Arquitectura del sistema
Las unidades de procesamiento tensorial (TPU) son circuitos integrados específicos de la aplicación (ASIC) diseñados por Google para acelerar las cargas de trabajo de aprendizaje automático. Cloud TPU es un servicio de Google Cloud que pone a disposición las TPU como un recurso escalable.
Las TPU están diseñadas para realizar operaciones matriciales con rapidez, por lo que son ideales para las cargas de trabajo de aprendizaje automático. Puedes ejecutar cargas de trabajo de aprendizaje automático en TPU mediante frameworks como TensorFlow, Pytorch y JAX.
Términos de Cloud TPU
Si es la primera vez que usas Cloud TPU, consulta la página principal de la documentación de TPU. En las siguientes secciones, se explican los términos y conceptos relacionados que se usan en este documento.
Inferencia por lotes
La inferencia por lotes o sin conexión se refiere a hacer inferencias fuera de las canalizaciones de producción, por lo general, en una gran cantidad de entradas. La inferencia por lotes se usa para tareas sin conexión, como el etiquetado de datos, y también para evaluar el modelo entrenado. Los SLO de latencia no son una prioridad para la inferencia por lotes.
chip TPU
Un chip TPU contiene uno o más TensorCores. La cantidad de TensorCores depende de la versión del chip TPU. Cada TensorCore consta de una o más unidades de multiplicación de matrices (MXU), una unidad vectorial y una unidad escalar.
Una MXU se compone de multiplicadores de 128 x 128 en un array sistólico. Las MXU proporcionan la mayor parte de la potencia de procesamiento en un TensorCore. Cada MXU es capaz de realizar 16,000 operaciones de multiplicación y acumulación por ciclo. Todas las multiplicaciones toman entradas bfloat16, pero todas las acumulaciones se realizan en formato de número FP32.
La unidad vectorial se usa para cálculos generales, como activaciones y softmax. La unidad escalar se usa para el flujo de control, calcular direcciones de memoria y otras operaciones de mantenimiento.
Cubo de TPU
Topología de 4 x 4 x 4. Esto solo es aplicable a topologías 3D (a partir de la versión de TPU v4).
Inferencia
La inferencia es el proceso de usar un modelo entrenado para hacer predicciones sobre datos nuevos. Lo usa el proceso de entrega.
Comparación entre varias porciones y una sola porción
Multislice es un grupo de porciones que extiende la conectividad de TPU más allá de las conexiones de interconexión entre chips (ICI) y aprovecha la red del centro de datos (DCN) para transmitir datos más allá de una porción. Los datos dentro de cada porción se transmiten a través de ICI. Mediante esta conectividad híbrida, Multislice habilita el paralelismo entre porciones y te permite usar una mayor cantidad de núcleos TPU para un solo trabajo que la que puede admitir una sola porción.
Las TPU se pueden usar para ejecutar un trabajo, ya sea en una o varias porciones. Consulta la Introducción a Multislice para obtener más detalles.
Resiliencia de ICI de Cloud TPU
La resiliencia a los ICI ayuda a mejorar la tolerancia a errores de los vínculos ópticos y los interruptores de circuitos ópticos (OCS) que conectan las TPU entre cubos. (Las conexiones de ICI dentro de un cubo usan eslabones de cobre que no se ven afectados). La resiliencia de ICI permite que las conexiones ICI se enruten en torno a los errores de OCS y de ICI ópticos. Como resultado, mejora la disponibilidad de programación de porciones de TPU, con la compensación de una degradación temporal en el rendimiento de ICI.
Al igual que Cloud TPU v4, la resiliencia de ICI se habilita de forma predeterminada para las porciones v5p que tienen un cubo o más:
- v5p-128 cuando se especifica el tipo de acelerador
- 4×4×4 cuando se especifica la configuración del acelerador
Recurso en cola
Una representación de los recursos de TPU, que se usa a fin de poner en cola y administrar una solicitud para un entorno de TPU de una o varias porciones. Consulta la guía del usuario de recursos en cola para obtener más información.
Entrega
La entrega es el proceso de implementación de un modelo de aprendizaje automático entrenado en un entorno de producción en el que se puede usar para realizar predicciones o tomar decisiones. La latencia y la disponibilidad a nivel de servicio son importantes para la entrega.
Host único y host múltiple
Un host de TPU es una VM que se ejecuta en una computadora física conectada al hardware de TPU. Las cargas de trabajo de TPU pueden usar uno o más hosts.
Una carga de trabajo de host único está limitada a una VM de TPU. Una carga de trabajo de varios hosts distribuye el entrenamiento entre varias VM de TPU.
Porciones
Una porción de pod es una colección de chips, todos ubicados dentro del mismo pod de TPU conectados por interconexiones entre chips (ICI) de alta velocidad. Los segmentos se describen en términos de chips o TensorCores, según la versión de TPU.
La forma de chip y la topología de chip también se refieren a las formas de porciones.
SparseCore
La v5p incluye cuatro SparseCores por chip que son procesadores de Dataflow que aceleran los modelos que se basan en las incorporaciones encontradas en los modelos de recomendación.
pod de TPU
Un pod de TPU es un conjunto contiguo de TPU agrupados en una red especializada. La cantidad de chips TPU en un Pod de TPU depende de la versión de TPU.
VM o trabajador de TPU
Una máquina virtual que ejecuta Linux y que tiene acceso a las TPU subyacentes. Una VM de TPU también se conoce como trabajador.
TensorCores
Los chips TPU tienen uno o dos TensorCores para ejecutar la multiplicación de matrices. Para obtener más información sobre TensorCores, consulta este artículo de ACM.
Trabajador
Consulta VM de TPU.
Versiones de TPU
La arquitectura exacta de un chip TPU depende de la versión de TPU que uses. Cada versión de TPU también es compatible con diferentes parámetros de configuración y tamaños de porción. Para obtener más información sobre la arquitectura del sistema y las configuraciones compatibles, consulta las siguientes páginas:
Arquitecturas de VM de Cloud TPU
La forma en que interactúas con el host de TPU (y la placa TPU) depende de la arquitectura de VM de TPU que usas: nodos TPU o VMs de TPU.
Arquitectura de VM de TPU
La arquitectura de VM de TPU te permite conectarte directamente a la VM conectada físicamente al dispositivo TPU mediante SSH. Tienes acceso raíz a la VM, por lo que puedes ejecutar código arbitrario. Puedes acceder a los registros de depuración y los mensajes de error del compilador y el entorno de ejecución.

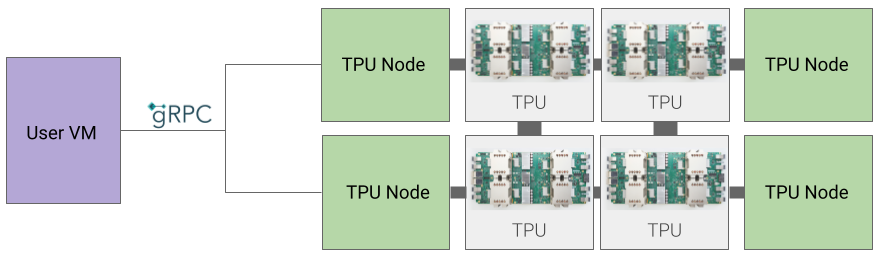
Arquitectura de nodo TPU
La arquitectura de nodo TPU consta de una VM de usuario que se comunica con el host de TPU a través de gRPC. Cuando usas esta arquitectura, no puedes acceder directamente al host de TPU, lo que dificulta la depuración de errores de entrenamiento y TPU.