Configurações de TPU
Configurações de TPU v5p
Um pod TPU v5p é composto por 8.960 chips interconectados com links reconfiguráveis de alta velocidade. A rede flexível da TPU v5p permite conectar os chips em uma fração do mesmo tamanho de várias maneiras. Ao criar uma fração de TPU usando o comando gcloud compute tpus tpu-vm create, especifique o tipo e a forma usando os parâmetros AcceleratorType ou AcceleratorConfig.
A tabela a seguir mostra as formas de fatia única mais comuns compatíveis com a v5p, além da maioria (mas não todas) das formas completas de cubo maiores que 1 cubo. O formato máximo do v5p é 16x16x24 (6.144 ícones, 96 cubos).
| Formato da fatia | Tamanho da VM | No de núcleos | # de ícones | No de máquinas | No de cubos | Oferece suporte ao Twisted? |
| 2x2x1 | Host completo | 8 | 4 | 1 | N/A | N/A |
| 2x2x2 | Host completo | 16 | 8 | 2 | N/A | N/A |
| 2x4x4 | Host completo | 64 | 32 | 8 | N/A | N/A |
| 4x4x4 | Host completo | 128 | 64 | 16 | 1 | N/A |
| 4x4x8 | Host completo | 256 | 128 | 32 | 2 | Sim |
| 4x8x8 | Host completo | 512 | 256 | 64 | 4 | Sim |
| 8x8x8 | Host completo | 1024 | 512 | 128 | 8 | N/A |
| 8x8x16 | Host completo | 2048 | 1024 | 256 | 16 | Sim |
| 8x16x16 | Host completo | 4096 | 2048 | 512 | 32 | Sim |
| 16x16x16 | Host completo | 8192 | 4096 | 1024 | 64 | N/A |
| 16x16x24 | Host completo | 12.288 | 6144 | 1.536 | 96 | N/A |
O treinamento de fração única é compatível com até 6.144 ícones. Ele é extensível para 18432 chips usando Multislice. Para mais detalhes, consulte a Visão geral de vários pedaços do Cloud TPU.
Como usar o parâmetro AcceleratorType
Ao alocar recursos de TPU, use o argumento --accelerator-type para especificar o número de TensorCores em uma fração. --accelerator-type é
uma string formatada
"v$VERSION_NUMBERp-$CORES_COUNT".
Por exemplo, v5p-32 especifica uma fração de TPU v5p com 32 TensorCores (16 chips).
Para provisionar TPUs para um job de treinamento v5p, use um dos seguintes tipos de acelerador na solicitação de criação da CLI ou da API TPU:
- v5p-8
- v5p-16
- v5p-32
- v5p-64
- v5p-128 (um cubo/rack completo)
- v5p-256 (2 cubos)
- v5p-512
- v5p-1024, v5p-12288
Como usar o parâmetro AcceleratorConfig
Nas versões v5p e posteriores do Cloud TPU, AcceleratorConfig é usado da mesma forma que no Cloud TPU v4. A diferença é que, em vez de especificar o tipo de TPU como --type=v4, é preciso defini-lo como a versão do TPU que você está usando (por exemplo, --type=v5p para a versão v5p).
Resiliência de ICI do Cloud TPU
A resiliência de ICI ajuda a melhorar a tolerância a falhas de links ópticos e chaves de circuito óptico (OCS, na sigla em inglês) que conectam TPUs entre cubos. As conexões ICI dentro de um cubo usam elos de cobre que não são afetados. A resiliência da ICI permite que as conexões da ICI sejam roteadas em torno das falhas de OCS e ICI ópticas. Como resultado, ele melhora a disponibilidade de programação de fatias de TPU, com a compensação da degradação temporária no desempenho do ICI.
Semelhante ao Cloud TPU v4, a resiliência de ICI é ativada por padrão para frações v5p que têm um cubo ou maior:
- v5p-128 ao especificar o tipo de acelerador.
- 4x4x4 ao especificar a configuração do acelerador
Propriedades da VM, do host e da fração
| Propriedade | Valor em uma TPU |
| Número de ícones v5p | 4 |
| No de vCPUs | 208 (apenas metade pode ser usada ao usar a vinculação NUMA para evitar penalidade de desempenho entre NUMA) |
| RAM (GB) | 448 (apenas metade pode ser usada ao usar a vinculação NUMA para evitar penalidade de desempenho entre NUMA) |
| No de nós NUMA | 2 |
| Capacidade de processamento de NIC (Gbps) | 200 |
Relação entre o número de TensorCores, chips, hosts/VMs e cubos em um pod:
| Núcleos | Ícones | Hosts/VMs | Cubos | |
|---|---|---|---|---|
| Organizador | 8 | 4 | 1 | |
| Cube (também conhecido como rack) | 128 | 64 | 16 | 1 |
| Maior fração com suporte | 12.288 | 6144 | 1.536 | 96 |
| Pod completo v5p | 17920 | 8960 | 2240 | 140 |
Configurações da TPU v5e
O Cloud TPU v5e é um produto combinado de treinamento e inferência (veiculação). Para diferenciar um ambiente de treinamento e de inferência, use as sinalizações AcceleratorType ou AcceleratorConfig com a API TPU ou a sinalização --machine-type ao criar um pool de nós do GKE.
Os jobs de treinamento são otimizados para capacidade e disponibilidade, enquanto os jobs de exibição são otimizados para latência. Assim, um job de treinamento em TPUs provisionadas para exibição pode ter menor disponibilidade e, da mesma forma, um job de exibição executado em TPUs provisionadas para treinamento pode ter maior latência.
Use AcceleratorType para especificar o número de TensorCores que você quer usar.
Especifique o AcceleratorType ao criar uma TPU usando a
CLI gcloud ou o console do Google Cloud. O valor especificado para AcceleratorType é uma string com o formato: v$VERSION_NUMBER-$CHIP_COUNT.
Também é possível usar AcceleratorConfig para especificar o número de TensorCores que você quer usar. No entanto, como não há variantes de topologia 2D personalizadas para a TPU
v5e, não há diferença entre usar AcceleratorConfig e
AcceleratorType.
Para configurar uma TPU v5e usando AcceleratorConfig, use as sinalizações --version e --topology. Defina --version como a versão da TPU que você quer usar e --topology como a disposição física dos chips de TPU na fração. O
valor especificado para AcceleratorConfig é uma string com o formato AxB,
em que A e B são as contagens de ícones em cada direção.
Os seguintes formatos de fatias 2D são compatíveis com a v5e:
| topologia | Número de chips do TPU | Número de hosts |
| 1x1 | 1 | 1/8 |
| 2x2 | 4 | 1/2 |
| 2x4 | 8 | 1 |
| 4x4 | 16 | 2 |
| 4x8 | 32 | 4 |
| 8x8 | 64 | 8 |
| 8x16 | 128 | 16 |
| 16x16 | 256 | 32 |
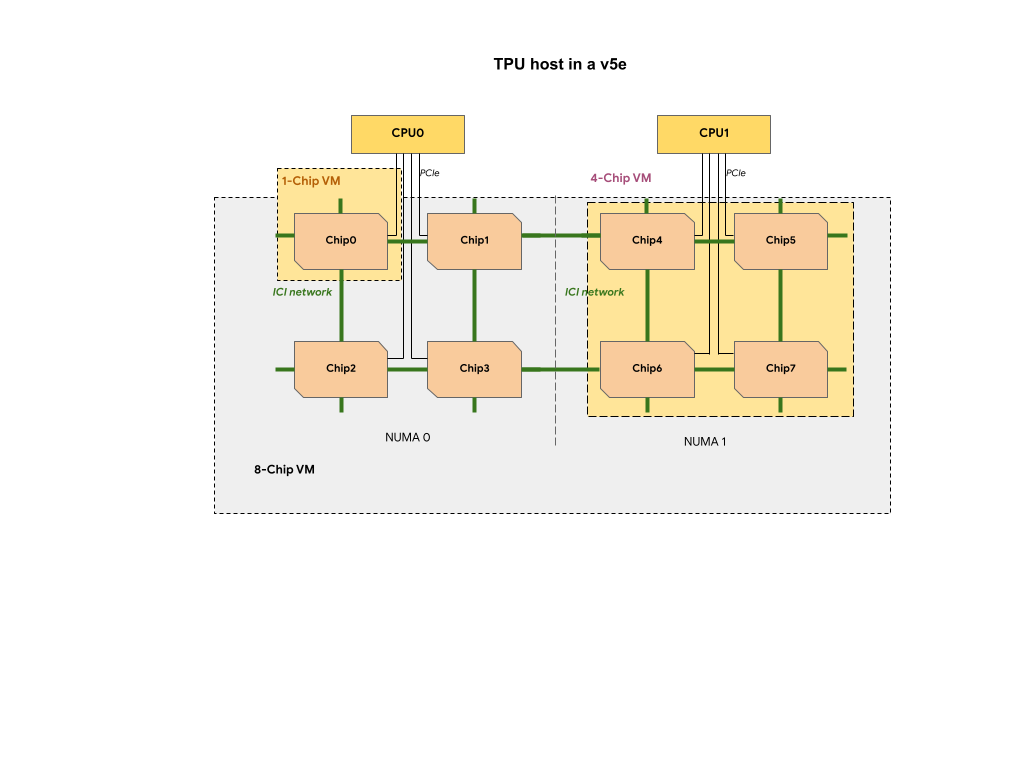
Cada VM de TPU em uma fração de TPU v5e contém 1, 4 ou 8 chips. Em partes menores e com quatro chips, todos os chips de TPU compartilham o mesmo nó de acesso não uniforme à memória (NUMA, na sigla em inglês).
Para VMs de TPU de 8 chips v5e, a comunicação entre CPU e TPU será mais eficiente nas partições
NUMA. Por exemplo, na figura a seguir, a comunicação com CPU0-Chip0 será
mais rápida que a comunicação com CPU0-Chip4.
Tipos do Cloud TPU v5e para veiculação
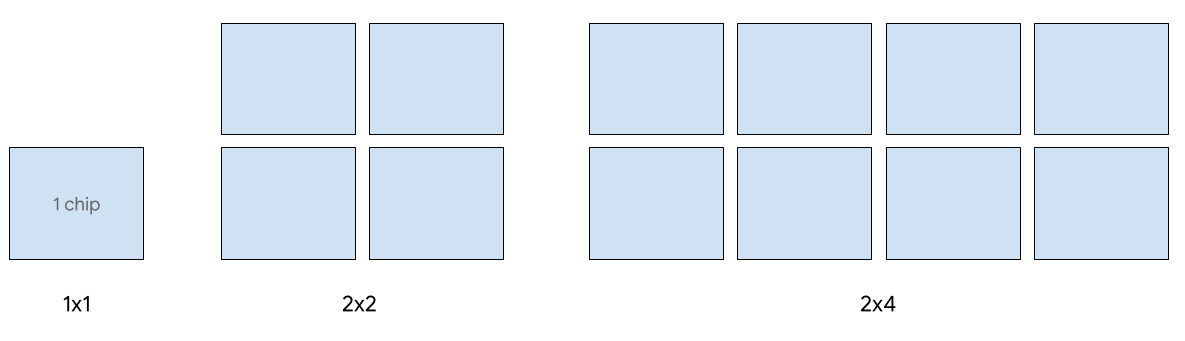
A veiculação de host único é suportada para até oito ícones v5e. As seguintes configurações são compatíveis: frações 1x1, 2x2 e 2x4. Cada fatia tem 1, 4 e 8 ícones, respectivamente.
Para provisionar TPUs para um job de exibição, use um dos seguintes tipos de acelerador na solicitação de criação de TPU da CLI ou API:
| AcceleratorType (API TPU) | Tipo de máquina (API GKE) |
|---|---|
v5litepod-1 |
ct5lp-hightpu-1t |
v5litepod-4 |
ct5lp-hightpu-4t |
v5litepod-8 |
ct5lp-hightpu-8t |
A disponibilização em mais de oito chips v5e, também chamada de exibição de vários hosts, é aceita usando Sax. Para mais informações, consulte Veiculação de modelos de linguagem grandes.
Tipos do Cloud TPU v5e para treinamento
O treinamento oferece suporte para até 256 chips.
Para provisionar TPUs para um job de treinamento v5e, use um dos seguintes tipos de acelerador na solicitação de criação de TPU de CLI ou API:
| AcceleratorType (API TPU) | Tipo de máquina (API GKE) | topologia |
|---|---|---|
v5litepod-16 |
ct5lp-hightpu-4t |
4x4 |
v5litepod-32 |
ct5lp-hightpu-4t |
4x8 |
v5litepod-64 |
ct5lp-hightpu-4t |
8x8 |
v5litepod-128 |
ct5lp-hightpu-4t |
8x16 |
v5litepod-256 |
ct5lp-hightpu-4t |
16x16 |
Comparação dos tipos de VM da TPU v5e:
| Tipo de VM | n2d-48-24-v5lite-tpu | n2d-192-112-v5lite-tpu | n2d-384-224-v5lite-tpu |
| Número de ícones v5e | 1 | 4 | 8 |
| No de vCPUs | 24 | 112 | 224 |
| RAM (GB) | 48 | 192 | 384 |
| No de nós NUMA | 1 | 1 | 2 |
| Aplicável a | v5litepod-1 | v5litepod-4 | v5litepod-8 |
| Interrupção | Alta | Média | Baixa |
Para liberar espaço para cargas de trabalho que exigem mais chips, os programadores podem forçar a interrupção de VMs com menos chips. Portanto, as VMs de 8 chips provavelmente vão forçar a interrupção das VMs de 1 e 4 chips.
Configurações da TPU v4
Um Pod TPU v4 é composto por 4096 chips interconectados com links reconfiguráveis de alta velocidade. A rede flexível da TPU v4 permite conectar os chips em uma fração de pod do mesmo tamanho de várias maneiras. Ao criar uma fração do Pod de TPU, especifique a versão da TPU e o número de recursos de TPU necessários. Ao criar uma fração do Pod de TPU v4, é possível especificar o tipo e o tamanho de duas maneiras: AcceleratorType e AcceleratorConfig.
Como usar o AcceleratorType
Use AcceleratorType quando não estiver especificando uma topologia. Para configurar TPUs v4 usando AcceleratorType, use a sinalização --accelerator-type ao criar sua fração de Pod de TPU. Defina --accelerator-type como uma string que contenha a versão da TPU e o número de TensorCores que você quer usar. Por exemplo, para criar uma fração do pod v4 com 32 TensorCores, você usaria --accelerator-type=v4-32.
O comando a seguir cria uma fração do Pod de TPU v4 com 512 TensorCores usando a sinalização --accelerator-type:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v4-512
--version=tpu-vm-tf-2.16.1-pod-pjrt
O número após a versão da TPU (v4) especifica o número de TensorCores.
Como há dois TensorCores em uma TPU v4, o número de chips de TPU seria 512/2 = 256.
Como usar o AcceleratorConfig
Use AcceleratorConfig quando quiser personalizar a topologia física da fração de TPU. Isso geralmente é necessário para o ajuste de desempenho com frações de pod
maiores que 256 chips.
Para configurar TPUs v4 usando AcceleratorConfig, use as sinalizações --version e --topology. Defina --version como a versão da TPU que você quer usar e --topology como a disposição física dos chips de TPU na fração do pod.
Especifique uma topologia de TPU usando uma de três tuplas, AxBxC, em que A<=B<=C e A, B, C são todos <= 4 ou são todos múltiplos inteiros de 4. Os valores A, B e C são
as contagens de ícones em cada uma das três dimensões. Por exemplo, para criar uma fatia de pod v4 com 16 chips, defina --version=v4 e --topology=2x2x4.
O comando a seguir cria uma fração do Pod de TPU v4 com 128 chips de TPU organizados em uma matriz de 4x4x8:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--type=v4
--topology=4x4x8
--version=tpu-vm-tf-2.16.1-pod-pjrt
Topologias em que 2A=B=C ou 2A=2B=C também têm variantes de topologia otimizadas para comunicação total, por exemplo, 4×4×8, 8×8×16 e 12×12×24. Elas são conhecidas como topologias tori trançadas.
As ilustrações a seguir mostram algumas topologias comuns da TPU v4.
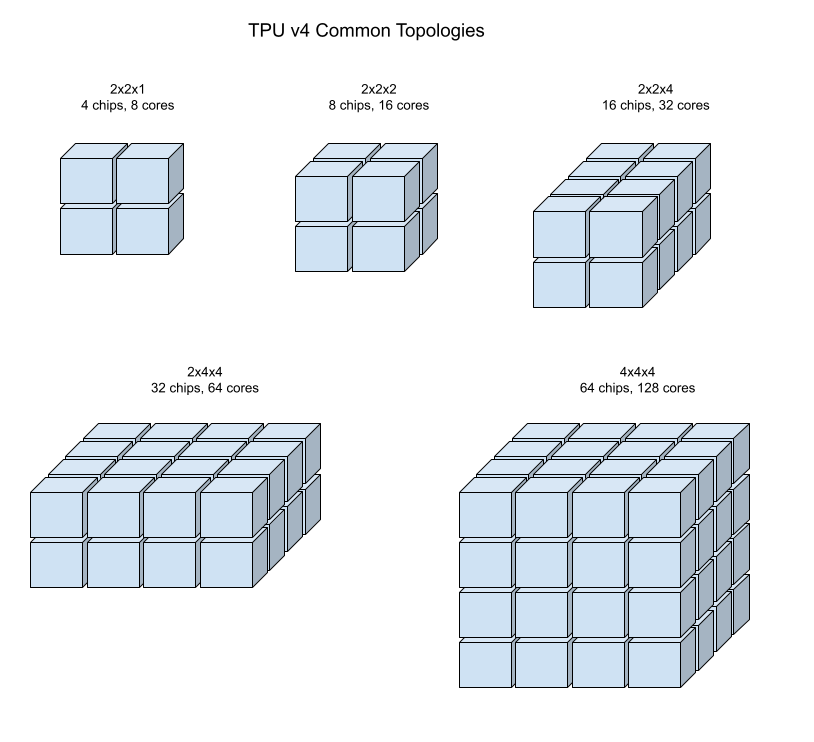
Fatias de pod maiores podem ser criadas com um ou mais "cubos" de chips 4x4x4.
Topologias torcidas de Tori
Algumas formas de frações de toro 3D v4 têm a opção de usar o que é conhecido como topologia de toro trançado. Por exemplo, dois cubos v4 podem ser organizados como uma fatia 4x4x8 ou 4x4x8_torcida. As topologias torcidas oferecem uma largura de banda com bissecção significativamente maior. O aumento da largura de banda de bissecção é útil para cargas de trabalho que usam padrões de comunicação globais. As topologias trançadas podem melhorar o desempenho da maioria dos modelos, sendo que grandes cargas de trabalho de incorporação de TPU são os mais beneficiadas.
Para cargas de trabalho que usam o paralelismo de dados como a única estratégia de paralelismo, as topologias torcidas podem ter um desempenho um pouco melhor. Para LLMs, o desempenho com uma topologia torcida pode variar dependendo do tipo de paralelismo (DP, MP etc.). A prática recomendada é treinar seu LLM com e sem uma topologia torcida para determinar qual oferece o melhor desempenho para o modelo. Alguns experimentos no modelo FSDP MaxText (link em inglês) tiveram de 1 a 2 melhorias de MFU usando uma topologia torcida.
O principal benefício das topologias torcidas é que elas transformam uma topologia de torus assimétrica (por exemplo, 4×4×8) em uma topologia simétrica intimamente relacionada. A topologia simétrica tem muitos benefícios:
- Balanceamento de carga aprimorado
- Largura de banda com bissecção maior
- Rotas de pacotes mais curtas
Esses benefícios se traduzem em melhor desempenho para muitos padrões de comunicação globais.
O software da TPU é compatível com tori trançado em frações em que o tamanho de cada dimensão é igual ou duas vezes o tamanho da menor dimensão. Por exemplo, 4x4x8, 4×8×8 ou 12x12x24.
Por exemplo, considere esta topologia de toro 4×2 com TPUs rotuladas com as coordenadas (X,Y) na fração:
As bordas neste gráfico de topologia são mostradas como arestas não direcionadas para maior clareza. Na prática, cada borda é uma conexão bidirecional entre as TPUs. Chamamos as bordas entre um lado dessa grade e o oposto como bordas circulares, conforme observado no diagrama.
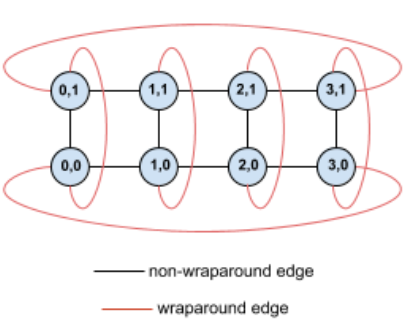
Ao torcer essa topologia, acabamos com uma topologia de torus trançado 4×2 completamente simétrica:
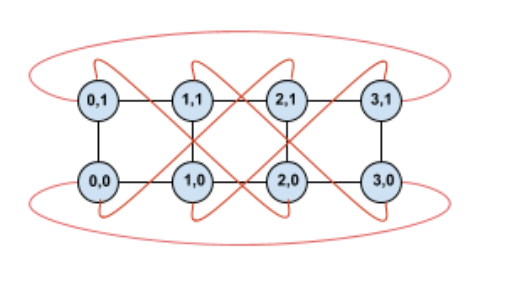
Tudo o que mudou entre esse diagrama e o anterior são as bordas em torno em Y. Em vez de se conectarem a outra TPU com a mesma coordenada X, elas foram deslocadas para se conectar à TPU com a coordenada X+2 mod 4.
A mesma ideia se aplica a diferentes tamanhos de dimensão e números de dimensões diferentes. A rede resultante é simétrica, desde que cada dimensão seja igual ou duas vezes o tamanho da menor dimensão.
A tabela a seguir mostra as topologias trançadas com suporte e um aumento teórico na largura de banda de bissecção delas em comparação com as topologias não trançadas.
| Topologia torcida | Aumento teórico da largura de banda com bissecção em comparação com um toro não trançado |
|---|---|
| 4×4×8_torcido | Aprox. 70% |
| 8x8x16_twisted | |
| 12×12×24_torcido | |
| 4×8×8_torrado | Aprox. 40% |
| 8×16×16_trançado |
Variantes da topologia de TPU v4
Algumas topologias que contêm o mesmo número de ícones podem ser organizadas de maneiras diferentes. Por exemplo, uma fração do Pod de TPU com 512 chips (1024 TensorCores) pode ser configurada usando as seguintes topologias: 4x4x32, 4x8x16 ou 8x8x8. Uma fração de Pod de TPU com 2048 chips (4096 TensorCores) oferece ainda mais opções de topologia: 4x4x128, 4x8x64, 4x16x32 e 8x16x16. Uma fração do Pod de TPU com 2.048 chips (4096 TensorCores) oferece ainda mais opções de topologia: 4x4x128, 4x8x64, 4x16x32 e 8x16x16.
A topologia padrão associada a determinada contagem de ícones é a mais semelhante a um cubo (consulte Topologia v4). Esse formato é provavelmente a melhor escolha para treinamento de ML com paralelismo de dados. Outras topologias podem ser úteis para cargas de trabalho com vários tipos de paralelismo. Por exemplo, paralelismo de modelo e dados ou o particionamento espacial de uma simulação. Essas cargas de trabalho funcionam melhor quando a topologia corresponde ao paralelismo usado. Por exemplo, colocar o paralelismo de modelos de 4 vias na dimensão X e o paralelismo de dados de 256 vias nas dimensões Y e Z corresponde a uma topologia 4x16x16.
Os modelos com várias dimensões de paralelismo têm melhor desempenho com as dimensões de paralelismo associadas às dimensões de topologia de TPU. Eles geralmente são modelos de linguagem grandes (LLMs) paralelos de dados + modelo. Por exemplo, para uma fração de pod da TPU v4 com topologia 8x16x16, as dimensões da topologia da TPU são 8, 16 e 16. É mais eficiente usar paralelismo de modelos de 8 ou 16 direções (mapeado para uma das dimensões de topologia física da TPU). Um paralelismo de modelo de quatro direções não seria ideal para essa topologia, já que não está alinhado com nenhuma das dimensões de topologia da TPU, mas seria ideal com uma topologia 4x16x32 no mesmo número de chips.
As configurações da TPU v4 consistem em dois grupos: os com topologias menores que 64 chips (topologias pequenas) e aqueles com topologias maiores que 64 chips (topologias grandes).
Topologias pequenas da v4
O Cloud TPU é compatível com as seguintes frações do Pod TPU v4 menores que 64 chips, um cubo 4x4x4. É possível criar essas pequenas topologias da v4 usando o nome baseado no TensorCore (por exemplo, v4-32) ou a topologia (por exemplo, 2x2x4):
| Nome (com base na contagem do TensorCore) | Número de fichas | topologia |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
Topologias grandes da v4
As frações do pod da TPU v4 estão disponíveis em incrementos de 64 ícones, com formas que são múltiplos de 4 em todas as três dimensões. As dimensões também precisam estar
em ordem crescente. Confira alguns exemplos na tabela a seguir. Algumas
dessas topologias são "personalizadas" que só podem ser criadas usando as
flags --type e --topology, porque há mais de uma maneira de organizar
os ícones.
O comando a seguir cria uma fração do Pod de TPU v4 com 512 chips de TPU organizados em uma matriz de 8x8x8:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--type=v4
--topology=8x8x8
--version=tpu-vm-tf-2.16.1-pod-pjrt
É possível criar uma fração do Pod de TPU v4 com o mesmo número de TensorCores usando --accelerator-type:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v4-1024
--version=tpu-vm-tf-2.16.1-pod-pjrt
| Nome (com base na contagem do TensorCore) | Número de fichas | topologia |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
N/A: é necessário usar as sinalizações --type e --topology. |
256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
N/A: é necessário usar sinalizações --type e --topology. |
1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |
Configurações da TPU v3
Um Pod TPU v3 é composto por 1024 chips interconectados por links de alta velocidade. Para criar um dispositivo TPU v3 ou uma fração de pod, use a sinalização --accelerator-type para o comando gcloud compute tpus tpu-vm. Para especificar o tipo de acelerador, você especifica a versão da TPU e o número de núcleos de TPU. Para uma única TPU v3, use --accelerator-type=v3-8. Para uma fração do Pod v3 com 128 TensorCores, use --accelerator-type=v3-128.
O comando a seguir mostra como criar uma fração do Pod de TPU v3 com 128 TensorCores:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v3-128
--version=tpu-vm-tf-2.16.1-pjrt
A tabela a seguir lista os tipos de TPU v3 compatíveis:
| Versão da TPU | Fim da compatibilidade |
|---|---|
| v3-8 | (data final ainda não definida) |
| v3-32 | (data final ainda não definida) |
| v3-128 | (data final ainda não definida) |
| v3-256 | (data final ainda não definida) |
| v3-512 | (data final ainda não definida) |
| v3-1024 | (data final ainda não definida) |
| v3-2048 | (data final ainda não definida) |
Para mais informações sobre como gerenciar TPUs, consulte Gerenciar TPUs. Para mais informações sobre as diferentes versões do Cloud TPU, consulte Arquitetura do sistema.
Configurações da TPU v2
Um Pod TPU v2 é composto por 512 chips interconectados com links reconfiguráveis de alta velocidade. Para criar uma fração do Pod de TPU v2, use a sinalização --accelerator-type para o comando gcloud compute tpus tpu-vm. Para especificar o tipo de acelerador, especifique a versão da TPU e o número de núcleos de TPU. Para uma única TPU v2, use --accelerator-type=v2-8. Para uma fração de pod v2 com 128 TensorCores, use --accelerator-type=v2-128.
O comando a seguir mostra como criar uma fração do Pod de TPU v2 com 128 TensorCores:
$ gcloud compute tpus tpu-vm create tpu-name
--zone=zone
--accelerator-type=v2-128
--version=tpu-vm-tf-2.16.1-pjrt
Para mais informações sobre como gerenciar TPUs, consulte Gerenciar TPUs. Para mais informações sobre as diferentes versões do Cloud TPU, consulte Arquitetura do sistema.
A tabela a seguir lista os tipos de TPU v2 compatíveis
| Versão da TPU | Fim da compatibilidade |
|---|---|
| v2-8 | (data final ainda não definida) |
| v2-32 | (data final ainda não definida) |
| v2-128 | (data final ainda não definida) |
| v2-256 | (data final ainda não definida) |
| v2-512 | (data final ainda não definida) |
Compatibilidade do tipo de TPU
É possível alterar o tipo de TPU para outro que tenha o mesmo número de TensorCores ou chips (por exemplo, v3-128 e v4-128) e executar seu script de treinamento sem alterações no código. No entanto, se você mudar para um tipo de TPU com um número maior ou menor de TensorCores, será necessário realizar ajustes e otimização significativos. Para mais informações,
consulte Treinamento em pods de TPU.
Versões de software da VM da TPU
Nesta seção, descrevemos as versões do software de TPU que precisam ser usadas em uma TPU com a arquitetura de VM da TPU. Para saber mais sobre a arquitetura do nó de TPU, consulte Versões de software do nó de TPU.
As versões do software da TPU estão disponíveis para os frameworks do TensorFlow, PyTorch e JAX.
TensorFlow
Use a versão de software do TPU que corresponde à versão do TensorFlow com que seu modelo foi gravado.
A partir do TensorFlow 2.15.0, também é necessário especificar o
ambiente de execução do executor de stream (SE, na sigla em inglês) ou PJRT. Por exemplo, se você estiver usando o TensorFlow 2.16.1 com o ambiente de execução PJRT, use a versão tpu-vm-tf-2.16.1-pjrt do software de TPU. As versões anteriores
ao TensorFlow 2.15.0 oferecem suporte apenas ao executor de stream. Para mais
informações sobre PJRT, consulte o suporte a PJRT do TensorFlow.
As versões de software atuais da VM de TPU do TensorFlow compatíveis são:
- tpu-vm-tf-2.16.1-pjrt
- tpu-vm-tf-2.16.1-se
- tpu-vm-tf-2.15.0-pjrt
- tpu-vm-tf-2.15.0-se
- tpu-vm-tf-2.14.1
- tpu-vm-tf-2.14.0
- tpu-vm-tf-2.13.1
- tpu-vm-tf-2.13.0
- tpu-vm-tf-2.12.1
- tpu-vm-tf-2.12.0
- tpu-vm-tf-2.11.1
- tpu-vm-tf-2.11.0
- tpu-vm-tf-2.10.1
- tpu-vm-tf-2.10.0
- tpu-vm-tf-2.9.3
- tpu-vm-tf-2.9.1
- tpu-vm-tf-2.8.4
- tpu-vm-tf-2.8.3
- tpu-vm-tf-2.8.0
- tpu-vm-tf-2.7.4
- tpu-vm-tf-2.7.3
Para mais informações sobre versões de patch do TensorFlow, consulte Versões de patch do TensorFlow compatíveis.
Compatibilidade com PJRT do TensorFlow
A partir do TensorFlow 2.15.0, é possível usar a interface PJRT para TensorFlow na TPU. O PJRT tem desfragmentação automática da memória do dispositivo e simplifica a integração do hardware com frameworks. Para mais informações sobre o PJRT, consulte PJRT: Simplificando o hardware de ML e a integração de framework (em inglês) no blog do Google Open Source.
Nem todos os recursos da TPU v2, v3 e v4 foram migrados para o ambiente de execução PJRT. A tabela a seguir descreve quais recursos têm suporte no PJRT ou no executor do stream.
| Accelerator | Engenharia de | Compatível com PJRT | Compatível com o executor de streaming |
|---|---|---|---|
| TPU v2 a 4 | Computação densa (sem API de incorporação de TPU) | Sim | Sim |
| TPU v2 a 4 | API Dense compute + API de embedding de TPU | Não | Sim |
| TPU v2 a 4 | tf.summary/tf.print com posicionamento de dispositivo flexível |
Não | Sim |
| TPU v5e | Computação densa (sem API de incorporação de TPU) | Sim | Não |
| TPU v5e | API TPU embedding | N/A: o TPU v5e não é compatível com a API de incorporação de TPU | N/A |
| TPU v5p | Computação densa (sem API de incorporação de TPU) | Sim | Não |
| TPU v5p | API TPU embedding | Sim | Não |
TPU v4 com o TensorFlow versão 2.10.0 e anteriores
Se você estiver treinando um modelo na TPU v4 com o TensorFlow, as versões 2.10.0 e anteriores do TensorFlow usarão as versões específicas de v4 mostradas na tabela a seguir. Se a versão do TensorFlow que você está usando não aparecer na tabela, siga as orientações na seção do TensorFlow.
| Versão do TensorFlow | Versão de software da TPU |
|---|---|
| 2.10.0 | tpu-vm-tf-2.10.0-v4 e tpu-vm-tf-2.10.0-pod-v4 |
| 2.9.3 | tpu-vm-tf-2.9.3-v4 e tpu-vm-tf-2.9.3-pod-v4 |
| 2.9.2 | tpu-vm-tf-2.9.2-v4 e tpu-vm-tf-2.9.2-pod-v4 |
| 2.9.1 | tpu-vm-tf-2.9.1-v4 e tpu-vm-tf-2.9.1-pod-v4 |
Versões do Libtpu
As VMs de TPU são criadas com o TensorFlow e a biblioteca Libtpu correspondente pré-instalada. Se você estiver criando sua própria imagem de VM, especifique as seguintes versões de software da TPU do TensorFlow e as versões do libtpu correspondentes:
| Versão do TensorFlow | Versão do libtpu.so |
|---|---|
| 2.16.1 | 1.10.1 |
| 2.15.0 | 1.9.0 |
| 2.14.1 | 1.8.1 |
| 2.14.0 | 1.8.0 |
| 2.13.1 | 1.7.1 |
| 2.13.0 | 1.7.0 |
| 2.12.1 | 1.6.1 |
| 2.12.0 | 1.6.0 |
| 2.11.1 | 1.5.1 |
| 2.11.0 | 1.5.0 |
| 2.10.1 | 1.4.1 |
| 2.10.0 | 1.4.0 |
| 2.9.3 | 1.3.2 |
| 2.9.1 | 1.3.0 |
| 2.8.3 | 1.2.3 |
| 2,8* | 1.2.0 |
| 2.7.3 | 1.1.2 |
PyTorch
Use a versão do software da TPU que corresponde à versão do PyTorch com que seu modelo foi gravado. Por exemplo, se você estiver usando o PyTorch 1.13 e a TPU v2 ou v3, use a versão de software do TPU tpu-vm-pt-1.13. Se você estiver usando a TPU v4, utilize a versão tpu-vm-v4-pt-1.13 do software da TPU. A mesma versão do software da TPU é usada para pods de TPU (por exemplo,v2-32, v3-128, v4-32). As versões atuais do software de TPU compatíveis são:
TPU v2/v3:
- tpu-vm-pt-2.0 (pytorch-2.0)
- tpu-vm-pt-1.13 (pytorch-1.13)
- tpu-vm-pt-1.12 (pytorch-1.12)
- tpu-vm-pt-1.11 (pytorch-1.11)
- tpu-vm-pt-1.10 (pytorch-1.10)
- v2-alpha (pytorch-1.8.1)
TPU v4:
- tpu-vm-v4-pt-2.0 (pytorch-2.0)
- tpu-vm-v4-pt-1.13 (pytorch-1.13)
TPU v5 (v5e e v5p):
- v2-alpha-tpuv5 (pytorch-2.0)
Quando você cria uma VM de TPU, a versão mais recente do PyTorch é pré-instalada nela. A versão correta do libtpu.so é instalada automaticamente quando você instala o PyTorch.
Para alterar a versão atual do software PyTorch, consulte Como alterar a versão do PyTorch.
JAX
Você precisa instalar manualmente o JAX na sua VM de TPU. Não existe uma versão de software de TPU específica do JAX para a TPU v2 e v3. Para versões posteriores da TPU, use as seguintes versões de software:
- TPU v4: tpu-vm-v4-base
- TPU v5e: v2-alpha-tpuv5
- TPU v5p: v2-alpha-tpuv5
A versão correta do libtpu.so é automaticamente instalada quando você instala o JAX.
Versões de software do nó da TPU
Nesta seção, descrevemos as versões do software da TPU que precisam ser usadas para uma TPU com a arquitetura de nó de TPU. Para a arquitetura de VM da TPU, consulte Versões do software da VM da TPU.
As versões do software da TPU estão disponíveis para os frameworks do TensorFlow, PyTorch e JAX.
TensorFlow
Use a versão de software do TPU que corresponde à versão do TensorFlow com que seu modelo foi gravado. Por exemplo, se você estiver usando o TensorFlow 2.12.0, use a versão 2.12.0 do software de TPU. As versões específicas do software de TPU do TensorFlow são:
- 2.12.1
- 2.12.0
- 2.11.1
- 2.11.0
- 2.10.1
- 2.10.0
- 2.9.3
- 2.9.1
- 2.8.4
- 2.8.2
- 2.7.3
Para mais informações sobre versões de patch do TensorFlow, consulte Versões de patch do TensorFlow compatíveis.
Quando você cria um nó da TPU, a versão mais recente do TensorFlow é pré-instalada nele.
PyTorch
Use a versão do software de TPU que corresponde à versão do PyTorch com que o
modelo foi gravado. Por exemplo, se estiver usando o PyTorch 1.9, utilize a versão de software pytorch-1.9.
As versões do software de TPU específicas para PyTorch são:
- pytorch-2.0
- pytorch-1,13
- pytorch-1,12
- pytorch-1,11
- pytorch-1,10
- pytorch-1.9
- pytorch-1.8
- pytorch-1.7
pytorch-1.6
pytorch-nightly
Quando você cria um nó da TPU, a versão mais recente do PyTorch é pré-instalada nele.
JAX
Como o JAX precisa ser instalado manualmente na VM de TPU, não há uma versão de software de TPU específica do JAX pré-instalada. É possível usar qualquer uma das versões de software listadas para o TensorFlow.
A seguir
- Saiba mais sobre a arquitetura de TPU na página Arquitetura do sistema.
- Consulte Quando usar TPUs para conhecer os tipos de modelos adequados para o Cloud TPU.