A ferramenta TensorBoard é exibida na lista suspensa Ferramentas.
Na linha do tempo, é possível aumentar e diminuir o zoom para ver o carregamento dinâmico dos eventos de trace no navegador.
Como monitorar seu job da Cloud TPU
Nesta seção, descreveremos como usar capture_tpu_profile para capturar um único perfil
ou monitorar continuamente seu job do Cloud TPU na interface de
linha de comando em tempo real. Ao definir a opção --monitoring_level
como 0 (padrão), 1 ou 2, você recebe
um único perfil, monitoramento básico ou monitoramento detalhado, respectivamente.
Abra um novo Cloud Shell e se conecte por SSH na VM (substitua vm-name no comando pelo nome da VM):
(vm)$ gcloud compute ssh vm-name \
--ssh-flag=-L6006:localhost:6006
No novo Cloud Shell, execute capture_tpu_profile com a
sinalização --monitoring_level definida como 1 ou 2. Por exemplo:
(vm)$ capture_tpu_profile --tpu=$TPU_NAME \
--monitoring_level=1
Configurar monitoring_level=1 produz um resultado semelhante ao seguinte:
TPU type: TPU v2
Utilization of TPU Matrix Units is (higher is better): 10.7%
Configurar monitoring_level=2 mostra informações mais detalhadas:
TPU type: TPU v2
Number of TPU Cores: 8
TPU idle time (lower is better): 0.091%
Utilization of TPU Matrix Units is (higher is better): 10.7%
Step time: 1.95 kms (avg), 1.90kms (minute), 2.00 kms (max)
Infeed percentage: 87.5% (avg). 87.2% (min), 87.8 (max)
Como monitorar sinalizações
--tpu(obrigatório) especifica o nome do Cloud TPU que você quer monitorar.--monitoring_levelaltera o comportamento decapture_tpu_profile, deixando de produzir um único arquivo para fazer monitoramento básico ou contínuo detalhado. Há três níveis disponíveis: nível 0 (padrão) - produz um único arquivo e sai, nível 1 - mostra a versão da TPU e o uso da TPU, nível 2 - mostra o uso da TPU, o tempo ocioso da TPU e o número de núcleos de TPU usados. Também fornece as durações máxima, mínima e média das etapas, juntamente com a contribuição percentual de entrada.--duration_ms(opcional, o padrão é 1.000 ms): especifica quanto tempo levará a criação de um perfil do host da TPU durante cada ciclo. Em geral, essa duração deve ser suficiente para capturar dados de pelo menos uma etapa de treinamento. Definir como 1 segundo captura uma etapa de treinamento na maioria dos modelos, mas se a duração de etapa do modelo for muito grande, é possível definir o valor como 2xstep_time(em ms).--num_queries: especifica por quantos ciclos executarcapture_tpu_profile. Para monitorar continuamente o job da TPU, defina o valor com um número alto. Para verificar rapidamente a duração da etapa do modelo, defina o valor com um número baixo.